









文章目录
1. 索引就是目录
以使用新华字典为例,假如我们要查汉字“库”,如果没有索引(目录),我们就需要在厚厚的一本新华字典中找到那个字,尽管由于新华字典的汉字条目是根据拼音有序排布的,我们可以比较快的查找到这个汉字,但是我们还是不可避免的要翻动很多次页面,在数据库中,这个翻动页面并查看该页中是否包含“页”字是很费时的事情。
有了目录之后呢?假设目录有10页,我们最多翻动10次页面,就可以精确定位到这个“库”字具体在哪一页,然后只管翻到哪一页就好了。
所以说,数据库中建立索引,就相当于给新华字典建立目录。有了索引我们在查找一条记录的时候,就不用在遍历整个数据库表,我们只要遍历一遍索引,就可以精确定位记录在磁盘中的位置,然后就去取出即可。这样为什么可以节约时间呢?这是因为索引比实际记录少了很多无用的内容,就像新华字典的目录中只描述了每一个汉字和其所在的页码,而并不会记录每个汉字是什么意思如何组词造句一样。
进一步对比,我们发现新华字典的目录中的汉字排布也是按照拼音有序的,这其实可以加速我们查索引的过程,而并不需要遍历整个索引。
2. 查询代价指标------I/O次数
数据是存储在磁盘中的,磁盘是有一个个扇区组成的,但是操作系统和dbms在存取数据的时候,并不是按照扇区来存取的,而是按照block也就是磁盘块来存取的,block是一个逻辑单位,这个概念可以认为是软件实现的,这就类似于在港口运输货物的时候,我们是以集装箱而不是内部的小箱子为单位一样,显然这样更容易管理,也就是说我取数据的时候至少取一个block,存数据(写数据)的时候至少存一个block,这既方便又可以起到批量传输的效果。
我们可以简单地将计算机的存储器分为内存和外存,外存就是磁盘(也叫硬盘),包括固态硬盘和机械硬盘,内存就是cpu可以直接操作的存储器。前面说过数据是存放在磁盘中的,或者说是存放在硬盘中的,而我们要对数据库进行修改的时候,就是要将数据从磁盘读取到内存,然后在内存中进行处理,最后再写回磁盘中。也就是分3步,input,process,output,其中我们查询代价的指标就是第一步和第三步的次数总和,也就是常说的I/O次数。I/O的对象是什么呢?是block。为什么要以I/O次数作为代价指标呢?最主要的原因就是I/O的速度要比处理的速度慢得多,也就是说在数据库操作中I/O的时间通常要比process的时间长得多。另一个原因是:一般而言一个dbms系统中的所有block是一样大小的,因此理论上如果I/O次数一样的话,实际执行时间也应该差不多,而不会说由于block不一样大,你这个I/O3个block的实际执行时间比我这个I/O 30个block的时间还长,尽管这种情况的确是可能存在的,因为我们这里的block其实是指dbms的block,而dbms是建立在操作系统上的,而操作系统也有block,dbms的block通常是操作系统的block的偶数倍。
3. 数据库索引如何减少I/O次数
通过回答这个问题来解释什么是索引以及索引有哪些种类。
3.1 顺序文件上的索引结构
-
1.什么是顺序文件?就是按照记录逻辑顺序来存储的文件。新华字典的正文就是典型的顺序文件,并且是不定长记录的顺序文件。如果我们把新华字典的正文每一页都撕下来,打乱顺序再装订,然后重新写上页码,然后更新目录中每个汉字的页码,这时候新华字典的正文就是一个随机文件,此时如果没有一个合适的目录,就很难找到一个给定的汉字了。
-
2.如果是顺序文件,他的索引结构是什么样的呢?就像新华字典的拼音目录一样,在索引中省去所有无关的内容,只保留汉字和相应页码。也就是说索引文件和实际记录相比,省去了除了查找键之外的所有内容,再加上相应的地址(页码)。很显然,索引(目录)本身所占的空间要少的多。具体的,顺序文件的索引可以分为密集索引和稀疏索引。
2.1 密集索引 每个记录都有一个索引项,索引项按查找键排序

新华字典的目录就是密集索引。
缺点:占用空间比较大。
2.2 稀疏索引 为每一个块的第一个记录建立索引项
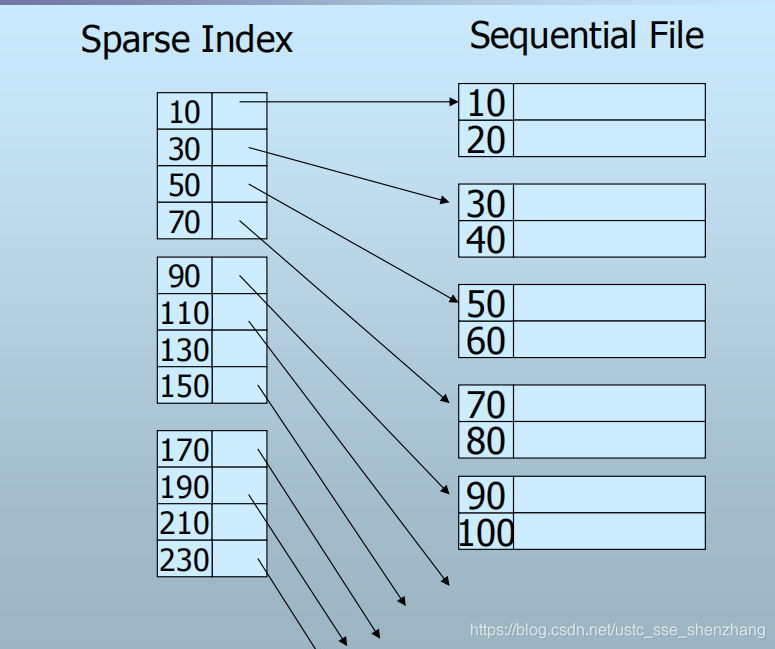
优点:索引项更少,索引本身所占空间更少。
缺点:对于“查找是否存在键值为K的记录”,可能需要读取磁盘数据块,而如果是密集索引,则不用读取数据块。2.3 多级索引
好处:- 一级索引可能还太大而不能常驻内存
- 二级索引更小,可以常驻内存
- 减少磁盘I/O次数
注意:
- 二级索引一定是稀疏索引,这也能推出一级索引本身一定是顺序文件
- 一般不考虑3级以上的多级索引,因为索引结构维护代价高,并且有更好的索引多级索引结构:B+树。
3.2 非顺序文件上的索引结构
首先看一下主索引和辅助索引的区别:

可见前面所说均为主索引,辅助索引也是索引,只不过他是相对于主索引而言的。举例而言,我们可能按照学号给学生表建立索引,那么学生表记录就是按照学号有序存储在磁盘中的,但是既然按照学号有序了,那么已经存储好的学生记录,就大概率不是按照成绩有序的,这个时候如果经常查找某个成绩的学生,就可以在成绩字段上建立索引,但是这个索引显然只能是密集索引,因为索引值在磁盘块中是无序的,在索引表中少了一项,对于那一项就无法定位了。而不像顺序文件那样可以通过一个索引值定位所在的磁盘块。
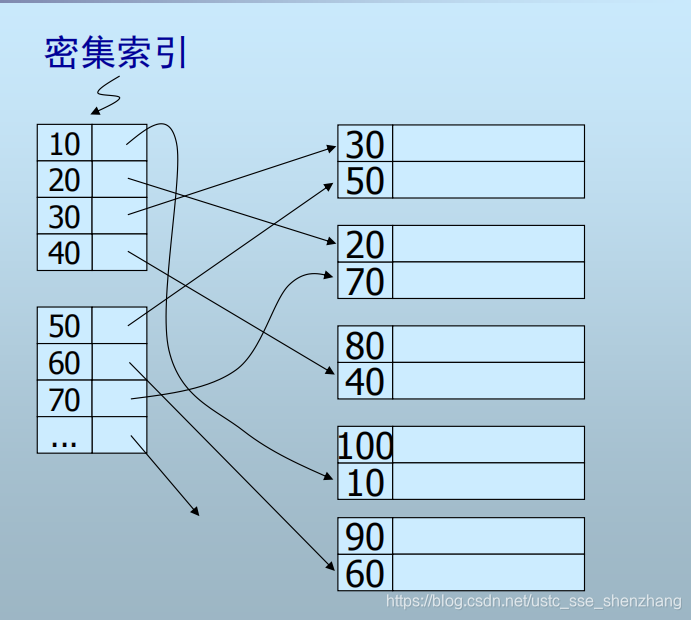
而这个密集索引表本身,可以是按照查找键有序的。
也就是说这个索引表本身是一个顺序文件,因此可以在其上建立二级稀疏索引。
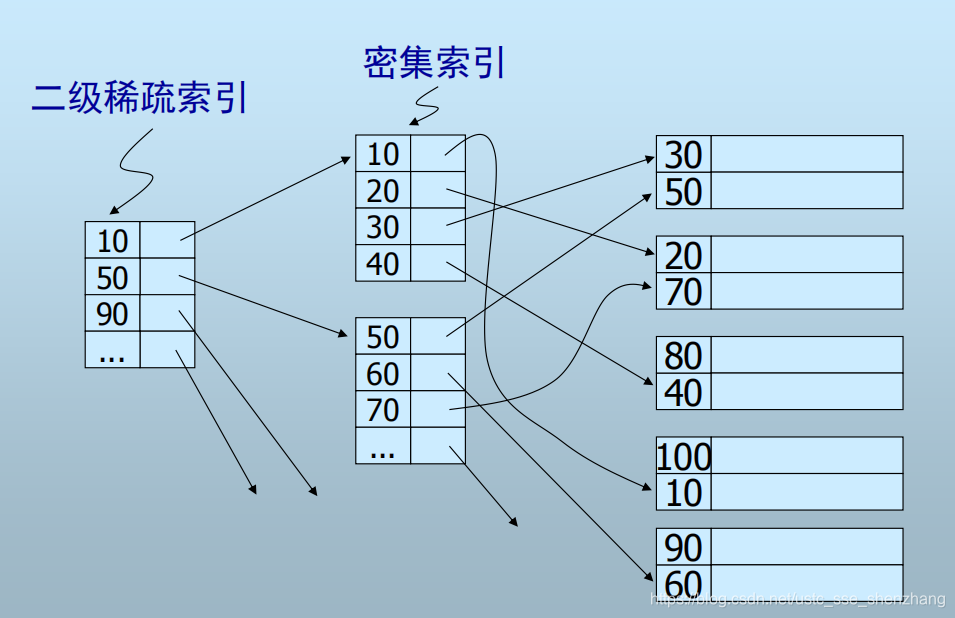
另一方面,由于辅助索引的字段并不是主键,就可能有大量重复,而辅助索引有必须是密集的,因此这可能会导致空间浪费。-----我们采用间接桶的办法:
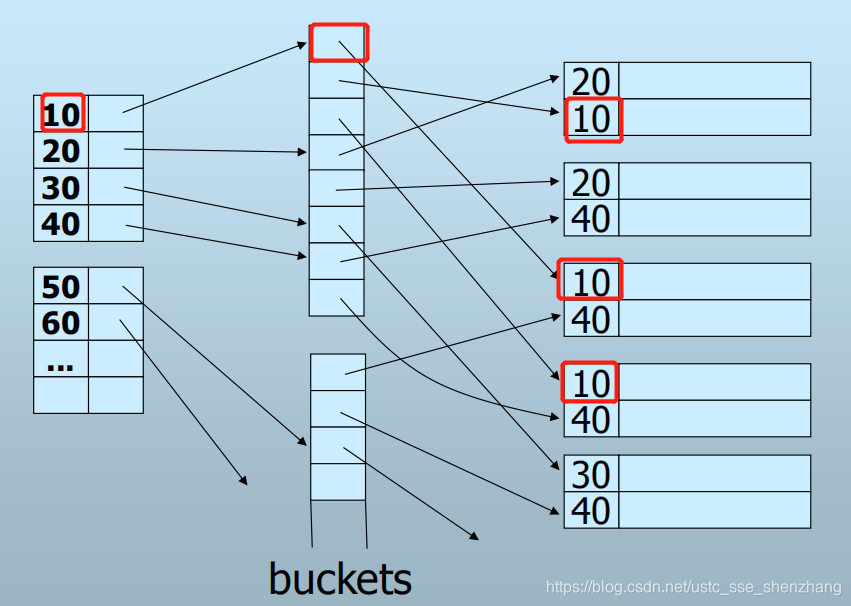
3.3 B+树
- 一种多级索引结构
- 所有节点的格式相同:n个值和n+1个指针。
- 所有叶节点位于同一层
- 适用于主索引,也可用于辅助索引
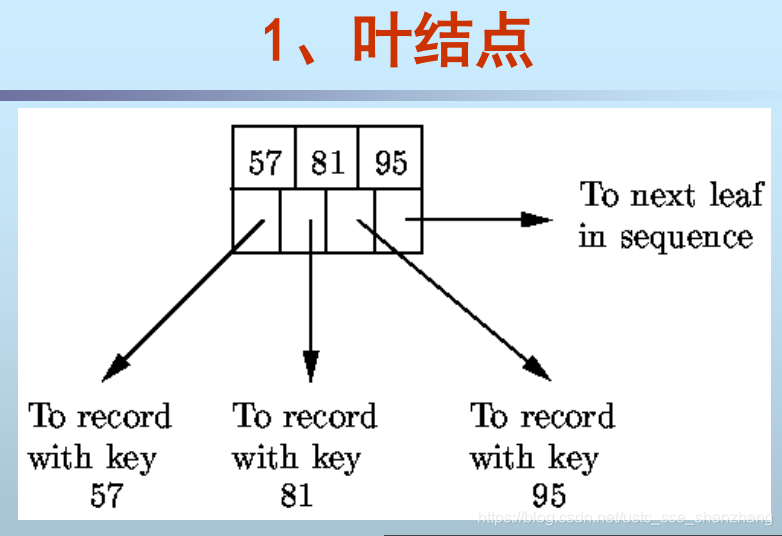
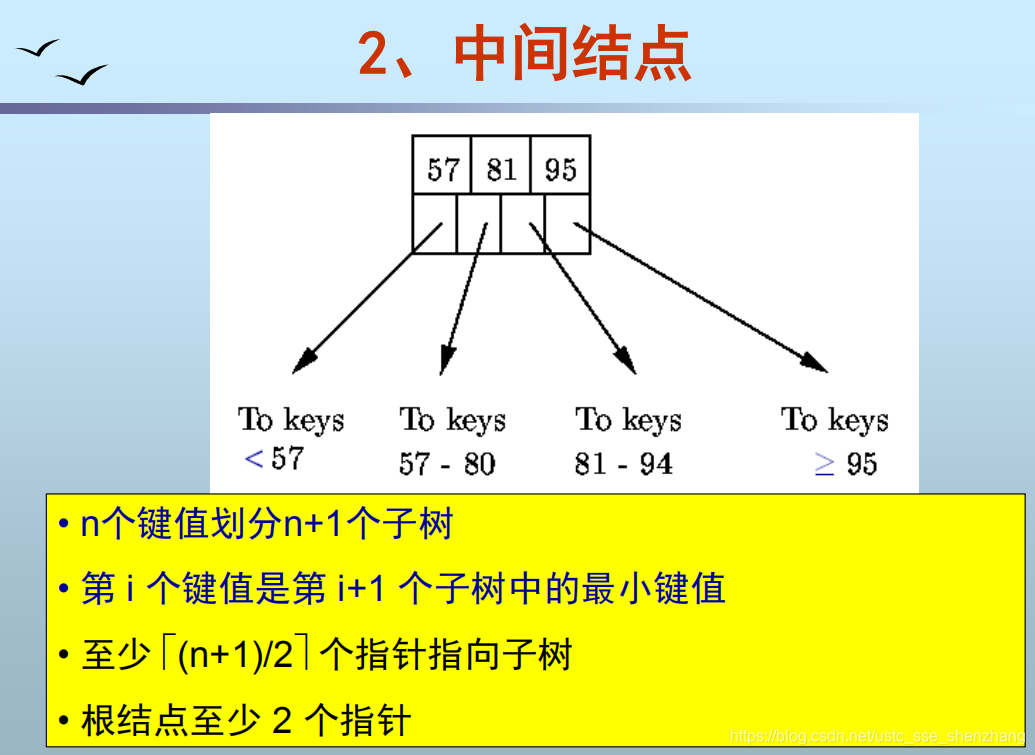
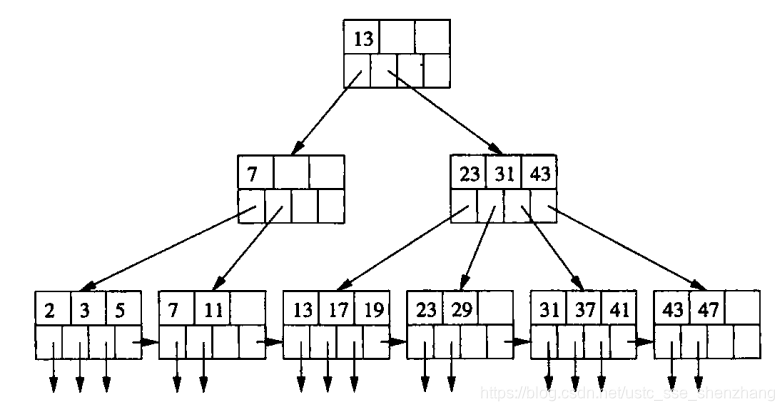
B+树的查找
从根节点开始往下,小的往左,大的往右,直至页节点,最后在页节点中顺序查找。
B+树的插入
- 先查找到插入节点
- 若页节点中有空闲位置,则插入
- 若没有空闲位置,则分裂叶节点
3.1 页节点的分裂可视作父节点中插入一个子节点
3.2 递归向上分裂
3.3 分裂过程中需要对父节点中的键加以调整
补充:若根节点分裂,则需要创建一个新的根节点,也就使得层数+1.
B+树的删除
- 直接查找到要删除的键值,然后删掉
- 若节点的键值填充低于规定值(太少了,要增加),则需要调整
2.1 若相邻的叶节点中的键值填充高于规定值,则将其中一个键值移到该节点中。
2.2 否则,也就是说相邻的也节点的填充度都不高,那就与相邻节点合并。(可以视作在父节点中删除一个子节点)
2.3 递归向上删除。 - 若删除的是叶节点中的最小键值,则需对父节点的键值加以调整。
以下举例说明
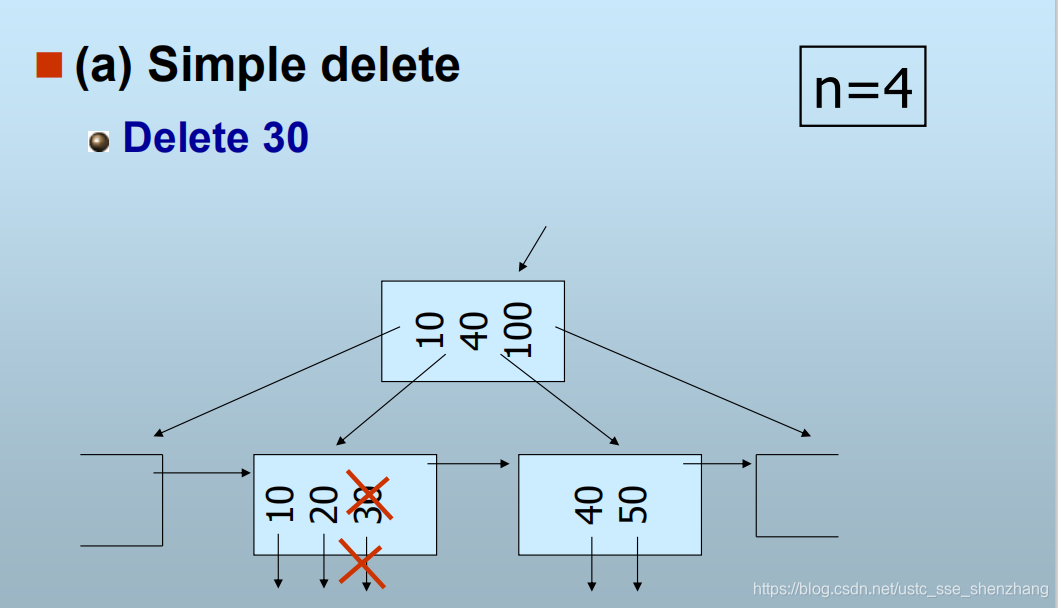
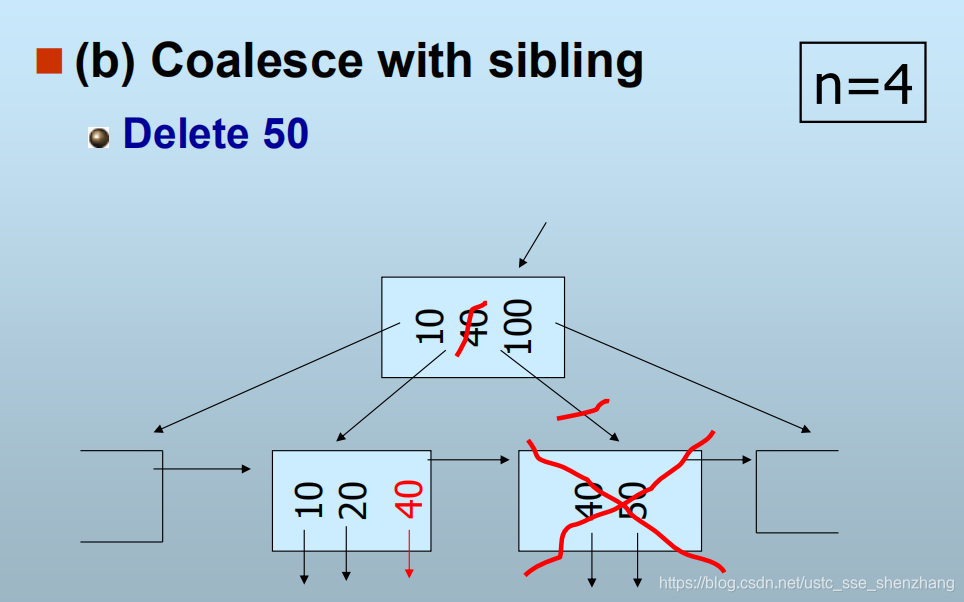
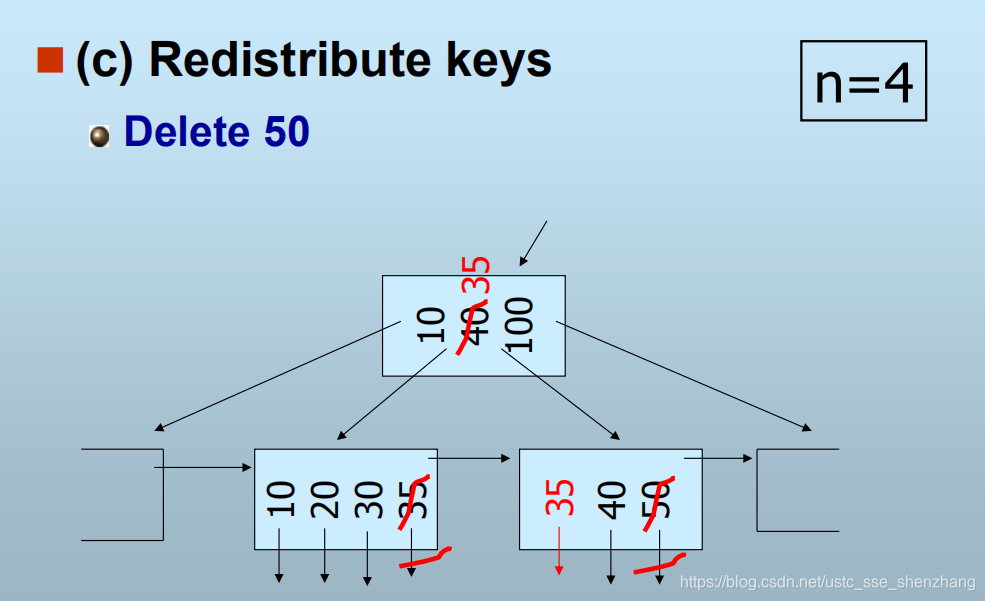
总之,B+树就是这样一种数据结构,是一种软件实现的逻辑结构。这样的结构是用来存储索引表本身的。
B+树的效率
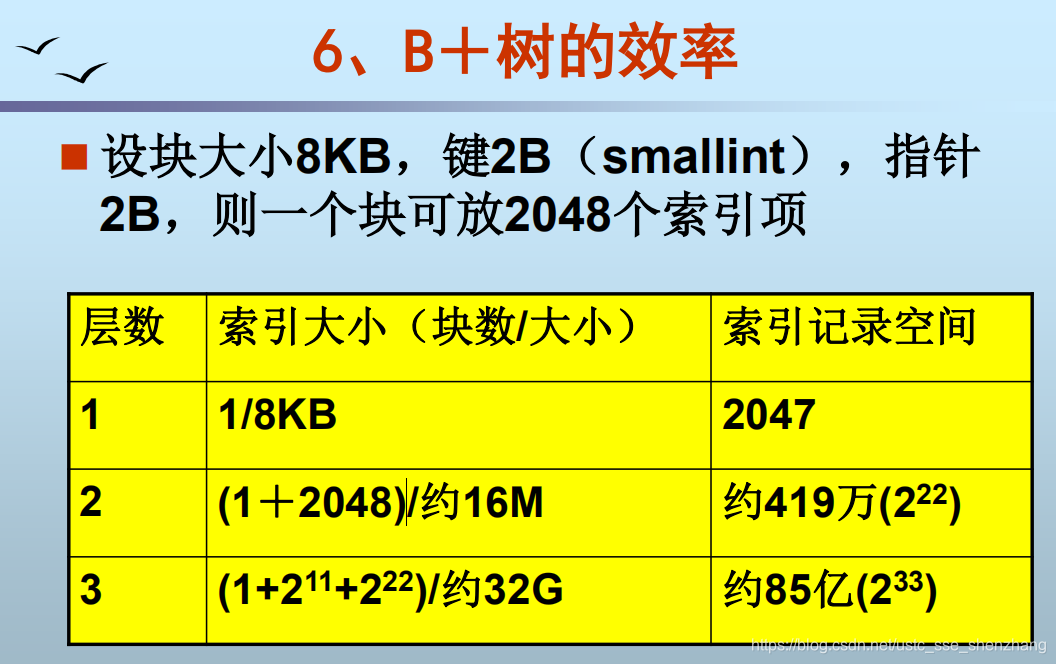
这样的一个三层的B+树,可以索引32G个block,每个block假设为16KB,则可以索引512TB的硬盘空间。
3.4 散列表
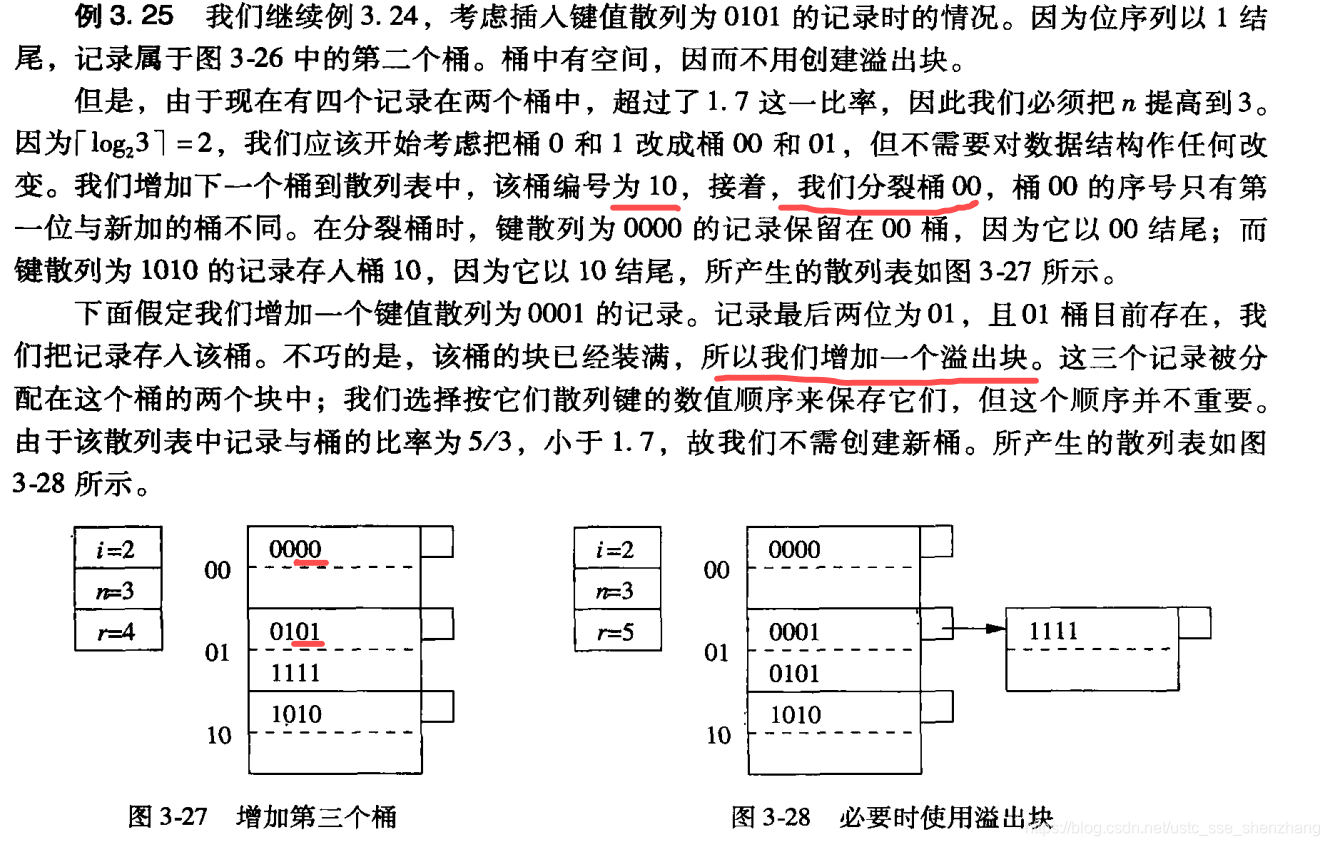
可扩展散列表

数据块中4位的二进制序列就是散列函数的值。
下面通过举例来说明散列函数的插入和删除。


优点
- 查找记录时,只需查找一个数据块。
缺点
- 桶是翻倍增长的,可能占用太多内存。
- 桶数组的翻倍需要做很多工作。
线性散列表




4. 总结
以上介绍了为什么需要索引,以及一些常见的索引类型(密集的、稀疏的、主索引、辅助索引)、逻辑结构(B+树、散列表)。
首先我们从直观上懂得了为什么需要索引---------为了减少I/O次数,从而节约时间。
其次具体的,针对数据在磁盘中的不同组织形式(顺序的or随机的),我们可以创建不同的逻辑结构的索引,从而方便我们对数据的增删改查。
最后我们具体介绍了两种常见的、重要的索引数据结构:B+树和散列表及其操作。这二者都是一种逻辑结构,也就是说他们都是逻辑上的概念,最终我们是通过代码去实现这样的逻辑结构的。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









