






Label Enhancement by Maintaining Positive and Negative Label Relation
method
基于保持正负标签关系的LE算法,该算法包含了一种新颖的排序损失,可以根据不同的排序误差产生不同的惩罚。
motivation
大多数LE算法在增强过程中忽略了维护正、负标签的排序关系,从而导致了大量的正、负标签排序误差。
某些LE算法使用包含最小二乘损失函数(LS)
L
(
θ
^
)
=
∑
i
=
1
n
∥
d
^
i
−
l
i
∥
\mathcal{L}(\hat{\theta})=\sum_{i=1}^n\Big\lVert \hat{d}_i-l_i\Big\rVert
L(θ^)=∑i=1n∥∥∥d^i−li∥∥∥,可以保证拟合度。但是,只考虑拟合程度是非常片面和不合理的。

用P-N排序错误来表示正负标签排序错误
output model
特征空间与标签空间线性相关
D
^
=
X
W
+
b
\hat{D}=XW+b
D^=XW+b
W
W
W是权重矩阵,
W
^
=
[
W
;
b
]
,
ϕ
(
x
i
)
=
[
x
i
,
1
]
\hat{W}=[W;b],\phi(x_i)=[x_i,1]
W^=[W;b],ϕ(xi)=[xi,1]
目标函数
min
W
^
=
L
(
W
^
)
+
λ
R
(
W
^
)
s
.
t
.
D
^
≥
0
n
×
c
\min_{\hat{W}}=L (\hat{W})+\lambda R(\hat{W}) \\ s.t. \hat{D}\ge0_{n\times c}
W^min=L(W^)+λR(W^)s.t.D^≥0n×c
L
L
L是损失函数,
R
R
R是用来约束正负标签之间排序关系的函数,
0
n
×
c
0_{n\times c}
0n×c是一个零矩阵
损失函数
L = ∑ i = 1 n ∥ d ^ i − l i ∥ 2 L=\sum_{i=1}^n\lVert\hat{d}_i-l_i\rVert^2 L=i=1∑n∥d^i−li∥2
成对排序损失
每个正标签对应的标签分布值应大于任何负标签对应的标签分布值
d
^
i
p
>
d
^
i
m
∀
p
∈
Y
i
+
,
m
∈
Y
i
−
\hat{d}_i^p>\hat{d}_i^m \quad \forall p\in Y_i^+,m\in Y_i^-
d^ip>d^im∀p∈Yi+,m∈Yi−
R
h
i
n
=
1
N
∑
i
=
1
N
∑
p
∈
Y
i
+
∑
m
∈
Y
i
−
m
a
x
(
0
,
α
+
d
^
i
m
−
d
^
i
p
)
R_{hin}=\frac{1}{N}\sum_{i=1}^N\sum_{p\in Y_i^+}\sum_{m\in Y_i^- }max(0,\alpha+\hat{d}_i^m-\hat{d}_i^p)
Rhin=N1i=1∑Np∈Yi+∑m∈Yi−∑max(0,α+d^im−d^ip)
α
\alpha
α是决定边际的超参数
hinge function
上面的铰链函数形式是非光滑的,使用指数函数和对数函数来平滑逼近
R l s e = 1 N ∑ i = 1 N log ( 1 + ∑ p ∈ Y i + ∑ m ∈ Y i − exp ( d ^ i m − d ^ i p ) ) R_{lse}=\frac{1}{N}\sum_{i=1}^N \log(1+\sum_{p\in Y_i^+}\sum_{m\in Y_i^- }\exp(\hat{d}_i^m-\hat{d}_i^p)) Rlse=N1i=1∑Nlog(1+p∈Yi+∑m∈Yi−∑exp(d^im−d^ip))
四种不同的P-N排序错误。
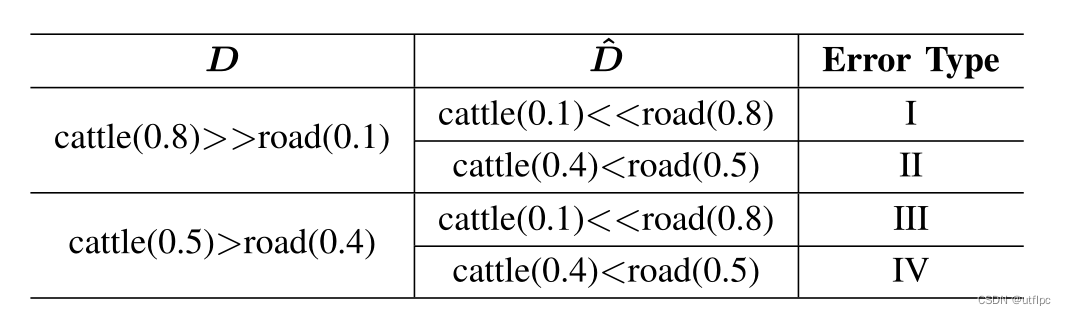
为了使不同d额P-N排名错误受到轻重不同惩罚,使用 ∣ d i p − d i m ∣ ⋅ ∣ d ^ i p − d ^ i m ∣ |d_i^p-d_i^m |\cdot |\hat{d}_i^p-\hat{d}_i^m| ∣dip−dim∣⋅∣d^ip−d^im∣来衡量惩罚
局部标签相关性
因为真实标签分布未知,使用标签相关性来反映两个标签的真实标签分布值之间的差值,同时因为成对排序损失函数是特定于一个实例的,为了减少误差,使用局部标签相关性。
[
S
g
]
i
j
=
l
g
,
i
,
:
l
g
,
j
,
:
T
∥
l
g
,
i
,
:
∥
∥
l
g
,
j
,
:
∥
[S_g]_{ij}=\frac{l_{g,i,:}l^T_{g,j,:}}{\lVert l_{g,i,:}\rVert \lVert l_{g,j,:}\rVert}
[Sg]ij=∥lg,i,:∥∥lg,j,:∥lg,i,:lg,j,:T
l
g
,
i
,
:
l_{g,i,:}
lg,i,:表示
L
g
L_g
Lg的第i列,
L
g
L_g
Lg是集群
X
g
X_g
Xg的逻辑标签集。
R l s e = 1 N ∑ i = 1 N log ( 1 + ∑ p ∈ Y i + ∑ m ∈ Y i − exp ( − [ S g ] p m ) exp ( d ^ i m − d ^ i p ) ) R_{lse}=\frac{1}{N}\sum_{i=1}^N \log(1+\sum_{p\in Y_i^+}\sum_{m\in Y_i^- }\exp(-[S_g]_{pm})\exp(\hat{d}_i^m-\hat{d}_i^p)) Rlse=N1i=1∑Nlog(1+p∈Yi+∑m∈Yi−∑exp(−[Sg]pm)exp(d^im−d^ip))
最终的目标函数
min W ^ = ∑ i = 1 n ∥ d ^ i − l i ∥ 2 + λ 1 N ∑ i = 1 N log ( 1 + ∑ p ∈ Y i + ∑ m ∈ Y i − exp ( − [ S g ] p m ) exp ( d ^ i m − d ^ i p ) ) s . t . D ^ ≥ 0 n × c \min_{\hat{W}}=\sum_{i=1}^n\lVert\hat{d}_i-l_i\rVert^2+\lambda \frac{1}{N}\sum_{i=1}^N \log(1+\sum_{p\in Y_i^+}\sum_{m\in Y_i^- }\exp(-[S_g]_{pm})\exp(\hat{d}_i^m-\hat{d}_i^p))\\ s.t. \hat{D}\ge0_{n\times c} W^min=i=1∑n∥d^i−li∥2+λN1i=1∑Nlog(1+p∈Yi+∑m∈Yi−∑exp(−[Sg]pm)exp(d^im−d^ip))s.t.D^≥0n×c


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









