






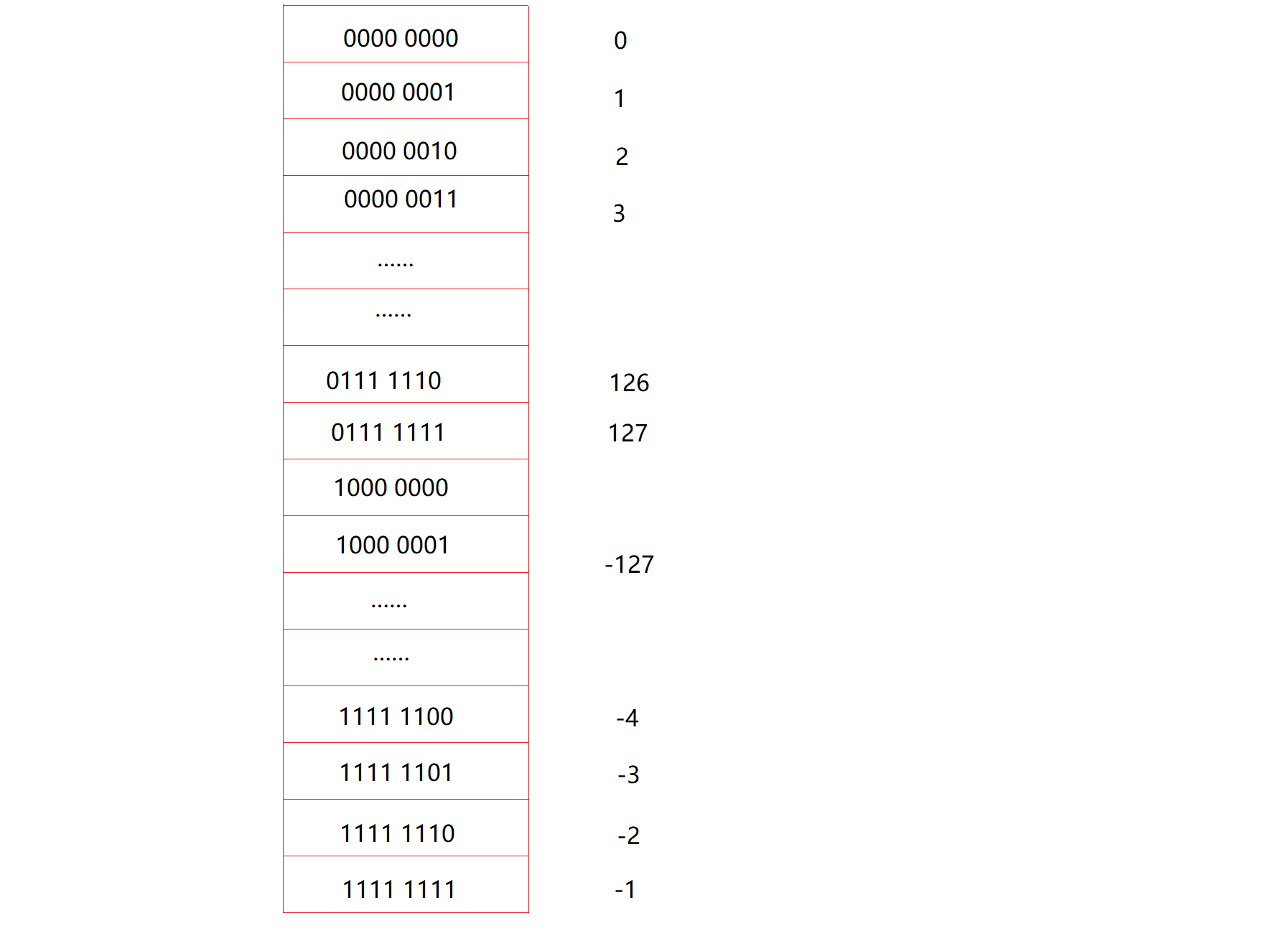
整数在内存中的存储
整数的二进制表示方法有三种:原码,反码,补码。三种表示方法均有符号位和数值位两种,符号位都是用“0”表示正,用“1”表示负;而二进制序列串的最高一位被当做符号位,剩余的都是符号位。
正整数的原反补码都相同。
负数的三种表示方法各不相同。
原码:直接将数值按照正负数的形式翻译成二进制得到的就是原码;
反码:将原码的符号位不变,其它位依次按位取反就可以得到反码;
补码:反码加一就得到补码。
注意:反码按位取反再加一就可以得到原码。
对于整型来说:存放于内存中的数据其实是补码
为什么呢?
在计算机系统中,数值⼀律⽤补码来表⽰和存储。
原因在于,使⽤补码,可以将符号位和数值域统⼀处理;
同时,加法和减法也可以统⼀处理(CPU只有加法器)此外,补码与原码相互转换,其运算过程是
相同的,不需要额外的硬件电路。
本来想把原码反码补码这三种码都将清楚的:这三种码是为了解决什么问题才诞生的,其背后的底层思想是什么,但考虑到本篇文章只是个“随笔”,再加上要查的资料估计有些多,就先鸽了,等之后有空再专门写一篇文章。
大小端字节序和字节序判断
我们都知道,计算机最原始的功能就是“计算”,要计算就必然有数据的参与,为了提高数据的利用率,就需要建立一套体系用于对数据的存储和调用,那对于人来说,这套体系是怎么样的呢?
我们首先通过一系列的感觉器官去收集信息,随后不同的信息会激活大脑中特定的神经元群,形成独特的神经元激活模式。因而每个记忆都对应一种独特的神经元激活序列。当需要回忆某个记忆时,大脑会重新激活当初编码该记忆的神经元序列,重放出相应的神经活动模式。总而言之,人脑并不像计算机那样以数字形式存储数据,而是通过神经元之间复杂的连接模式和激活状态来编码和存储记忆。
好了,扯远了。那计算机是如何存储数据的呢?
我们知道,在内存中,计算机是通过数字的方式以字节为单位对数据进行存储的,每个单位字节的存储空间都通过硬件手段有唯一的编号与之对应,有了这个编号,就可以快速找到这个存储空间,从而调用存储空间中的数据,我们将这个编号形象地称为“地址”或者“指针”。
那么,问题就来了:有些数据是大于一个字节的,要存储它们,就必然有多个存储空间的参与,该以怎样的顺序把数据和存储空间一一对应起来呢?
好,现在我们假设这个红色的方框就是内存,设从左往右是由低地址指向高地址,从上到下是由高位指向低位:
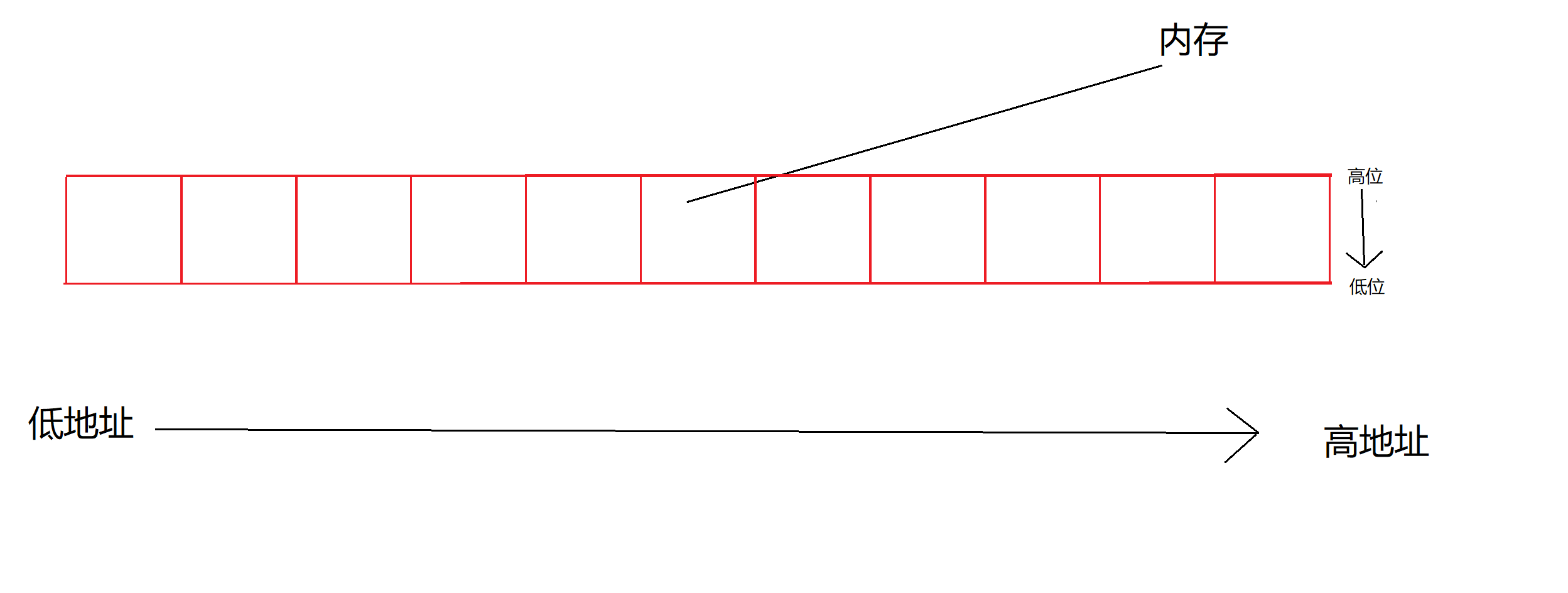
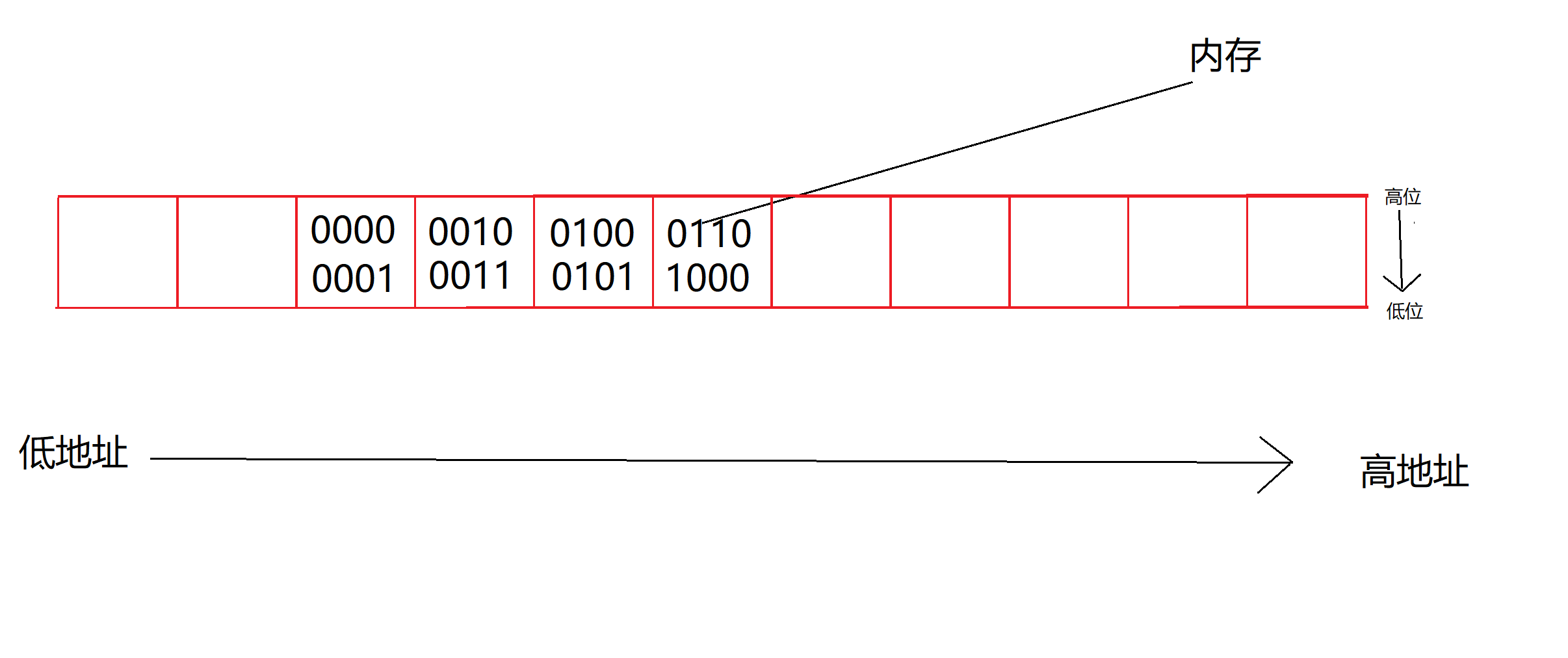
现在假设有一个32位的二进制序列串0000 0001 0010 0011 0100 0101 0110 1000,我们要将这个序列串存进计算机的内存中,该如何存呢?
可以这样存储,数据的低位字节内容保存在内存的⾼地址处,⽽数据的⾼位字节内容,保存在内存的低地址处。称为⼤端(存储)模式:
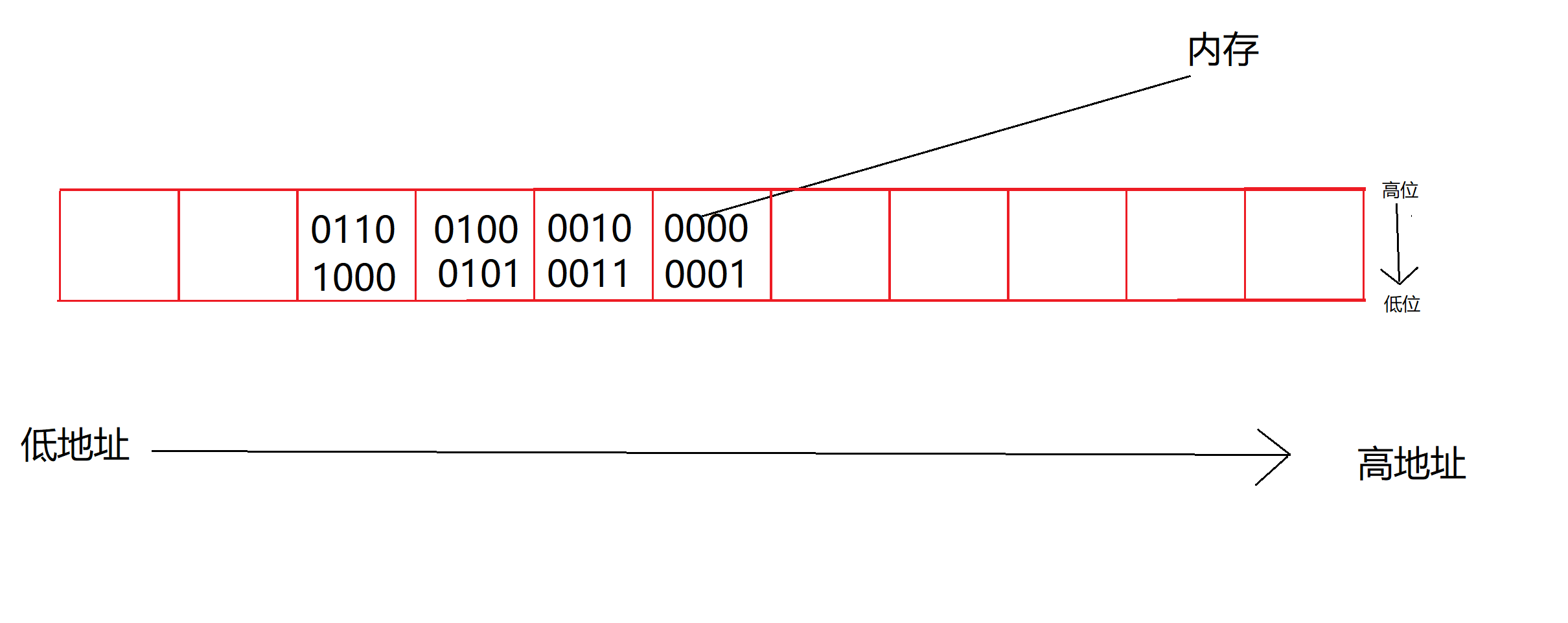
也可以这样存储,数据的低位字节内容保存在内存的低地址处,⽽数据的⾼位字节内容,保存在内存的⾼地址处。称为⼩端(存储)模式:
当然也有其它的存储顺序,但看起来可能会很别扭,很不自然,在此就不列举了。
这两种存储模式就是大小端字节序;另外注意:大小端是对超过一个字节的数据来说的,指针也是以字节为单位的,这也是我在之前图中,规定从上到下是由高位指向低位,而不是由高指针指向低指针;对于单个字节来说,无论是大端还是小端模式,数据都是从低位开始存储,然后是更高位。
那VS x64是大端还是小端呢?
我们可以通过调试来判断:
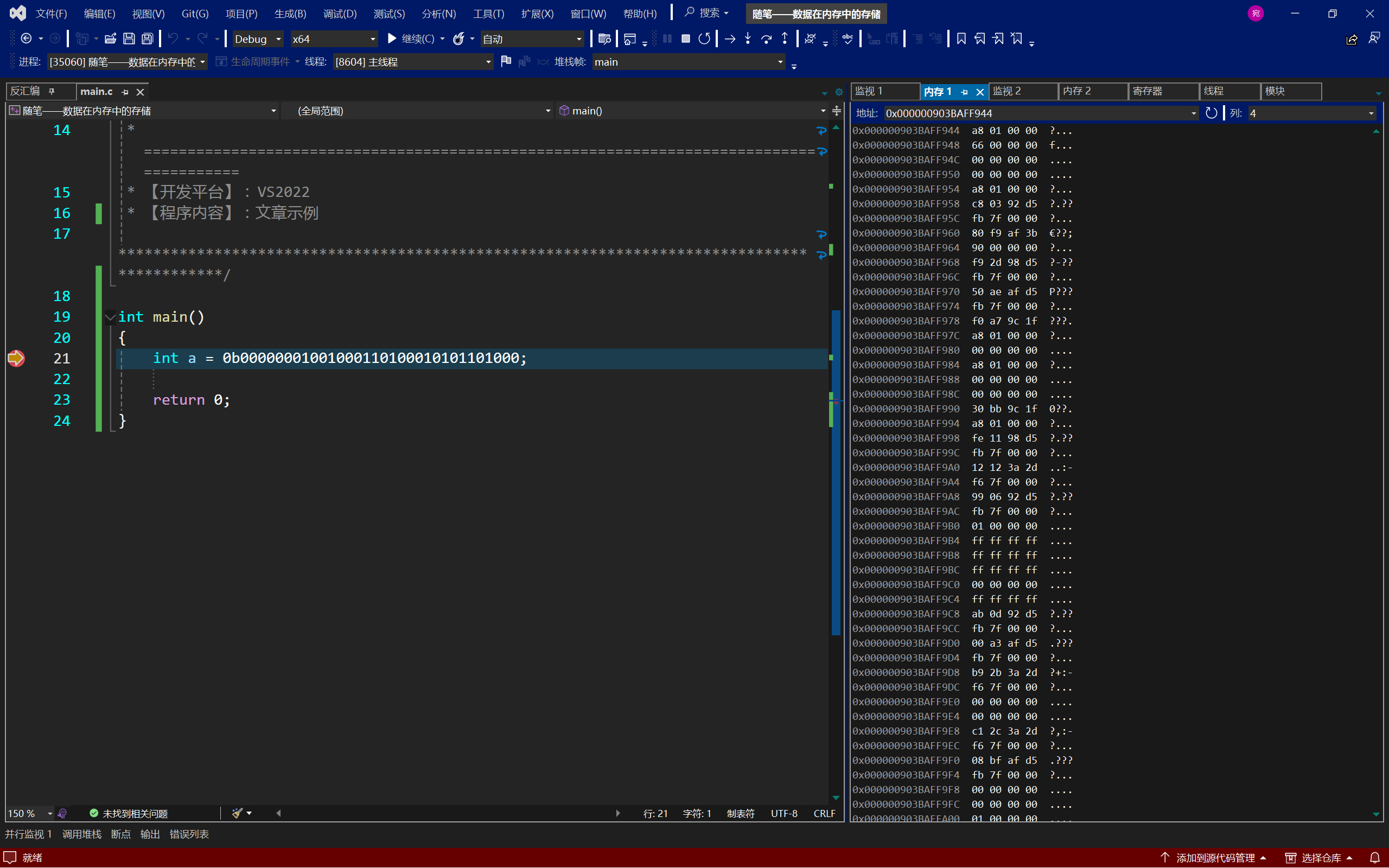
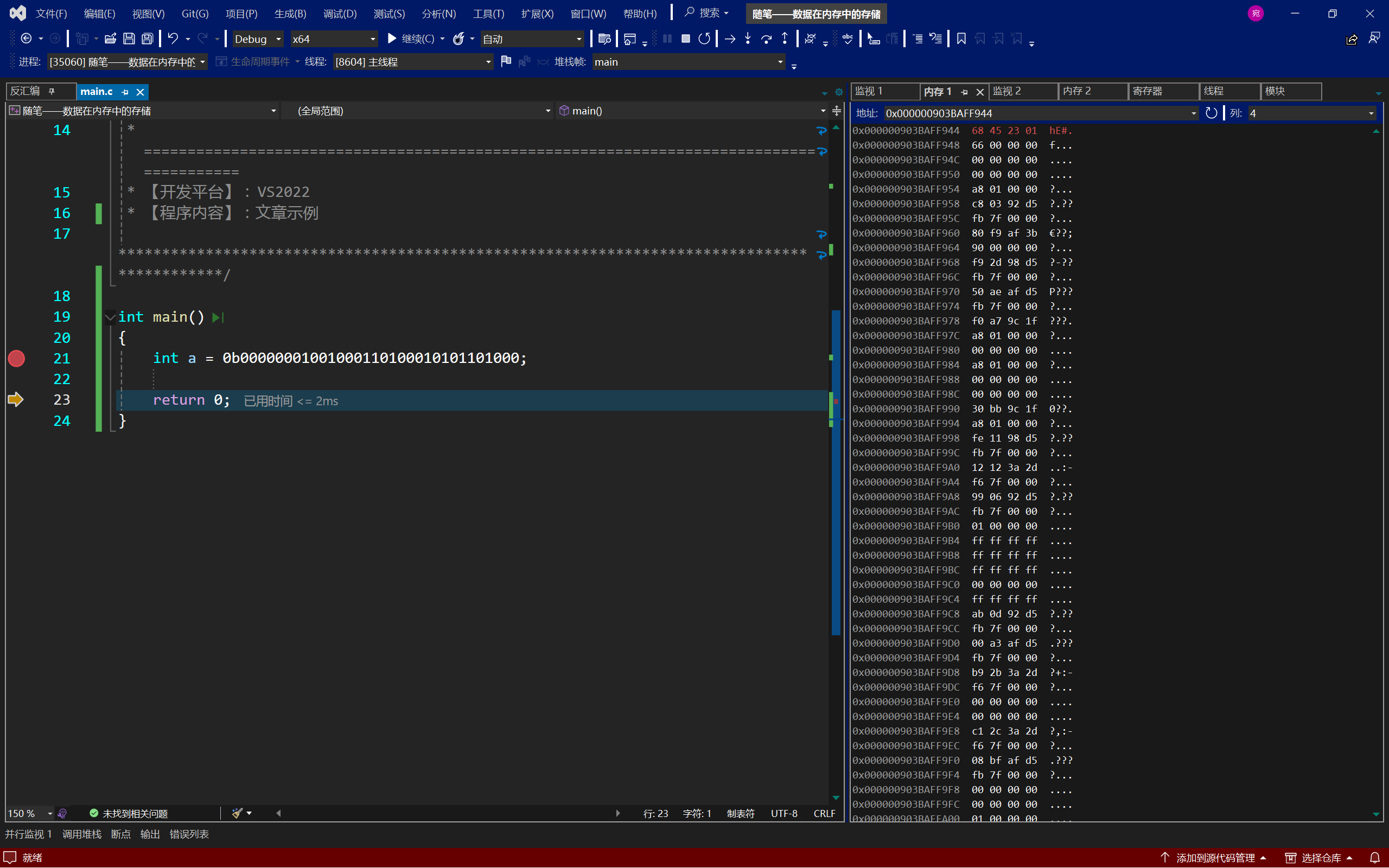
什么?你说看不到这个二进制序列?这是因为二进制序列实在是太长了,真要写出来,不好观察,调试里主要用的都是16进制,那0000 0001 0010 0011 0100 0101 0110 1000转化成16进制是什么呢?就是01234568;我们从调试中看到,计算机把数据的低位字节内容保存在内存的低地址处,⽽数据的⾼位字节内容,保存在内存的⾼地址处,因而VS x64是小端存储模式。
实际上,我们常⽤的 X86 结构是⼩端模式,⽽KEIL C51 则为⼤端模式。很多ARM,DSP都为⼩端模式。有些ARM处理器还可以由硬件来选择是⼤端模式还是⼩端模式。
我们刚刚通过调试获知了VS x64的字节序,那能不能写个程序来判断某个机器的字节序呢?当然可以,下面是代码:
#include<stdio.h>
int main()
{
int i = 1;
char j = (*(char*)&i);
if (j)
{
printf("小端\n");
}
else
{
printf("大端\n");
}
return 0;
}
VS x64环境下的运行结果:
1的类型为int,其二进制序列为0000 0000 0000 0000 0000 0000 0000 0001,把它的值赋给整型i,i的二进制序列就变成了0000 0000 0000 0000 0000 0000 0000 0001,16进制写法就是0x00000001,&i就得到了i的地址,强制类型转换char*,就得到i的第一个字节空间的地址,再对其解引用,查看里面的内容,如果是00(逻辑假),说明数据的⾼位字节内容,保存在内存的低地址处,是大端存储方式;如果是01(逻辑真),则说明数据的低位字节内容保存在内存的低地址处,是小端存储方式。
能不能把char j = (*(char*)&i);替换成char j = (char)i;呢?
当然不行
前面的写法是不把数据拿出来直接在内存中查看,查看的就是低地址处的内容;后面那种写法,是先把数据拿出来再查看数据的最低位,不管大端小端,结果都是01。
下面我们进行几个小实验,来加深对上述知识的理解:
实验一:
#include <stdio.h>
int main()
{
char a = -1;
signed char b = -1;
unsigned char c = -1;
printf("a=%d,b=%d,c=%d", a, b, c);
return 0;
}
能得到什么结果呢?
在开始正式分析之前,有些题外话要说:
我们常说:无符号字符型的取值范围是0~256,有符号字符型的取值范围是-128~127,这到底是怎么来的呢?
首先我们知道字符数据的长度是一个字节,也就是八个比特位,那这八个比特位,有多少种可能性呢?
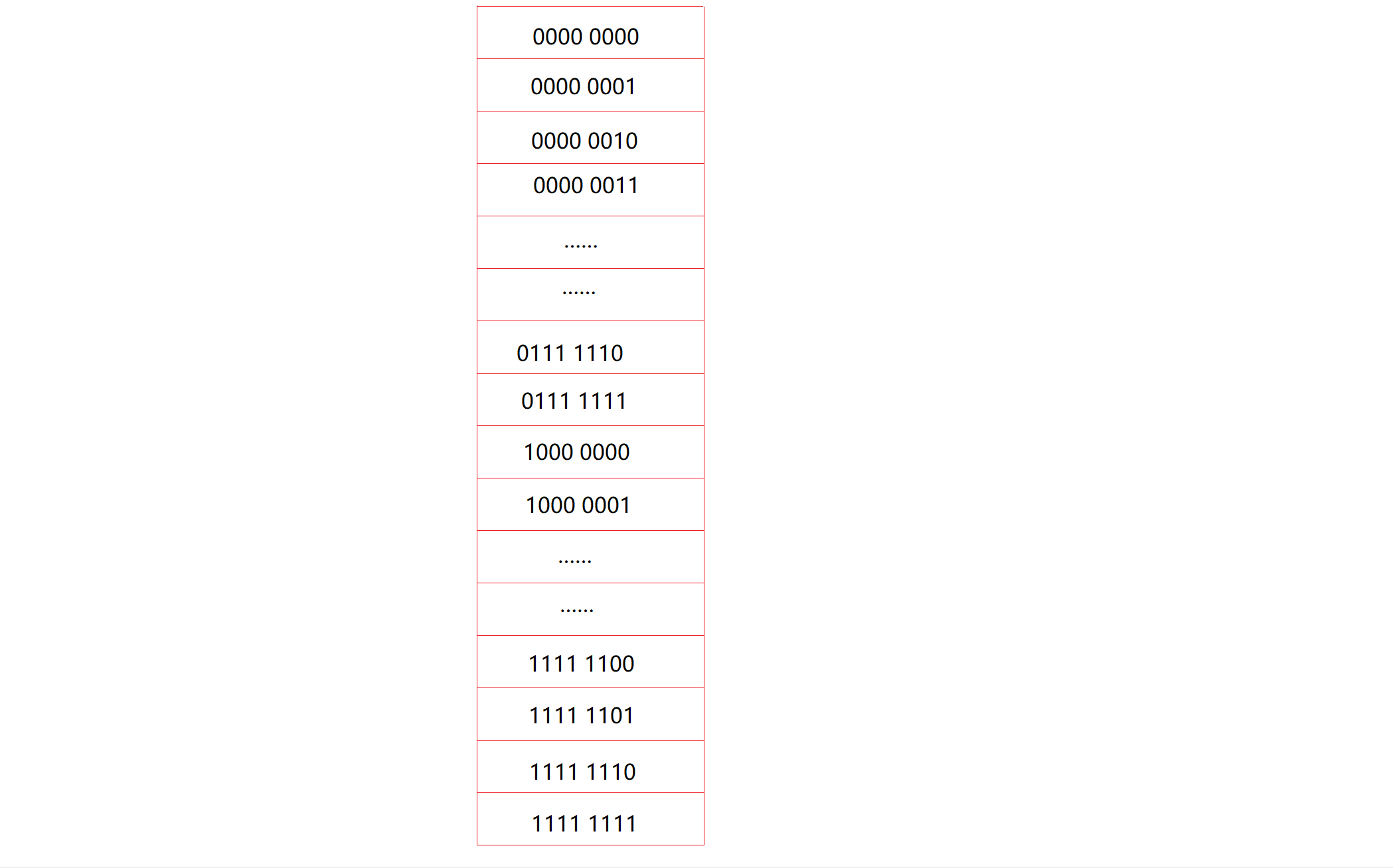
高中时我们就学过排列组合,这种情况要用分步计数法:一共八步,每步两种可能性,那一共是2^8=256种可能性,我们可以画个图形象的表示出来:(你们就当做有256个小格吧)

可以这样填:
那在signed眼中,这些数是什么呢?
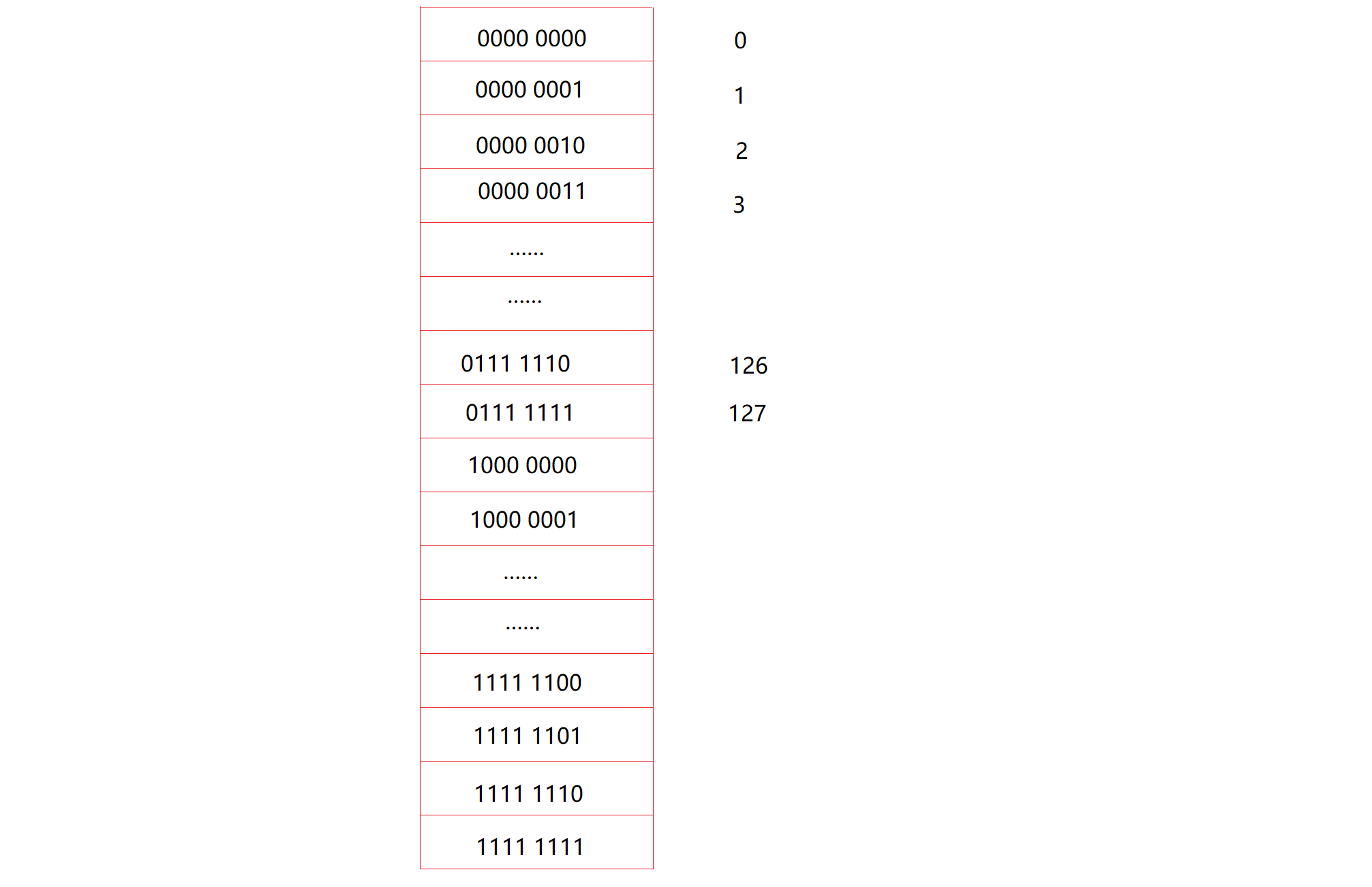
因为是有符号的,所以这八位的最高位是符号位,我们先看正数,也就是符号位为0的,因为正数原码反码补码都一样,比较好算:
负数则要把补码转化成原码,1000 0000 取反后是1111 1111,加一进位溢出超过八个位了,怎么办?
那先跳过这行数,看其他的,结果得到:
那这1000 0000 到底要算成什么数呢?
你看-1,-2,-3,-4……-126,-127它们都是连续的,那就干脆把1000 0000 当成-128吧。
同理,对于其它符号位为1,数值位都为0的数,都是这样处理的;
有符号讲完了,无符号怎么办呢?
无符号可就没这么多讲究了,直接算就行:

怎么样?这种记忆方法很形象,很自然吧,数都是连续的。等会我会用另一种方法,去强调它们的这种连续感。
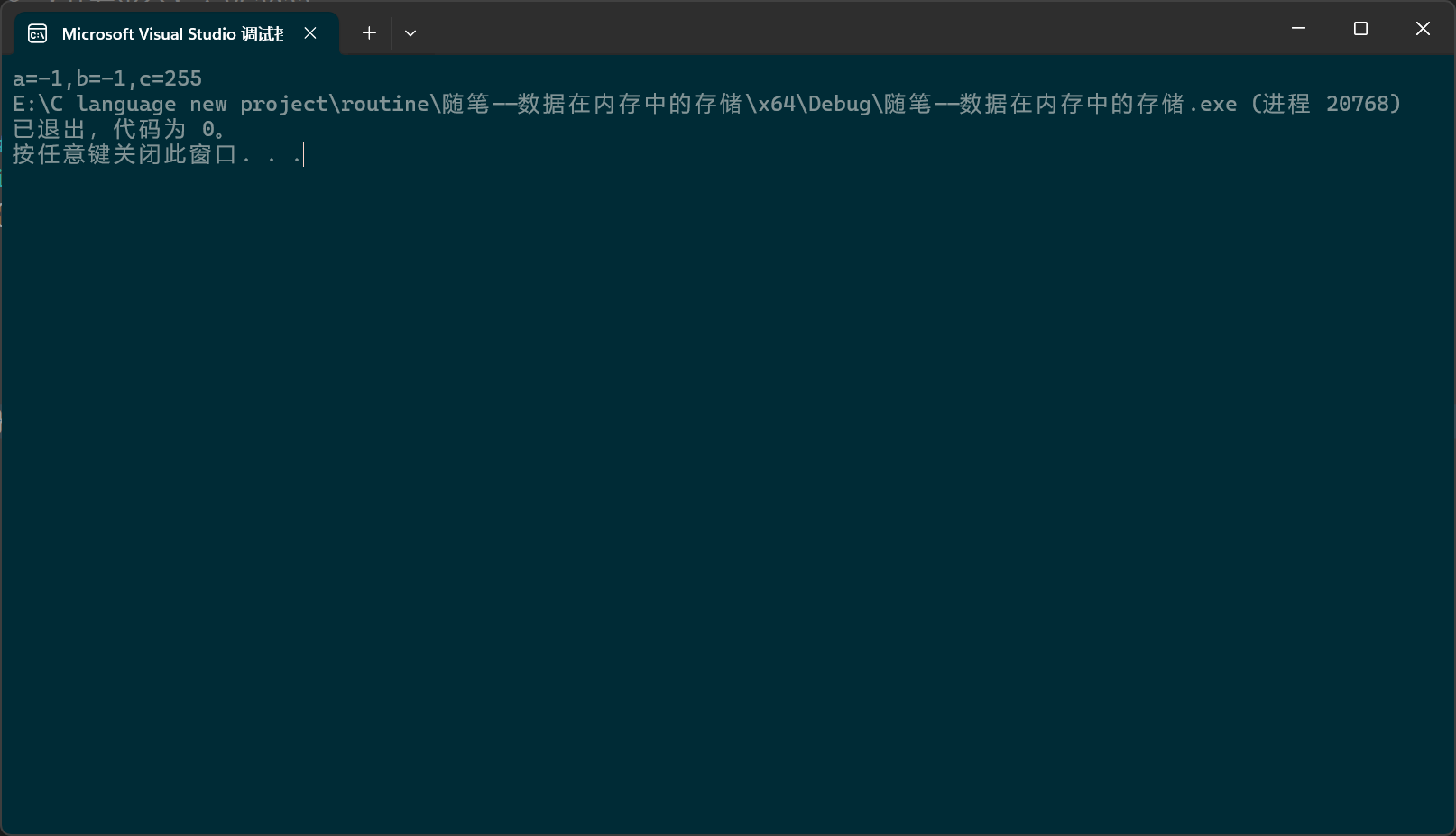
-1是整型数据,原码为1000 0000 0000 0000 0000 0000 0000 0001,-1是负数,需要对原码进行转化才能得到补码,-1的反码是1111 1111 1111 1111 1111 1111 1111 1110,反码加一得补码:1111 1111 1111 1111 1111 1111 1111 1111 ,所以abc的二进制序列串就都是1111 1111;
a,b,c这三个数据的类型分别为char, signed char, unsigned char,它们都是一个字节长度,现在却要用%d,也就是十进制整型的形式打印出来,这意味要对这三个数据进行补位,把它们从一个字节补成四个字节,该如何补位呢?(注:除了char之外,像什么int ,double, float什么的,如果前面没有signed ,unsigned 这种用于修饰有无符号的关键字,那就默认有符号,比如int就相当于signed int; char则要看编译器,这里我们用的是VS,在VS中,char就等于signed char。)
对于有符号整数,要依据它的符号位进行补位,如果是正数,符号位为0,就把待补的位全补为0,如果是负数,符号位为1,就把待补的位全补为1;如果是无符号整数,就把待补的位全补为0。
现在abc中存储的二进制序列串都是1111 1111;而在VS中,signed char就相当于char,都是有符号字符的意思;a和b都是有符号的,最高位就是符号位,所以补位之后就变成了1111 1111 1111 1111 1111 1111 1111 1111 ,这是补码,要想知道会打印出来什么,还要把这个二进制序列转换成原码,如何把补码转化成原码呢?我们刚刚才讲,原码和补码的转换过程是相同的,原码取反加一得到补码,补码取反加一会得到原码;所以要先对上面的补码字符串序列进行取反得到:1000 0000 0000 0000 0000 0000 0000 0000(注意这个不是反码,补码取反得到的不是反码)再加1得到1000 0000 0000 0000 0000 0000 0000 0001,这个转化成十进制整型就是-1,所以第一个和第二个都打印-1,;至于c吗,它是无符号字符型,补位之后就变成了0000 0000 0000 0000 0000 0000 1111 1111,%d是有符号整型格式,0000 0000 0000 0000 0000 0000 1111 1111中的最高位0会被视为符号位,表示正,转换成十进制就是255;
让我们看看调试控制台的结果:
实验二:
#include <stdio.h>
int main()
{
char a = -128;
printf("%u\n", a);
return 0;
}
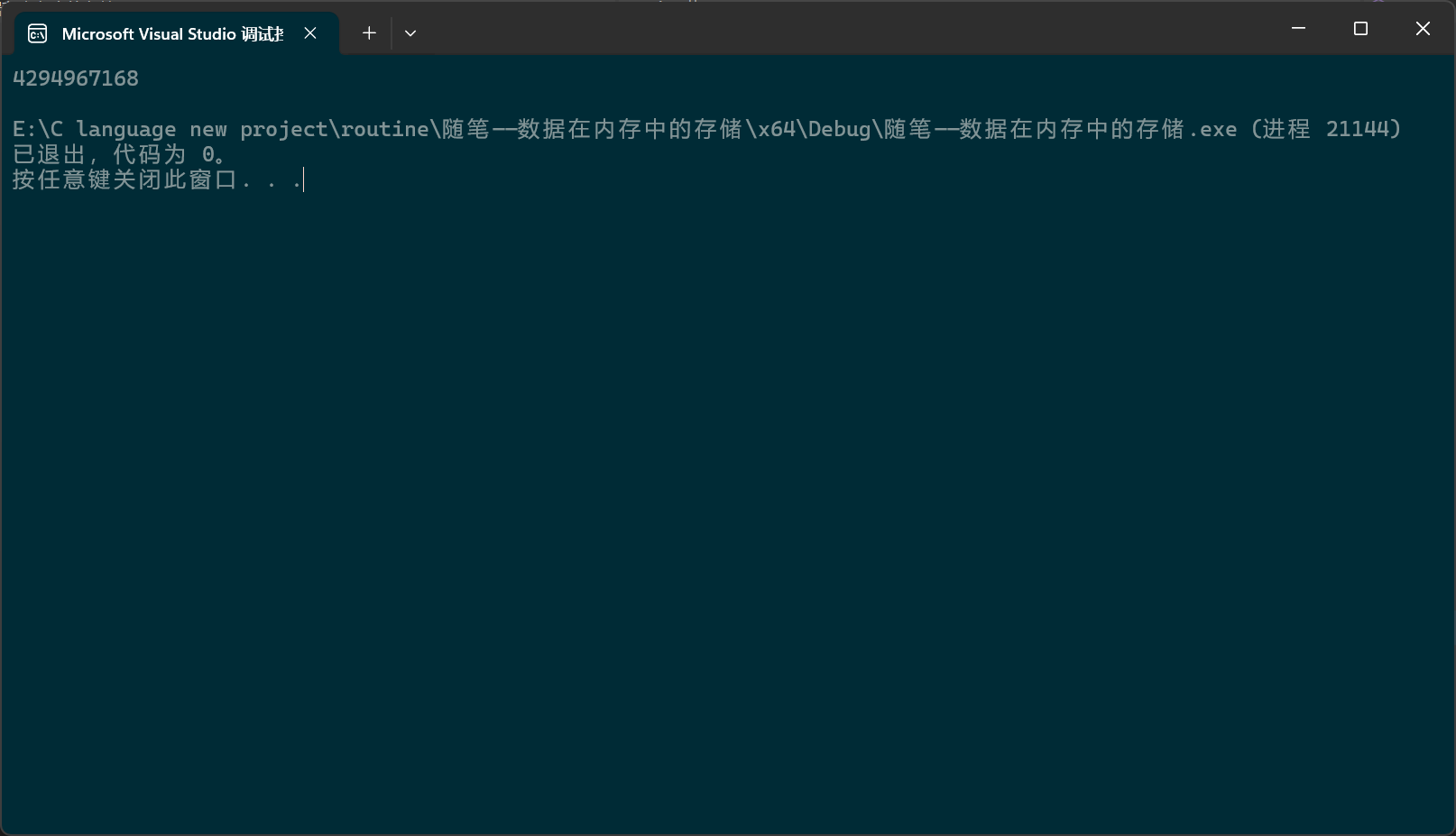
-128是int类型,其原码为1000 0000 0000 0000 0000 0000 1000 0000,取反后变成1111 1111 1111 1111 1111 1111 0111 1111 ,加一就变成了补码:1111 1111 1111 1111 1111 1111 1000 0000,现在a中存的就是1000 0000,
然后要以%u(无符号十进制整型)的格式去打印,位数不够,要补位,VS的char是有符号的,符号位是1,补位变成了1111 1111 1111 1111 1111 1111 1000 0000,然后是以无符号整型的格式去打印,无符号,没有数值位,直接计算,得到的结果就是4 ,294, 967, 168。
调试控制台结果如何呢?
实验三
#include <stdio.h>
int main()
{
char a = 128;
printf("%u\n", a);
return 0;
}
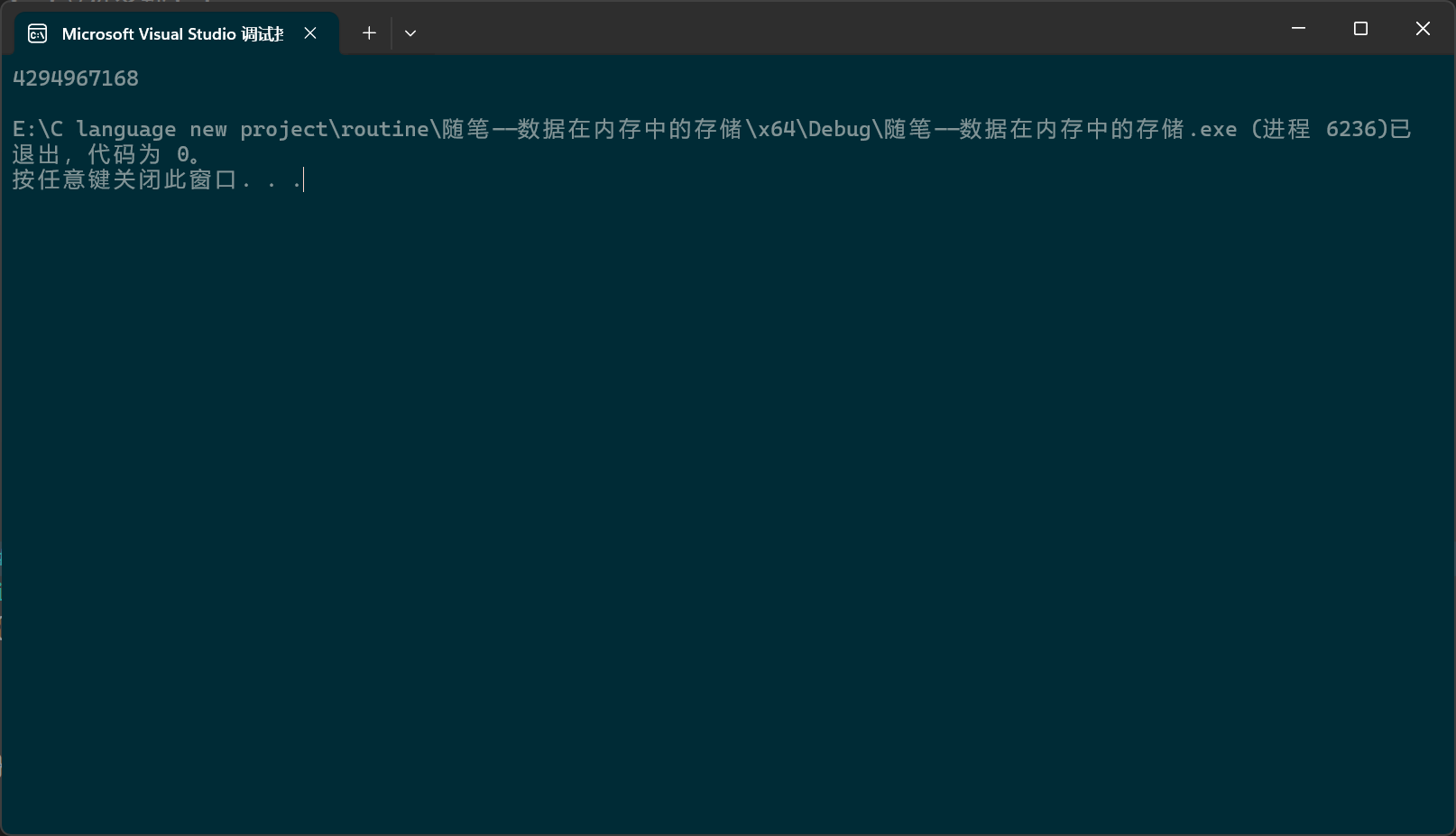
同理:128是int类型,其原码为1000 0000 0000 0000 0000 0000 1000 0000,128是正数,原码反码补码相同,所以128的补码就是1000 0000 0000 0000 0000 0000 1000 0000,现在a中存的就是1000 0000,然后要以%u(无符号十进制整型)的格式去打印,位数不够,要补位,VS的char是有符号的,符号位是1,补位变成了1111 1111 1111 1111 1111 1111 1000 0000,然后是以无符号整型的格式去打印,无符号,没有数值位,直接计算,得到的结果就是4 ,294, 967, 168。
调试控制台结果:
实验四
#include <stdio.h>
int main()
{
char a[1000];
int i;
for (i = 0; i < 1000; i++)
{
a[i] = -1 - i;
}
printf("%zd", strlen(a));
return 0;
}
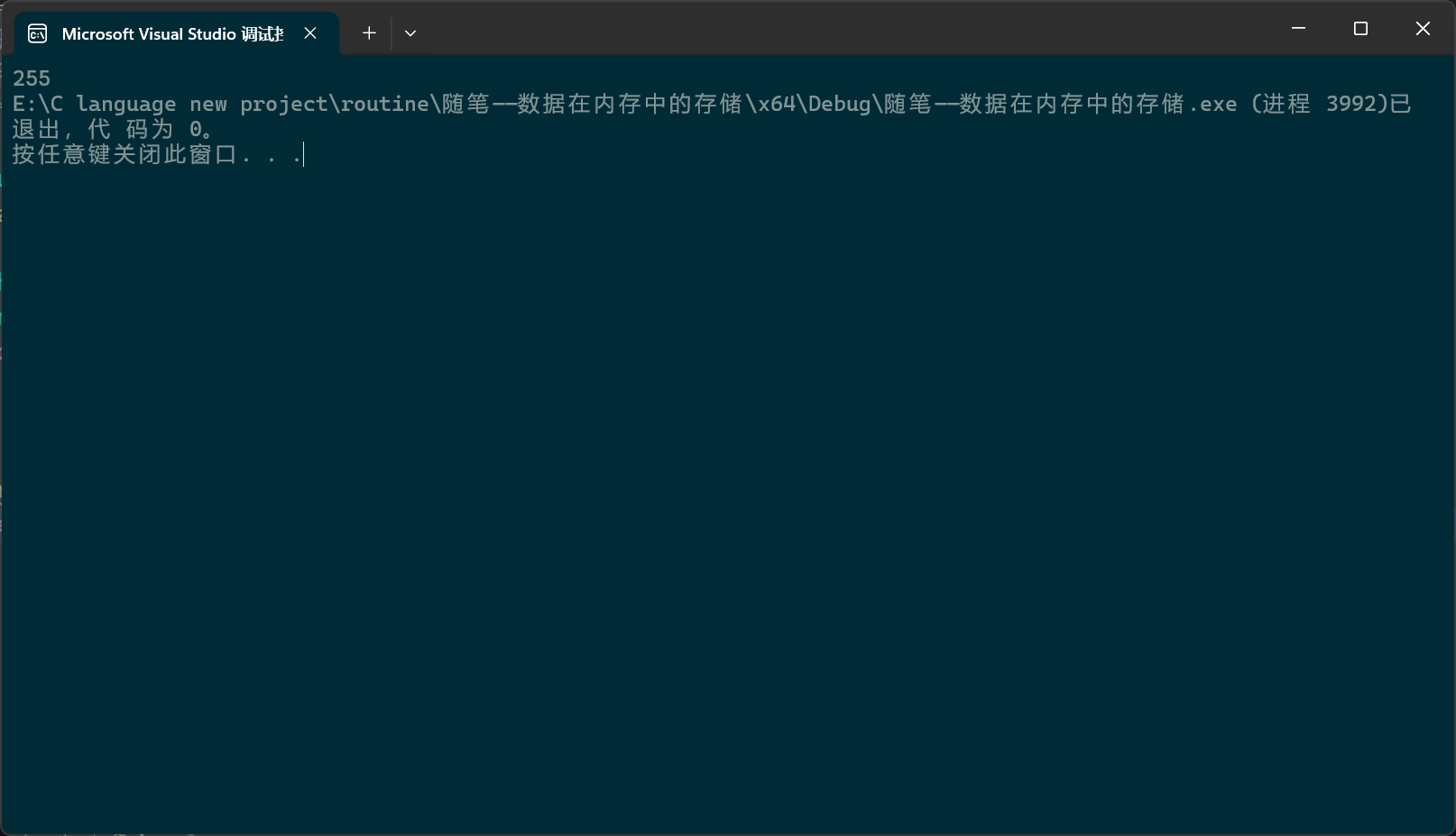
刚才我们才讲过,有符号字符型的取值范围是-128~127。那这-1一直往下减,等到减到-128再减一会得到什么呢?
接下来就要讲之前说的更有连续感,循环感的(找不到词形容了,有更好的形容词在评论区发一个),
石英钟表都见过吧?(一个圆上面有十二个刻度的那种);现在想象有一个圆,上面有256个刻度,每个刻度代表八位二进制序列的一种可能性,可以画成这样(当然我不会把256个刻度全画上去):
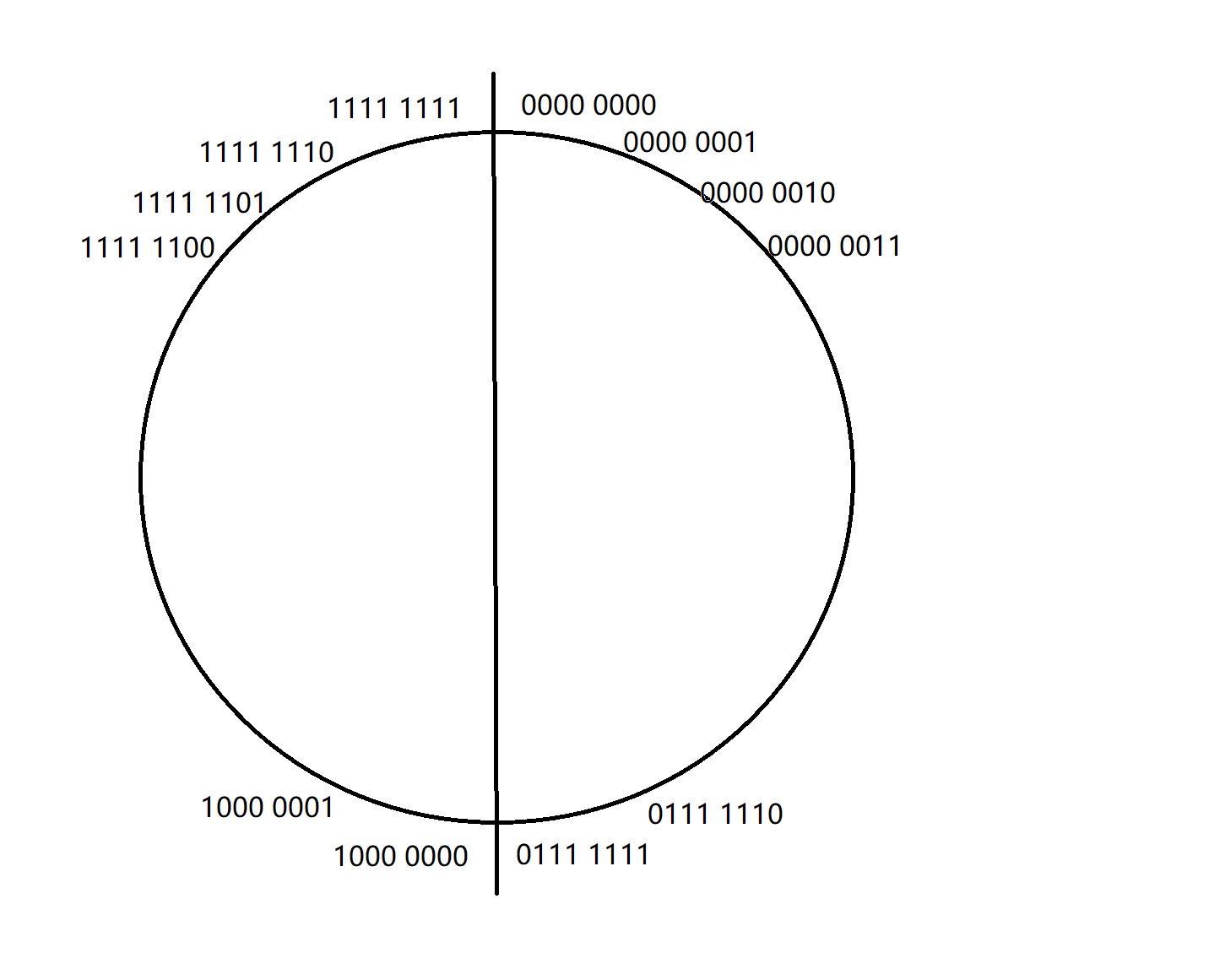
这样顺时针旋转就是加一,逆时针旋转就是减一:(这里的加一减一是对二进制序列来说的)
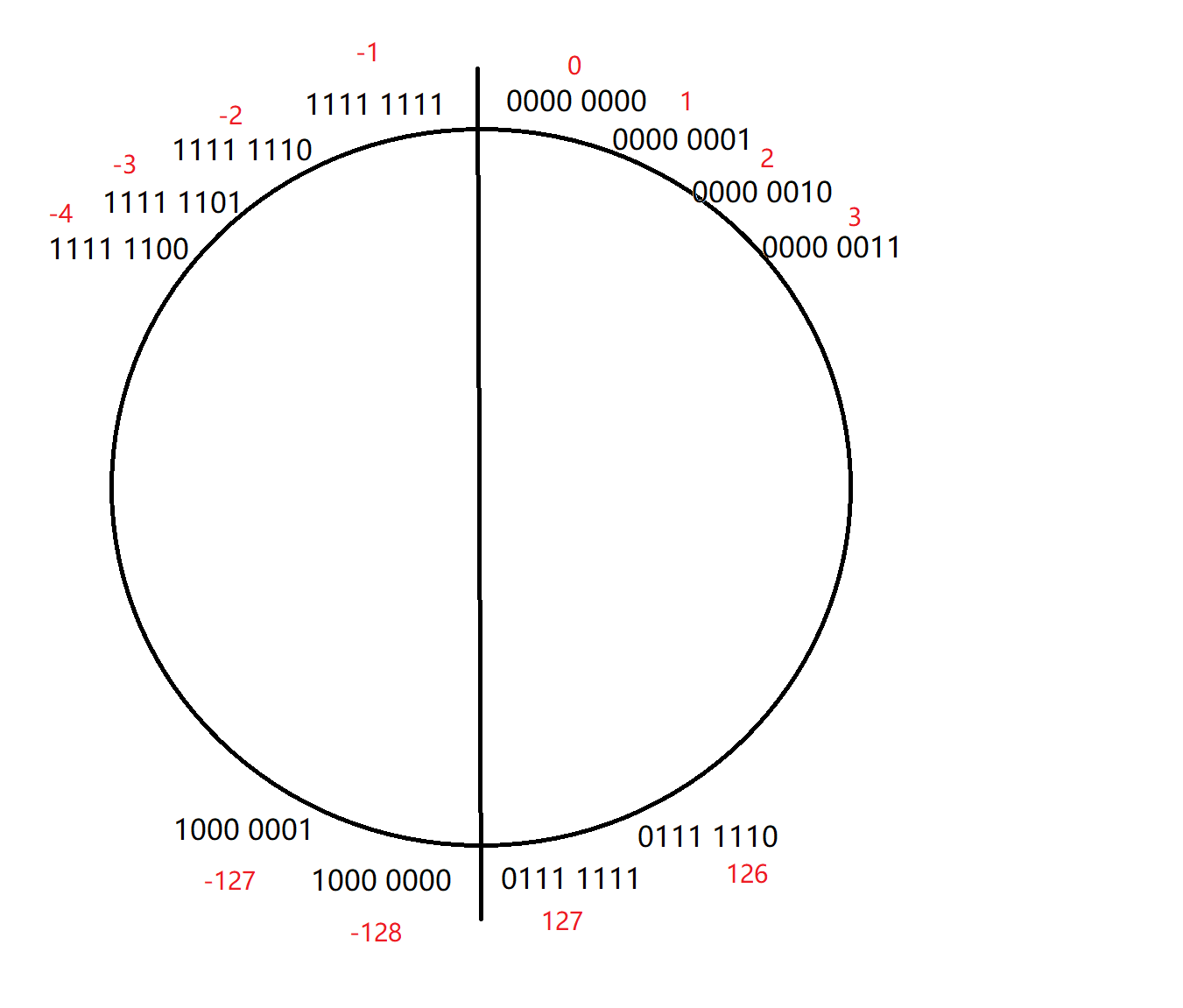
那-128再减一变成多少呢?没错,变成了127。至于strlen大家之前应该都自己写过,它会统计’\0’之前的字符个数,而’\0’的ASCII码就是0,于是问题就变成了:在这个表盘中,从-1到0(包括-1但不包括0),一共有多少个刻度,答案显而易见,是255。
实验五
#include <stdio.h>
unsigned char i = 0;
int main()
{
for (i = 0; i <= 255; i++)
{
printf("hello world\n");
}
return 0;
}
结果会怎样呢?
和刚刚我们画的那个256刻度表盘差不多,只不过刚刚画的是有符号的,而这里的i是无符号的,刻度是从0到255,所以255加一之后会等于零,会无限循环下去。
实验六
#include <stdio.h>
int main()
{
unsigned int i;
for (i = 9; i >= 0; i--)
{
printf("%u\n", i);
}
return 0;
}
首先可以知道,unsigned int永远都是等于等于0,所以会一直循环,然后呢,unsigned int是32位,有2^32=4,294,967,296种可能性,所以范围就是0~4,294,967,295。这样0再减一就会变成4,294,967,295,如果你想让程序打印慢一些,就可以在printf后面加一个Sleep函数,Sleep的头文件是windows.h,这样程序就会变成
#include <stdio.h>
#include<windows.h>
int main()
{
unsigned int i;
for (i = 9; i >= 0; i--)
{
printf("%u\n", i);
Sleep(1000);
}
return 0;
}
效果是这样的:
(VS可能比较智能,其实你写出这种代码它已经报警,把鼠标放在那个波浪线上)
随笔——数据在内存中的存储——实验六示例
实验七
//环境:VS x86(x64跑不动,打印不出来)
#include <stdio.h>
int main()
{
int a[4] = { 1, 2, 3, 4 };
int* ptr1 = (int*)(&a + 1);
int* ptr2 = (int*)((int)a + 1);
printf("%x,%x", ptr1[-1], *ptr2);
return 0;
}
首先声明一下‘%x’是十六进制整数,对于学过指针的,第一个%x应该很简单,如果你没学过指针,理解起来恐怕就有点难了,指针内容太多了,我只是一个学生,没啥空,就算写估计也只有寒暑假有空,而且实际上我大概率不会写,你们就先看看别人文章或者资料吧。
&a取出的是整个数组的地址,其指针类型是int(*)[4],对其加一,跳过指向内容的大小,也就是int[4],这样现在指针就指向4后面的那个int,再把这个指针类型强制转换成int*,这意味现在这个指针的单位变化范围是int大小,ptr[-1]等同于*(ptr-1),于是指针就指向4了,当然这个‘4’是十进制的‘4’,要转换成十六进制,于是还是‘4’。
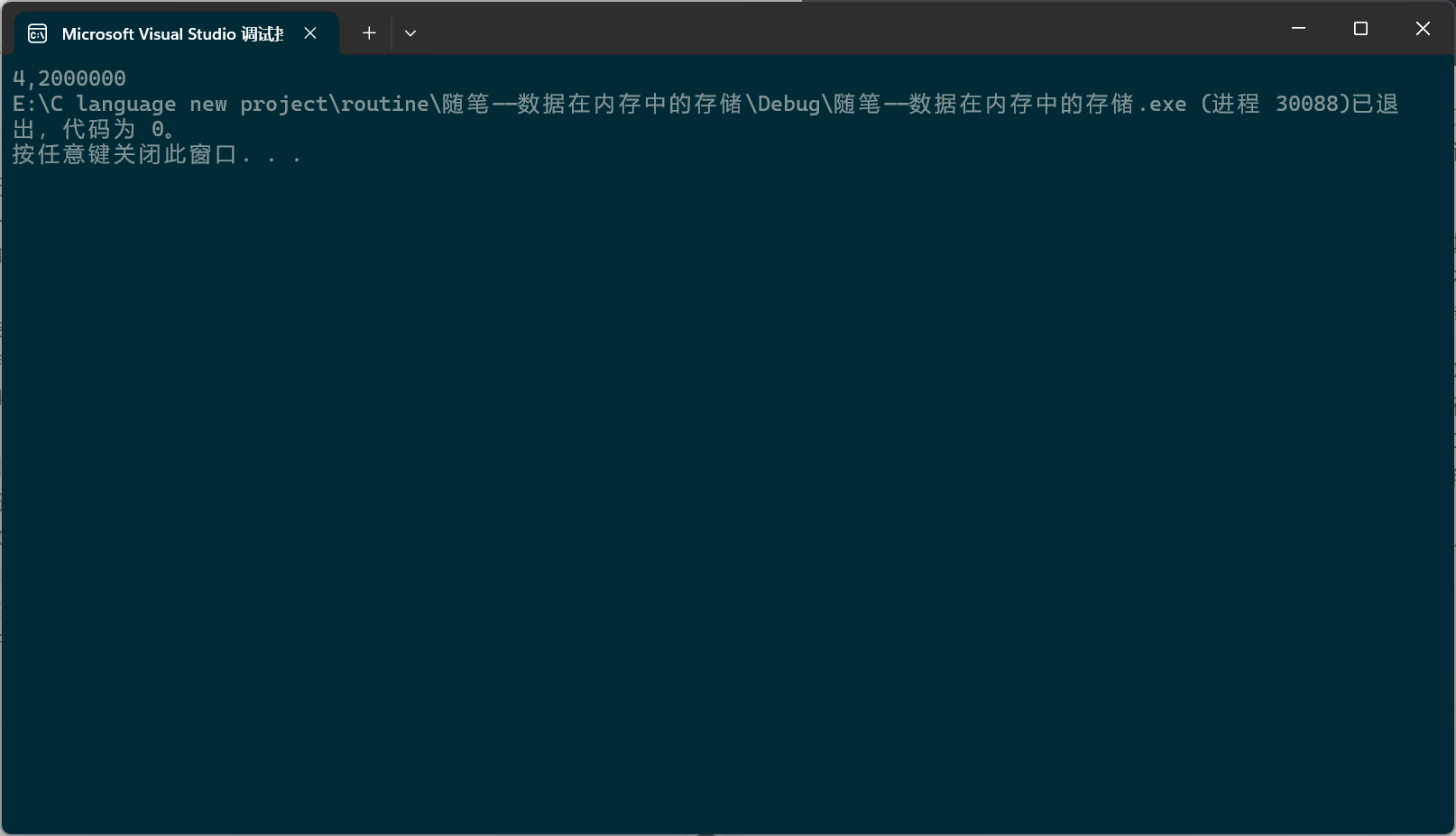
十进制1,2,3,4分别用32比特位十六进制表示就是00 00 00 01, 00 00 00 02, 00 00 00 03, 00 00 00 04;VS是小端存储方式,而数组中元素的地址都是连续的,所以内存中这个数组的存储内容就是(这里用十六进制而不是二进制表示,原因还是二进制太长了)01 00 00 00 02 00 00 00 03 00 00 00 04 00 00 00,a表示数组首元素地址,强转成int后加一就是加一(所以这里的int用char*应该也是可以的),这样就增大了一个字节长度,再强转成int*,现在指针指向的就是第一个00,随后对其解引用,指针ptr2的类型为int*,读取32个比特位,这样读出来的就是00 00 00 02,然后因为VS是小端存储,所以打印出来是02 00 00 00(第一个0被省略了)。
浮点数在内存中的存储
计算机作为一个计算工具,肯定不能只支持整数的计算,必然有进行小数计算的需求,这时,如何把小数存储在内存中就变成了一个问题;在计算机行业发展的初期时代,各个计算机厂商对这个问题都给出了不同答案,这倒也好理解,毕竟一千个读者心中就有一千个哈姆雷特,面对同样的问题,不同的人有不同的解决方案,但由于缺乏统一的浮点数存储方法,不同型号的计算机之间难以进行数据交换和协同工作。
在一众不同的浮点数存储方案中,由英特尔公司推出的基于单片8087浮点数协处理器的浮点数表示法及定义的运算因其较为合理先进的特点被各计算机厂商广泛采用,成为了事实上的工业标准。
于是,负责定义国际技术标准的电气电子工程师学会(简称IEEE)便采纳了该方案,于1985年发布了著名的“IEEE 754──浮点算法规范”,至今仍为最广泛使用的浮点数运算标准,被誉为计算机科学的一项伟大成就。
下面我们就基于该标准去理解浮点数在内存中的存储方式。
根据IEEE 754,任意⼀个⼆进制浮点数V可以表示成下面的形式:
V
=
(
−
1
)
S
∗
M
∗
2
E
V=(-1)^S*M*2^E
V=(−1)S∗M∗2E
- ( − 1 ) S (-1)^S (−1)S表示符号位,当S为0时,V为正数;当S=1时,V为负数
- M表示有效数字,M是大于等于1,小于2的
- 2 E 2^E 2E表示指数位,注意E是无符号整型
当把一个浮点数转化成这种形式后,再把SME这三个变量做一定处理存储在内存中,怎么处理呢?
S没什么好处理的,它就一位,不是1就是0,不用做处理;
M和E就要处理了
对于M来说:由于 1≤M<2 ,或者说,M可以写成 1.xxxxxx 的形式,其中 xxxxxx 表示小数部分。在计算机内部保存M时,默认这个数的第⼀位总是1,因此可以被舍去,只保存后面的xxxxxx部分。比如保存1.01的时候,只保存01,等到读取的时候,再把第⼀位的1加上去。这样做的目的是节省1位有效数字,提高M的精度。
对于E来说:有时转换成标准形式后指数E会为负数,比如对于0.00011来说,要转换成标准形式就是1.1*2-4
而E又是无符号整型,所以要选取某个数作为基准(就像物理里的零势能面),把E与这个基准的偏移量存入内存,比如32位的浮点数E的基准数是127,对于0.00011来说,-4+127=123,实际存的是123的二进制;至于为什么非要把E规定为无符号整型而不是有符号整型,可能是无符号整型不用考虑原码反码补码相互转换,更为简单不易出错。
处理好了就要存了,怎么存?
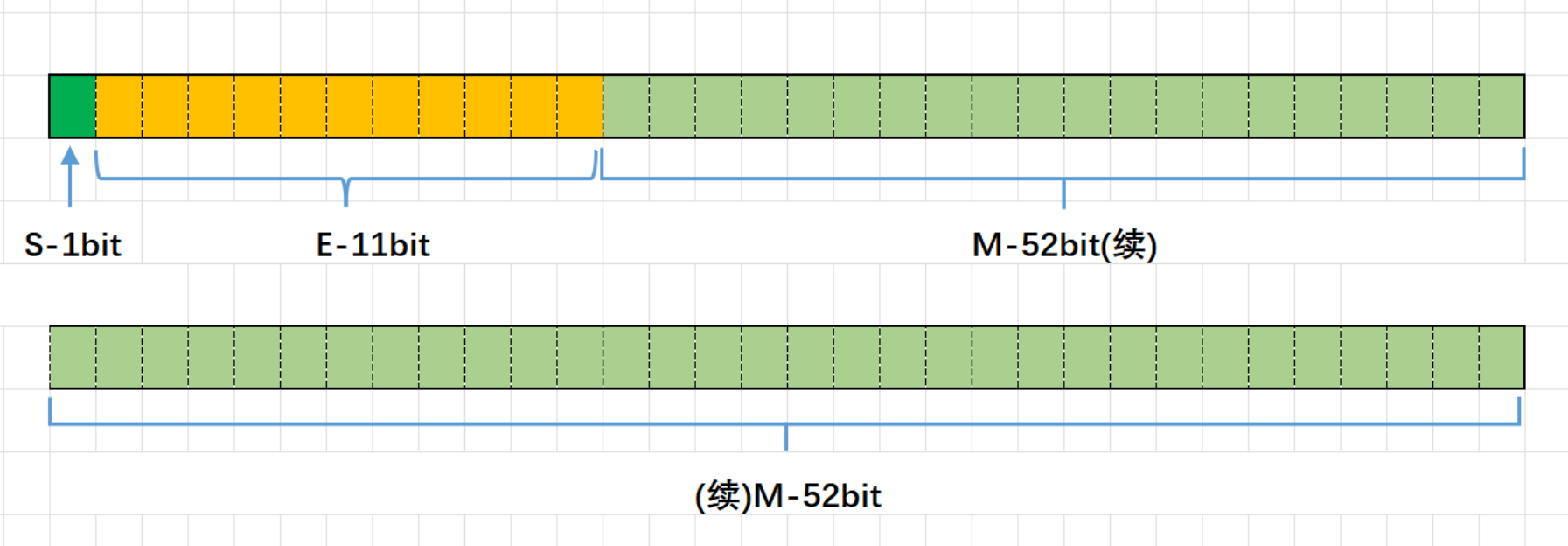
对于32位的浮点数(也就是float),最高的1位存储符号位S;接着的8位存储指数E(处理后的),此时E的基准数是127;
剩下的23位存储有效数字M(处理后的):

对于64位的浮点数(或者说double),最⾼的1位存储符号位S;接着的11位存储指数E(处理后的),此时E的基准数为1023;
剩下的52位存储有效数字M(处理后的):
题外话:
因为M的位数大了不少,所以double的精度比float高,实际上VS也会把浮点数默认为double,若是把一个浮点数赋给类型为float的变量,就会经过类型转换从而丢失精度。
像这样写,就有可能丢失精度:
float i = 5.25;
若是想让VS把浮点数默认为float,就要在浮点数后面加个后缀f:
float i = 5.25f;
例如:若要将十进制小数+5.25转换成float类型(VSx64环境),首先要将其转换成标准形式,有
+
5.25
=
(
−
1
)
0
∗
1.0101
∗
2
2
+5.25=(-1)^0*1.0101*2^2
+5.25=(−1)0∗1.0101∗22
也就是未经处理的S=0,M=1.0101,E=2。然后把对这三个变量做处理:
- S=0
- M=0101(不满23位后面用0补位)
- E=2+127=129(二进制是10000001)
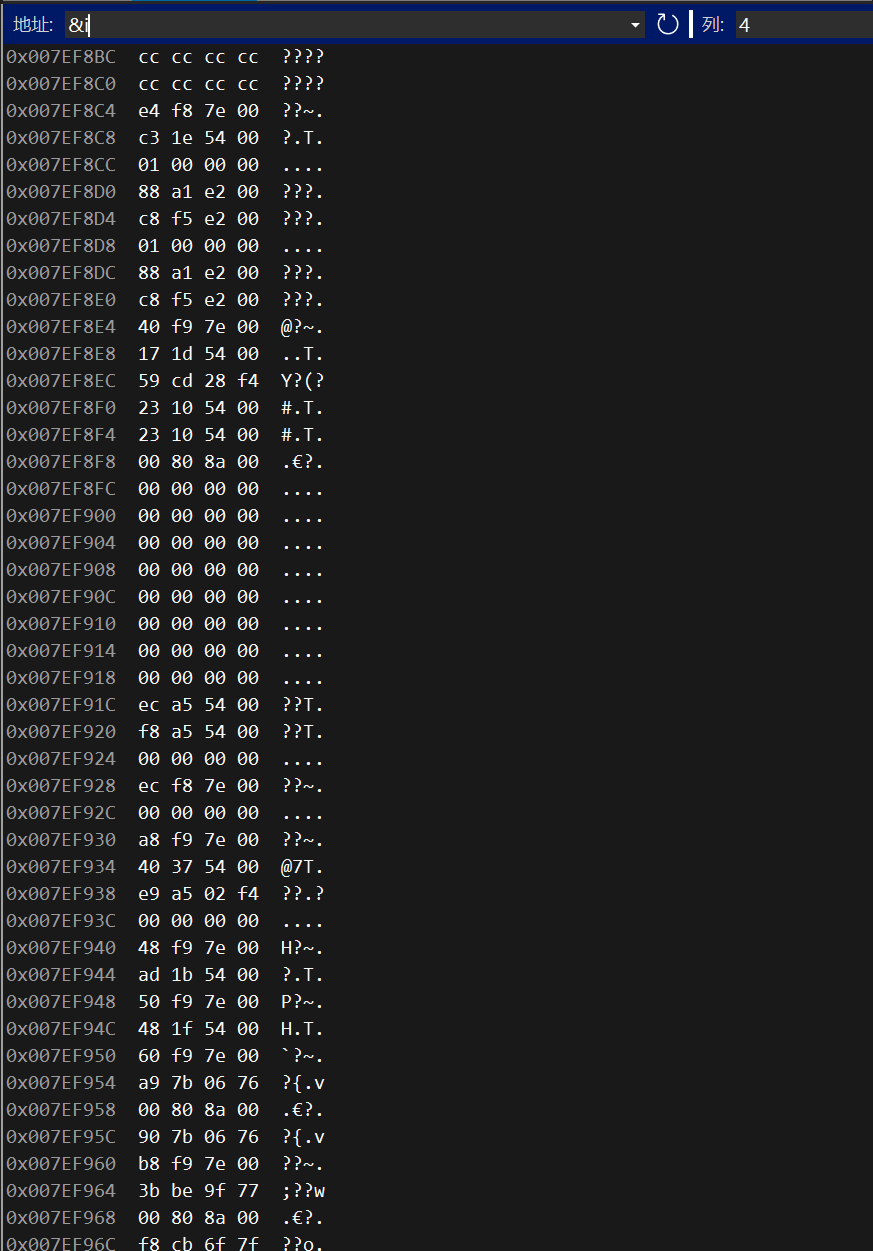
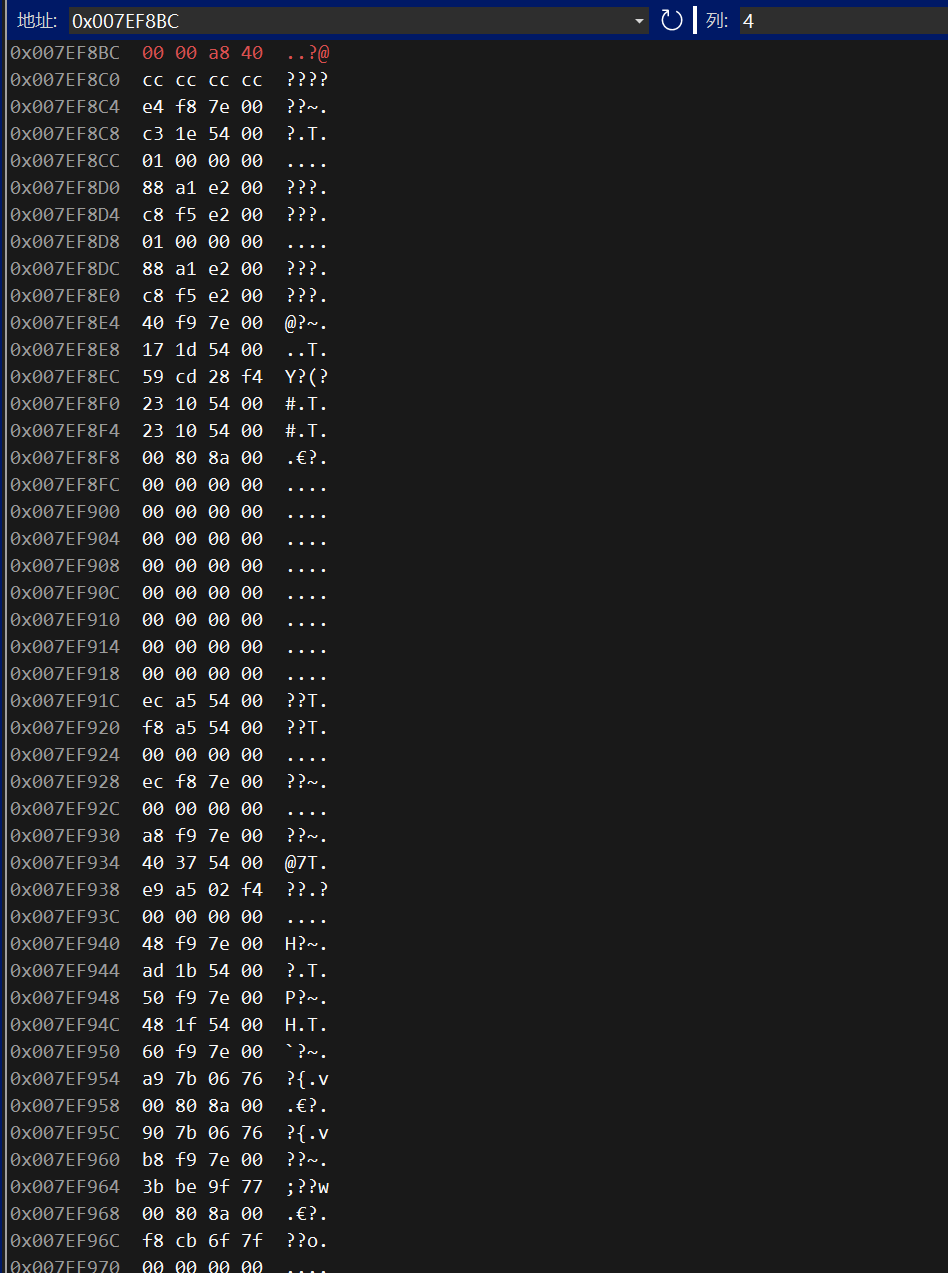
所以要存入的二进制序列串就是0 1000 0001 0101 0000 0000 0000 0000 000 (十六进制表示是0x40A8 0000)
别忘了,float是四个字节大于一个字节的,存储时有大小字节序的区分,VS是小端字节序,实际存入的就是00 00 A8 40,调试一下看看:
#include <stdio.h>
int main()
{
float i = 5.25f;
return 0;
}
有时候处理后的E转换成二进制序列会非常极端
需要稍微留意一下:
- E(处理后的)的二进制序列全为0,这意味着浮点数V非常小,其绝对值很靠近0,V可能像0.0000000000000(一大串0)1111这样,因为数值很小,所以这种浮点数对精度要求更高,(精度不高甚至可以直接当成0);为了提高这种浮点数的精度,我们不再使用之前的公式:
V = ( − 1 ) S ∗ M ∗ 2 E V=(-1)^S*M*2^E V=(−1)S∗M∗2E
而是使用一个精度更高的转化方法:
在这个方法中,这时,浮点数的指数E(未经处理的)被强制当成1-127(或者1-1023)也就是-126或者-1022,有效数字M不再加上第⼀位的1,而是还原为0.xxxxxx的⼩数。(可以看看之后的实验)
- E(处理后的)的二进制序列全为1,这意味着浮点数V非常大,这时,我们把这个浮点数视为正负无穷大(正负取决于符号位s);
说实话,这两个极端情况,我其实没听懂,以后有机会再做深入说明。
来做个小实验吧。
代码如下:
#include <stdio.h>
int main()
{
int n = 9;
float* pFloat = (float*)&n;
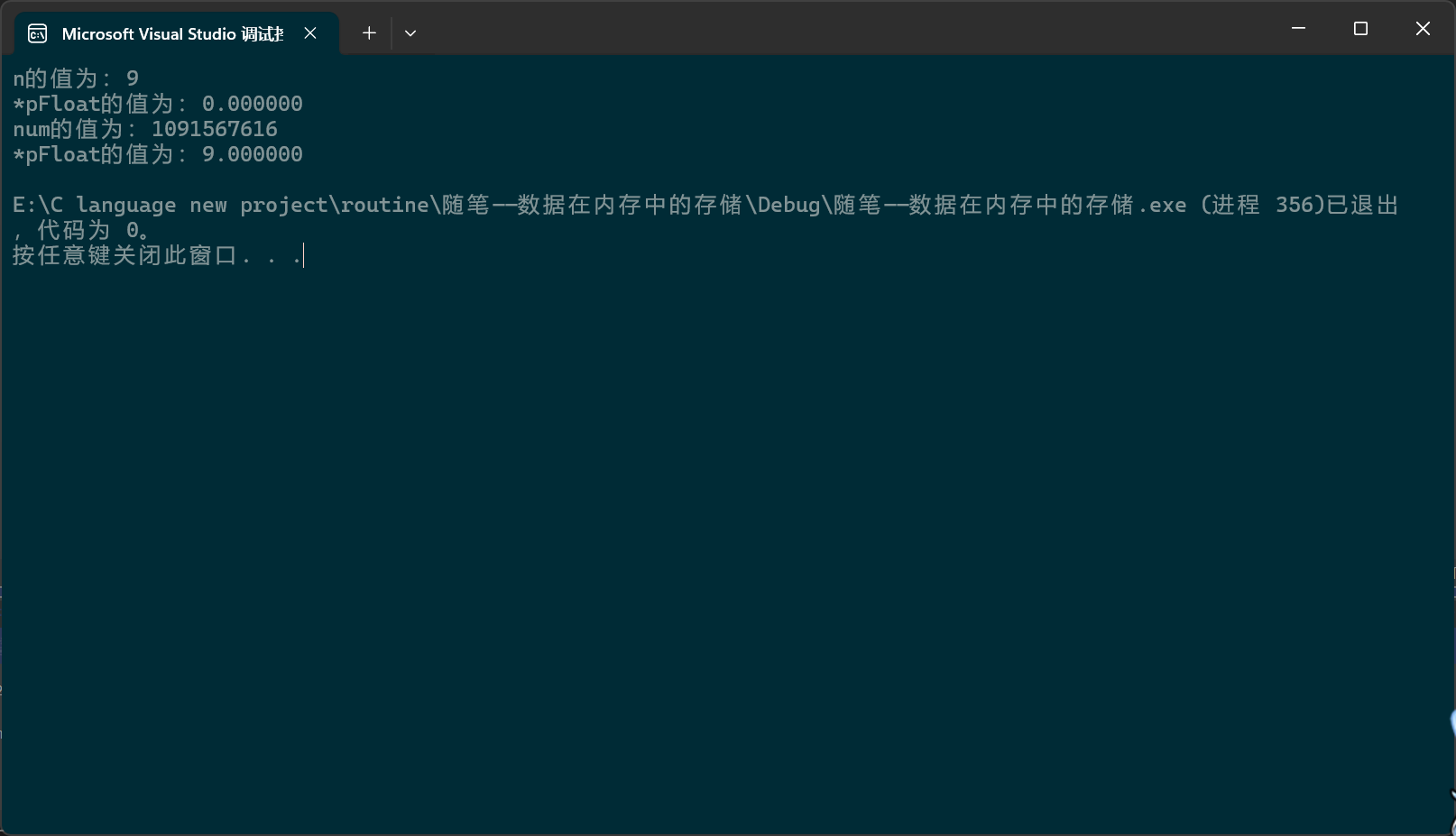
printf("n的值为:%d\n", n);
printf("*pFloat的值为:%f\n", *pFloat);
*pFloat = 9.0;
printf("num的值为:%d\n", n);
printf("*pFloat的值为:%f\n", *pFloat);
return 0;
}
9的原码是0000 0000 0000 0000 0000 0000 0000 1001,然后9是正数,正数反码就是原码,所以内存中实际存储的就是0000 0000 0000 0000 0000 0000 0000 1001,如果这串序列被当成32位浮点数,那么,就会被当成
0 00000000 00000000000000000001001,S是0,意味这是正数,E为全0,意味这是第一种极端情况,于是浮点数V就会被还原为
V=
(
−
1
)
0
(-1)^0
(−1)0 * 0.00000000000000000001001*2(-126)
总之这个数很小,而%f是只精确到小数点后六位,所以直接打印出了0.000000;
9.0是正数,S是0,转化成二进制是1001.0,转化为标准形式是1.001*2^3,未经处理的E是3,于是内存中存的就是0 1000 0010 00100000000000000000000,把它看成%d(整型),第一位是0,是正数,补码就是原码,原码就是0 1000 0010 00100000000000000000000,转化成十进制就是1091567616。
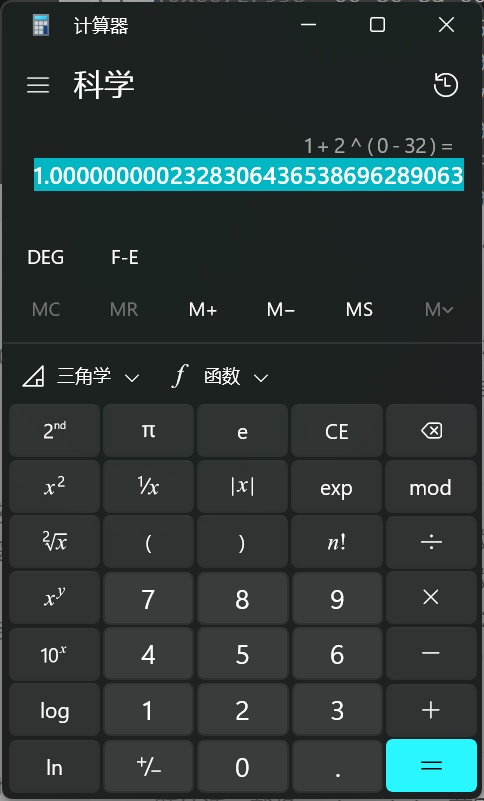
另外注意,有些浮点数的有效数M很长,长到连23或者52位都存不下,这样就会丢失精度,其结果可能是把这个数打印出来,打印的结果与原数非常接近,但并不相同。我们可以反推找到一个浮点数用来示例,我们先假设这个浮点数是float型,float型的M就23位,那干脆拿1+2-32
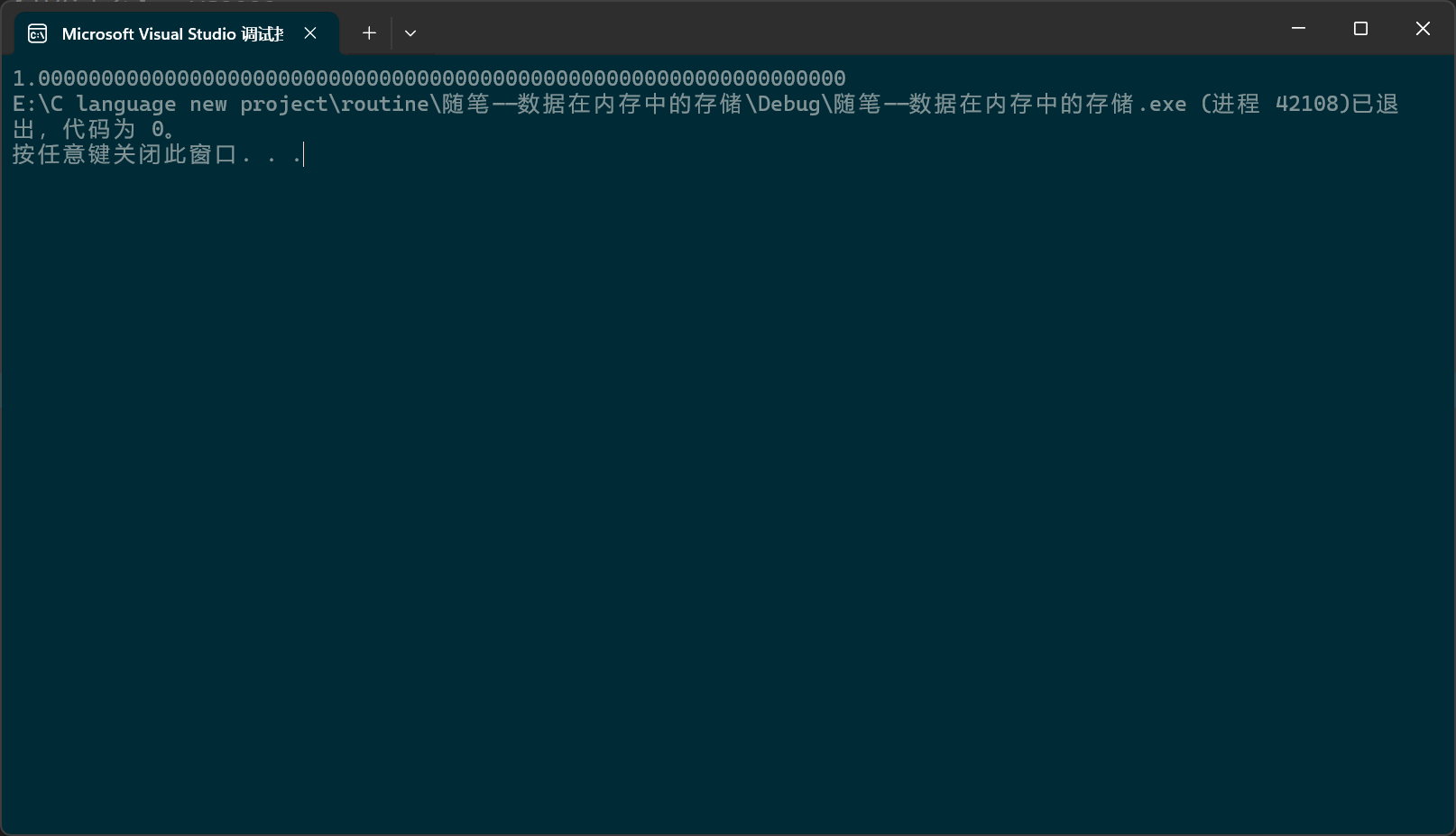
计算器算出的结果是1.0000000002328306436538696289063,再把这个数赋给一个类型为float的浮点型,结果最后打印果然存在微小差别。
#include <stdio.h>
int main()
{
float i = 1.0000000002328306436538696289063;
printf("%.64f", i);
return 0;
}
题外话:就像unsigned char范围是0~255是因为8位二进制序列串一共就256种可能性,或者说,unsigned char的取值范围是由其储存方式决定的一样,浮点数的取值范围也是由其储存方式决定的。储存方式是因,对应范围是果。
完
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









