







redis在windows下查看工具 Another Redis Desktop Manager
发布订阅有多种实现方式,常用pubsub和stream
1.基于频道(Channel)或模式(Pattern)的发布/订阅
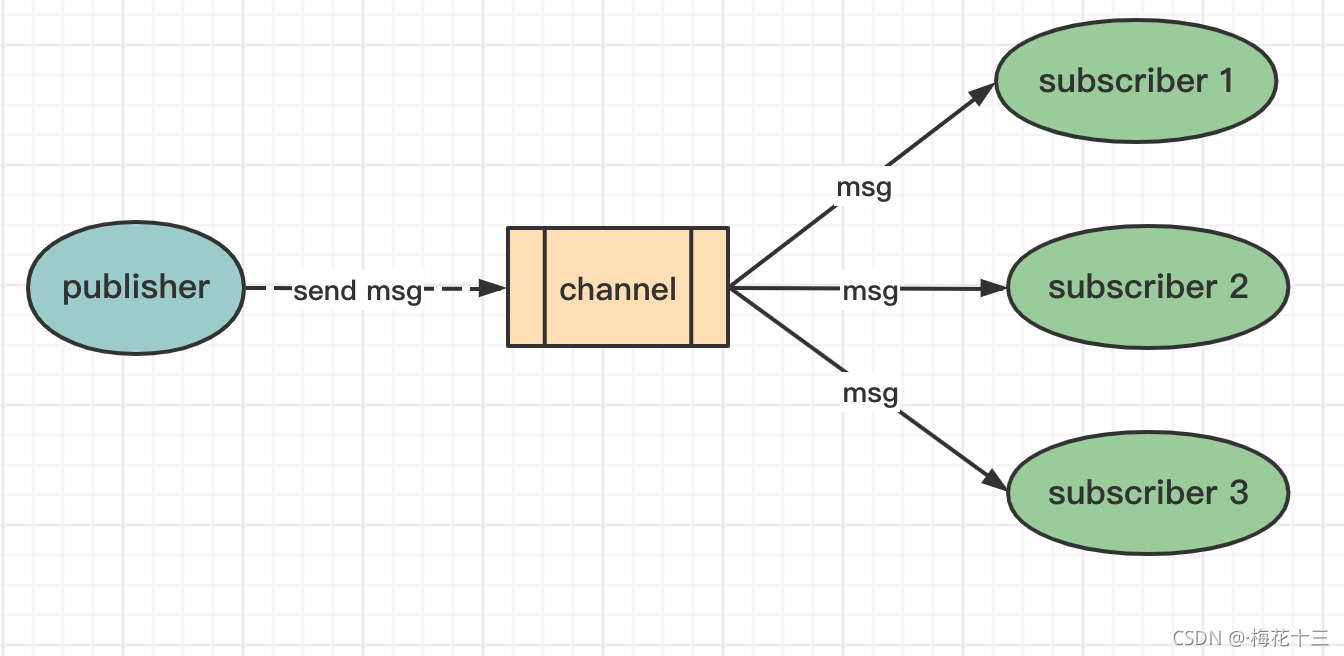
✦ 使用注意
客户端需要及时消费和处理消息。
客户端订阅了channel之后,如果接收消息不及时,可能导致DCS实例消息堆积,当达到消息堆积阈值(默认值为32MB),或者达到某种程度(默认8MB)一段时间(默认为1分钟)后,服务器端会自动断开该客户端连接,避免导致内部内存耗尽。
客户端需要支持重连。
当连接断开之后,客户端需要使用subscribe或者psubscribe重新进行订阅,否则无法继续接收消息。
不建议用于消息可靠性要求高的场景中。
Redis的pubsub不是一种可靠的消息系统。当出现客户端连接退出,或者极端情况下服务端发生主备切换时,未消费的消息会被丢弃。
缺点:
1.消息无法持久化,存在丢失风险
和常规的MQ不同,redis实现的发布/订阅模型消息无法持久化,一经发布,即使没有任何订阅方处理,该条消息就会丢失
2.没有类似ACK的机制
即发布方不会确保订阅方成功接收
3.广播机制,下游消费能力取决于消费方本身
广播机制无法通过添加多个消费方增强消费能力,因为这和发布/订阅模型本身的目的是不符的.广播机制的目的是一个一个发布者被多个订阅进行不同的处理
使用aioredis实现订阅
import asyncio
import aioredis
from pprint import pp
async def main():
redis = await aioredis.create_redis('redis://:foobared@localhost:6379/0', encoding='utf-8')
[channel] = await redis.psubscribe('bigfoot:broadcast:channel:*')
while True:
message = await channel.get()
pp(message)
asyncio.run(main())
————————————————
https://blog.csdn.net/m0_49079037/article/details/107289103使用aioredis实现发布
import asyncio
import aioredis
async def main():
redis = await aioredis.create_redis('redis://:foobared@localhost:6379/0', encoding='utf-8')
await asyncio.gather(
publish(redis, 1, 'Possible vocalizations east of Makanda'),
publish(redis, 2, 'Sighting near the Columbia River'),
publish(redis, 2, 'Chased by a tall hairy creature')
)
redis.close()
await redis.wait_closed()
def publish(redis, channel, message):
return redis.publish(f'bigfoot:broadcast:channel:{channel}', message)
asyncio.run(main())
————————————————
https://blog.csdn.net/m0_49079037/article/details/1072891032.基于stream的发布订阅
在 2018 年 6 月,Redis 5.0 新增了 Stream 数据结构,这个功能给 Redis 带来了 持久化消息队列
在 xadd 的指令提供一个定长长度 maxlen,就可以将老的消息干掉,确保最多不超过指定长度
在客户端消费者读取 Stream 消息时,Redis 服务器将消息回复给客户端的过程中,客户端突然断开了连接,消息就丢失了。但是 PEL 里已经保存了发出去的消息 ID,待客户端重新连上之后,可以再次收到 PEL 中的消息 ID 列表。不过此时 xreadgroup 的起始消息 ID 不能为参数 > ,而必须是任意有效的消息 ID,一般将参数设为 0-0,表示读取所有的 PEL 消息以及自 last_delivered_id 之后的新消息。
发布
import asyncio
import aioredis
async def main():
redis = await aioredis.create_redis('redis://:foobared@localhost:6379/0', encoding='utf-8')
await asyncio.gather(
add_to_stream(redis, 1, 'Possible vocalizations east of Makanda', 'Class B'),
add_to_stream(redis, 2, 'Sighting near the Columbia River', 'Class A'),
add_to_stream(redis, 3, 'Chased by a tall hairy creature', 'Class A'))
redis.close()
await redis.wait_closed()
def add_to_stream(redis, id, title, classification):
return redis.xadd('bigfoot:sightings:stream', {
'id': id, 'title': title, 'classification': classification })
asyncio.run(main())
————————————————
https://blog.csdn.net/m0_49079037/article/details/107289103消费
import asyncio
import aioredis
from pprint import pp
async def main():
redis = await aioredis.create_redis('redis://:foobared@localhost:6379/0', encoding='utf8')
last_id = '0-0'
while True:
events = await redis.xread(['bigfoot:sightings:stream'], timeout=0, count=5, latest_ids=[last_id])
for key, id, fields in events:
pp(fields)
last_id = id
asyncio.run(main())
————————————————
https://blog.csdn.net/m0_49079037/article/details/107289103
Redis 超越缓存 使用 Python 配合_编程歆妍的博客-CSDN博客 redis其他典型应用
Redis 中的发布/订阅功能_IT瘾君的博客-CSDN博客_redis订阅发布缺点
Redis 基于内存存储,这意味着它会比基于磁盘的 Kafka 快上一些,也意味着使用 Redis 我们 不能长时间存储大量数据。不过如果您想以 最小延迟 实时处理消息的话,您可以考虑 Redis,但是如果 消息很大并且应该重用数据 的话,则应该首先考虑使用 Kafka。















 1242
1242











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









