








开篇
性能优化是一个很复杂的工作,且充满了不确定性。它不像Java业务代码,可以一次编写到处运行(write once, run anywhere),往往一些我们可能并不能察觉的变化,就会带来惊喜/惊吓。能够全面的了解并评估我们所负责应用的性能,我认为是提升技术确定性和技术感知能力的非常有效的手段。本文尽可能简短的总结我自己在性能优化上面的一些体会和经验,从实践的角度出发尽量避免过于啰嗦和生硬,但相关的知识实在太多,受限于个人经验和技术深度,不足之外还请大家补充。
第1部分是偏背景类知识的介绍,有这方面知识的同学可以直接跳过。
1. 了解运行环境
大多数的编程语言(尤其是Java)做了非常多的事情来帮助我们不用太了解硬件也能很容易的写出正确工作的代码,但你如果要全面了解性能,却需要具备不少的从硬件、操作系统到软件层面的知识。
1.1 服务器
目前我们大量使用Intel 64位架构的Xeon处理器,除此之外还会有AMD x64处理器、ARM服务器处理器(如:华为鲲鹏、阿里倚天)、未来还会有RISC-V架构的处理器、以及一些专用FPGA芯片等等。我们这里主要聊聊目前我们大量使用的阿里云ECS使用的Intel 8269CY处理器。
1.1.1 处理器
Intel Xeon Platinum 8269CY,阿里云使用的这一款处理器是阿里定制款,并不能在Intel的官方手册中查询到,不过我们可以通过下方Intel处理器的命名规则了解到不少的信息,它是一款这样的处理器:主频2.5GHz(睿频3.2GHz、最大睿频3.8GHz),26核心52线程(具备超线程技术),6通道DDR4-2933内存,最大配置内存1T,Cascade Lake微架构,48通道PCI-E 3.0,14nm光刻工艺,205W TDP。它是这一代至强处理器中性能比较强的型号了,最大支持8路部署。
具备动态自动超频的能力将能够短时间提升性能,同时在少数核心忙碌的时候还可以让它们保持长时间的自动超频,这会严重的影响我们对应用性能的评估(少量测试时性能很好,大规模测试时下降很厉害)。
最大配置内存1TB,代表处理器具备48bit的VA(虚拟地址),也就是通常需要四级页表(下一代具备57bit VA的处理器已经在设计中了,通常需要五级页表),过深的页表显然是极大的影响内存访问的性能以及占用内存(页表也是存储在内存中的)的,所以Intel设计了大页(2MB、1GB大页)机制,以减少过深的页表带来的影响。6通道2933MHz的内存总线代表它具备总计约137GB/s(内存总线是64bit位宽)的宽带,不过需要记住他们是高度并行设计的。

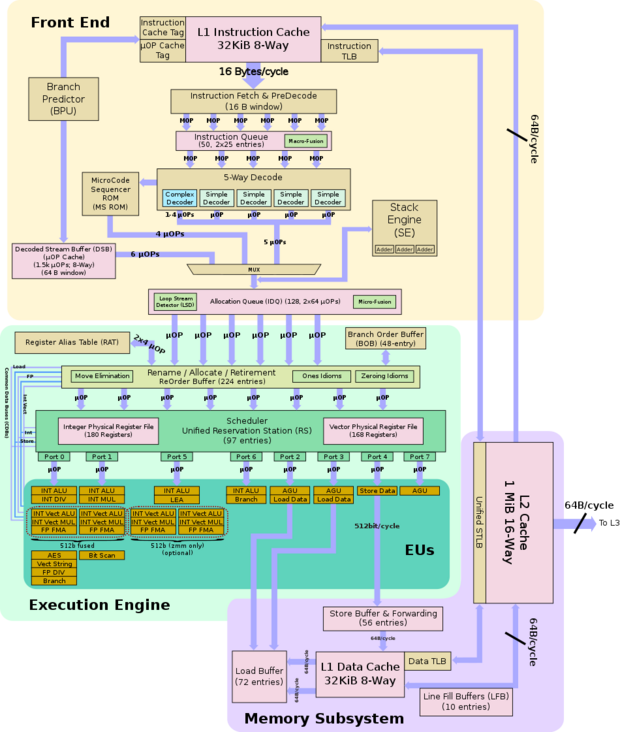
这个微处理的CPU核架构如下图所示,采用8发射乱序架构, 32KB指令+32KB数据 L1 Cache,1MB L2 Cache。发射单元是CPU内部真正的计算单元,它的多少是CPU性能的关键因素。8个发射单元中有4个单元都可以进行基本整数运算(ALU单元),只有2个可以进行整数乘除和浮点运算,所以对于大量浮点运算的场景并行效率会偏低。1个CPU核对应的2个HT(这里指超线程技术虚拟出的硬件线程)是共享8个发射单元的,所以这两个HT之间将会有非常大的相互影响(这也会导致操作系统内CPU的使用率不再是线性值,具体请查阅相关资料),L1、L2 Cache同样也是共享的,所以也会相互影响。
Intel Xeon处理器在分支预测上面花了很多功夫,所以在较多分支代码(通常就是if else这类代码)时性能往往也能做的很好,比大多数的ARM架构做的都要好。Java常用的指针压缩技术也受益于x86架构灵活的寻址能力(如:mov eax, ecx * 8 + 8),可以一条指令完成,同时也不会带来性能的损失,但是这在ARM、RISC-V等RISC(精简指令集架构,Reduced Instruction Set Computing)处理器上就不适用了。
从可靠渠道了解道,下一代架构(Sunny Cove)将大幅度的进行架构优化,升级为10发射,同时L1 Cache将数据部分增加到48KB,这代表接下来的处理器将更加侧重于提升SIMD(单指令多操作数,Signle Instruction Multiple Data)等的数据计算性能。
一颗8269CY内部有26个CPU核,采用如下的拓扑结构进行连接。这一代处理器最多有28个CPU核,8269CY屏蔽掉了2个核心,以降低对产品良率的要求(节约成本)。可以看到总计35.75MB的L3 Cache(图中为LLC: Last Level Cache)被分为了13块(图中是14块,屏蔽2个核心的同时也屏蔽了与之匹配的L3 Cache),每块2.75MB,并不是简单意义理解上的是一大块统一的区域。6通道的内存控制器也分布在左右两侧,与实际主板上内存插槽的位置关系是对应的。这些信息都告诉我们,这是一颗并行能力非常强的多核心处理器。
1.1.2 服务器
阿里云通常都是采用双Intel处理器的2U机型(基于散热、密度、性价比等等的考虑),基本都是2个NUMA(非一致性内存访问,Non Uniform Memory Access)节点。具体到Intel 8269CY,代表一台服务器具备52个物理核心,104个硬件线程,通常阿里云会称之为104核。NUMA技术的出现是硬件工程师的妥协(他们实在没有能力做到在多CPU的情况下还能实现访问任何地址的性能一致性),所以做的不好也会严重的降低性能,大多数情况下虚拟机/容器调度团队要做的是将NUMA打开,同时将一个虚拟机/容器部署到同一个NUMA节点上。
这几年AMD的发展很好,它的多核架构与Intel有很大的不同,不久的将来阿里云将会部署不少采用AMD处理器的机型。AMD处理器的NUMA节点将会更多,而且拓扑关系也会更复杂,阿里自研的倚天(采用ARM架构)就更复杂了。这意味着虚拟机/容器调度团队够得忙了。
多数情况下服务器大都采用CPU:内存为1:2或1:4的配置,即配置双Intel 8269CY的物理机,通常都会配备192GB或384GB的内存。如果虚拟机/容器需要的内存:CPU过大的情况下,将很难实现内存在CPU对应的NUMA节点上就近分配了,也就是说性能就不能得到保证。
由于2U机型的物理高度是1U机型的2倍,所以有更多的空间放下更多的SSD盘、高性能PCI-E设备等。不过云厂商肯定是不愿意直接将物理机卖给用户(毕竟他们已经不再是以前的托管物理机公司)的,再怎么也得在上面架一层,也就是做成ECS再卖给客户,这样诸如热迁移、高可用等功能才能实现。前述的"架一层"是通过虚拟化技术来实现的。
1.1.3 虚拟化技术
一台物理机性能很强大,通常我们只需要里面的一小块,但我们又希望不要感知到其他人在共享这台物理机,所以催生了虚拟化技术(简单来说就是让可以让一个CPU工作起来就像多个CPU并行运行,从而使得在一台服务器内可以同时运行多个操作系统)。早期的虚拟机技术是通过软件实现的,老牌厂商如VMWare,但是性能牺牲的有点多,硬件厂商也看好虚拟机技术的前景,所以便有了硬件虚拟化技术。
各厂商的实现并不相同,但差异不是很大,好在有专门的虚拟化处理模块去兼容就可以了。Intel的虚拟化技术叫Intel VT(Virtualization Technology),它包括VT-x(处理器的虚拟化支持)、VT-d(直接I/O访问的虚拟化)、VT-c(网络连接的虚拟化),以及在网络性能上的SR-IOV技术(Single Root I/O Virtualization)。
这里面一个很重要的事情是,原本我们访问内存的一层转换(线性地址->物理地址)会变成二层转换(VM内线性地址->Host线性地址->物理地址),这会引入更多的内存开销以及页表的转换工作。所以大多数云厂商会在Host操作系统上开启大页(Linux 操作系统通常是使用透明大页技术),以减少内存相关的虚拟化开销。
服务器对网络性能的要求是很高的,现在的网络硬件都支持网卡多队列技术,通常情况下需要将VM中的网络中断分散给不同的CPU核来处理,以避免单核转发带来的性能瓶颈。
Host操作系统需要管理它上面的一个或多个VM(虚拟机,Virtual Machine),以及前述提及的处理网卡中断,这会带来一定的CPU消耗。阿里云上一代机型,服务器总计是96核(即96个硬件线程HT,实际是48个物理核),但最多只能分配出88核,需要保留8个核(相当于物理机CPU减少8.3%)给Host操作系统使用,同时由于I/O相关的虚拟化开销,整机性能会下降超过10%。
阿里云为了最大限度的降低虚拟化的开销,研发了牛逼的“弹性裸金属服务器 - 神龙”,号称不但不会因为虚拟化降低性能,反而会提升部分性能(主要是网络转发)。
1.1.4 神龙服务器
为了避免虚拟化对性能的影响,阿里云(类似还有亚马逊等云厂商的类似方案)研发了神龙服务器。简单来说就是设计了神龙MOC卡,将大部分虚拟机管理工作、网络中断处理等从CPU offload到MOC卡进行处理。神龙MOC卡是一块PCI-E 3.0设备,其内有专门设计的用于网络处理的FPGA芯片,以及2颗低功耗的x86处理器(据传是Intel Atom),最大限度的接手Host操作系统的虚拟化管理工作。通过这样的设计,在网络转发性能上甚至能做到10倍于裸物理机,做到了当之无愧的裸金属。104核的物理机可以直接虚拟出一台104核的超大ECS,再也不用保留几个核心给Host操作系统使用了。
1.2 VPC
VPC(虚拟专有云,Virtual Private Cloud),大多数云上的用户都希望自己的网络与其它的客户隔离,就像自建机房一样,这里面最重要的是网络虚拟化技术,目前阿里云采用的是VxLAN协议,它底层采用UDP协议进行数据传输,整体数据包结构如下图所示。VxLAN在VxLAN帧头中引入了类似VLAN ID的网络标识,称为VxLAN网络标识VNI(VxLAN Network ID),由24比特组成,理论上可支持多达16M的VxLAN段,从而满足了大规模不同网络之间的标识、隔离需求。这一层的引入将会使原始的网络包增加50 Bytes的固定长度的头。当然,还需要与之匹配的交换机、路由器、网关等等。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 493
493











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









