






MonoNeRD: NeRF-like Representations for Monocular 3D Object Detection
MonoNeRD:用于单目三维物体检测的类 NeRF 表示法
摘要翻译
在单目三维检测领域,通常的做法是利用场景几何线索来提高检测器的性能。然而,现有的许多作品都明确采用了这些线索,如估计深度图并将其反向投影到三维空间。由于从二维到三维的维度增加,这种显式方法会导致三维表示的稀疏性,从而导致大量信息丢失,尤其是对于远处和被遮挡的物体。为了缓解这一问题,我们提出了 MonoNeRD,这是一种新颖的检测框架,可以推断出密集的三维几何图形和占位情况。具体来说,我们用符号距离函数(SDF)对场景进行建模,从而有助于生成密集的三维表征。我们将这些表示法视为神经辐射场(NeRF),然后采用体积渲染来恢复 RGB 图像和深度图。据我们所知,这项研究首次为 M3D 引入了体积渲染技术,并展示了隐式重建技术在基于图像的 3D 感知方面的潜力。在 KITTI-3D 基准和 Waymo 开放数据集上进行的大量实验证明了 MonoNeRD 的有效性。代码可在此 https 网址获取。
论文总结
论文提出了一种名为MonoNeRD的新型检测框架,该框架能够从单目图像中推断出密集的3D几何结构和占用情况。该框架使用有符号距离函数(SDF)来建模场景,并将其视为神经辐射场(NeRF),以便从单张图像中实现精确的3D感知。作者首次为单目3D目标检测引入了体积渲染技术。通过在基准数据集上进行的广泛实验,证明了MonoNeRD与先前最先进方法相比的有效性。这项研究的主要贡献包括为单目3D检测引入了类NeRF表示,使用体积渲染进行3D表示,并展示了隐式重建对基于图像的3D感知的潜力。
主要要点包括:
- MonoNeRD是一种用于单目3D目标检测的新型检测框架。
- 它使用类NeRF表示来推断密集的3D几何结构和占用情况。
- 为单目3D检测引入了体积渲染技术,这在该领域尚属首次。
- 在基准数据集上进行的广泛实验证明了MonoNeRD的有效性。
- 研究突出了隐式重建对基于图像的3D感知的潜力。
架构
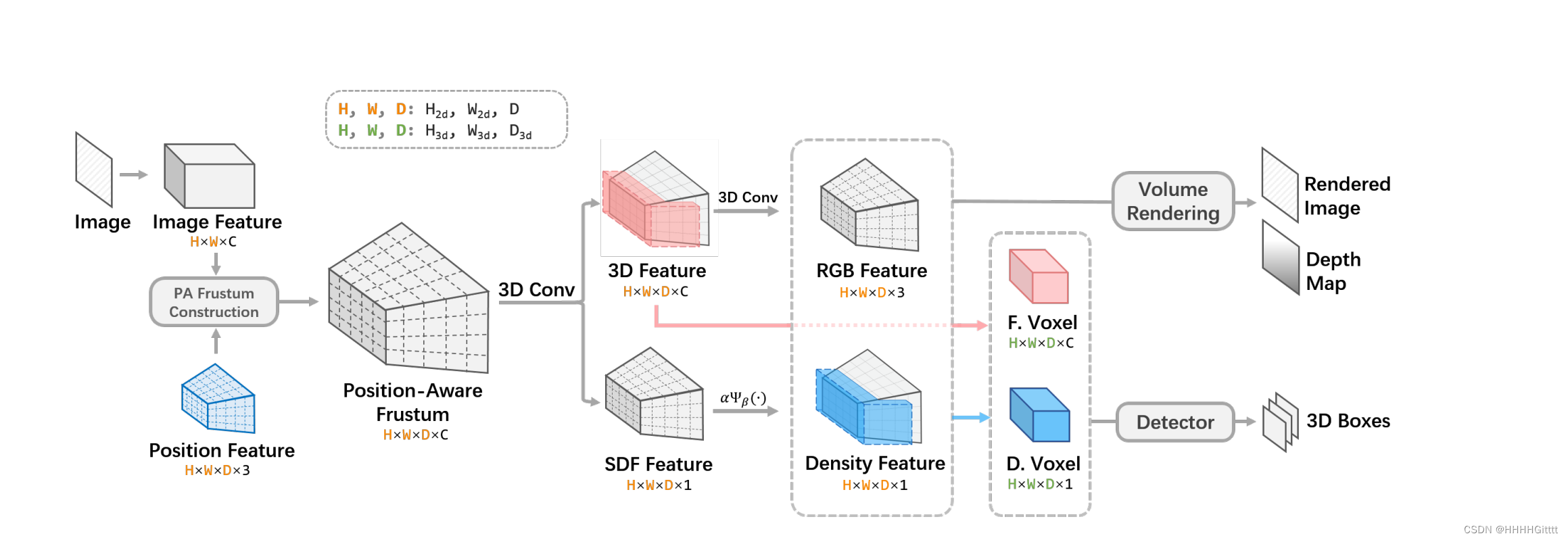
架构解读:
-
MonoNeRD框架:MonoNeRD是一个为单目3D目标检测设计的检测框架,它能够从单张图像中推断出密集的3D几何结构和占用情况。这一点对于只有单个视角图像可用的应用场景尤为重要。
-
使用有符号距离函数(SDF)建模场景:MonoNeRD框架使用SDF来建模场景的3D几何结构。SDF为场景中的每个点提供了一个值,表示该点到最近表面的距离,其中正值表示点在物体外部,负值表示点在物体内部。这种方法允许框架精确地表示复杂的3D形状和结构。
-
将场景视为神经辐射场(NeRF):MonoNeRD将使用SDF建模的场景视为NeRF,利用NeRF的技术来从单张图像中实现精确的3D感知。这包括使用体积渲染技术来渲染3D场景,从而从单个视角图像中推断出3D信息。
主要贡献:
-
为单目3D检测引入类NeRF表示:MonoNeRD框架的核心创新之一是为单目3D目标检测引入了类NeRF的表示方法,这在该领域尚属首次。这种表示方法使得从单张图像中推断3D几何结构和占用情况成为可能。
-
引入体积渲染技术:MonoNeRD首次为单目3D目标检测引入了体积渲染技术,这一技术在处理单目图像时展现了隐式重建的潜力,为基于图像的3D感知提供了新的视角。
-
在基准数据集上的有效性验证:通过在基准数据集上进行的广泛实验,MonoNeRD展示了其有效性,与先前的最先进方法相比,取得了更好的性能。这证明了MonoNeRD在单目3D目标检测领域的应用潜力。
总的来说,MonoNeRD框架通过结合SDF和NeRF的技术,为单目3D目标检测提供了一种新的方法,能够有效地从单张图像中推断出3D几何结构和占用情况,展示了隐式重建对于图像基础的3D感知的重要潜力。
以下是如何使用SDF来增强NeRF的体积渲染技术的一种方法:
1. SDF的几何信息引导NeRF训练
-
场景表示:首先,使用SDF来表示场景的3D几何结构。SDF不仅能够描述物体的表面,还能提供关于物体内部和外部区域的信息。
-
结合SDF和NeRF:在NeRF的框架中,通常是通过一个深度神经网络(如MLP)来学习场景的连续体积表示,包括颜色和密度。通过将SDF的几何信息作为额外的输入或约束融入到NeRF的训练过程中,可以使NeRF更准确地捕捉到场景的3D结构。
2. 体积渲染时考虑SDF信息
-
体积渲染:NeRF通过沿视线方向对场景进行体积渲染,计算光线穿过体积元素时的颜色累积和衰减。在这个过程中,可以利用SDF提供的距离信息来指导渲染过程,例如,通过调整体积元素的密度值,使其反映SDF定义的物体表面和内部结构。
-
改进渲染效果:SDF的准确几何信息可以帮助NeRF模型更精确地模拟光线与物体表面的相互作用,如反射和折射,从而在渲染的图像中实现更真实的视觉效果。
3. 优化和加速渲染
- 空间加速:SDF还可以用于加速NeRF的渲染过程。由于SDF提供了关于场景几何的精确信息,可以通过SDF来优化光线追踪步骤,快速确定光线与场景交互的位置,减少不必要的计算。
实验
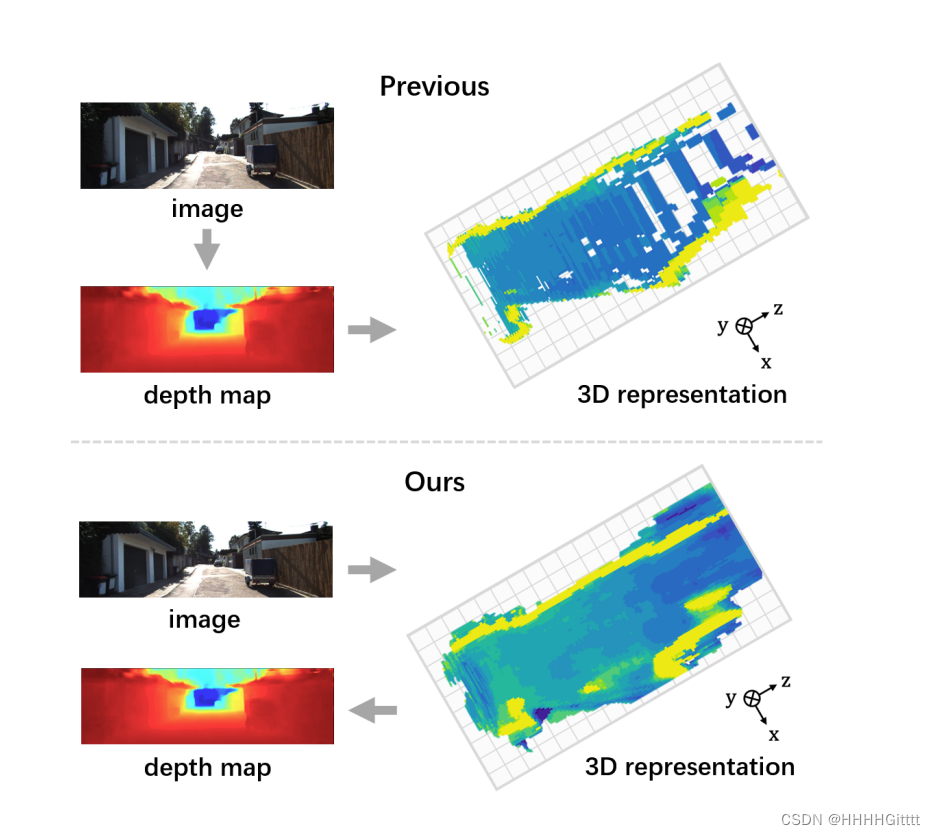
第五部分“实验”(Experiments)详细介绍了以下内容:
-
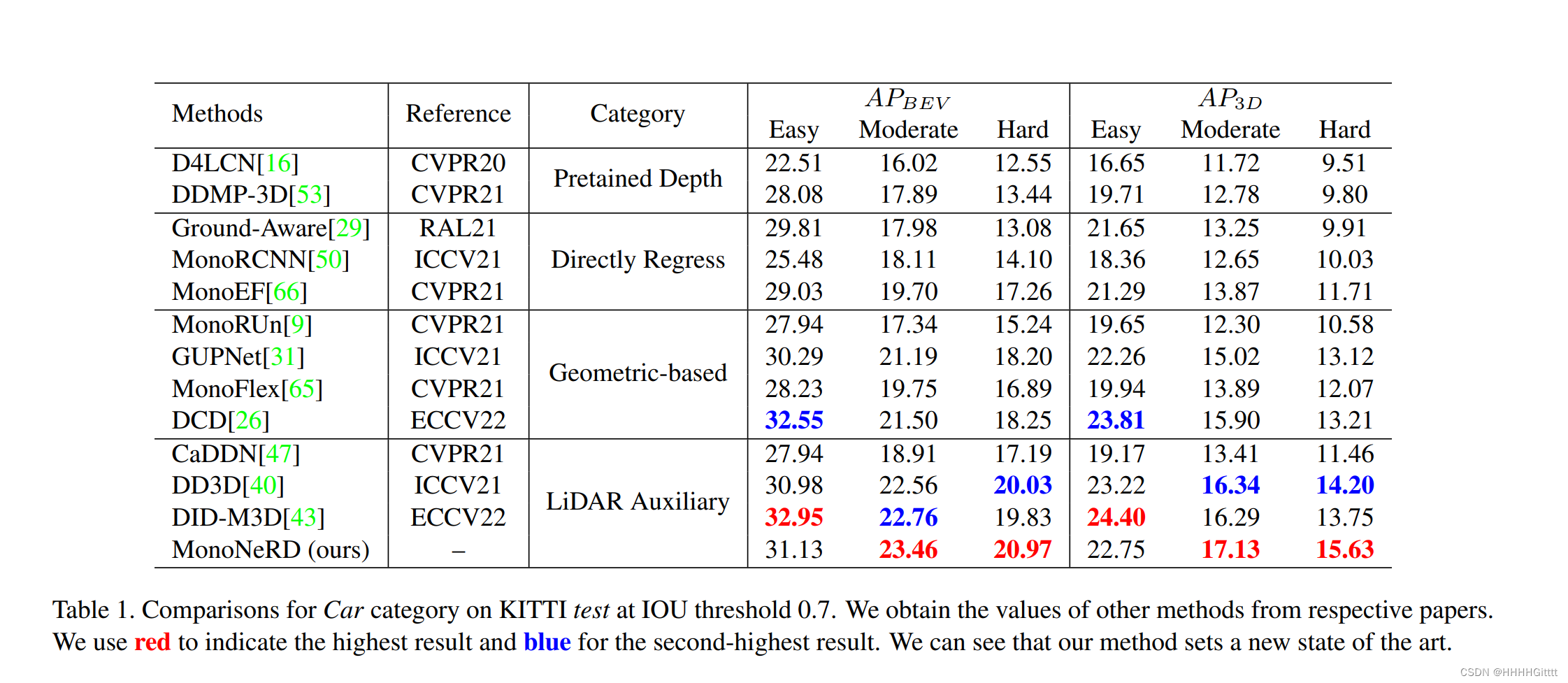
数据集和评价指标:实验主要在KITTI数据集上进行,该数据集包含了7,481张训练图像(trainval集)和7,518张测试图像(test集),并配有同步的LiDAR点云数据。以往的工作通常将训练图像分为3,712个样本的训练集和3,769个样本的验证集,本文也遵循了这一设置。KITTI数据集上的结果是使用基于IoU的标准来测量的,对于汽车类别,既包括鸟瞰图(BEV)任务也包括3D任务,使用0.7的阈值计算40个召回值的平均精度(AP|R40)。
-
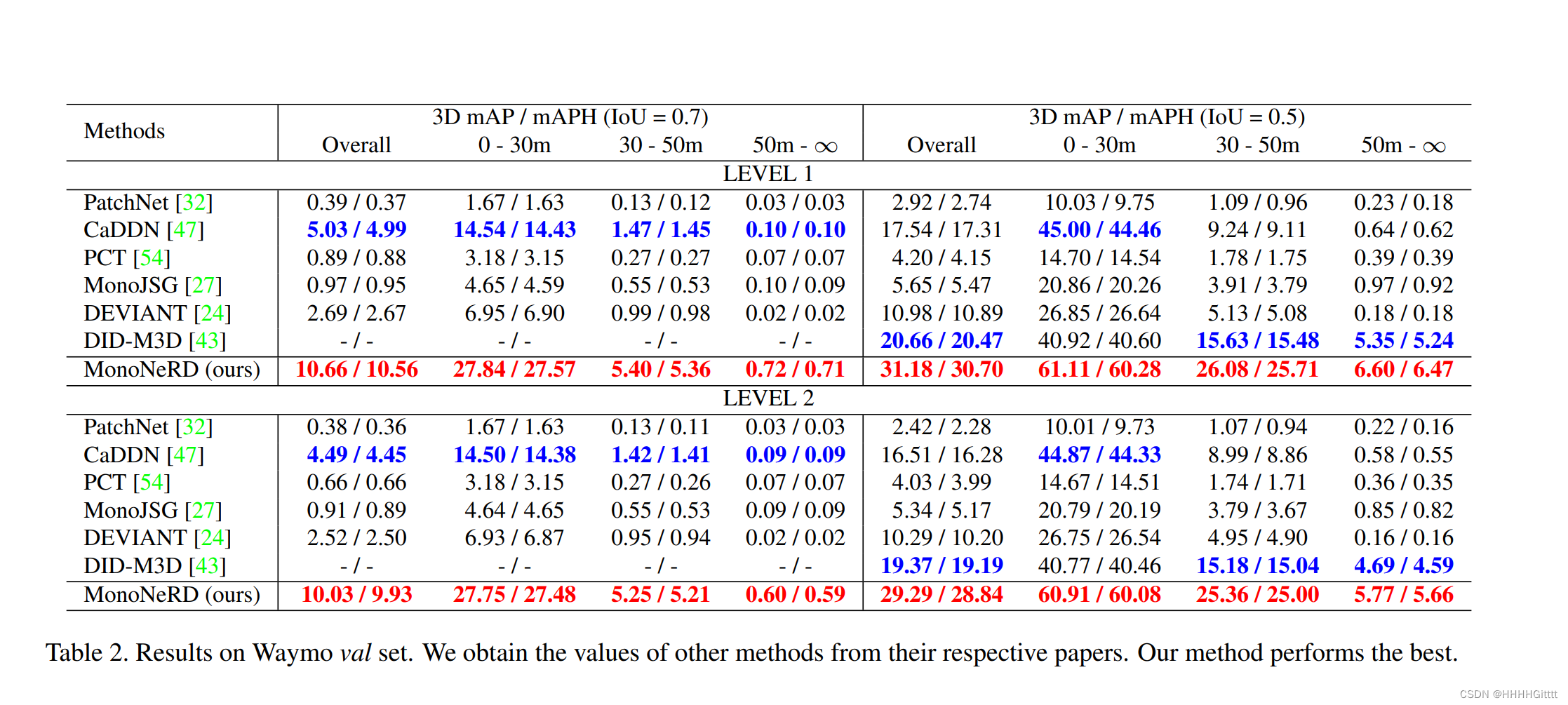
实验结果:在KITTI硬任务和Waymo数据集的距离范围(30m-50m, 50m-∞)上的结果展示了该方法在处理远距离和遮挡对象方面的优越性。
-
消融研究:对KITTI验证集上的汽车类别进行了消融研究,以分析所提出的NeRF式表示的有效性。实验表明,仅使用单个RGB图像的监督对检测无用甚至有害,因为单一图像无法提供深度信息。稀疏的LiDAR深度图标签可以显著改善性能。
-
网络结构和体积渲染损失的消融:进行了网络结构和体积渲染损失的消融研究,以验证所提出设计的有效性。实验结果显示,与基线相比,使用更多的3D卷积层和不同的损失函数可以改善性能。
-
可视化:提供了深度图基表示和所提出的NeRF式表示的可视化对比,展示了所提方法为远处对象生成更密集特征的能力。
结论
通过将SDF的准确3D几何信息结合到NeRF的体积渲染技术中,可以显著提高渲染的准确性和效率,特别是在处理具有复杂3D结构的场景时。这种结合利用了SDF在几何建模方面的优势和NeRF在生成高质量渲染图像方面的能力,为3D场景的精确渲染和分析提供了一种强大的工具。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









