






现在,网易视频云与大家分享一下Infobright。
Infobright是一个有多年历史的开源的adhoc 数据仓库软件。它首次发布于2005年,并于2008年开源社区版本。并在2009年成为MySQL合作伙伴,并集成到MySQL中。
Infobright虽然集成到MySQL中,默认有一个BrightHouse 引擎,但是与InnoDB/MyISAM这类引擎不同在于,Infobright有自己的查询优化层,它仅仅是利用的MySQL原有的一些查询解析以及重写机制。

Infobright最大的特点是列式存储,数据压缩以及基于它独有的知识网格(Knowledge grid)查询优化方式。暂时撇开列存以及压缩不表,本文着重分析知识网格的实现方式,以及它的查询优化器如何进行SQL优化。
传统的数据库利用创建索引进行查询优化,无论是MyISAM 这样堆表索引或者是InnoDB主键的聚蔟索引,都是建立表中的若干列到整条表纪录的映射关系,目的就是为了已较小的访问代价尽快的定位符合查询条件的数据行,为控制访问代价,最流行的数据库索引是由B树,以及B树的变种来实现。
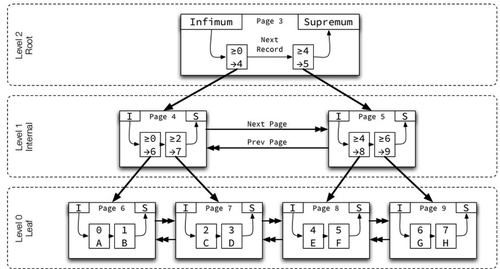
B树一般使用二分查找的方式从根节点到叶子节点定位纪录。当索引能完全存储在内存中时,索引查询的速度会非常的快。然而当索引需要内外存换入换出时,性能会有明显的下降。不仅是性能,B树索引本身占用的空间也相对较大,常见的索引键构成为索引列加行号或者是索引列加主键,一条索引键对应一条记录,当数据库使用不当,或者是为查询建立过多索引或者索引中含有过多的列时,索引本身的体积会很快成为一个现实的问题。此外,B树索引也不适合unique键值较少的列(效率低),同时也不支持前导模糊查询。所以B树索引最适合的是小数据量的OLTP场景。
Infobright 为OLAP设计,它没有索引的概念,而是利用知识网格进行数据的筛选,从而达到降低数据访问代价的目的。在说明知识网格之前首先需要说明一些基础的概念:
1.DataPack(DP):BrightHouse引擎将数据按照64k行的大小切分成一个个Rough rows,Rough rows根据列由分为一个个DP,DP是BrightHouse底层的数据存储单元,也是基本压缩解压单元。
2.DataPackNode(DPN):一个DPN与一个DP对应,存储了一些基本信息,最大值,最小值,平均值、记录值总和,null值的数量以及记录的总数量。3.Knowlege Node (KN):相比DPN更高层次的一些智能化的信息,包括有直方图、字符位图、pack-to-pack。
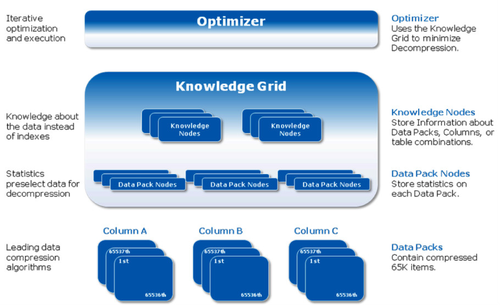
在存储引擎层,DPN和KN组成了知识网格,DP是底层的存储。DP包含65536条数据,而且根据DP内数据分布的不同会采用不同的压缩方式,部分压缩算法的解压代价是较高的,知识网格的作用类似于索引能有效地过滤查询中不符合条件的数据,从而加快查询响应速度。
知识网格采用了一种模糊处理的概念,因此以相对较小的代价来定位以DP为最小单位的数据,根据Infobright的白皮书上的说明,知识网格只占据数据总大小的1%以下,因此在绝大多数情况下可以轻松装入内存。而且知识网格是一个“智能”的查询过滤器,能根据线上查询的负载优化自身的内容。接下来我们来看一下知识网格的实现。
KN有三种基本的类型:
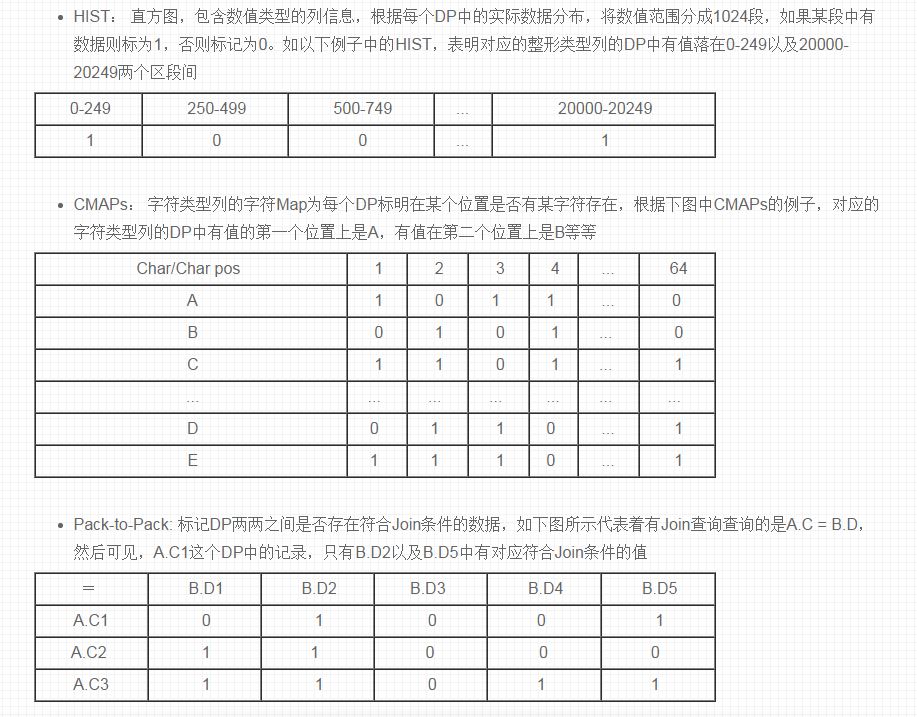
现实中,数据对于上述的三种KN的影响较大,比如HIST中数据的稠密性,并且列内的DP之间的依赖关系没有涉及,根据机器学习或者数据挖掘的理论,尚可引入更多的信息来帮助加速查询。
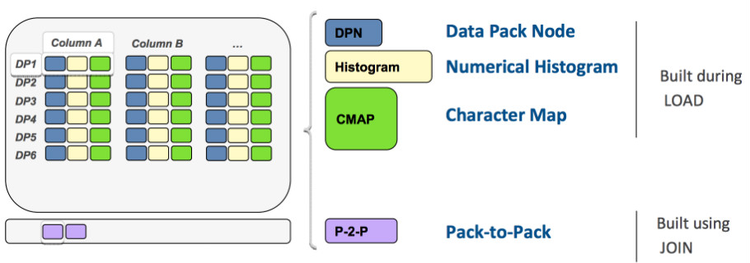
DPN、HIST以及CMAP在数据导入的时候伴随着生成,而Pack-to-Pack则是在查询的过程中生成,知识网格数是持久化到外存的,DPN存储于表目录.bht 文件中,与数据文件隔离,随着数据加载同时load到内存中。而KN由配置文件指定位置,HIST.xxx.yyy.rsi 为直方图文件,CMAP.xxx.yyy.rsi为CMAPs文件,JPP.xxx.yyy.xxx.yyy.rsi为Pack-to-Pack文件,xxx是表的编号,yyy为列号,当查询需要时才load到一个专门的内存KN Pool中。KN这些持久化的数据会随着新的导入/更新/删除操作(后两者为企业版特有功能)做一些append操作,也会随着新的Join查询进行更新。如果要保证知识网格与数据的强同步,会极大程度的降低数据导入/更新的速度,比如针对Pack-to-Pack,新增的数据需要扫描对应表中所有的数据,这对用户来说是难以忍受的。针对这个问题,Infobright采用的是延时计算的方法,即为了保证数据装载速度,部分的知识网格在查询的时候再进行计算。
有了条件过滤器知识网格,接下来就要看Infobright是如何去进行优化以及执行的了。Infobright 的查询优化基于Rough set粗糙集的理论,主要思想是通过一些先验知识库,将知识理解对数据进行划分,将不确定或不精确的知识用于已知的知识进行刻画,Infobright的查询优化器根据查询条件,通过知识网格对DP进行分类:
·无关DP:DP中没有符合查询条件的数据, 对应Negative region
·强相关DP:DP中所有数据都符合查询条件,对应Positive region
·待定DP:可能部分数据符合条件,根据知识网格还无法区分,对应Boundary region
针对一个普通查询,只有select的列相关的DP以及过滤条件中的待定DP需要进行解压。看一个例子:
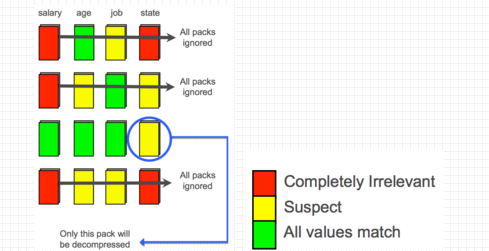
在一个拥有Salary,Age, Job, State四列组成的表中进行查询,查询条件中4列的都进行了限制,并且用And连接,根据DPN、HIST,CMAPs的帮助下,很快能划分出表中的无关DP(红色)、强相关DP(绿色)、待定DP(黄色),因为是AND条件,所以能看到Salary(1), Salary(2), Salary(4)这三个DP对应的行都无法满足查询条件,因此只需要考虑Salary(3)这个DP对应的行,又由于Salary (3), Age(3), Job(3)都是强相关,只有State(3)是待定,因此只需要解压State(3)即可。
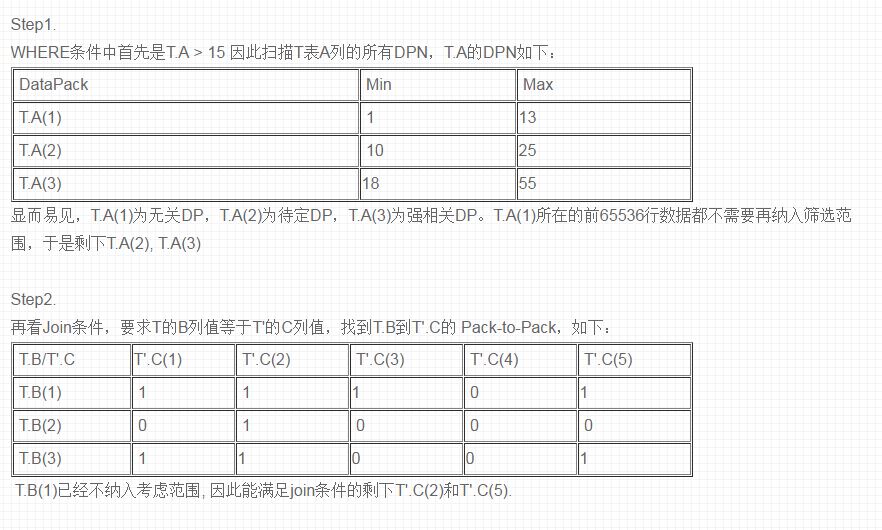
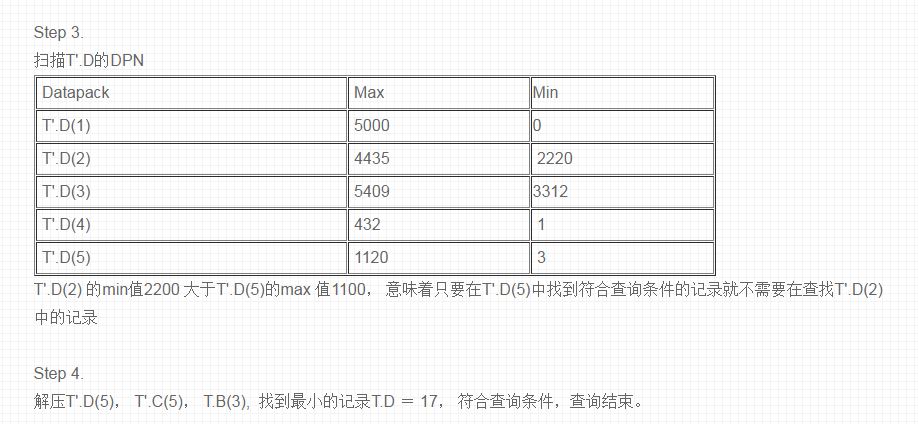
再来看一个真实的查询,看一下知识网格是如何进行DP筛选的:
Query: SELECT MIN(T’.D) FROM T , T’ WHERE T.A > 15 AND T.B = T’.C;
Infobright 依靠强大的知识网格以及高效的列式压缩在大数据量的环境下提供高效的批量查询服务。目前IB的营销策略和MySQL一样提供免费的社区版以及收费昂贵的企业版。不过不如MySQL厚道的是,Infobright社区版的功能被阉割严重,例如不支持DML语句,不支持并发导入数据,不支持并发查询,这使得社区版的实用价值大打折扣。虽然开源版功能打折,并且在使用上有诸多注意点(见附注),不过作为列存数据仓库的技术以及源码研究来说依然是相当有价值的产品。
附注:
1.Infobright不能使用MySQL的query cache,在多次执行相同的SQL时,Infobright会缓存那些已经解压的Pack以及知识网格,因此可以大幅减少访问开销(主要是解压)
2.Infobright对binary/varbinary/float/double/text 等类型的数据没有做过多的优化
3.Infobright尽量将一切数据转化为Integer进行实际存储,这也是在一些unique值不多的char/varchar列,IB可以声明LookUp关键词将字符转化为整形以提高压缩率,但如果unique值超过10000,会影响查询速度
4.Infobright的外存存储,每张表都有独立的目录
5.Infobright的一张表的行数上限是140.7兆,列数上限是100000
6.Infobright目前只支持关库拷贝文件的冷备及恢复
7.Infobright只支持HashJoin
8.由于知识网格文件关系到查询速度,因此在内存不足的情况下有条件使用SSD专门存储这些文件















 104
104

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









