







写前面的话
最近在搞一个python3的项目,其中有个功能需要写文件,但是接口传给我的数据是str类型的。我用str写文件的话,由于对于str原始的编码不能确定,所以文件就会出现乱码,大致描述如下:
UnicodeEncodeError: ‘gbk’ codec can’t encode character u’\u200e’ in position 43: illegal multibyte sequence
Bytes与String
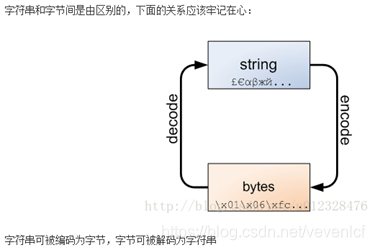
python3最重要的新特性大概要算对文本和二进制数据做了更为清晰的区分,文本总是unicode字符集,有str类型表示,二进制数据则有bytes类型表示。python3不会以任何隐式的方式混用str和bytes,正是这是的这两者的区别特别明显,你不能拼接字符串和字节包,也无法在字节包里搜索字符串(反之亦然),也不能将字符串传入参数为字节包的函数(反之亦然);
代码展示:
buf = "我爱祖国"
print (type(buf), buf)
buf2 = buf.encode(encoding='utf-8')
print (type(buf2), buf2)
<class 'str'> 我爱祖国
<class 'bytes'> b'\xe6\x88\x91\xe7\x88\xb1\xe7\xa5\x96\xe5\x9b\xbd'
decode函数与encode函数使用
1. decode()函数
描述:以 encoding 指定的编码格式解码Bytes类型数据,解码后的数据类型为:<class ‘str’>
2. encode()函数
描述:以 encoding 指定的编码格式对string类型数据转码,编码后的数据类型为:<class ‘bytes’>
-
encoding ——要使用的编码,如:utf-8,gb2312,cp936,gbk等。
-
errors ——设置不同解码错误的处理方案。默认为 ‘strict’,意为编码错误引起一个 UnicodeDecodeError。 其它可能得值有 ‘ignore’, 'replace’以及通过 codecs.register_error() 注册的1其它值。
程序示例:
s = "我爱祖国"
str1 = s.encode(encoding="utf-8",errors="strict")
str2 = s.encode("gb2312") #编码错误的处理方案默认为"strict"
str3 = s.encode("gbk")
print (type(str1), type(str2), type(str3))
print(str1.decode(encoding="utf-8",errors="strict"))#用utf-8的解码格式,解码str1.
print(str1.decode(encoding="gbk",errors="ignore")) ##如果以gbk的解码格式对str1进行解码得,将无法还原原来的字符串内容
print(str1.decode(encoding="gbk",errors="strict"))
print(str1.decode(encoding="gbk",errors="replace"))
print(str2.decode("gb2312"))
print(str3.decode("gbk"))
结果展示:
<class 'bytes'> <class 'bytes'> <class 'bytes'>
我爱祖国
鎴戠埍绁栧浗
鎴戠埍绁栧浗
鎴戠埍绁栧浗
我爱祖国
我爱祖国
文件操作问题
除了在数据的处理上有二进制bytes和字符串string区分,其实写文件的时候也有区分。同样写文件的时候也有编码的区分,尤其当输入文本类型为string类型的时候。
import requests
s = requests.get('http://www.12306.cn/mormhweb')
with open('12306.html','w', encoding='utf-8') as fd:
fd.write(s.content.decode('UTF-8',errors='replace'))
我们看到 encoding=‘utf-8’ 说明写入文件的编码方式为utf-8,与文本解码出来的格式是一样的。如果我们把 encoding='gbk’那么可想而知,得出的结果就不一定对了。
filerad = open(‘C:/Users/Administrator/Desktop/randomnum.txt’,‘wb’) # 以二进制方式进行写入
以下为open模式:
- r 打开只读文件,该文件必须存在。
- r+ 打开可读写的文件,该文件必须存在。
- w 打开只写文件,若文件存在则文件长度清为0,即该文件内容会消失。若文件不存在则建立该文件。
- w+ 打开可读写文件,若文件存在则文件长度清为零,即该文件内容会消失。若文件不存在则建立该文件。
- a 以附加的方式打开只写文件。若文件不存在,则会建立该文件,如果文件存在,写入的数据会被加到文件尾,即文件原先的内容会被保留。
- a+ 以附加方式打开可读写的文件。若文件不存在,则会建立该文件,如果文件存在,写入的数据会被加到文件尾后,即文件原先的内容会被保留。
上述的形态字符串都可以再加一个b字符,如rb、w+b或ab+等组合,加入b 字符用来告诉函数库打开的文件为二进制文件,而非纯文字文件。不过在POSIX系统,包含Linux都会忽略该字符。
结论
说了这么多,其实py3的 关于bytes与str的区分已经给了我们答案了!come on!
很多时候,如果不知道解决方法,是否可以回过头再梳理一下基础知识呢!!
备注:
在python3调用 vs dll时候,传参为bytes 格式!!!!否则传参就会错误!















 4198
4198











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











