







web自动化 ,一个老生常谈的话题 ,很多人的自动化之路就是从它开始 。它学起来简单 ,但做起来又比较难以驾驭 ;它的执行效率慢 、但又是最接近于用户的操作场景 ;
1.web自动化中的三大亮点技术
我们先聊聊 ,在web自动化中都有哪些亮点技术 ?这里就不得不谈的以下三种技术,分别为 :
-
PO模式 :页面对象模型 ,将页面对象和操作逻辑分离 ,解决的是代码扩展性的问题 。
-
数据驱动 : 通过添加不同数据 ,让测试用例循环运行 ,达到同一测试用例验证不同数据的目的 ,解决数据覆盖问题 。
-
关键字驱动 :通过编写关键字 ,驱动测试用例运行 ,解决用例编写效率问题 。
当然 ,在框架中再结合上用例的配置方式 ,就能最大化的解决编写效率问题、减少人工编写用例时间 ,比如:
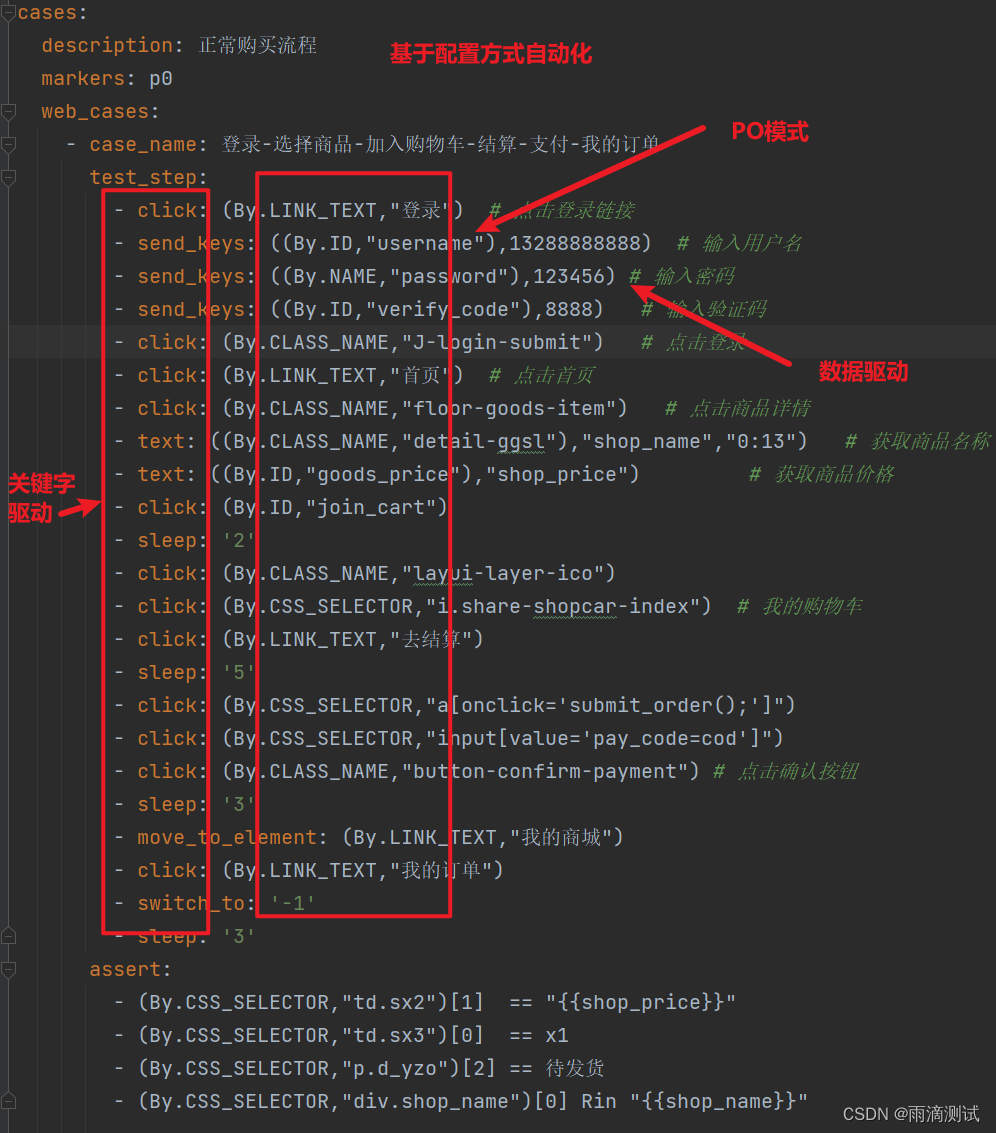
2.web自动化能解决什么问题 ?
在做功能测试时,经常会出现如下的情况:
-
每次测试都要进行大量的回归测试 ,回归耗时耗力 。
-
做兼容性测试时,也需要对已测试的功能进行各种浏览器的兼容测试 。
以上的测试都有一个共同特点 ,就是重复性的测试 ,且占用时间长 。
那么 ,长时间的这种重复性的测试会导致如下问题 :
-
测试效率低下,有时候回归测试的时间可能占总时间的1/5 ~ 1/3 。
-
回归测试时,最容易出现人为的漏测 ,导致可能出现bug流到线上 。
-
长时间的回归测试可能会导致测试人员觉得测试工作枯燥,对测试工作失去兴趣 。
怎么办 ? 最好的方案就是自动化解决 ,而如果你的系统是B/S架构 ,那无疑就是使用web自动化 。
3.为什么是selenium ?
其实做web自动化的框架或工具有很多 ,比如Robot Framework 、Cypress 、TestComplete等 。那我们为啥要选择selenium呢 ?
第一 : 主流 , 它目前是web自动化中最流行的工具 ,流量大意味着需求广 ,当然在应聘或工作中也就会用到的多 。
第二 :需求适应性好 ,不同项目的自动化需求是不同 ,有的只是做一些流程用例 、有的还想跑兼容 ,有的想在window上跑 ,同样有的想在Linux下跑 。而selenium这些个性化需求都能满足要求 。
4.selenium特点
-
开源 : 完全可以自由下载 ,并且可以根据需求增加某些功能 。
-
跨平台 : Linux ,Windows ,Mac
-
支持多浏览器 : Firefox ,Chrome ,IE ,Edge ,Opera ,Safari 。
-
支持多种语言 : python ,java ,c# ,JavaScript ,ruby,php 。
-
成熟稳定 : 目前已被互联网的各种大小公司所使用 。
-
功能强大 : 基本能实现浏览器中的绝大多数操作 。
5.selenium安装
学习selenium ,肯定离不开语言 ,这里我选用的是python ,所以学习前请安装python 。
python的推荐版本 :3.6~3.9之间的版本
python下载地址 :Download Python | Python.org
-
selenium安装 :
pip install selenium -
selenium验证 :
pip show selenium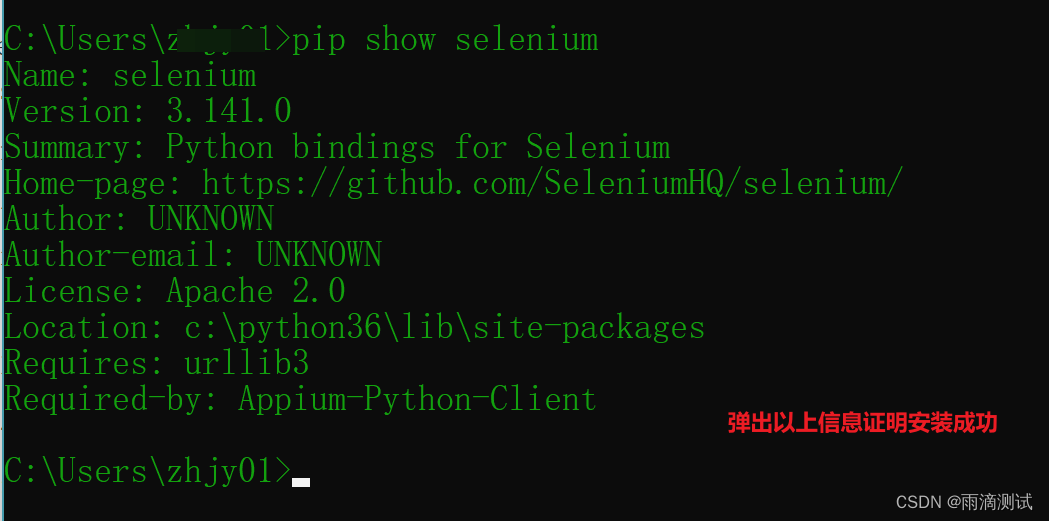
6.下载浏览器及驱动
selenium支持多种浏览器 ,我比较喜欢用chrome浏览器 。但是使用selenium需要下载对应的驱动版本 。
下载地址 :新建标签页 (googlechromelabs.github.io)

-
chrome : 做web自动化所运行的浏览器 ,一般下载window 64位即可
-
chromedriver : 若要在chrome浏览器上运行,必须需要用到这个驱动,下载chrome浏览器对应的驱动版本即可 。
注意 :需要将chromedriver下载后解压,将chromedriver.exe放在python的安装路径下即可 。如下图 。
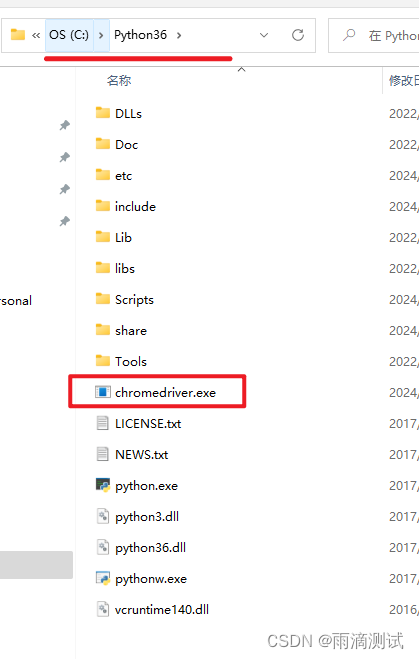
7.测试代码
目前能否在浏览器中运行 ,你需要编写一段代码进行验证 ,若下面的这段代码能正常运行不报错 ,则代表前面的配置没有问题 ,若报错 ,很可能是前面的配置不正确 ,请检查配置 。
# 1. 导包
from selenium import webdriver
import time
# 2. 创建浏览器驱动
driver = webdriver.Chrome()
driver.maximize_window()
# 3. 打开web页面,输入百度
driver.get("http://www.baidu.com")
time.sleep(3)
# 4. 在浏览器地址栏中输入关键字 :python
driver.find_element_by_id("kw").send_keys("python")
# 5. 点击按钮 :百度一下
driver.find_element_by_id("su").click()
# 6. 暂停
time.sleep(5)
# 7. 关闭浏览器
driver.quit()如果你是初次接触它 ,你可能会想 ,这段代码是怎么驱动浏览器运行的了 ?要知道这个问题的答案 ,就必须搞清楚以下3个问题 。
-
它(selenium)的运行原理 .
-
所调用方法的含义
-
它是如何准确的点击按钮和进行输入框输入的 ?
本篇幅只聊前两个问题 。
8.selenium的运行原理
下面这张图是selenium官网提供的一张运行原理图 ,比较清楚地说明了它的运行原理 。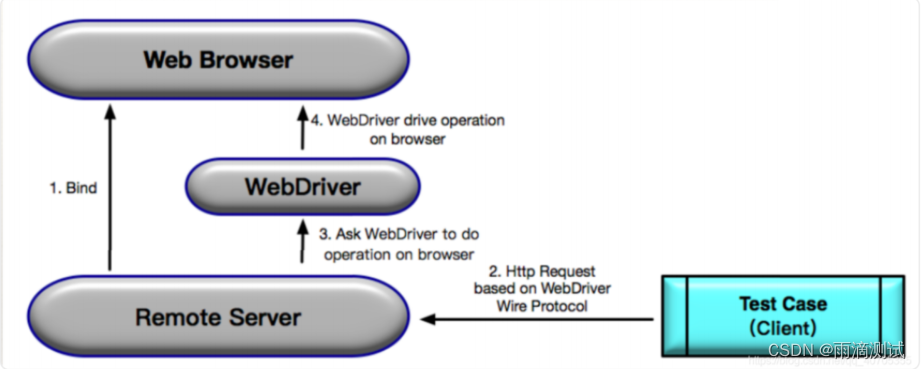
具体步骤是 :
-
当使用 Selenium启动浏览器器时,后台会同时启动基于 WebDriver Wire 协议的 Web Service 作为 Selenium 的 Remote Server,并与浏览器器绑定。之后,Remote Server 就开始监听 Client 端的操作请求;
-
执⾏行行测试时,测试⽤用例例会作为 Client 端,将需要执⾏行行的⻚页⾯面操作请求以 Http Request 的⽅方式发送给 Remote Server 。 该 Http Request 的 body,是以 WebDriver Wire 协议规定的 JSON 格式来描述需要浏览器器执⾏行行的具体操作;
-
Remote Server 接收到请求后,会对请求进⾏行行解析,并将解析结果发给WebDriver,由WebDriver 实际执⾏行行浏览器器的操作;
-
WebDriver 可以看做是直接操作浏览器器的原⽣生组件(Native Component),所以搭建测试环境时,通常都需要先下载浏 览器器对应的 WebDriver。
你可能不太理解Remote Server 是啥? WebDriver又是啥 ? 接下来我们把这几个关键术语进行解释。
| 关键字 | 说明 | 备注 |
|---|---|---|
| Test Case(Client) | 编写的python代码 | 当然它也支持其它语言,这里相当于客户端 |
| Remote Server | 就是selenium | selenium里有个类叫WebDriver ,负责接收client端的请求,解析后转发给浏览器驱动。 |
| WebDriver | 浏览器驱动文件,名称为:chromedriver.exe | 接受Remote Server请求,并请求操作浏览器 |
| Web Browser | 浏览器 |
所以 ,以上代码中的这句driver = webdriver.Chrome() ,就已经启动了Remote Server ,而后的代码都将通过Remote Server解析后发送给浏览器驱动 。
9.常用方法介绍
以上代码中通过driver调用的方法都属于selenium的方法 ,其中它就是如下这些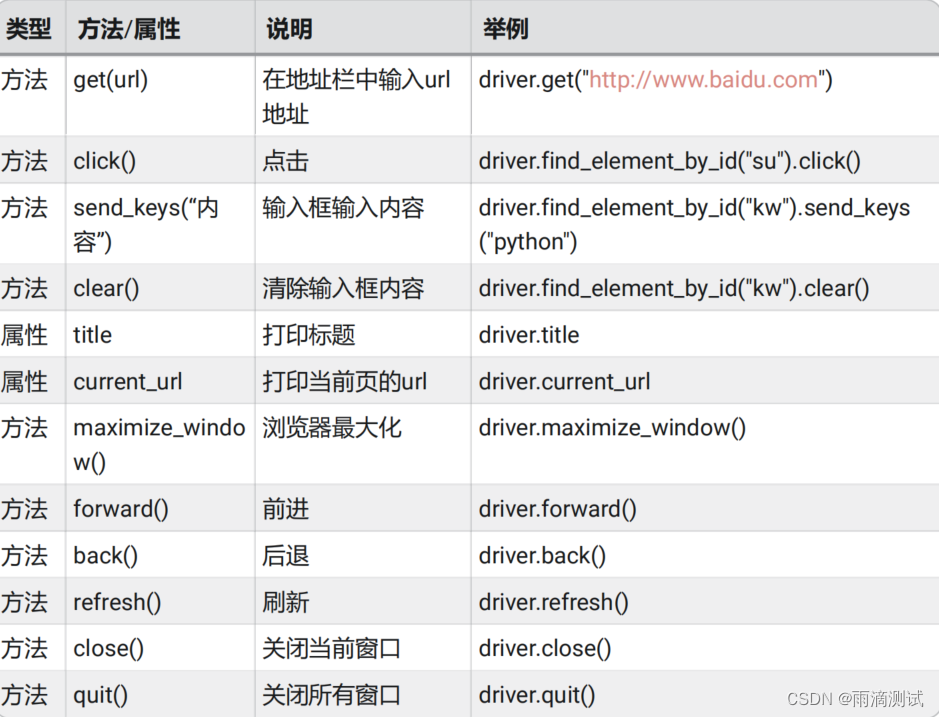
以上除了find_element_by_id() 这个方法没有介绍外(单独介绍),代码中的方法都已提到 。
最后通过一张图来总结它的属性和方法 。
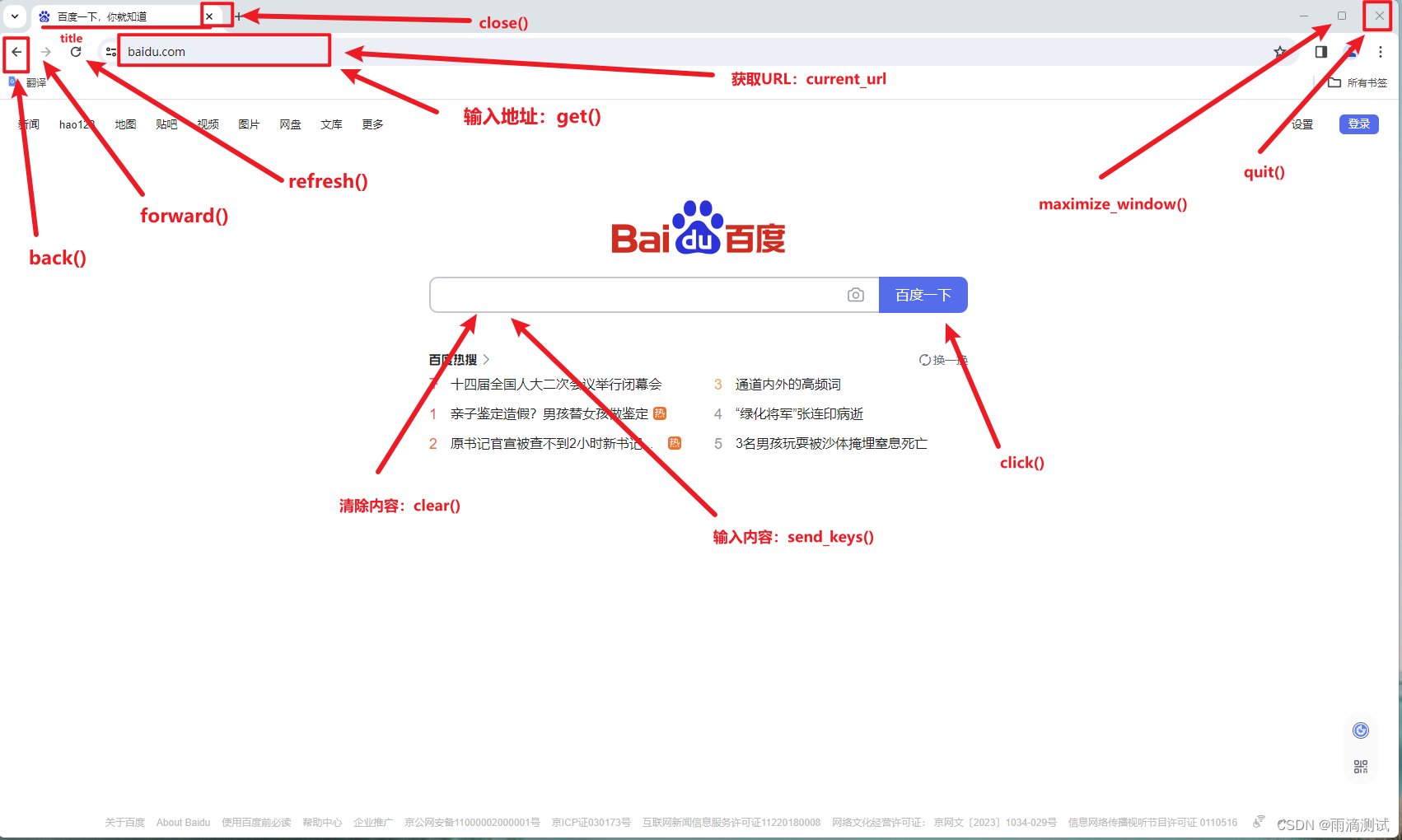
当selenium能准确的定位某个元素时 ,你可能会想 ,它是如何做到的呢 ?这里就不得不提到的元素定位技术 。
10.如何定位
当我们想定位某一个页面元素时 ,比如百度一下这个按钮 ,我们就必须使用浏览器F12键的这个功能 。你可以在火狐浏览器 、chrome浏览器 、或者edge浏览器使用它 。F12键都能适用 ,也就是说你只要按F12 ,它就会弹出一个开发调试工具 。
当然这个调试工具的还有另外一种打开形式,选中某个页面对象(比如百度一下) ,鼠标右击,点击检查,同样能打开相同的调试工具 。如下 :
其中下图就是我们看到的调试工具界面 ,选择默认的第一个就是Elements . 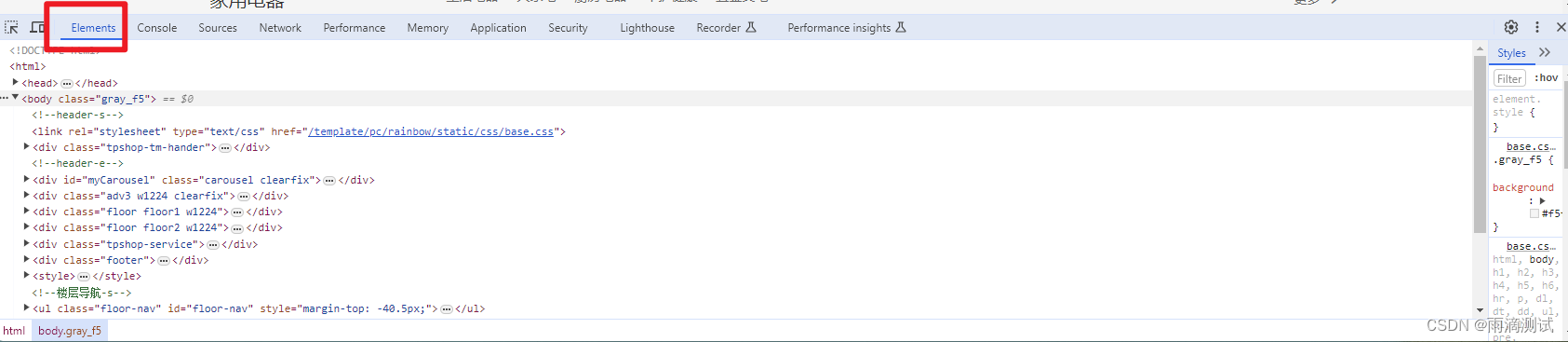
它里面显示的是前端人员开发的html代码,而这些代码正是构成页面展示的所有对象 ,比如按钮、输入框、链接、下来列表等。在HTML页面中,这些按钮、输入框、链接等对象都称之为元素 。你可以看到调试工具中的第一个单词显示的就是Elements ,翻译成中文就是元素的意思 。
这里面有一个很重要的隐藏前提 ,就是HTML代码中的某一行代码就可以代表一个元素 。比如百度一下这个按钮,就是某行代码构成的 。简单的说 ,某个代码片段 = 某个页面元素
举例 :
百度一下(按钮) 就等同于下面这段代码
<input type="submit" id="su" value="百度一下" class="bg s_btn">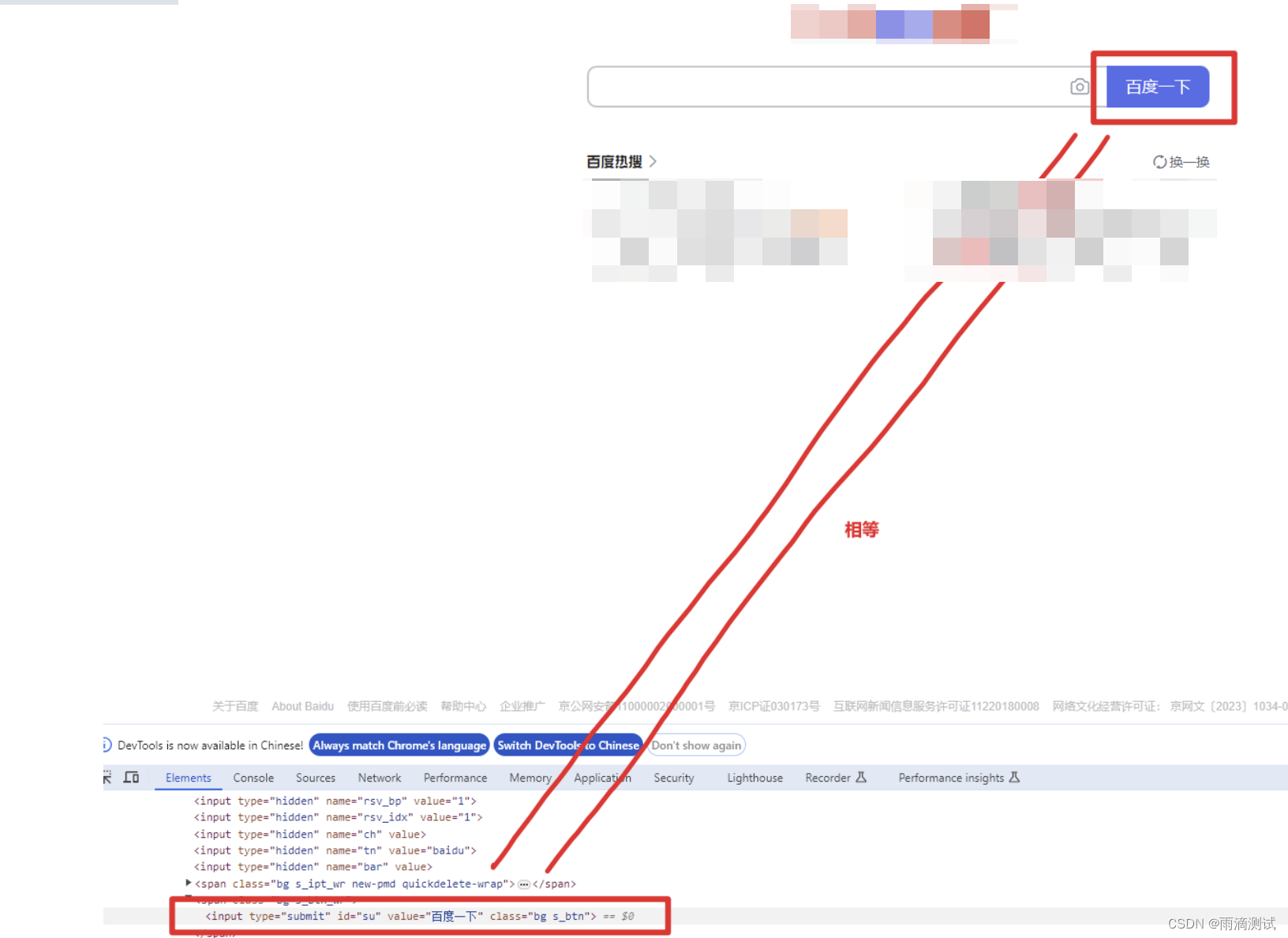
11.页面元素介绍
你可能会说 ,我没有学过前端知识 ,我也不知道什么叫html ,它里面的代码是什么意思我都看不懂 ,怎么办 ?
下面我们就简单介绍下html语言的一些简单知识 。
在这里 ,我首先要搞清楚三个概念 ,分别是层级 、标签 、属性
-
层级 :就是说html其实是有层级关系的,一个页面的元素 ,它是放在那个层级下 ,它的父级是什么 ?它的子级是什么 ?这些都能从Elements里看到 。层级在元素定位时也会使用到 。比如百度一下的层级是 :/html/body/div[2]/div[1]/div[5]/div/div/form/span[2]/input
-
标签 :是<后面显示的那个东西 ,每个标签都代表不同的含义,这里我们也需要了解它的含义,只需要知道什么是标签即可。
-
属性 :就是<>里由key=value组成的格式 ,其中key叫做属性名 ,value叫做属性值 。在Html中最常见的属性有 :id 、name、class
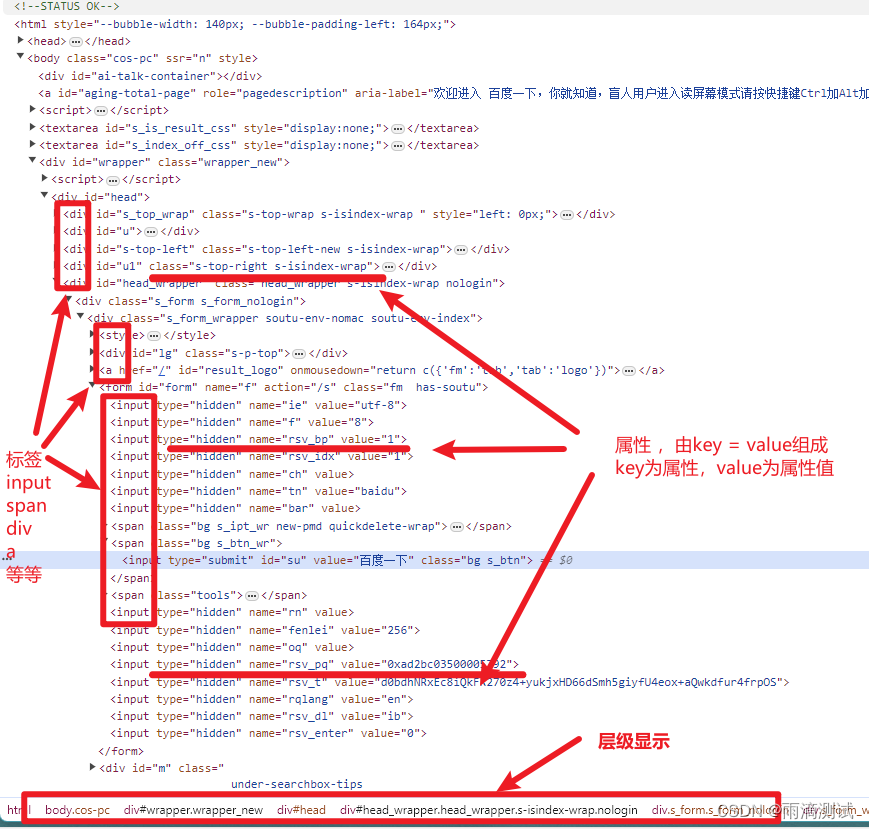
以上我们介绍过,一个页面元素(比如百度一下)其实就对应HTML中的一行代码 ,而这行代码 ,其实又是由标签和属性组成 ,我们马上要介绍的元素定位就是由这些标签和属性来进行元素定位的。
12.确定唯一性
既然我们已经知道页面中的每一个元素对应html中的某一行代码 ? 你是否知道页面中的某一个元素 ,它对应的是哪行代码 ? 比如我想知道"百度一下"这个按钮对应的代码 ,你怎么找 ?
具体操作是 :
-
鼠标右击这个元素(比如百度一下),点击检查 。
-
在下面弹出的HTML页面中有一行是被选中的 ,它的背景色是淡蓝色的 ,你只有是在按钮上操作 ,它就能选中这行代码 。
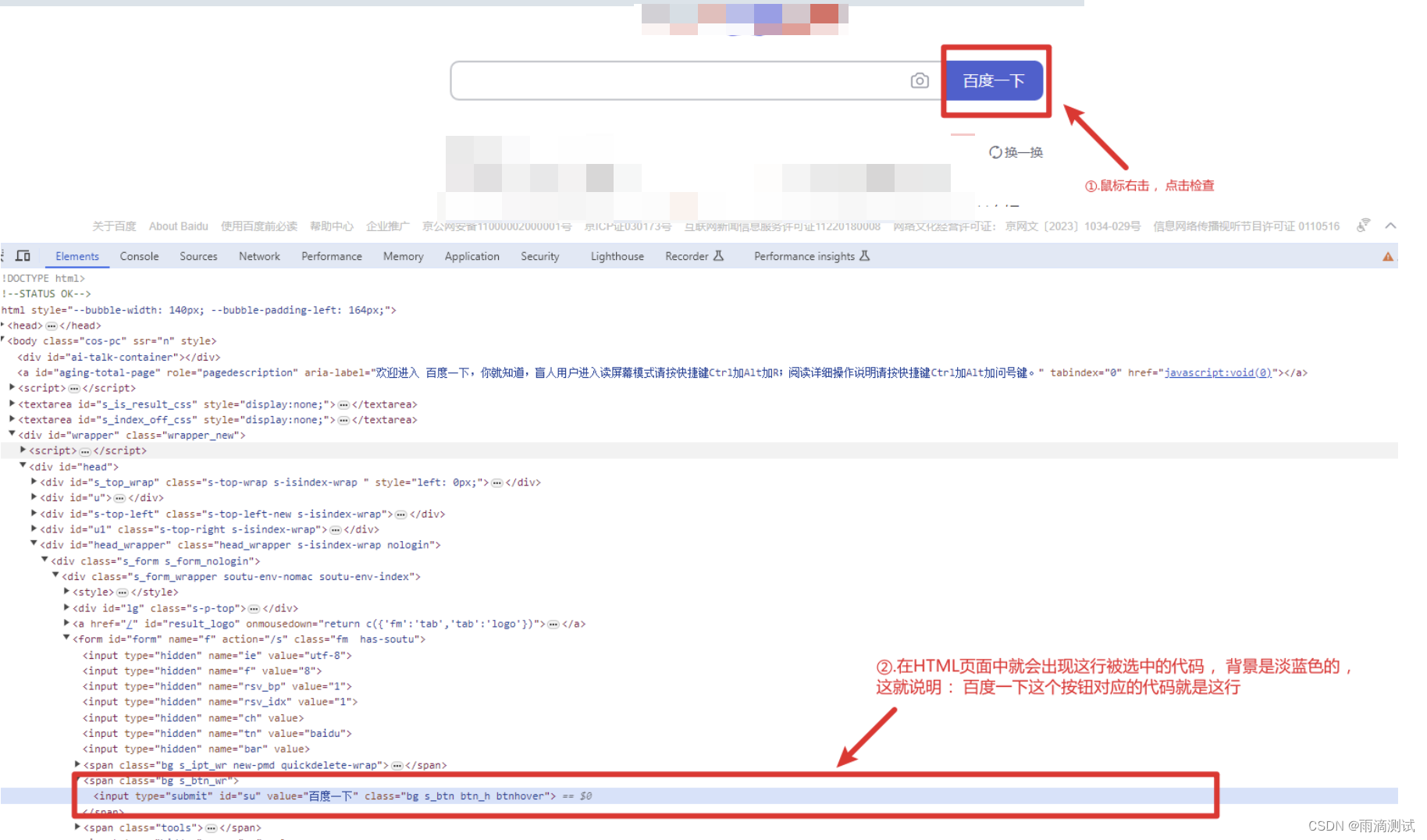
也就是说这一行代码就能代表“百度一下”这个按钮 ,我们也知道这行代码就是由标签和属性构成 ,难道说这些标签和属性就能代表页面中的一个元素吗 ?答案还就是这样的 。
这里的关键是无论你选择标签也好 、属性也好 ,只要选择的对象它是页面中唯一的,它就能代表这个元素 。大白话就是我要选择一个唯一的HTML对象来代表页面对象 。
比如我可以选择这一行中的input标签 、或者是选择type="submit" 、或者是选择id="su" 都行 ,但是要求就必须是唯一 。
你可以选择input标签作为定位元素 ,但是在HTML中 ,有很多的input标签 ,所以它不唯一 ,也不能定位到这个按钮 。所以,就的换定位方式 。
你也可以选择type='sumbit' 这个属性作为定位元素 ,你必须确保type='sumbit'是整个HTML页面是唯一的 。
当然,你也可以选择id='su'作为定位元素 ,但你也必须确保id='su'是整个HTML页面是唯一的 。
所以 ,结论就是无论选择那个元素作为定位符 ,必须确保唯一 。
事实上,我们前面写的那段代码 ,就是使用id=su作为定位符来进行定位百度一下这个按钮的 。
# 这里的su就是id的值 ,而id属性 ,selenium给提供了一个id的定位方法叫 :find_element_by_id("id的值")
driver.find_element_by_id("su").click()
# 所以,这行代码的意思就是通过id='su' 确定是百度一下这个按钮 ,然后再点击 。如何确定这个页面元素就是唯一的呢 ? 答案就是搜索 。
通过ctrl + f快捷键 ,输入你想要搜索的关键字进行搜索 ,若一般搜索的这个值是唯一的 ,你就可以使用它 ,若不唯一 ,你就看看是不是有重复的情况 。
比如 ,我要使用id='su'作为定位元素,但我不清楚su是否唯一 ,按ctrl+f进行搜索 ,输入su关键字 。你也许会搜索出很多带su的字符。但是id=su的只有这一个 ,你就可以拿它作为定位 。

你也可能搜索出id=su有多组值的情况 ,这很正常 ,不过这个我们就的使用selenium提供的一些方法帮我们定位了(后面介绍) 。但无论使用什么方法定位 ,最终要确定下来的还是唯一的 。这个是不变的 。
前面我们介绍了html页面元素主要是通过标签和属性来进行定位 ,只要满足唯一,无论是标签还是属性 ,都能进行定位 。当然 ,我们要通过selenium来进行定位 ,同样还是使用标签和属性 。
13.selenium的定位方法
下面我们就来看下selenium提供的16种定位方法 。本文主要介绍id、name、class_name、link_text等方法的使用 ,向xpath和css放在后面的系列中介绍
以上的方法的意思是,我要使用什么的元素定位 。 是使用标签定位呢 ?还是使用属性定位 。selenium都给你提供了对应的方法。
比如 :
使用input标签定位 ,就可以使用find_element_by_tag_name('input') ,其中方法中传入的值就必须是标签的名字 ;
若使用id属性定位,就可以使用使用find_element_by_id(属性值) ,其中方法中传入的值必须id的属性值 。
同理,其它方法也都是如此 ,而这两个方法系列都有不同的使用场景 。
-
find_element系列的方法,它定位后返回的是一个元素对象 ,即它能代表唯一性 ,所以大多数也会使用这里面的方法。
-
find_elements系列的方法,它定位后返回的是多个元素对象 ,这些对象放在一个列表 ,所以你的通过索引获取我们要用那个 ,一般只有在定位不到时才会使用这个系列的方法 。
14.操作案例
需求:通过selenium完成对tpshop的登录操作,具体如下 :
-
使用link_text定位首页登录按钮 ,
-
使用id定位用户名输入框,并输入账号,如13112345678
-
使用id定位确认密码输入框,并输入123456 。
-
使用name定位验证码输入框,并输入8888
-
使用class_name定位登录按钮,并点击确定 。
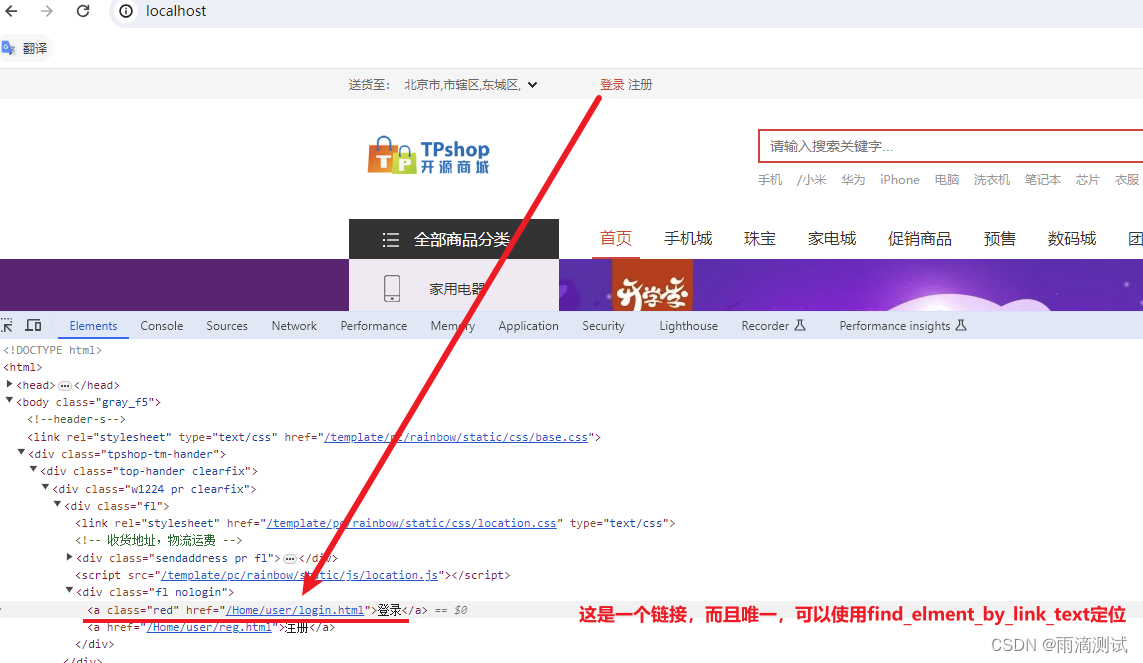
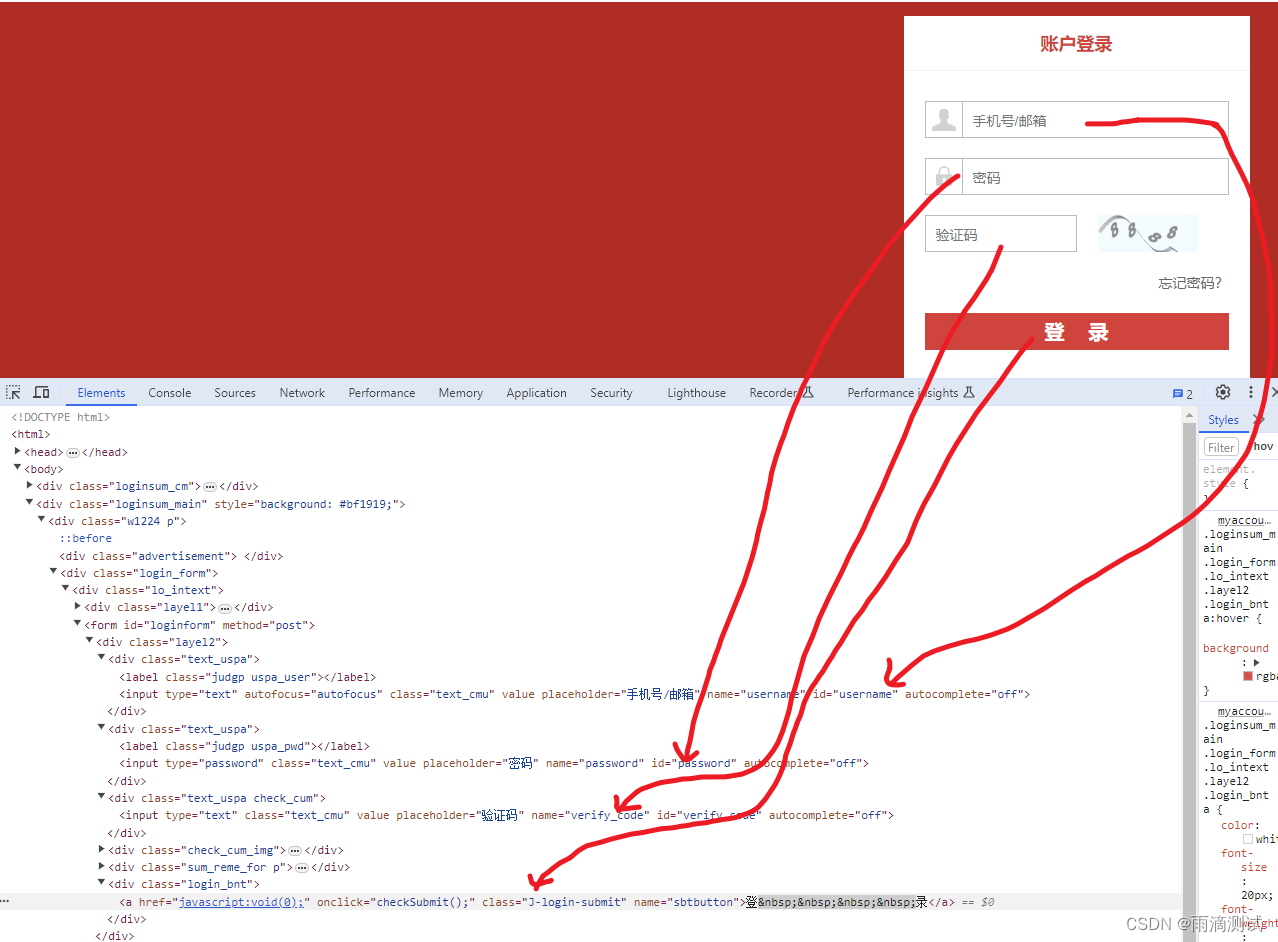
找到每个页面对象的定位元素后 ,我们就可以写代码了 。下面我们使用python编写一段代码 。
15.实现代码
# 定位登录
from selenium import webdriver # 导入webdriver
from time import sleep
# 1. 创建浏览器对象
driver = webdriver.Chrome()
driver.maximize_window() # 浏览器最大化
# 2. 输入地址
driver.get("http://localhost")
# 3. 元素定位
# 3.1 点击登录 : link_text定位
driver.find_element_by_link_text("登录").click()
sleep(3)
# 3.2 输入用户名 :id定位
driver.find_element_by_id("username").send_keys("13088888888")
# 3.3 输入密码 :id定位
driver.find_element_by_id("password").send_keys("123456")
# 3.4 输入验证码 :name定位
driver.find_element_by_name("verify_code").send_keys("8888")
# 4. 点击登录 :class定位
driver.find_element_by_class_name("J-login-submit").click()
sleep(6)
driver.quit() # 退出浏览器16.xpath介绍
XPath 是一门在 XML 文档中查找信息的语言。XPath 用于在 XML 文档中通过元素和属性进行导航。而html中也应用了这种语言 ,所以 ,我们定位html页面元素时也会用到xpath这种方法 。
17.xpath定位方式
xpath主要通过以下四种方法定位 :
-
路径定位
-
属性定位
-
多属性定位
-
路径与属性结合定位
以上的方法都是xpath本身具有的特性 ,它跟selenium现在还没有关系 。而selenium为了支持xpath这种定位方式 。故实现了一个方法,即 :
find_element_by_xpath(定位方法) .
而括号内的定位方法正是以上四种定位方式 ,所以 ,重点还是要理解如何使用以上的四种定位方式 。
18.路径定位
路径可以分为相对路径和绝对路径
-
绝对路径 : 是从根节点/html开始定位 ,使用/代表元素的层级,直到定位到想要的元素层级 。比如 :
/html/body/div/fieled[2]/input。但是这种定位只能定位到该层级的标签 ,而这样的标签在html会有很多 ,故它定位不了元素的唯一性 ,只能和其他方法结合使用 。 -
相当路径 :查找元素时不限制元素的位置 ,在定位元素时前面需要加两个斜杠(//) . 如定位input标签 ,编写格式为:
//input, 定位的就是html页面的所有Input标签 . 也可以使用//*代替 ,这样查找的就是所有的标签 。
无论使用相当路径还是绝对路径 ,需结合者属性一起使用 ,这样才能完成元素定位的唯一性 。还需要一点需要说明,就是在定位元素时一般不使用绝对路径 ,绝对路径写的比较死 ,不灵活 ,影响后期维护 。
19.属性定位
这应该是xpath定位的核心 ,多数xpath定位 ,都是选取的这种定位方式 。
所谓的属性定位 ,就是从html页面的节点中找到其中一个属性来完成定位,如果这个属性唯一 ,它就能代表页面的对象 。
它的编写格式为 ://标签[@属性名='属性值'] ,对这句代码的解释是 :
| 包含格式 | 说明 |
|---|---|
| //标签 | 这是相对路径,标明要查找节点的标签,加上标签,能起到缩小定位范围的作用,比如//input,就只查找input标签。 |
| [] | 查找某个特定节点或某个指定的值的节点 ,这是固定格式 。 |
| @ | 查找的属性 |
| text() | 定位值 |
举例 :
-
xpath属性编写格式:
//input[@name='username'],意思是定位input标签下属性名为name, 属性值为username的元素 。 -
selenium的xpath编写方法 :
find_element_by_xpath("//input[@name='username']") -
代码编写为 :
driver.find_element_by_xpath("//input[@name='username']").send_keys("13988888888")
xpath的这种方法能定位大多数元素 ,所以很多人都喜欢使用这种方式定位 。
总结如下 ,若使用xpath定位 ,具体步骤 :
-
通过浏览器找到要定位对象的属性 ,确定它就是唯一值 。
-
使用find_element_by_xpath() 方法 ,括号内编写xpath对应属性的格式 。
-
进行调试 ,若能定位到,说明你的方法没有问题 。
20.属性与逻辑定位
在前面我们介绍到使用属性定位 ,但是如若使用一个属性定位不到怎么办 ? 你就可以是用两个属性或者多个属性同时定位 。
这里就不得不说的一个逻辑运算符 ,and(逻辑与) . 它的意思是并且,大白话就是两者都要求满足 。比如 属性1 and 属性2 ,代表这两个属性都要同时都满足 。
所以 ,如果你一个属性定位不到的话 ,再加一个属性就可以进一步缩小范围,从而提高定位准确率 。
而这种写法也正好是xpath语言中所支持的,它的编写格式为 ://标签[@属性1='值1' and @属性2='值2'] 。
举例 :
-
xpath两个属性的编写格式 :
//input[@class='text_cmu' and @name='username'] -
selenium xpath方法编写格式 :
find_element_by_xpath("//input[@class='text_cmu' and @name='username']")
以上的定位虽然使用到了and逻辑运算符 ,但是xpath中,其实并不仅仅支持这一个逻辑运算符 。以下的都可以使用 :
-
算术运算符 : = ,!= , < , <= , >, >=
-
逻辑运算符 : or , and
只是以上运算符中,用在定位上的可能只有and比较有用 。
21.路径与属性结合定位
如果你使用了上面的各种方法 ,依然定位不到元素 ,那这个时候 ,你就可以考虑把路径加进来 。
一般原则是先加它的父路径 ,然后再加上当前路径 ,结合使用 。
具体格式为 :
-
//*[@id='um']/input: 父路径属性 + 子标签 -
//bookstore/[@price='30']: 父路径标签 + 子属性 -
//div[@class='login_bnt']/a[@class='J-login-submit': 父路径属性 + 子属性
不管咋写 ,只要能确定元素的唯一性 ,就都可以 ,不过这种写法很明显是逼不得已 ,因为你可能使用其它方法都无效的情况下 ,才会使用这种方法 。
22.定位总结
我们将以上所有方法总结为,可以使用以下的几种方法进行定位 。
| 定位方式 | xpath |
|---|---|
| id属性定位 | //*[@id='值'] |
| class属性定位 | //*[@class='值'] |
| 属性定位 | //*[@属性名='值'] |
| 标签+属性定位 | //标签[@属性名='值'] |
| 逻辑+属性定位 | //标签[@属性名='值' and @属性名1='值1'] |
| 路径定位 | //标签[@属性名='值']/标签[@属性名='值'] |
23.项目案例
需求:通过selenium完成对tpshop的登录操作,具体如下 :
-
使用xpath属性定位首页登录按钮 ,
-
使用逻辑与属性定位用户名输入框,并输入账号,如13988888888
-
使用属性定位确认密码输入框,并输入123456 。
-
使用属性定位验证码输入框,并输入8888
-
使用路径与属性结合定位登录按钮,并点击确定 。
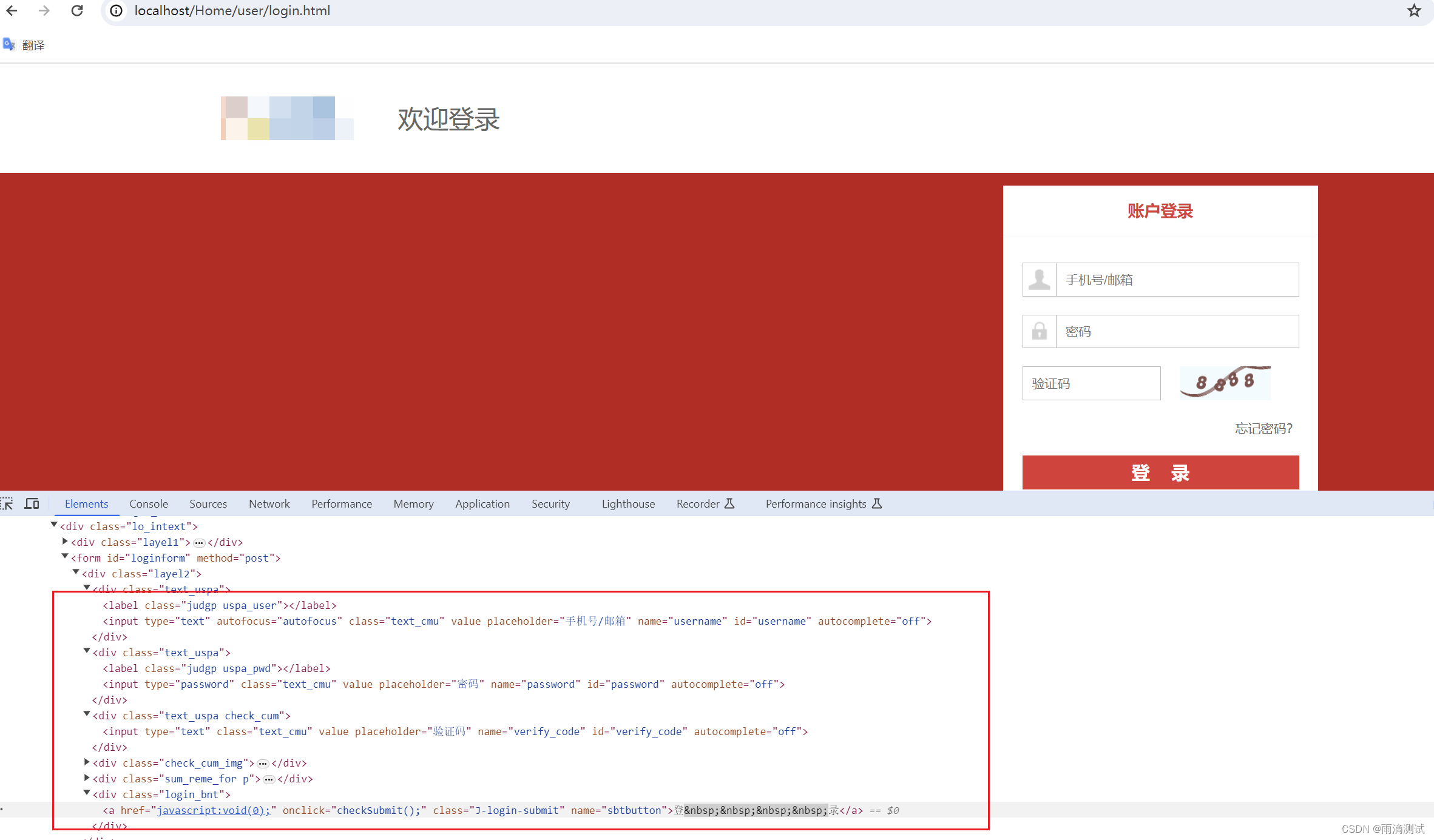
# 使用xpath属性进行定位 : //标签[@属性名='属性值']
from selenium import webdriver
import time
# 1. 创建浏览器对象
driver = webdriver.Chrome()
driver.maximize_window()
# 2. 输入地址 :http://localhost
driver.get("http://localhost")
# 3. 点击登录 : 使用xpath属性定位
driver.find_element_by_xpath("//a[@href='/Home/user/login.html']").click()
time.sleep(3)
# 输入用户名,密码,验证码 :使用逻辑与属性集合定位
driver.find_element_by_xpath("//input[@class='text_cmu' and @name='username']").send_keys("13988888888")
driver.find_element_by_xpath("//input[@id='password']").send_keys("123456")
driver.find_element_by_xpath("//input[@name='verify_code']").send_keys("8888")
# 使用层级与属性结合定位
driver.find_element_by_xpath("//div[@class='login_bnt']/a[@class='J-login-submit']").click()
time.sleep(5)
driver.quit()
24.什么是CSS定位
CSS(Cascading Style sheets)是一种语言 ,它主要用来描述HTML元素的样式显示 。
在CSS中,选择器是一种模式 ,用于选择需要添加样式的元素
25. CSS定位方式
css的定位和xpath定位基本相同 ,只不过css针对id和class有单独的写法 ,其它都一样 ,具体如下 :
-
id定位
-
class定位
-
属性定位
-
组合定位
selenium同样为css实现一个对应的方法 ,即 :
find_element_by_css_selector(css_selector)
其中css_selector编写的正式以上几种的定位方法 。
26.定位方法介绍
通过表格来列举下它们每种定位方式的不同 ,具体如下 :
| 定位方式 | css格式 | 示例 | 说明 |
|---|---|---|---|
| id属性定位 | #id属性值 | #username | #代表id属性,username代表id对应的值。 |
| class属性定位 | .class属性值 | .username | .代表class属性,username代表class对应的值 |
| 标签定位 | 标签 | input | 使用input标签定位,不过一般单独使用定位到元素,故不会单独使用 。它只能和其它方式结合使用 |
| 属性定位 | [属性名=值] | [type='password'] | []是固定格式,代表要使用属性定位,type是属性名,password是属性值 |
| 标签+id定位 | 标签#id属性值 | input#username | 标签为input ,id的属性值为username ,两者结合。 |
| 标签+class定位 | 标签.class属性值 | input.username | 标签为input ,class的属性值为username ,两者结合。 |
| 标签和属性集合定位 | 标签[属性名=值] | input[type='password'] | 标签为input , []括号内的为属性和值 。这种用法最多。 |
| 多属性定位 | [属性1=值1][属性2=值2] | [type='password'][id='password'] | 同时使用两个属性一起定位 ,这种情况用于一个属性定位不到,可以选择两个一起定位 。 |
27.项目案例
需求:通过selenium完成对tpshop的登录操作,具体如下 :
-
使用css属性定位首页登录按钮 ,
-
使用css id定位用户名输入框,并输入账号,如13988888888
-
使用css 标签+属性定位确认密码输入框,并输入123456 。
-
使用css多属性定位验证码输入框,并输入8888
-
使用css class定位登录按钮,并点击确定 。
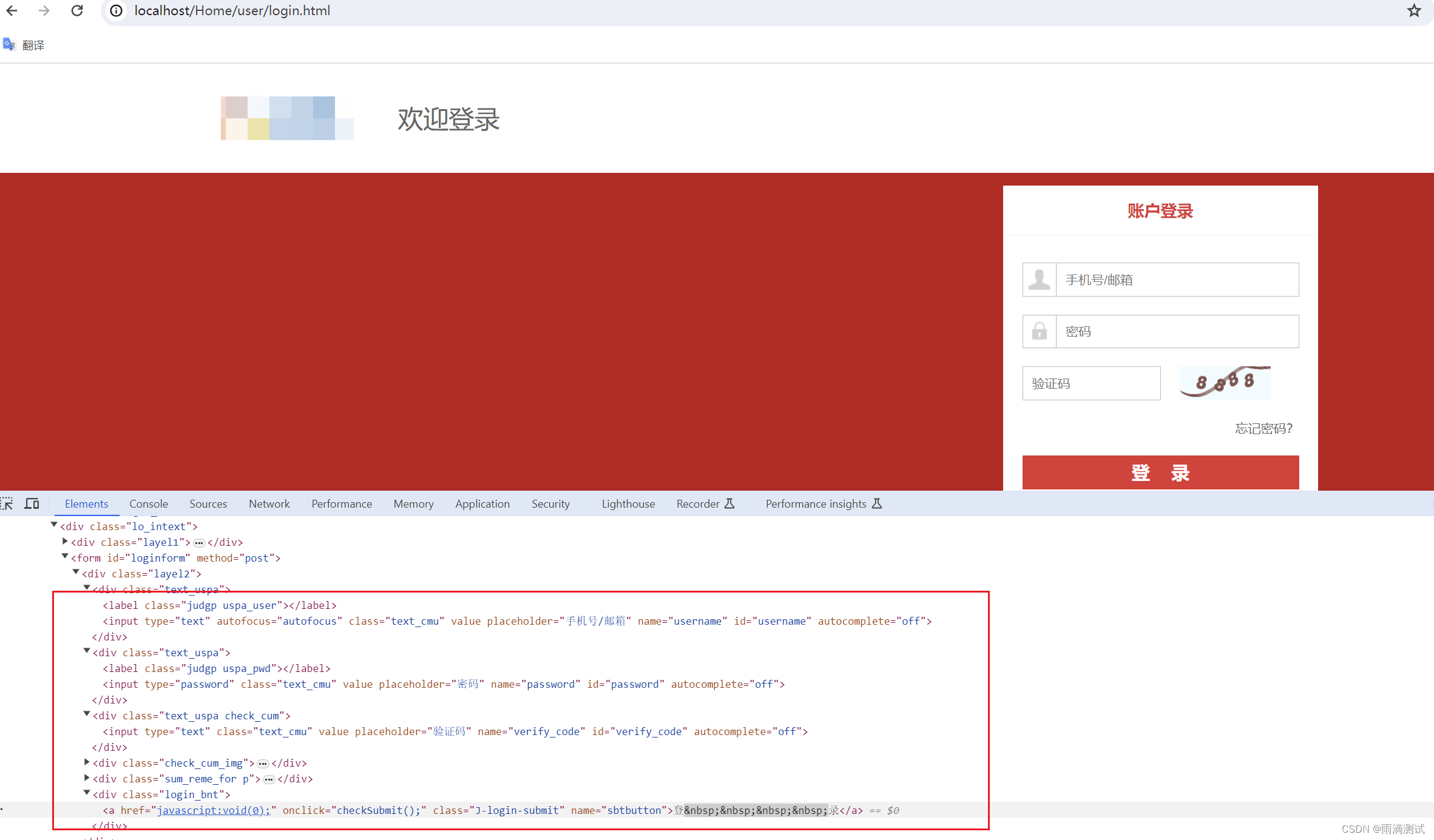
# 使用css定位
from selenium import webdriverimport time
# 1. 创建浏览器对象
driver = webdriver.Chrome()driver.maximize_window()
# 2. 输入地址 :http://localhost
driver.get("http://localhost")
# 3. 定位元素# 1) 定位登录 : css属性定位
driver.find_element_by_css_selector("[href='/Home/user/login.html']").click()
time.sleep(3)
# 2) 输入用户名 :css id定位driver.find_element_by_css_selector("#username").send_keys("13988888888")
# 3) 输入密码 :css 标签 + 属性定位driver.find_element_by_css_selector("input[type='password']").send_keys("123456")
# 4) 输入验证码 : css 多属性定位
driver.find_element_by_css_selector("[placeholder='验证码'][name='verify_code']").send_keys("8888")time.sleep(1)
# 5) 点击登录 : css class属性定位
driver.find_element_by_css_selector(".J-login-submit").click()
time.sleep(5)
driver.quit()28.定位方法总结
至此,我们将selenium中的前8种方法已经介绍完了 ,它们各有优缺点 ,也都有各自的使用场景 。现将这8种方法放在一起做个综合比较,具体如下 :
| 元素定位 | xpath | css | 其它方法 |
|---|---|---|---|
| id属性定位 | //*[@id='值'] | #id值 | id定位方法 |
| class属性定位 | //*[@class='值'] | .class | class定位方法 |
| 标签定位 | //标签 | 标签 | tag_name定位方法 |
| 属性定位 | //*[@属性名='值'] | [属性名=值] | 不支持 |
| 标签+属性定位 | //标签[@属性名='值'] | 标签[属性名=值] | 不支持 |
| 逻辑+属性定位 | //标签[@属性名='值' and @属性名1='值1'] | 标签[属性名=值][属性名=值] | 不支持 |
| 路径定位 | //标签[@属性名='值']/标签[@属性名='值'] | 标签[属性名=值]/[属性名1=值] | 不支持 |
你可以看到,通过xpath和css基本能实现所有的定位 ,而xpath 能实现的css也能实现 ,反过来也一样 ,所以 ,这两个其实熟悉一个就可以了 。
前面已经介绍了8种定位方法 ,大多数情况下我们都会优先使用这8种方法 。
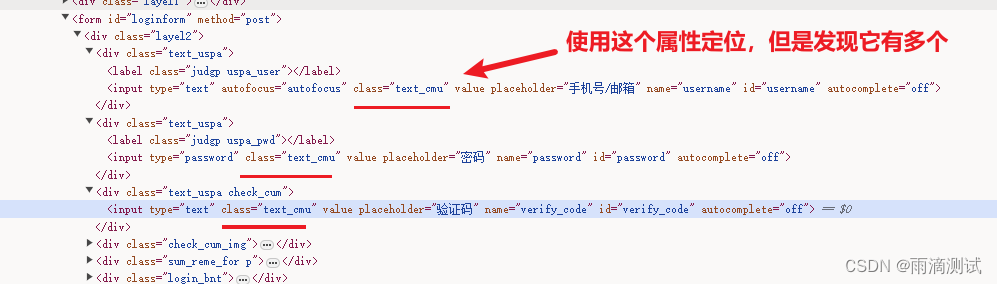
但有的时候在你选择定位元素时 ,会出现多个同样的定位属性和值 。而且你能选择定位也就这一种情况 。这种情况你只能使用它来进行定位 。
图中的这个元素只能使用class='sx2'定位 ,但是使用它来定位的话,就会出现定位到多个值的情况 。怎么办呢 ?
selenium提供了8种定位这种重复值的方法 。
29.find_elements的八种定位方法
谈到这8种方法 ,你就不得不了解前面的八种方法 ,通过对比我们可以看出它们的不同 。

总结以上方法,有以下3点需要注意 :
-
用法上和find_elment完全相同 ,虽然方法名有所不同 ,但用法上和find_element对应方法完全相同 ,可随意切换 。
-
定位后返回列表 :使用find_elements系列的方法定位 , 一般会返回多个元素 。而将这些元素都放在一个列表中 。所以 ,当获取其中的某一个元素时 ,就必须使用列表中的索引来获取 :list[index] .
-
它的使用场景:正常情况下 ,能使用find_element定位到的 ,就不会使用find_elements方法 ,它只是在find_element系列方法定位不到的情况下才会考虑使用 。
30.具体案例
需求:通过selenium完成对tpshop的登录操作,具体如下 :
-
进入首页,点击登录按钮 ,进入到登录页面
-
使用find_elements系方法定位用户名输入框,并输入账号,如13988888888
-
使用find_elements系方法定位确认密码输入框,并输入123456 。
-
使用find_elements系方法定位验证码输入框,并输入8888
-
点击登录按钮 ,进入我的账户页面 。
# 使用find_elements定位 ,返回的都是多个值,存放在列表汇中
from selenium import webdriver
import time
# 1. 创建浏览器对象
driver = webdriver.Chrome()
driver.maximize_window()
# 2. 输入地址 :http://localhost
driver.get("http://localhost")
driver.find_element_by_link_text("登录").click()
time.sleep(3)
# 通过class属性获取到多个元素,这里的elem_lst是一个列表 ,列表中放了三个元素,分别为用户名、密码、验证码
elem_lst = driver.find_elements_by_class_name("text_cmu")
print("元素集:{}".format(elem_lst))
# 输入用户名 :从列表中取第一个元素
elem_lst[0].send_keys("13988888888")
# 输入密码 :从列表中取第二个元素
elem_lst[1].send_keys("123456")
# 输入验证码 :从列表中取第三个元素
elem_lst[2].send_keys("8888")
driver.find_element_by_class_name("J-login-submit").click()继续介绍selenium中的一些方法和属性 ,下面的这些方法和前面已经介绍过的clear 、send_keys等都是在一个类中,即WebElement 。我们其实使用很多方法都是在这个类中 。
31.方法和属性
| 类型 | 方法/属性 | 说明 | 场景 |
|---|---|---|---|
| 属性 | size | 返回元素的大小 | / |
| 属性 | text | 返回元素的文本信息 | 用它获取实际值进行断言 |
| 方法 | get_attribute(‘x’) | 获取属性的值,传递的是属性 | 有时候想要获取其值可用它 |
| 方法 | is_displayed() | 判断元素是否可见 | 返回bool类型 ,封装类方法可用到 |
| 方法 | is_enabled() | 判断元素是否可用 | 返回bool类型 ,封装类方法可用到 |
| 方法 | is_selected() | 判断元素是否被选中,主要用来检查复选框和单选按钮是否被选中 | 返回Bool类型 ,只有有复选框或单选按钮的场景才可用到 |
以上的属性或方法中 ,使用最频繁的就是text ,我们用它来获取软件的返回值 ,从而进行断言操作 。
32.具体案例
需求:通过selenium完成对tpshop的注册操作,具体如下 :
-
进入首页,点击注册按钮 ,进入到注册页面
-
使用size获取欢迎注册图标的大小
-
使用text获取欢迎注册的文本信息
-
使用get_attribute()方法获取欢迎注册的属性值
-
使用is_displayed()方法判断欢迎注册元素是否可见
-
使用is_enabled()方法判断欢迎注册元素是否可用
-
使用is_selected()方法判断复选框是否被选择
-
点击复选框 ,将勾取消掉 。
-
再次使用is_selected()方法判断复选框是否被选择

# 属性和方法
from selenium import webdriver
import time
# 1. 创建浏览器对象
driver = webdriver.Chrome()
driver.maximize_window()
# 2. 输入地址 :http://localhost
driver.get("http://localhost")
# 3. 点击注册
driver.find_element_by_link_text("注册").click()
time.sleep(2)
# 获取欢迎注册的大小 :size
elem = driver.find_element_by_xpath("//span[@class='m-fntit']")
print("size:{}".format(elem.size))
# 获取欢迎注册的文本 :text
print("text:{}".format(elem.text))
# 获取属性值 :get_attribute()
print("属性值:{}".format(elem.get_attribute('class')))
# 判断元素是否可见 :is_displayed()
print("元素是否可见:{}".format(elem.is_displayed()))
# 判断元素是否可用 :is_enabled()
print("元素是否可用:{}".format(elem.is_enabled()))
# 元素是否被选中 :is_selected()
checkbox = driver.find_element_by_css_selector("input[type='checkbox']")
print("复选框是否被选中:{}".format(checkbox.is_selected()))
time.sleep(1)
checkbox.click()
print("取消后的复选框是否被选中:{}".format(checkbox.is_selected())) 














 3847
3847











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









