







分布式数据库表的类型选择很重要,本文主要学习tdsql分布式相关表类型。
表的分类
- shard表-普通表
数据会根据shardkey打散,分布在各个DN结点中 。 - shard表-分区表
每个节点都会建相同的分区,数据会分布在各DN结点中。 - shard表-冷热分区表
每个节点都会建相同的分析,数据根据冷热分隔规则分布在不同的节DN点。 - 复制表
复制表存在于每个DN结点中
shard表-普通表
- 有主键shardkey取主键
postgres=# create table t1(id int,name varchar(50),ct timestamp,primary key(id));
CREATE TABLE
postgres=# \d+ t1;
Table "public.t1"
Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
--------+-----------------------------+-----------+----------+---------+----------+--------------+-------------
id | integer | | not null | | plain | |
name | character varying(50) | | | | extended | |
ct | timestamp without time zone | | | | plain | |
Indexes:
"t1_pkey" PRIMARY KEY, btree (id)
Has OIDs: yes
Distribute By: SHARD(id)
Location Nodes: ALL DATANODES
- 无主键可指定shardkey
postgres=# create table t11(id int,name varchar(50),ct timestamp) distribute by shard(ct);
CREATE TABLE
postgres=# \d+ t11;
Table "public.t11"
Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
--------+-----------------------------+-----------+----------+---------+----------+--------------+-------------
id | integer | | | | plain | |
name | character varying(50) | | | | extended | |
ct | timestamp without time zone | | not null | | plain | |
Has OIDs: yes
Distribute By: SHARD(ct)
Location Nodes: ALL DATANODES
- 复合主键shardkey取主键第一个字段
postgres=# create table t2(id int,name varchar(50),ct timestamp,primary key(id,name));
CREATE TABLE
postgres=# \d+ t2;
Table "public.t2"
Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
--------+-----------------------------+-----------+----------+---------+----------+--------------+-------------
id | integer | | not null | | plain | |
name | character varying(50) | | not null | | extended | |
ct | timestamp without time zone | | | | plain | |
Indexes:
"t2_pkey" PRIMARY KEY, btree (id, name)
Has OIDs: yes
Distribute By: SHARD(id)
Location Nodes: ALL DATANODES
postgres=# create table t3(id int,name varchar(50),ct timestamp,primary key(name,id));
CREATE TABLE
postgres=# \d+ t3;
Table "public.t3"
Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
--------+-----------------------------+-----------+----------+---------+----------+--------------+-------------
id | integer | | not null | | plain | |
name | character varying(50) | | not null | | extended | |
ct | timestamp without time zone | | | | plain | |
Indexes:
"t3_pkey" PRIMARY KEY, btree (name, id)
Has OIDs: yes
Distribute By: SHARD(name)
Location Nodes: ALL DATANODES
- 有主键的时候,指定的shardkey必须为主键中的一个
postgres=# create table t5(id int,name varchar(50),ct timestamp,primary key(id)) distribute by shard(ct);
ERROR: Unique index of partitioned table must contain the hash distribution column.
postgres=# create table t5(id int,name varchar(50),ct timestamp,primary key(id,name)) distribute by shard(name);
CREATE TABLE
postgres=# \d+ t5;
Table "public.t5"
Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
--------+-----------------------------+-----------+----------+---------+----------+--------------+-------------
id | integer | | not null | | plain | |
name | character varying(50) | | not null | | extended | |
ct | timestamp without time zone | | | | plain | |
Indexes:
"t5_pkey" PRIMARY KEY, btree (id, name)
Has OIDs: yes
Distribute By: SHARD(name)
Location Nodes: ALL DATANODES
--分布键字段长度不能修改,类型不能修改,分布键值不能修改。
postgres=# alter table t5 alter column name type varchar(100);
ERROR: cannot alter type of column named in distributed key
postgres=# alter table t1 alter column id type text;
ERROR: cannot alter type of column named in distributed key
postgres=# update t1 set id=10000 where id=1;
ERROR: Distributed column "id" can't be updated in current version
shard表-分区表
新建分区表,观察节点数据分布及分区使用情况。
postgres=# create table t1_pt(id int not null,name varchar(20),ct timestamp not null,primary key(id)) partition by range (ct) begin (timestamp without time zone '2020-01-01 0:0:0') step (interval '1 month') partitions (3) distribute by shard(id) to group default_group;
CREATE TABLE
postgres=# insert into t1_pt(id,name,ct) values (1,'n1','2020-01-01'),(2,'n1','2020-02-01'),(3,'n1','2020-03-01'),(4,'n1','2020-04-01'),(5,'n1','2020-05-01'),(6,'n1','2020-06-01');
COPY 6
postgres=# explain select * from t1_pt where ct >'2020-03-09';
QUERY PLAN
---------------------------------------------------------------------------
Remote Fast Query Execution (cost=0.00..0.00 rows=0 width=0)
Node/s: dn001, dn002
-> Seq Scan on t1_pt_part_2 (cost=0.00..18.25 rows=220 width=70)
Filter: (ct > '2020-03-09 00:00:00'::timestamp without time zone)
(4 rows)
shard表-冷热分区表
所谓冷热,就是所数据节点进行分组,业务历史数据查询更新少、数据量占用空间大的数据放到冷数据组。经常要用的数据放在热数据组。
- 新增dn003用来存放冷数据
- 配置冷数据规则并应用
- 观察冷热数据的节点分布及分区使用情况
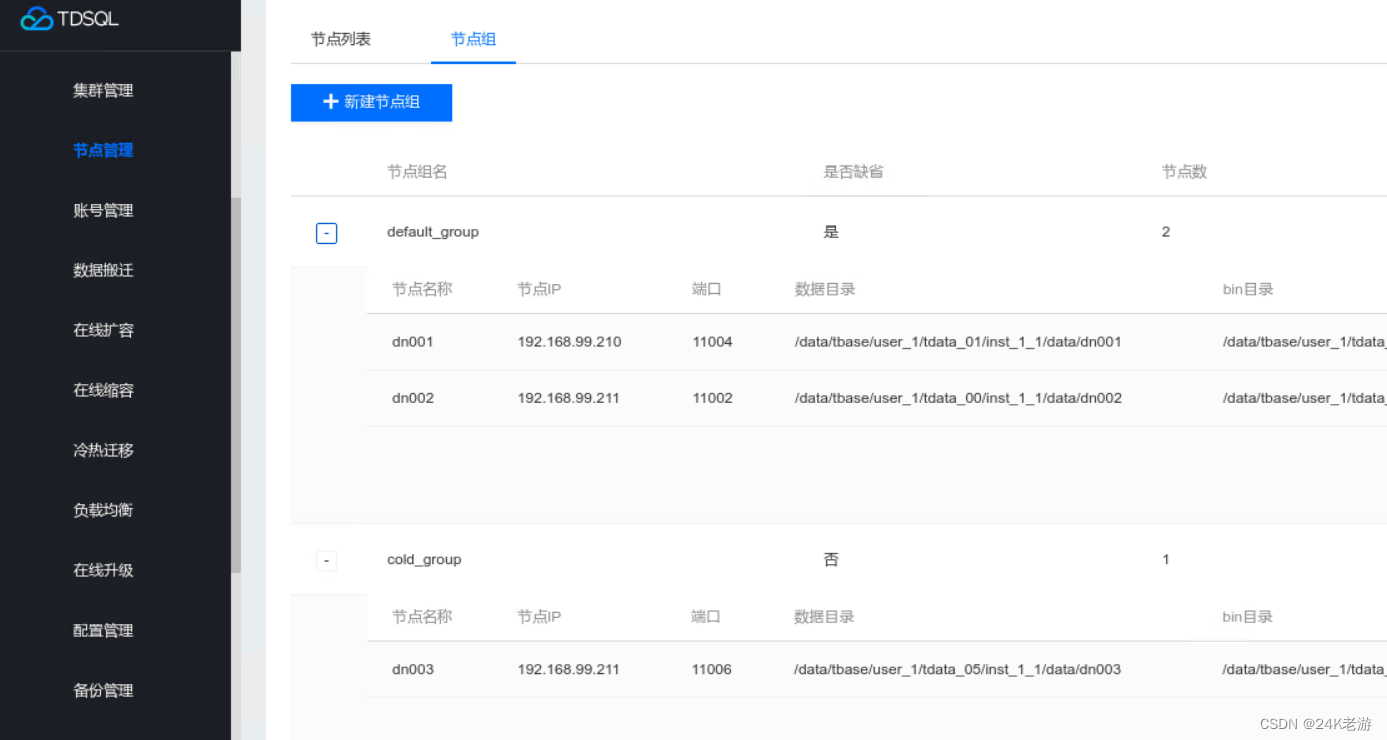
新增dn003节点注意事项:
通过oss平台新增节点需要先选择冷节点组,而新建节点组又要求最少选择一个DN节点,这就有了一个先有鸡还是先有蛋的问题。
解决办法:先扩容,新建一个DN节点,选择默认节点组。建立成功后再缩容,把新建的节点从默认节点组移出。最后新建冷节点组,把刚移出的DN节点加入即可。
最终状态如下图:
- 配置冷数据分隔模式
tdsql默认按年迁移冷热数据,但我们这个例子是按月迁移,所以需要修改分隔模式(cold_hot_sepration_mode)为月,所有cn和dn结点都要设置。
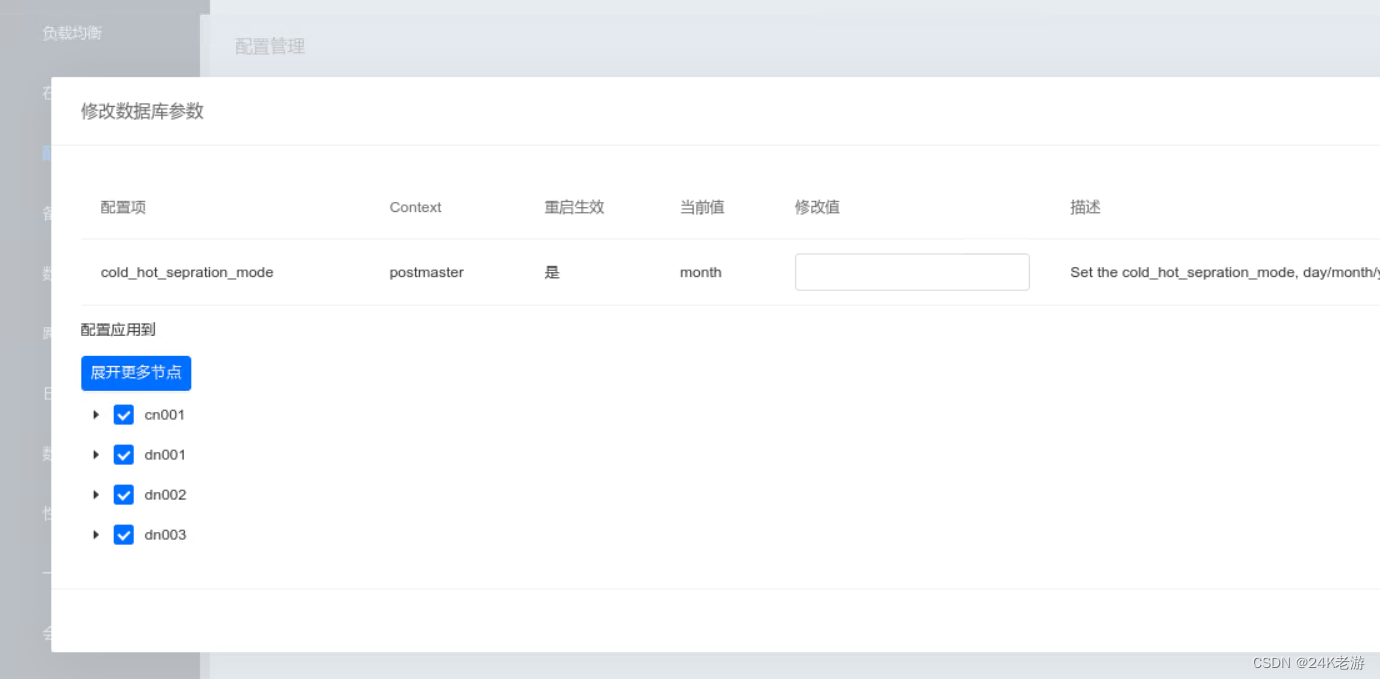
设置完成后,登录DN003数据节点,将DN003节点设置为冷数据节点,如果有多个冷数据节点,每个节点都要设置。因为新增的节点默认为热节点,所以热节点不用设置。
postgres=# select pg_set_node_cold_access();
pg_set_node_cold_access
-------------------------
success
(1 row)
- 配置迁移任务
建表并观察执行计划
postgres=# create table t2_pt(id int not null,name varchar(20),ct timestamp not null,primary key(id,ct)) partition by range (ct) begin (timestamp without time zone '2020-01-01 0:0:0') step (interval '1 month') partitions (3) distribute by shard(id,ct) to group default_group cold_group;
CREATE TABLE
postgres=#
postgres=#
postgres=# explain select * from t2_pt;
QUERY PLAN
----------------------------------------------------------------------
Remote Fast Query Execution (cost=0.00..0.00 rows=0 width=0)
Node/s: dn001, dn002, dn003
-> Seq Scan on t2_pt_part_2 (cost=0.00..16.60 rows=660 width=70)
(3 rows)
postgres=# explain select * from t2_pt where ct<'2020-02-01';
QUERY PLAN
---------------------------------------------------------------------------
Remote Fast Query Execution (cost=0.00..0.00 rows=0 width=0)
Node/s: dn003
-> Seq Scan on t2_pt_part_0 (cost=0.00..18.25 rows=220 width=70)
Filter: (ct < '2020-02-01 00:00:00'::timestamp without time zone)
(4 rows)
--如果分隔模式与分区时间类型不一致会报如下错:
postgres=# create table t2_pt(id int not null,name varchar(20),ct timestamp not null,primary key(id,ct)) partition by range (ct) begin (timestamp without time zone '2020-01-01 0:0:0') step (interval '1 month') partitions (3) distribute by shard(id,ct) to group default_group cold_group;
ERROR: cold-hot table shoule partition by year
复制表
复制表,每个DN点都会存放一份相同的数据。主要用于关联查询经常用上,且数据变化少的数据表,如配置表、维度表。
优点是可以大幅提高查询速度,缺点是因为要更新每个DN节点上相同的表,所以更新速度慢。
新建复制表,对比非普通表和复制表对联合查询的影响
--普通分布表
postgres=# create table t5_conf as select generate_series(1,26) id,chr(generate_series(65,65+25)) n,random() v;
INSERT 0 26
postgres=# \d+ t5_conf;
Table "public.t5_conf"
Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
--------+------------------+-----------+----------+---------+----------+--------------+-------------
id | integer | | not null | | plain | |
n | text | | | | extended | |
v | double precision | | | | plain | |
Has OIDs: yes
Distribute By: SHARD(id)
Location Nodes: dn001, dn002
--复制表
postgres=# create table t5_conf1(id int,n text,v double precision) distribute by replication;
CREATE TABLE
postgres=# insert into t5_conf1(id,n,v) select id,n,v from t5_conf;
INSERT 0 26
--主数据表
postgres=# create table t5_main as select generate_series(1,1000000) id,chr(cast(random()*24+65 as int)) n;
INSERT 0 1000000
postgres=# \d+ t5_main;
Table "public.t5_main"
Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
--------+---------+-----------+----------+---------+----------+--------------+-------------
id | integer | | not null | | plain | |
n | text | | | | extended | |
Has OIDs: yes
Distribute By: SHARD(id)
Location Nodes: dn001, dn002
--普通表查询分析
postgres=# explain analyze select a.n,sum(b.v) from t5_main a,t5_conf b where a.n=b.n group by a.n;
QUERY PLAN
----------------------------------------------------------------------------------------------------------------------------------------------
Remote Subquery Scan on all (dn001,dn002) (cost=58677.39..58677.51 rows=12 width=10) (actual time=999.343..999.357 rows=25 loops=1)
-> Finalize HashAggregate (cost=58677.39..58677.51 rows=12 width=10)
DN (actual startup time=995.012..995.610 total time=995.016..995.614 rows=11..14 loops=1..1)
Group Key: a.n
-> Remote Subquery Scan on all (dn001,dn002) (cost=58677.15..58677.33 rows=12 width=0)
DN (actual startup time=994.238..995.539 total time=994.936..995.543 rows=11..14 loops=1..1)
Distribute results by S: n
-> Partial HashAggregate (cost=58577.15..58577.27 rows=12 width=10)
DN (actual startup time=897.801..988.973 total time=897.806..988.976 rows=11..14 loops=1..1)
Group Key: a.n
-> Hash Join (cost=22570.00..48077.15 rows=2100000 width=10)
DN (actual startup time=592.270..595.007 total time=765.927..846.232 rows=457966..542034 loops=1..1)
Hash Cond: (b.n = a.n)
-> Remote Subquery Scan on all (dn001,dn002) (cost=100.00..128.10 rows=420 width=40)
DN (actual startup time=0.723..2.034 total time=2.071..2.251 rows=12..14 loops=1..1)
Distribute results by S: n
-> Seq Scan on t5_conf b (cost=0.00..9.20 rows=420 width=40)
DN (actual startup time=0.016..0.021 total time=0.022..0.032 rows=12..14 loops=1..1)
-> Hash (cost=12802.00..12802.00 rows=500000 width=2)
DN (actual startup time=588.587..591.360 total time=588.587..591.360 rows=457966..542034 loops=1..1)
Buckets: 131072 (originally 131072) Batches: 32 (originally 8) Memory Usage: 3795kB
-> Remote Subquery Scan on all (dn001,dn002) (cost=100.00..12802.00 rows=500000 width=2)
DN (actual startup time=20.078..24.626 total time=354.216..377.666 rows=457966..542034 loops=1..1)
Distribute results by S: n
-> Seq Scan on t5_main a (cost=0.00..9202.00 rows=500000 width=2)
DN (actual startup time=0.029..0.067 total time=161.704..185.476 rows=499436..500564 loops=1..1)
Planning time: 0.305 ms
Execution time: 1008.855 ms
(28 rows)
--复制表查询分析
postgres=# explain analyze select a.n,sum(b.v) from t5_main a,t5_conf1 b where a.n=b.n group by a.n;
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------------------------------------
HashAggregate (cost=91166.30..91166.42 rows=12 width=10) (actual time=1264.314..1264.321 rows=25 loops=1)
Group Key: a.n
-> Hash Join (cost=22570.00..70166.30 rows=4200000 width=10) (actual time=607.966..1009.806 rows=1000000 loops=1)
Hash Cond: (b.n = a.n)
-> Remote Subquery Scan on all (dn001) (cost=100.00..156.20 rows=840 width=40) (actual time=0.671..0.732 rows=26 loops=1)
-> Seq Scan on t5_conf1 b (cost=0.00..18.40 rows=840 width=40)
DN (actual startup time=0.022..0.022 total time=0.029..0.029 rows=26..26 loops=1..1)
-> Hash (cost=12802.00..12802.00 rows=500000 width=2) (actual time=605.933..605.933 rows=1000000 loops=1)
Buckets: 131072 (originally 131072) Batches: 32 (originally 8) Memory Usage: 4152kB
-> Remote Subquery Scan on all (dn001,dn002) (cost=100.00..12802.00 rows=500000 width=2) (actual time=1.056..204.799 rows=1000000 loops=1)
-> Seq Scan on t5_main a (cost=0.00..9202.00 rows=500000 width=2)
DN (actual startup time=0.043..0.073 total time=123.018..127.203 rows=499436..500564 loops=1..1)
Planning time: 0.200 ms
Execution time: 1267.510 ms
(14 rows)
可以看到普通表比复制表需要更多的远端查询操作。
















 5482
5482

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











