






- Scrapy 安装
pip install scrapy - Scrapy框架
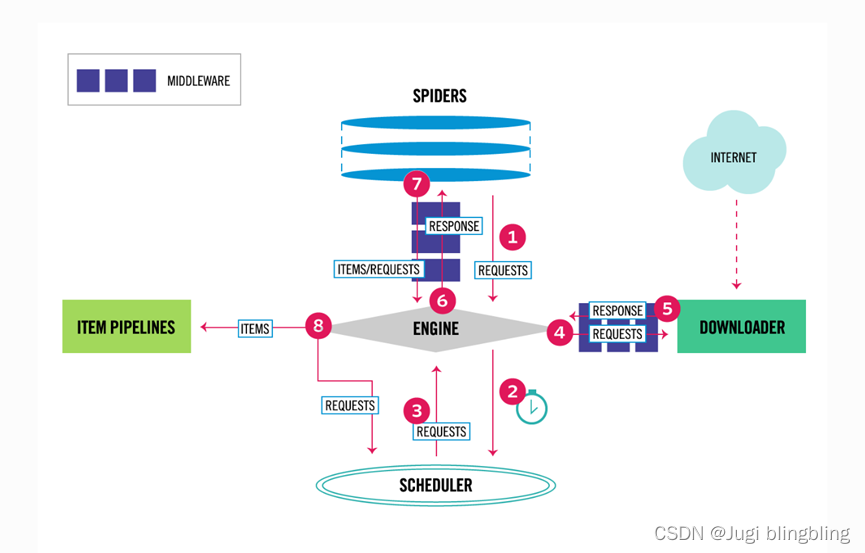
(1) Engine 从 Spider 获取要爬行的初始请求
(2) Engine 在 Scheduler调度程序中调度请求,并请求抓取下一个请求。
(3) Scheduler 将下一个请求返回给engine
(4) Engine 将请求发送给 downloader,通过downloader中间件(process_request)
(5) 一旦页面完成下载,downloader就会生成一个响应(使用该页面)并将它发送到engine,通过downloader(process_response)
(6) 引擎接受来自downloader的响应,并通过spider中间件(process_spider_input)将其发送到spilder进行处理
(7) Spiler处理响应,并通过Spiler中间件(spilder_process_input)将获取的项和新请求一并返回给engine。
(8)Engine将处理过的项目发送给项目管道,将将处理过的请求发送给scheduler,并请求下一个可能得请求到调度器。
(9) 重复,直到不再有步骤来为止。
Engine: 引擎获取所有数据之间组件之间的数据流,并在某些操作时出发响应
Scheduler: 调度器接受来自引擎的请求,并对他们进行排队
Downloader: downloader负责抓取网页,而引擎又将其提供给Spilder
Spilder: 是用户编写的自定义类,用于解析响应并从中提取项或要跟踪的其他请求。
Item pipline: 负责在spilder提取项目后进行处理,包括清理,验证和持久化(比如将项存储在数据库中
- 创建项目
Scrapy startproject
// 进入项目splider 目录,创建爬虫模板
eg: scrapy genspider tu8tu https://xiaoguotu.to8to.com/tuce_sort1
启动调用的名称
scrapy crawl tu8tu
4. 代码
import scrapy
import re
import json
from cc_demo_project.items import CcDemoProjectItem
class Tu8tuSpider(scrapy.Spider):
name = "tu8tu"
allowed_domains = ["www.to8to.com"]
start_urls = ["https://xiaoguotu.to8to.com/tuce_sort1"]
# 这里使用了正则表达式来获取项目的id,需要使用转义字符来转义这个.
def parse(self, response):
content_id_search = re.compile(r"(\d+)\.html")
# response 就是一个Xpath 对象
item_list = response.xpath("//div[@class='item']");
num = 0;
for item in item_list:
info = {}
info['content_name'] = item.xpath('.//div/a/text()').extract_first()
content_url = 'https:' + item.xpath(".//div/a/@href").extract_first()
info['content_url'] = content_url
if content_url == 'https://www.to8to.com/zb/?ptag=9426_2_1_9628':
continue
info['content_id'] = content_id_search.search(content_url).group(1)
#print(content_url)
#info['content_ajax_url'] = 'https://xiaoguotu.to8to.com/case/list?a2=0&a12=&a11=' + str(info['content_id']) + '&a1=0&a17=1'
yield scrapy.Request(url=info['content_url'] , callback =self.handle_pic_response , dont_filter=True , meta=info);
#if response.xpath("//a[@id='nextpageid']"):
new_page = int(response.xpath("//div[@class='pages']/strong/text()").extract_first());
page_code = new_page+1
new_page_url = "https://xiaoguotu.to8to.com/tuce_sort1?page={}".format(page_code);
#print(new_page_url)
yield scrapy.Request(url=new_page_url , callback=self.parse, dont_filter=True)
def handle_pic_response(self , response):
# print('---------------')
#print(response.text)
pic_data = response.xpath("//div[@class='item__wrapper']");
for datas in pic_data:
info_data =CcDemoProjectItem()
content_name= datas.xpath('.//img/@src').extract_first()
print(content_name)
info_data['content_name'] = content_name
info_data['iamge_url'] = datas.xpath('.//img/@alt').extract_first()
yield info_data
- 项目响应到 Pipine
ITEM_PIPELINES = {
“cc_demo_project.pipelines.CcDemoProjectPipeline”: 300,
}














 371
371











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









