







Hadoop集群安装与配置
①在Master上安装与配置Hadoop
将hadoop-1.2.1.tar.gz复制到"/usr"目录下面,解压兵命名为hadoop,赋予用户hadoop权限
(chown -R hadoop:hadoop /usr/hadoop)
在/usr/hadoop下创建tmp文件夹(tmp的权限也要如上修改),配置环境/etc/profile,在其尾部添加:

重启/etc/profile:
source /etc/profileHadoop配置文件均在/usr/hadoop/conf目录下,之前的版本的配置文件主要是Hadoop-default.xml和Hadoop-site.xml。由于Hadoop发展迅速,代码量急剧增加,代码开发分为了core,hdfs和map/reduce三部分,配置文件也被分成了三个core-site.xml、hdfs-site.xml、mapred-site.xml。core-site.xml和hdfs-site.xml是站在HDFS角度上配置文件;core-site.xml和mapred-site.xml是站在MapReduce角度上配置文件。
1)配置hadoop-env.sh
在文件末位添加:

2)配置core-site.xml
此处配置HDFS的地址和端口号。如图:

因为Hadoop架构是主master模式,所以在一个集群中的所有master及slave上设置的fs.default.name值应该是唯一一个NameNode主服务器的地址。
3)配置hdfs-site.xml
备份数要少于等于salve的数目

4)配置mapred-site.xml
此处配置的是JobTracker,由于JobTracker(NameNode)位于Master节点上,所以此文件在master和slave上的内容一样。

5)配置masters文件和slaves文件
masters文件:
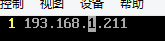
slaves文件:

Master节点上的Hadoop安装及配置就完成了
②Slave上的安装和配置
可以用scp命令直接复制Master节点上的/usr/hadoop到slave上的/usr下,并修改权限
(chown -R hadoop:hadoop /usr/hadoop)最后把所有slave机器上的/etc/profile文件,加入如下内容,并source /etc/profile。
















 974
974

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









