







【十二】C语言调用阿里云Python接口
1.测试
接上一篇的garbage.py文件,将其封装成函数,供C语言调用。
将场景二注释,场景一代码打开,并输入自己测试图片的路径,如下:
# -*- coding: utf-8 -*-
# 引入依赖包
# pip install alibabacloud_imagerecog20190930
import os
import io
from urllib.request import urlopen
from alibabacloud_imagerecog20190930.client import Client
from alibabacloud_imagerecog20190930.models import ClassifyingRubbishAdvanceRequest
from alibabacloud_tea_openapi.models import Config
from alibabacloud_tea_util.models import RuntimeOptions
config = Config(
# 创建AccessKey ID和AccessKey Secret,请参考https://help.aliyun.com/document_detail/175144.html。
# 如果您用的是RAM用户的AccessKey,还需要为RAM用户授予权限AliyunVIAPIFullAccess,请参考https://help.aliyun.com/document_detail/145025.html
# 从环境变量读取配置的AccessKey ID和AccessKey Secret。运行代码示例前必须先配置环境变量。
access_key_id=os.environ.get('ALIBABA_CLOUD_ACCESS_KEY_ID'),
access_key_secret=os.environ.get('ALIBABA_CLOUD_ACCESS_KEY_SECRET'),
# 访问的域名
endpoint='imagerecog.cn-shanghai.aliyuncs.com',
# 访问的域名对应的region
region_id='cn-shanghai'
)
#封装成函数
def alibaba_garbage():
#场景一:文件在本地
img = open(r'/home/orangepi/trash/test.jpg', 'rb')#以后把拍到的垃圾文件统一放到这个文件里面,不用跟着改了
#场景二:使用任意可访问的url
# url = 'https://viapi-test-bj.oss-cn-beijing.aliyuncs.com/viapi-3.0domepic/imagerecog/ClassifyingRubbish/ClassifyingRubbish1.jpg'
#img = io.BytesIO(urlopen(url).read())
classifying_rubbish_request = ClassifyingRubbishAdvanceRequest()
classifying_rubbish_request.image_urlobject = img
runtime = RuntimeOptions()
try:
# 初始化Client
client = Client(config)
response = client.classifying_rubbish_advance(classifying_rubbish_request, runtime)
# 获取整体结果
print(response.body)
except Exception as error:
# 获取整体报错信息
print(error)
# 获取单个字段
print(error.code)
if __name__ == "__main__":
alibaba_garbage()
测试是否正确:python3 garbage.py


其中“/home/orangepi/trash/test.jpg”为本地测试用图片(根据在线文档要求:图像类型:JPEG、JPG、PNG,图像大小:不大于3 MB,图像分辨率:不限制图像分辨率,但图像分辨率太高可能会导致API识别超时,超时时间为5秒)
代码缩进技巧:按住V进入视图,鼠标框选后缩进的代码,按住shift+>就缩进了。
2.输出dict类型
在上面输出的类型中我们查看一下是不是我们想要的dict类型,打印一下他的类型:print(response.body)
我们发现它输出的却是class类:

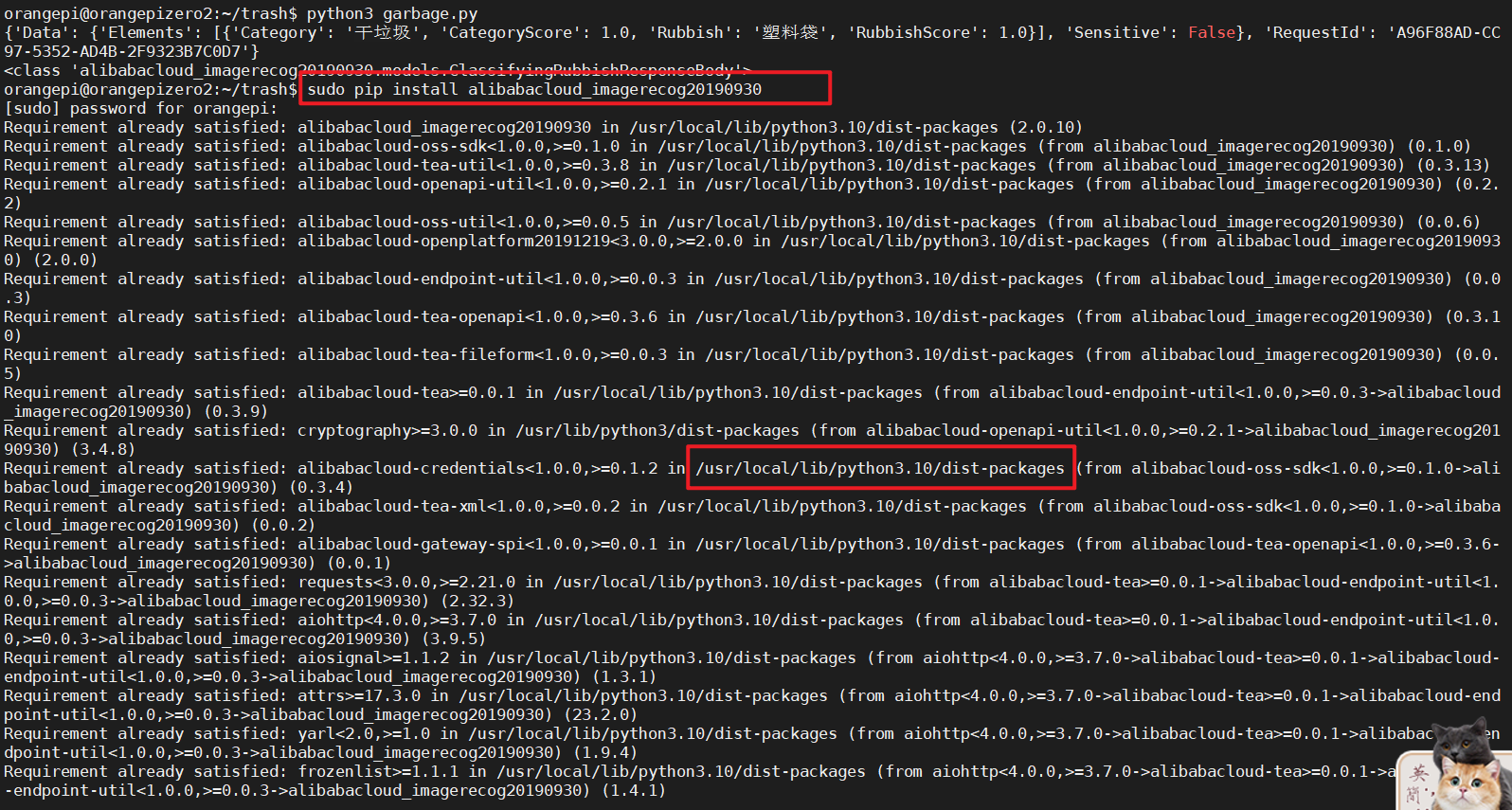
//1.查看安装目录
pip install alibabacloud_imagerecog20190930
//2.进入到这个目录
cd /usr/local/lib/python3.10/dist-packages
//3.查找一下我们之前输出的class类,ClassifyingRubbishResponseBody
grep -r ClassifyingRubbishResponseBody.
//4.进入到alibabacloud_imagerecog20190930/models.py
vi alibabacloud_imagerecog20190930/models.py
//5.在models.py里面搜索ClassifyingRubbishResponseBody
/ClassifyingRubbishResponseBody
我们发现在这个文件:alibabacloud_imagerecog20190930/models.py,
进入到alibabacloud_imagerecog20190930/models.py
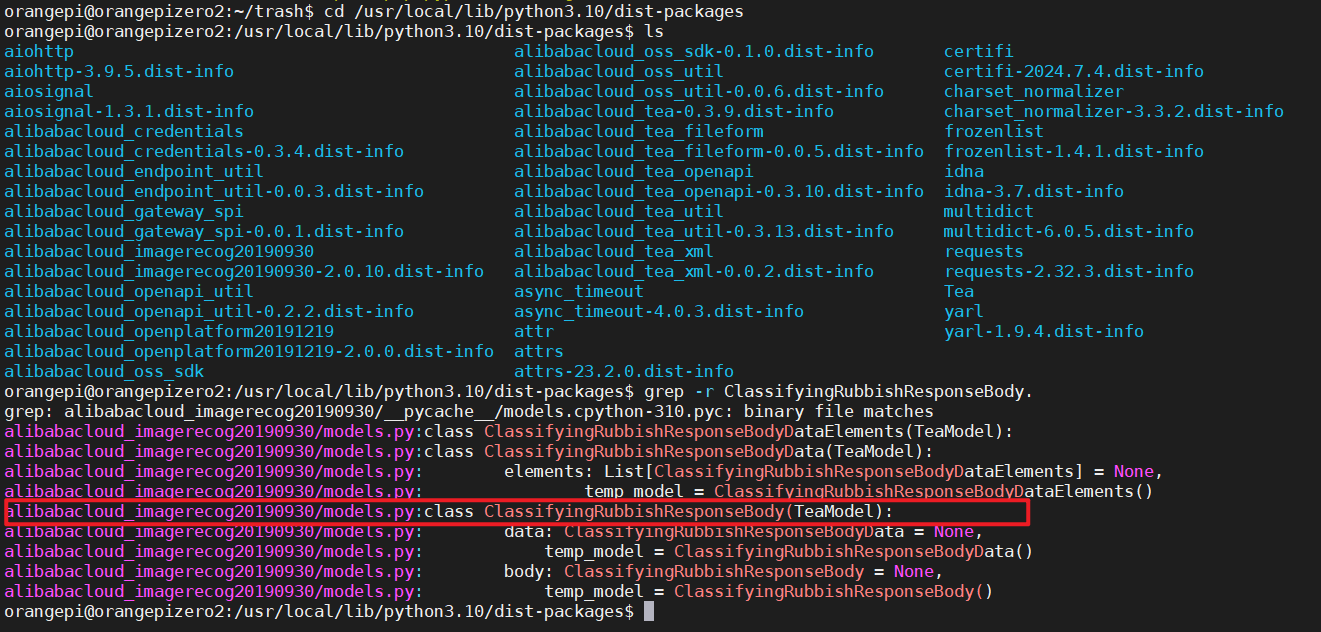
5.在models.py里面搜索ClassifyingRubbishResponseBody
我们发现里面有一个to_map函数,,map就是dict,返回的是dict类型,那么我们就可以调用这个to_map函数
q!强制退出
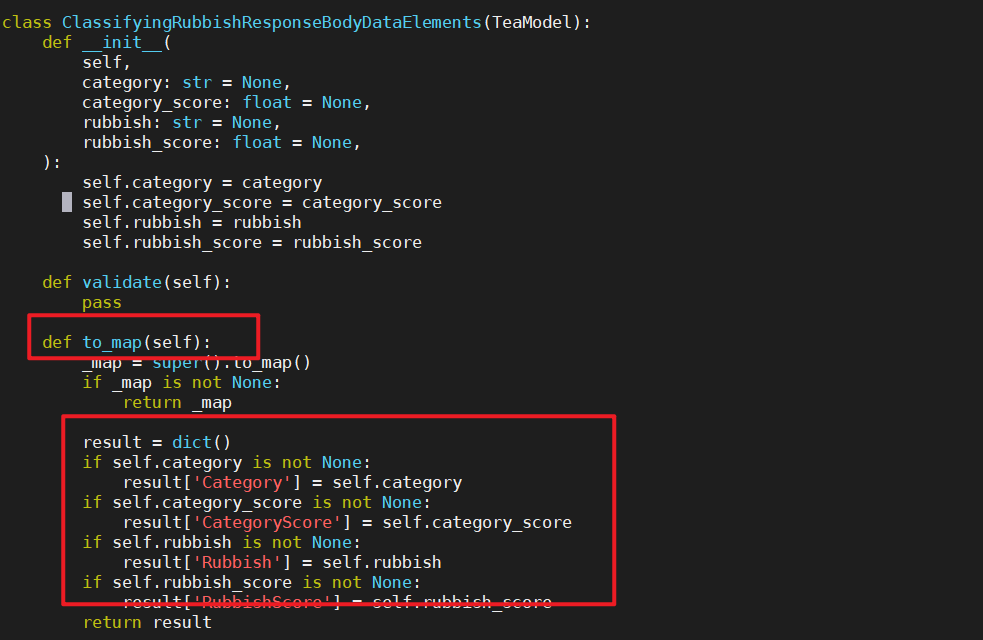
我们调用一下to_map函数看看他的类型和输出值。
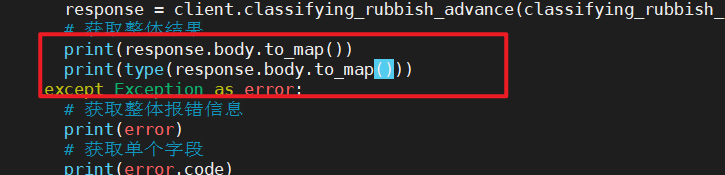
OK了,是我们想要的类型和结果,接下来就可以用到我们之前的dict嵌套了。

3.代码改进
在之前我们讲过如何取dict字典嵌套的值。
print(response.body.to_map()[‘Data’][‘Elements’][0]['Category'])
print(type(response.body.to_map()))
其次我们在代码后面发现会打印一些报错信息,但是我不想乱七八糟的打印。之后我们会用C语言调用这个Python函数,我们就需要一个返回值来接收。
print(response.body)
except Exception as error:
# 获取整体报错信息
print(error)
# 获取单个字段
print(error.code)
以下是改进部分
print(response.body.to_map()['Data']['Elements'][0]['Category'])
return response.body.to_map()['Data']['Elements'][0]['Category']
except Exception as error:
return '获取失败'
最终代码:
garbage.py
# -*- coding: utf-8 -*-
# 引入依赖包
# pip install alibabacloud_imagerecog20190930
import os
import io
from urllib.request import urlopen
from alibabacloud_imagerecog20190930.client import Client
from alibabacloud_imagerecog20190930.models import ClassifyingRubbishAdvanceRequest
from alibabacloud_tea_openapi.models import Config
from alibabacloud_tea_util.models import RuntimeOptions
config = Config(
# 创建AccessKey ID和AccessKey Secret,请参考https://help.aliyun.com/document_detail/175144.html。
# 如果您用的是RAM用户的AccessKey,还需要为RAM用户授予权限AliyunVIAPIFullAccess,请参考https://help.aliyun.com/document_detail/145025.html
# 从环境变量读取配置的AccessKey ID和AccessKey Secret。运行代码示例前必须先配置环境变量。
access_key_id=os.environ.get('ALIBABA_CLOUD_ACCESS_KEY_ID'),
access_key_secret=os.environ.get('ALIBABA_CLOUD_ACCESS_KEY_SECRET'),
# 访问的域名
endpoint='imagerecog.cn-shanghai.aliyuncs.com',
# 访问的域名对应的region
region_id='cn-shanghai'
)
#封装成函数
def alibaba_garbage():
#场景一:文件在本地
img = open(r'/home/orangepi/trash/test.jpg', 'rb')#以后把拍到的垃圾文件统一放到这个文件里面,不用跟着改了
#场景二:使用任意可访问的url
# url = 'https://viapi-test-bj.oss-cn-beijing.aliyuncs.com/viapi-3.0domepic/imagerecog/ClassifyingRubbish/ClassifyingRubbish1.jpg'
#img = io.BytesIO(urlopen(url).read())
classifying_rubbish_request = ClassifyingRubbishAdvanceRequest()
classifying_rubbish_request.image_urlobject = img
runtime = RuntimeOptions()
try:
# 初始化Client
client = Client(config)
response = client.classifying_rubbish_advance(classifying_rubbish_request, runtime)
# 获取整体结果
print(response.body.to_map()['Data']['Elements'][0]['Category'])
return response.body.to_map()['Data']['Elements'][0]['Category']
except Exception as error:
return '获取失败'
if __name__ == "__main__":
alibaba_garbage()

4.实现C语言调用Python函数
garbage.c
直接把之前讲的代码搬过来,接下来讲一下如何快速替换里面的代码,
接下来我们准备采用分文件的编程方式,因为每次调用这个函数,不一定非要每次都做初始化,所有我们将这些部分全部封装成函数,供我们之后调用
#include <Python.h>
int main()
{
Py_Initialize();
// 将当前路径添加到sys.path中
PyObject *sys = PyImport_ImportModule("sys");
PyObject *path = PyObject_GetAttrString(sys, "path");
PyList_Append(path, PyUnicode_FromString("."));
// 导入para模块
PyObject *pModule = PyImport_ImportModule("para");
if (!pModule)
{
PyErr_Print();
printf("Error: failed to load nopara.py\n");
}
//获取say_funny函数对象
PyObject *pFunc = PyObject_GetAttrString(pModule, "say_funny");
if (!pFunc)
{
PyErr_Print();
printf("Error: failed to load say_funny\n");
}
//创建一个字符串作为参数
//char *category = "comedy";
//PyObject *pArgs = Py_BuildValue("(s)", category);//字符串加括号表示他是一个包含字符串的元组
//调用say_funny函数并获取返回值
PyObject *pValue = PyObject_CallObject(pFunc, NULL);
if (!pValue)
{
PyErr_Print();
printf("Error: function call failed\n");
}
//将返回值转换为C类型
char *result = NULL;
if (!PyArg_Parse(pValue, "s", &result))
{
PyErr_Print();
printf("Error: parse failed\n");
}
//打印返回值
printf("pValue=%s\n", result);
//释放所有引用的Python对象
Py_DECREF(pValue);
Py_DECREF(pFunc);
Py_DECREF(pModule);
//释放所有引用的Python对象
Py_Finalize();
return 0;
}
1.把para模块换成garbage (因为函数在garbage.py文件中)2.say_fanny函数换成我们需要的alibaba_garbage函数
:%s /para/garbage/g
2.把传参函数删掉
char *category = "comedy"; PyObject *pArgs = Py_BuildValue("(s)", category);//字符串加括号表示他是一个包含字符串的元组 PyObject *pValue = PyObject_CallObject(pFunc, pArgs);//改null
封装成函数:里面需要注意的是出错了之后里面的if语句我们就应该释放掉,而不是继续运行,这是不对的,所以我们需要用goto语句来跳转到释放的地方。
result的值是pValue赋予的,且他们都是字符串指针变量,而pValue在最后返回前就会被free掉,pValue的值一旦被free,result的值也会被free,所以必须在pValue被free之前再定义一个字符串,使用strcpy来保存需要返回的结果!
garbage.c
#include <Python.h>
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
void garbage_init(){
Py_Initialize();
// 将当前路径添加到sys.path中
PyObject *sys = PyImport_ImportModule("sys");
PyObject *path = PyObject_GetAttrString(sys, "path");
PyList_Append(path, PyUnicode_FromString("."));
}
void garbage_final()
{
// 关闭Python解释器
Py_Finalize();
}
char *garbage_category(char *category)
{
// 导入para模块
PyObject *pModule = PyImport_ImportModule("garbage");
if (!pModule)
{
PyErr_Print();
printf("Error: failed to load garbage.py\n");
goto FAILED_MODULE; //goto的意思就是如果运行到这里就直接跳转到FAILED_MODULE
}
//获取say_funny函数对象
PyObject *pFunc = PyObject_GetAttrString(pModule, "alibaba_garbage");
if (!pFunc)
{
PyErr_Print();
printf("Error: failed to load say_funny\n");
goto FAILED_FUNC;
}
//创建一个字符串作为参数
//char *category = "comedy";
//PyObject *pArgs = Py_BuildValue("(s)", category);//字符串加括号表示他是一个包含字符串的元组
//调用say_funny函数并获取返回值
PyObject *pValue = PyObject_CallObject(pFunc, NULL);
if (!pValue)
{
PyErr_Print();
printf("Error: function call failed\n");
goto FAILED_VALUE;
}
//将返回值转换为C类型
char *result = NULL;
if (!PyArg_Parse(pValue, "s", &result))
{
PyErr_Print();
printf("Error: parse failed\n");
goto FAILED_RESULT;
}
//打印返回值
//printf("pValue=%s\n", result);
// 为垃圾分类信息分配内存,复制返回值
category = (char *)malloc(sizeof(char) * (strlen(result) + 1));
memset(category, 0, (strlen(result) + 1));
strncpy(category, result, (strlen(result) + 1));
//释放所有引用的Python对象
FAILED_RESULT:
Py_DECREF(pValue);
FAILED_VALUE:
Py_DECREF(pFunc);
FAILED_FUNC:
Py_DECREF(pModule);
FAILED_MODULE:
return category;
}
5.最终整合
到了最后的这个环节,我们来捋一捋我们的思路:
我们通过阿里云给我们提供的API,在garbage.h中去解析垃圾的类型,紧接着我们通过garbage.c文件来调用garbage.h中判断垃圾类型的函数,其次我们将garbage.c文件里面的函数写到garbage.h文件中,供我们之后其他文件来调用,因为garbage.c文件中包含着调用pyhton一些函数的调用,看起来不简洁,所有我们剥离出来。在之后如果想要识别垃圾分类的时候,我们就可以直接导入garbage.h garbage.c garbage.py这三个文件即可。
garbage.py
# -*- coding: utf-8 -*-
# 引入依赖包
# pip install alibabacloud_imagerecog20190930
import os
import io
from urllib.request import urlopen
from alibabacloud_imagerecog20190930.client import Client
from alibabacloud_imagerecog20190930.models import ClassifyingRubbishAdvanceRequest
from alibabacloud_tea_openapi.models import Config
from alibabacloud_tea_util.models import RuntimeOptions
config = Config(
# 创建AccessKey ID和AccessKey Secret,请参考https://help.aliyun.com/document_detail/175144.html。
# 如果您用的是RAM用户的AccessKey,还需要为RAM用户授予权限AliyunVIAPIFullAccess,请参考https://help.aliyun.com/document_detail/145025.html
# 从环境变量读取配置的AccessKey ID和AccessKey Secret。运行代码示例前必须先配置环境变量。
access_key_id=os.environ.get('ALIBABA_CLOUD_ACCESS_KEY_ID'),
access_key_secret=os.environ.get('ALIBABA_CLOUD_ACCESS_KEY_SECRET'),
# 访问的域名
endpoint='imagerecog.cn-shanghai.aliyuncs.com',
# 访问的域名对应的region
region_id='cn-shanghai'
)
#封装成函数
def alibaba_garbage():
#场景一:文件在本地
img = open(r'/home/orangepi/trash/test.jpg', 'rb')#以后把拍到的垃圾文件统一放到这个文件里面,不用跟着改了
#场景二:使用任意可访问的url
# url = 'https://viapi-test-bj.oss-cn-beijing.aliyuncs.com/viapi-3.0domepic/imagerecog/ClassifyingRubbish/ClassifyingRubbish1.jpg'
#img = io.BytesIO(urlopen(url).read())
classifying_rubbish_request = ClassifyingRubbishAdvanceRequest()
classifying_rubbish_request.image_urlobject = img
runtime = RuntimeOptions()
try:
# 初始化Client
client = Client(config)
response = client.classifying_rubbish_advance(classifying_rubbish_request, runtime)
# 获取整体结果
# print(response.body.to_map()['Data']['Elements'][0]['Category'])
return response.body.to_map()['Data']['Elements'][0]['Category']
except Exception as error:
return '获取失败'
if __name__ == "__main__":
alibaba_garbage()
garbage.c
#include <Python.h>
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
void garbage_init(){
Py_Initialize();
// 将当前路径添加到sys.path中
PyObject *sys = PyImport_ImportModule("sys");
PyObject *path = PyObject_GetAttrString(sys, "path");
PyList_Append(path, PyUnicode_FromString("."));
}
void garbage_final()
{
// 关闭Python解释器
Py_Finalize();
}
char *garbage_category(char *category)
{
// 导入para模块
PyObject *pModule = PyImport_ImportModule("garbage");
if (!pModule)
{
PyErr_Print();
printf("Error: failed to load garbage.py\n");
goto FAILED_MODULE; //goto的意思就是如果运行到这里就直接跳转到FAILED_MODULE
}
//获取say_funny函数对象
PyObject *pFunc = PyObject_GetAttrString(pModule, "alibaba_garbage");
if (!pFunc)
{
PyErr_Print();
printf("Error: failed to load say_funny\n");
goto FAILED_FUNC;
}
//创建一个字符串作为参数
//char *category = "comedy";
//PyObject *pArgs = Py_BuildValue("(s)", category);//字符串加括号表示他是一个包含字符串的元组
//调用say_funny函数并获取返回值
PyObject *pValue = PyObject_CallObject(pFunc, NULL);
if (!pValue)
{
PyErr_Print();
printf("Error: function call failed\n");
goto FAILED_VALUE;
}
//将返回值转换为C类型
char *result = NULL;
if (!PyArg_Parse(pValue, "s", &result))
{
PyErr_Print();
printf("Error: parse failed\n");
goto FAILED_RESULT;
}
//打印返回值
//printf("pValue=%s\n", result);
// 为垃圾分类信息分配内存,复制返回值
category = (char *)malloc(sizeof(char) * (strlen(result) + 1));
memset(category, 0, (strlen(result) + 1));
strncpy(category, result, (strlen(result) + 1));
//释放所有引用的Python对象
FAILED_RESULT:
Py_DECREF(pValue);
FAILED_VALUE:
Py_DECREF(pFunc);
FAILED_FUNC:
Py_DECREF(pModule);
FAILED_MODULE:
return category;
}
garbage.h
#ifndef __CLASSIFY__H
#define __CLASSIFY__H
void garbage_init(void);
void garbage_final(void);
char *garbage_category(char *category);
#endif
garbagetest.c
#include <stdio.h>
#include <stdlib.h>
#include "garbage.h"
int main()
{
char *category = NULL;
garbage_init();
category = garbage_category(category);
printf("category=%s\n", category);
garbage_final();
free(category);//释放掉开辟的资源
return 0;
}
编译运行:
//注意多文件的编译方式以及链接库文件
gcc -o garbage garbage.c garbagetest.c garbage.h -I /usr/include/python3.10 -l python3.10
//“-I”指定python头文件路径;“-l”指定python库文件路径



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











