








深夜,我面对又一个因记忆混乱而“胡言乱语”的智能体,突然意识到:我们给AI装上的可能不是记忆,而是一个堆满杂物的仓库。
凌晨两点,我的智能体在连续对话30轮后,突然把用户十分钟前明确拒绝的方案又推了出来。作为有二十年经验的老兵,我经历过数据库索引失效、内存泄漏,但这次的问题更隐蔽——我们集体误解了大模型的“长期记忆”。
在智能体架构中,记忆系统正成为新的技术债务黑洞。今天,我想和你坦诚聊聊向量数据库、上下文窗口扩展和长期记忆本质之间的认知鸿沟。
01 误区一:向量库即长期记忆
在智能体项目中,最常见的场景是:“我们需要长期记忆?上向量数据库!” 这种条件反射背后,是将存储介质等同于记忆系统的根本误解。
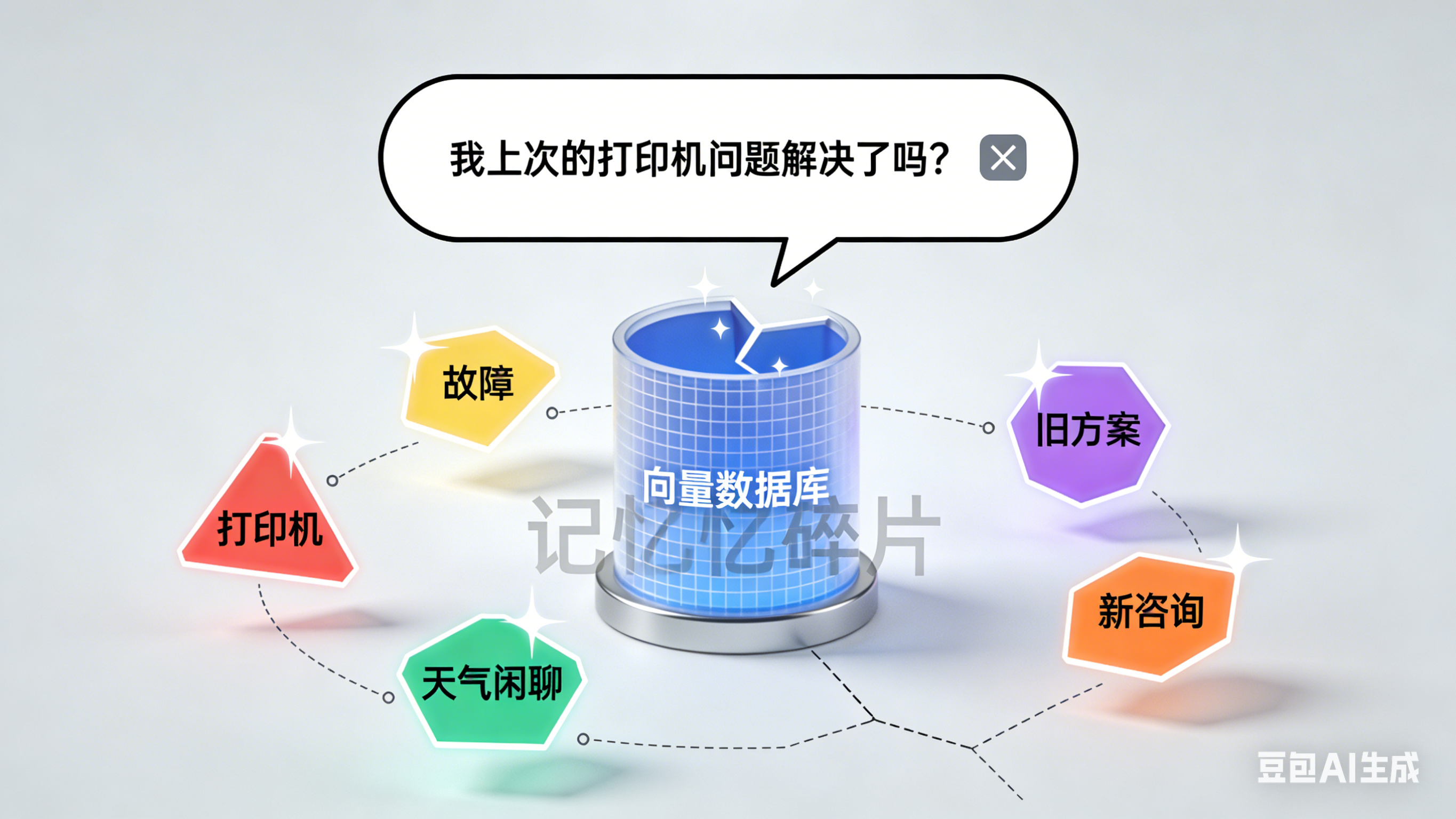
上个月,我评审了一个客服智能体架构。团队自豪地展示了他们的“记忆系统”:用户每次对话后,所有内容都会被切成片段,嵌入向量,存入数据库。但当用户问“我上次反映的打印机问题解决了吗?”时,智能体却从向量库中找出了五个不同的“打印机”相关片段,拼凑出混乱的答案。
问题不在向量数据库本身——它是一种高效的相似性检索工具。但记忆不是简单的“存储与检索”,而是包含编码、存储、巩固、提取、遗忘的完整系统。
向量库只解决了存储和基于相似性的提取,却忽略了几个关键问题:
-
记忆的层次性:用户的核心需求(打印机故障)与闲聊内容(天气话题)应有不同的存储权重
-
记忆的关联性:打印机的故障描述、解决进度、后续反馈应是关联记忆,而非独立片段
-
记忆的衰减与更新:一周前的临时方案与今天的最新进展,哪个更应被记住?
真正的工程启示:向量库应作为记忆系统的存储层之一,而非全部。一个完整的记忆系统需要:
-
分层存储策略(短期/长期/核心/边缘)
-
记忆关联图谱(而非孤立片段)
-
记忆刷新与衰减机制
-
基于元数据的智能检索(而不仅是向量相似性)
02 误区二:扩展上下文窗口等于增强记忆
当各大模型厂商竞相宣传“100万token上下文窗口”时,我团队的年轻工程师兴奋地说:“我们的记忆问题解决了!” 我给他泼了冷水:这就像为了解决交通拥堵,把城市所有道路都扩宽十倍。
技术圈很少公开讨论但极为关键的一点是:超长上下文窗口存在显著的“中部记忆塌陷”现象。在超长文本中,模型对开头和结尾的内容记忆较好,但对中间部分的内容召回率会显著下降。
更实际的问题是工程成本。在我的性能测试中,一个128K上下文窗口的调用,成本是4K窗口的8-12倍,延迟则是5-7倍。而大部分业务场景中,真正需要在单次调用中传递的信息,很少超过8K token。
这引出了第二个关键认知:上下文窗口本质上是“工作记忆”(Working Memory),相当于电脑的RAM,而非硬盘。它的特点是快速存取但容量有限、断电(对话结束)即清空。
把长期记忆全部塞进上下文窗口,就像为了记住一生所有经历,时刻在脑海中反复背诵——效率极低且成本高昂。
架构师的实际解法:我设计的智能体系统中,上下文窗口只保留三类信息:
-
本次对话的核心任务与状态(约500 token)
-
从长期记忆中提取的精准相关片段(通常不超过5条,约1500 token)
-
系统指令与当前步骤的思考框架(约500 token)
总长度严格控制在4K token以内,保证性能与成本的最优平衡。长期记忆则通过外挂系统管理,按需精准提取。

03 误区三:记忆是越多越好,越久越好
人类的大脑会主动遗忘,这是进化的智慧。但在AI系统中,我们却默认“记忆应尽可能完整、永久保存”。这个误区导致许多智能体最终被自己的“记忆”压垮。
我曾接手过一个已运行半年的销售助手智能体,它的“记忆库”中存储了超过10万条对话片段。随着时间推移,响应速度从1.2秒逐渐恶化到8秒以上,且回答质量显著下降——经常引用过时甚至矛盾的旧信息。
问题核心在于:未经管理的记忆积累会形成“记忆污染”。旧策略、过时信息、错误案例与最新知识混杂在一起,使智能体陷入“记忆沼泽”。
智能体需要的不是“完整的记忆”,而是有效的记忆。这需要三个层面的设计:
-
记忆的衰减与淘汰机制
在我的架构中,每条记忆都有“保质期”和“强度值”。闲聊记忆的强度每天衰减30%,7天后自动归档;核心业务记忆衰减率仅为5%,且每次成功使用会增强20%。
-
记忆的抽象与概括
原始对话:“用户喜欢蓝色、讨厌红色、对价格敏感、常用优惠码...” 不应直接存储,而应抽象为:“用户偏好:冷色调;价格敏感度高;有促销倾向”。这减少了存储量,提高了检索效率。
-
记忆的验证与纠错
当智能体基于某记忆做出决策却导致任务失败时,该系统应能自动降低该记忆的权重,并标记需要人工审核。

04 智能体记忆系统的架构本质
经过多个项目的迭代,我现在将智能体记忆系统抽象为四层架构:
-
感官缓存层(<1分钟):存储当前对话的原始流,对话结束时自动清理。
-
工作记忆层(本次对话):在上下文窗口中的信息,随对话结束而清空。
-
短期记忆层(数小时至数天):外挂存储,记录本次会话的核心事实与状态,用于跨会话的连续性。
-
长期记忆层(数天至永久):核心知识、用户画像、历史模式,经过去重、抽象、关联后结构化存储。
每一层都有不同的存储介质、检索策略和失效机制,而不是简单地将所有东西向量化后扔进同一个数据库。
05 一个实用的记忆系统设计框架
如果你正在设计智能体记忆系统,可以基于以下原则开始:
原则一:记忆应有明确的存取成本
在我的系统中,从感官缓存读取的代价是0.1,从工作记忆读取是0.5,从短期记忆读取是2,从长期记忆读取是5(相对单位)。智能体在需要记忆时会权衡成本与收益,避免无节制地“回忆一切”。
原则二:记忆的价值随时间动态变化
设计记忆的“价值衰减曲线”。闲聊内容的价值在24小时内从100降至10,业务需求的价值一周内从100降至80,然后缓慢衰减。价值低于阈值的记忆自动降级或清理。
原则三:记忆之间应有清晰的隔离与关联
不同主题、不同敏感度的记忆应物理或逻辑隔离。同时,相关记忆应通过指针或图谱关联,支持沿着关联链进行深度回忆。
原则四:记忆系统应有自清洁能力
定期自动运行“记忆整理”流程:合并相似记忆、淘汰低价值记忆、修正矛盾记忆、强化高频使用记忆。
三周前,我重构了那个深夜出错的智能体记忆系统。现在,它会区分“用户偏好”、“问题历史”、“解决方案”和“闲聊残影”,每类记忆有不同的生命周期和提取策略。
工程师真正的价值不在于堆砌最新技术组件,而是理解复杂需求的本质后,做出精准而克制的设计。大模型的记忆系统也是如此——它需要的不是更大的仓库,而是一套智慧的图书馆管理规则:知道什么该收藏、如何编目、何时下架,以及怎样在最需要时迅速找到。
当你的智能体再次“记错”事情时,不妨先问自己:我们设计的是记忆系统,还是只是又一个等待技术债务到期的数据沼泽?真正的智能不在于记住一切,而在于记住该记住的,并以有用的方式记住。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









