






分析cpu使用率
使用top、或pidstat命令查看进程的cpu使用情况。

PID为进程id, %CPU为进程消耗的cpu百分比, 默认是按照百分比降序排列的。
2)pidstat是sysstat中的命令,(官网:www.fhadmin.org) 使用之前需要先安装sysstat, yum install sysstat安装即可。
安装完成后输入pidstat 2 2, 表示每个2秒输出一次进程信息, 一共输出2次, 显示如下:

其中cpu列表示该进程占用的cpu数量(官网:www.fhadmin.org) 。
如果要查看某一进程的cpu使用信息, 则使用pidstat -p pid -t period count 命令查看。
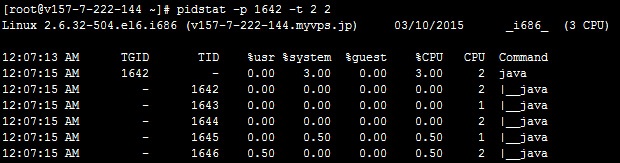
如pidstat -p 1642 -t 2 2显示如下信息:
 、
、
其中TGID表示进程id, tid表示线程id, %system表示cpu利用率, %CPU表示该进程的cpu使用百分比。 %system这个在top命令中是查看不到的。
3) vmstat查看cpu、内存、io采样数据。
输入 vmstat 1 2 可获得如下显示信息:

一般命令格式为(官网:www.fhadmin.org) vmstat 采样时间间隔 [采样次数]
输出内容含义如下:
r 表示运行队列(就是说多少个进程真的分配到CPU),我测试的服务器目前CPU比较空闲,没什么程序在跑,当这个值超过了CPU数目,就会出现CPU瓶颈 了。这个也和top的负载有关系,一般负载超过了3就比较高,超过了5就高,超过了10就不正常了,服务器的状态很危险。top的负载类似每秒的运行队 列。如果运行队列过大,表示你的CPU很繁忙,一般会造成CPU使用率很高。
b 表示阻塞的进程,这个不多说,进程阻塞,大家懂的。
swpd 虚拟内存已使用的大小,如果大于0,表示你的机器物理内存不足了,如果不是程序内存泄露的原因,那么你该升级内存了或者把耗内存的任务迁移到其他机器。
free 空闲的物理内存的大小,我的机器内存总共8G,剩余3415M。
buff Linux/Unix系统是用来存储,目录里面有什么内容,权限等的缓存,我本机大概占用300多M
cache cache直接用来记忆我们打开的文件,给文件做缓冲,我本机大概占用300多M(这里是Linux/Unix的聪明之处,把空闲的物理内存的一部分拿来做文件和目录的缓存,是为了提高 程序执行的性能,当程序使用内存时,buffer/cached会很快地被使用。)
si 每秒从磁盘读入虚拟内存的大小,如果这个值大于0,表示物理内存不够用或者内存泄露了,要查找耗内存进程解决掉。我的机器内存充裕,一切正常。
so 每秒虚拟内存写入磁盘的大小,如果这个值大于0,同上。
bi 块设备每秒接收的块数量,这里的块设备是指系统上所有的磁盘和其他块设备,默认块大小是1024byte,我本机上没什么IO操作,所以一直是0,但是我曾在处理拷贝大量数据(2-3T)的机器上看过可以达到140000/s,磁盘写入速度差不多140M每秒
bo 块设备每秒发送的块数量,例如我们读取文件,bo就要大于0。bi和bo一般都要接近0,不然就是IO过于频繁,需要调整。
in 每秒CPU的中断次数,包括时间中断
cs 每秒上下文切换次数,例如我们调用系统函数,就要进行上下文切换,线程的切换,也要进程上下文切换,这个值要越小越好,太大了,要考虑调低线程或者进程的 数目,例如在apache和nginx这种web服务器中,我们一般做性能测试时会进行几千并发甚至几万并发的测试,选择web服务器的进程可以由进程或 者线程的峰值一直下调,压测,直到cs到一个比较小的值,这个进程和线程数就是比较合适的值了。系统调用也是,每次调用系统函数,我们的代码就会进入内核 空间,导致上下文切换,这个是很耗资源,也要尽量避免频繁调用系统函数。上下文切换次数过多表示你的CPU大部分浪费在上下文切换,导致CPU干正经事的 时间少了,CPU没有充分利用,是不可取的。
us 用户CPU时间,我曾经在一个做加密解密很频繁的服务器上,可以看到us接近100,r运行队列达到80(机器在做压力测试,性能表现不佳)。
sy 系统CPU时间,如果太高,表示系统调用时间长,例如是IO操作频繁。
id 空闲 CPU时间,一般来说,id + us + sy = 100,一般我认为id是空闲CPU使用率,us是用户CPU使用率,sy是系统CPU使用率。
wt 等待IO CPU时间。
4) ps查看进程、线程信息, 具体不再描述。
5)sar查看历史进程信息。
我们使用top命令分析,(官网:www.fhadmin.org) 可以发现CPU使用率过高主要体现在us、sy、wa、hi。其中wa的值是受IO等待影响的, IO等待时间越长,wa的值越高, hi的值受硬件中断影响, 主要包括磁盘读写、网卡收发数据等, 对于java程序来说, 分析uy、sy就够了。
1) us表示的意思是用户空间占用cpu百分比, 他的值过高, 就说明是应用程序消耗了过多的cpu资源, 对于java应用来说主要是因为线程一直在循环操作、正则匹配、者大量的计算,或者频繁的GC。加入客户端的每次请求, 服务端都要分配较多的内存, 那么请求量大的时候就会导致不断的GC, 影响系统性能, 进而造成请求堆积,消耗更多内存, 反复如此, 进入恶性循环中。 对于前几种情况, 就要我们找到消耗cpu的线程, 分析对应的代码, 找到影响性能的部分, 来解决问题, 对于频繁GC的问题, 就要通过分析jvm来查找原因, 随后我会写一篇针对jvm内存分析的文章来进行详解。
查找消耗CPU线程的方法kill -3 pid或者jstack pid导出线程信息, 然后将pid转化为16进制, 在导出的线程信息中找到即可。(当jvm实例挂起后, kill -3是无法导出线程信息的)
2)sy值过高说明linux系统cpu耗费很多资源来进行线程切换, 对于java进程来说就是启动了过多的线程,且线程不断的阻塞或者状态不断变化, 这就导致操作系统要不断的切换线程。分析的时候通过kill -3或者jstack导出线程信息, 查看线程信息、锁信息, 分析解决问题。

















 349
349

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









