









Flink技术架构
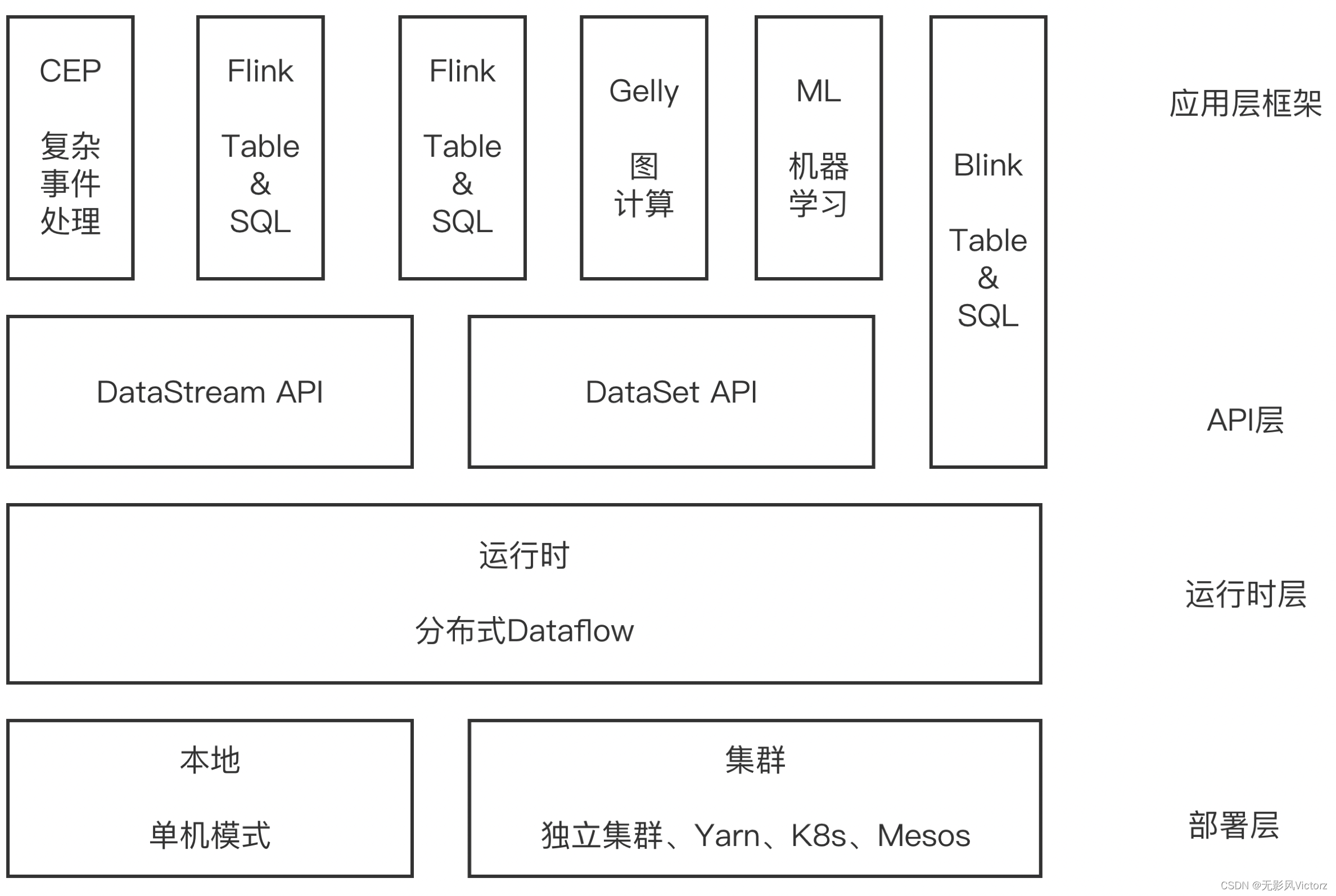
Flink运行架构
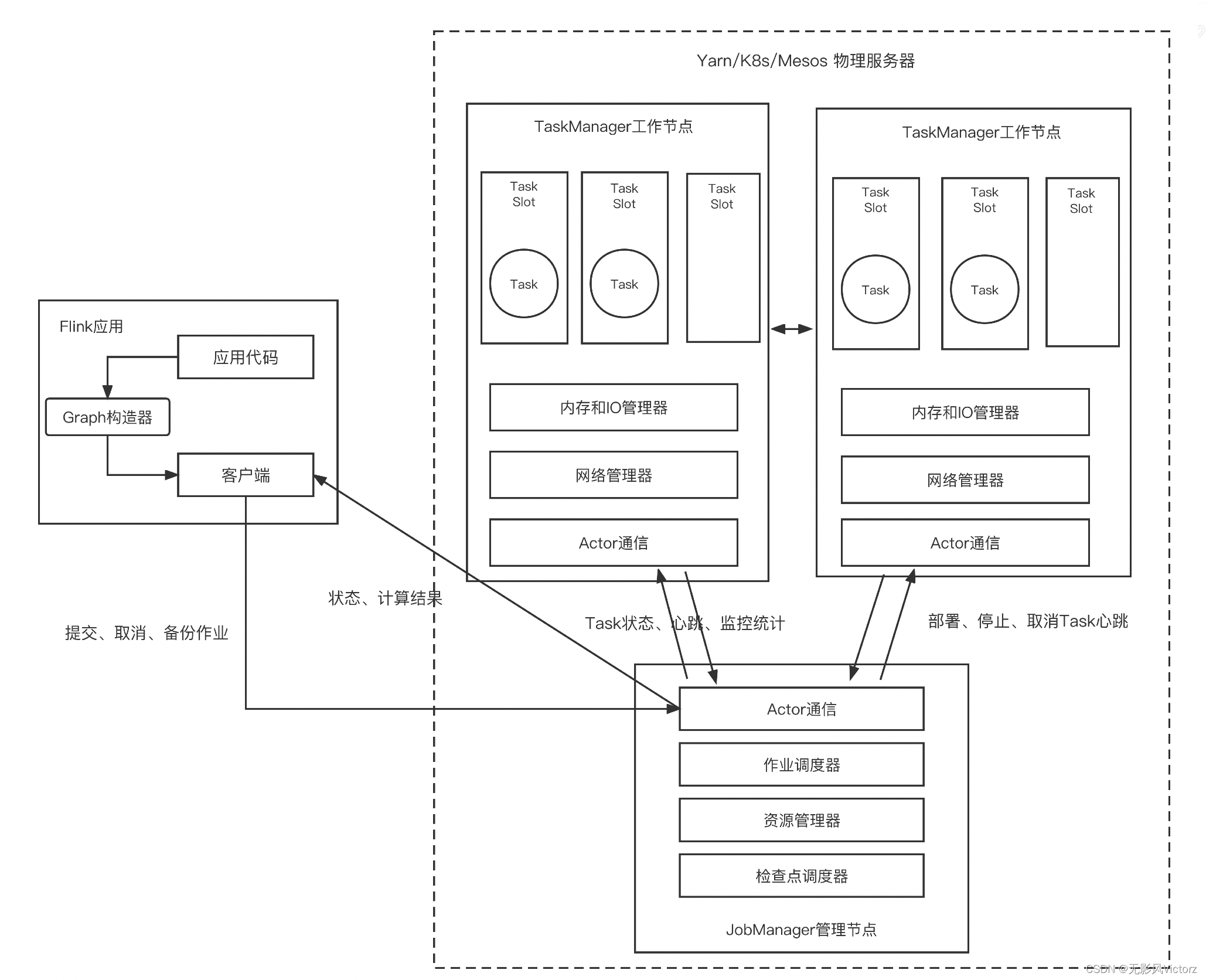
Flink流批一体的统一:
Flink-1.9之前,流批是两套体系,流-DataStream、批-DataSet Flink-1.9之后,在Table&SQL层面实现流批统一,DataSet将会被废弃
Flink应用的基本套路:
(1)获取参数(可选)
(2)初始化Stream执行环境
(3)配置参数
(4)读取外部数据
(5)数据处理流程
(6)将处理结果写入外部
(7)触发执行
DataStream体系:
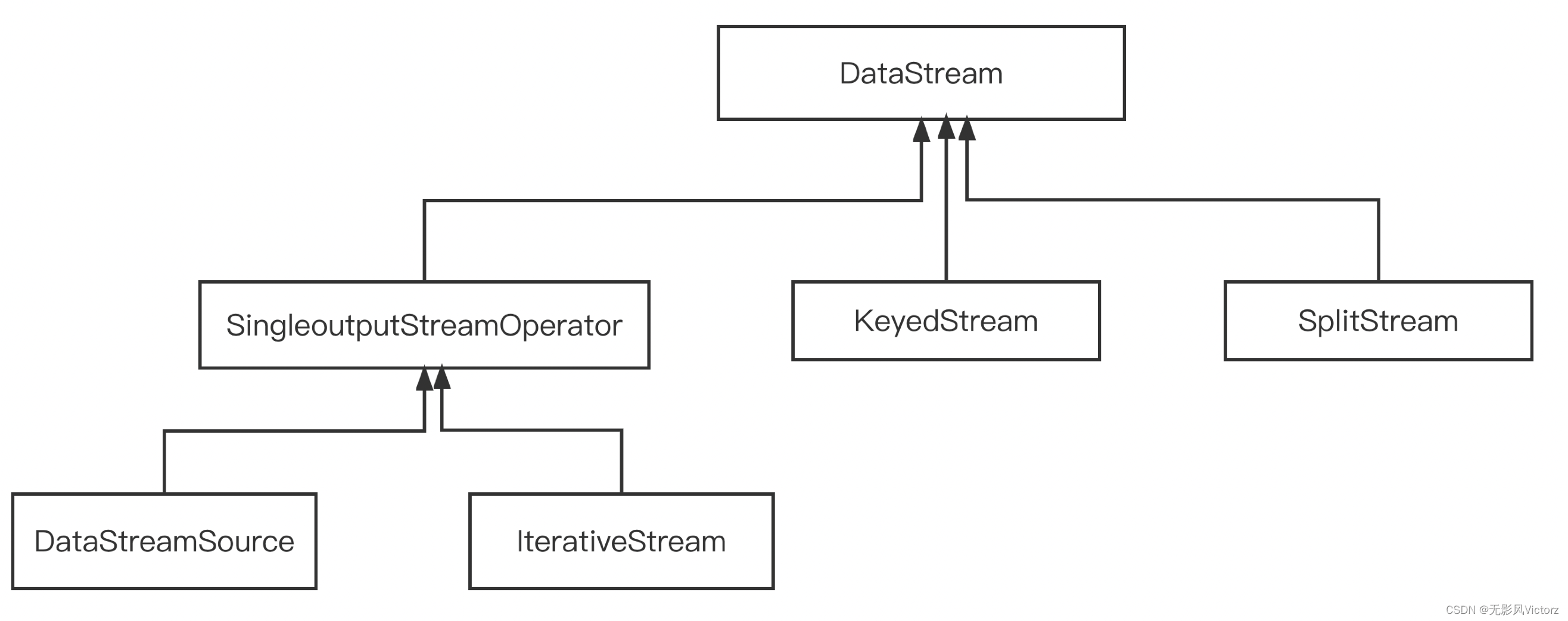
- DataStream:是Flink数据流核心抽象。其上定义了对数据流的一些列操作,同时也定义了其他类型DataStream相互转换关系。每个DataStream都有一个Transformation对象,表示该DataStream从上游DataStream使用该Transformation而来
- DataStreamSource:是DataStream的起点,在StreamExecutionEnvironment中创建
- DataStreamSink:通过DataStream.addSink 创建而来
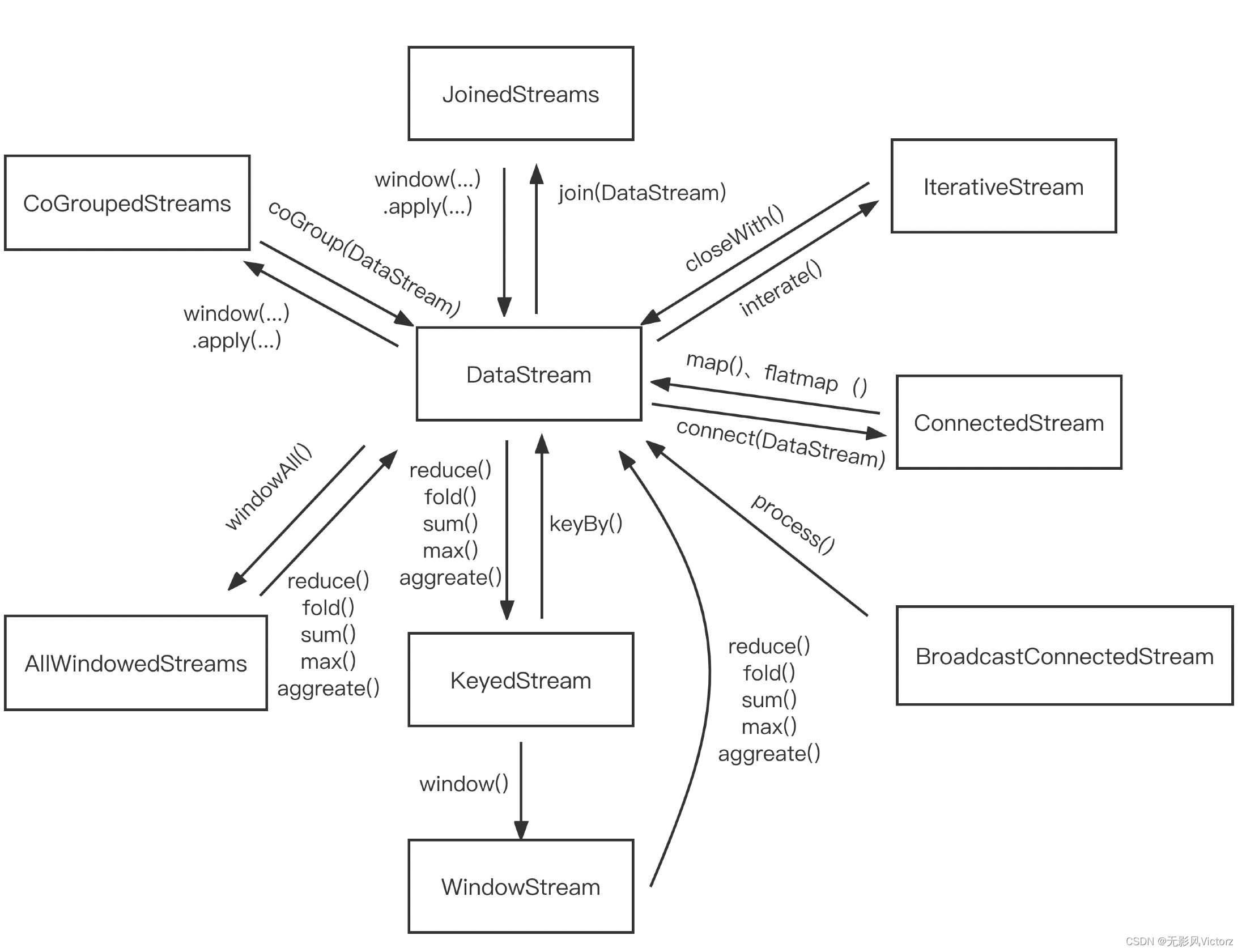
- KeyedStream:用来表示根据指定key进行分组的数据流。一个KeyedStream可以通过调用DataStream.keyBy()来获得
- WindowedStream & AllWindowedStream:WindowStream 代表了根据key分组且基于WindowAssigner切分窗口的数据流
- JoinedStreams & CoGroupedStreams:Join是CoGroup的一种特例,JoinedStreams底层使用CoGroupedStreams来实现,两者的区别是:
1)CoGrouped侧重Group,对数据进行分组,是对同一个key上的两组集合进行操作。
2)Join侧重的是数据对,对同一个key的每一对元素进行操作
- ConnectedStreams:表示两个数据流的组合,适用于两个有关系的数据流的操作,共享State
- BroadcastStream & BroadcastConnectedStream:实际对一个普通DataStream的封装,提供了DataStream的广播行为
BroadcastConnectedStreams 一般由 DataStream / KeyedDataStream 于 BroadcastStream连接而来,类似于ConnectedStream
- IterativeStream:对DataStream的得带操作,从逻辑上来说,包含IterativeStream的Dataflow是一个有向无环图,在底层执行层面上,Flink对其进行特殊处理
- AsyncDataStream:提供在DataStream上使用异步函数的能力
DataStream 转化关系:
环境对象:
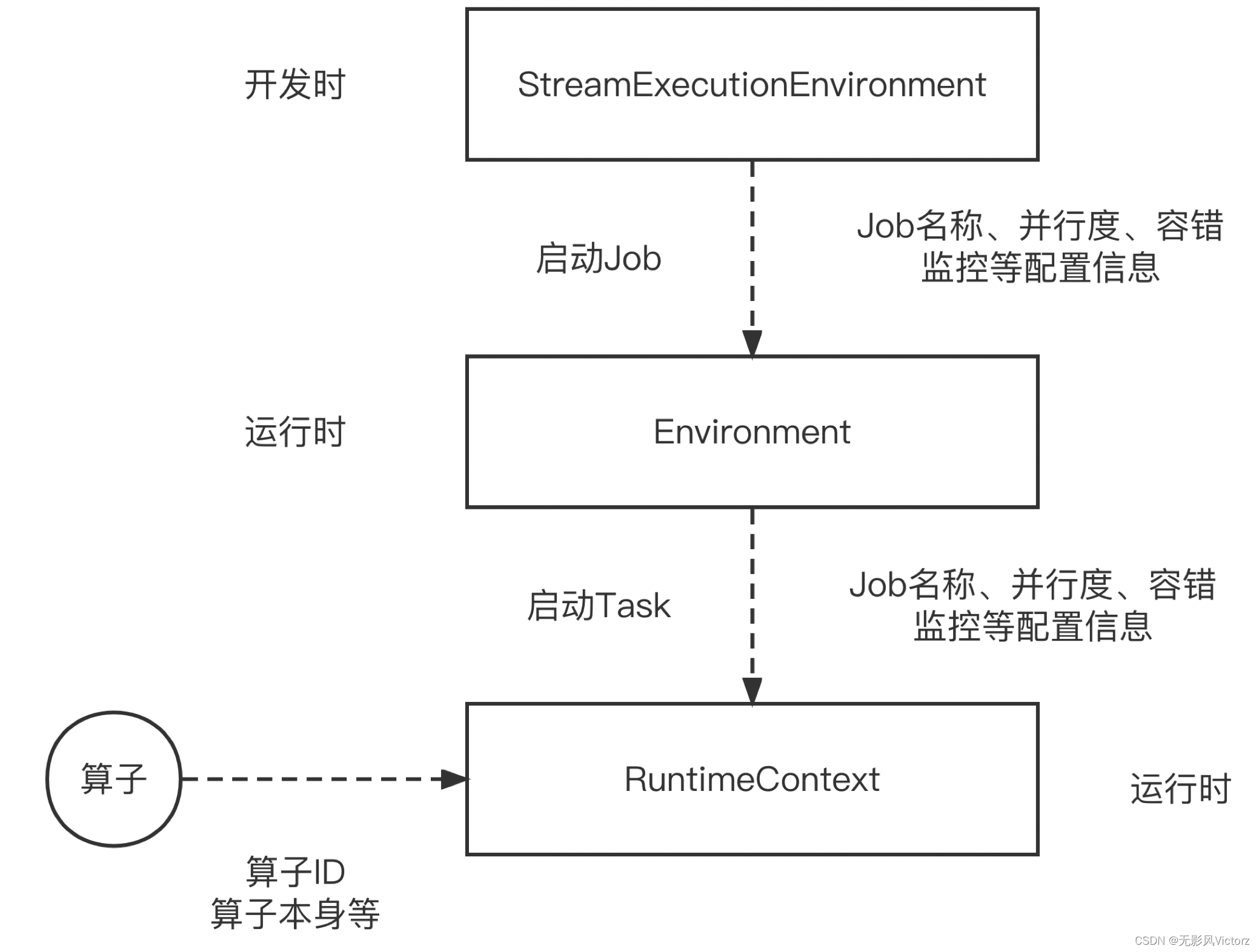
- StreamExecutionEnvironment:Flink应用开发时的概念,表示流计算作业的执行环境,是作业开发的入口,数据源接口,生成和转换DataStream的接口、数据Sink的接口、作业配置接口、作业启动执行的入口(StreamExecutionEnvironment在作业开发Main函数中使用 )
- Environment:是运行时作业级别的概念,从StreamExecutionEnvrionment衍生而来(Environment衔接StreamExecutionEnvironment和RuntimeContext的作用)
- RuntimeContext:是运行时Task实例级别的概念(RuntimeContext在UDF开发中使用)
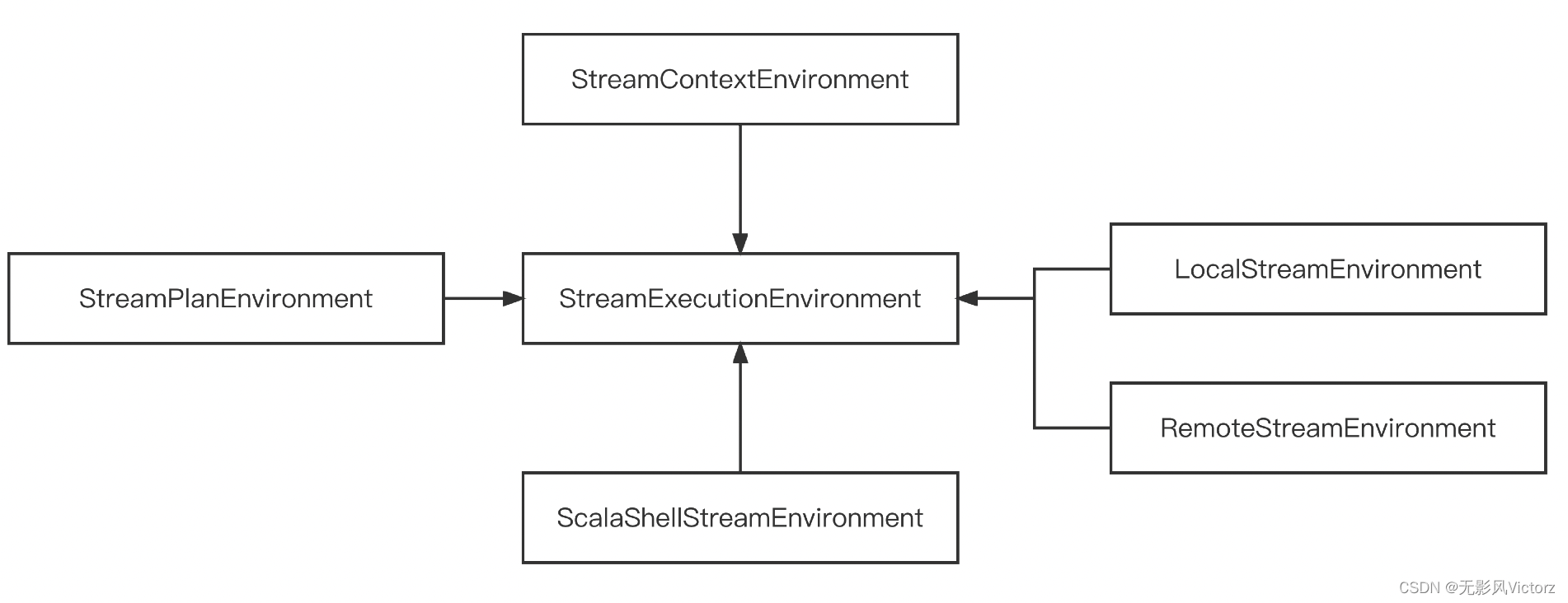
执行环境:
运行时环境:
RuntimeEnvironment:在Task开始执行时进行初始化,把Task运行相关的信息封装在该对象中
SavepointEnvrionment:是Environment 的最小化实例,在状态处理器的API中使用
运行时上下文:
RuntimeContext 是Function运行时的上下文,封装了Function运行时可能需要的所有信息
- StreamingRuntimeContext:在流计算UDF中使用的上下文,用来访问作业信息,状态等
- DistributedRuntimeUDFContext:由运行时UDF所在的批处理算子创建,在DataSet批处理中使用
- RuntimeUDFContext::在批处理应用的UDF中使用
- SavepointRuntimeContext:支持对检查点和保存点进行操作,包括读取、变更、写入等
- CepRuntimeContext:CEP复杂事件处理中使用的上下文
数据流元素:StreamElement

- StreamRecord:数据流中的一条记录(或者叫一个事件),也叫数据记录
- LatencyMarker:用来近似评估延迟
- Watermark:时间戳,告诉算子所有事件早于等于Watermark的事件记录已经到达
- StreamStatus:用来通知Task是否会继续接收到上游的记录或者Watermark
数据转换:Transformation
衔接DataStream API 和 Flink内核的逻辑结构,Transformation包含了一些关键参数:
(1)name:转换器的名称,用于可视化
(2)uid:在job重启时再次分配跟之前相同的uid,可以持久保存状态
(3)bufferTimeout:buffer超时事件
(4)parallelism:并行度
(5)id:跟属性uid无关,生成方式时基于一个静态累加器
(6)outputType:输出类型,用来进行序列话数据
(7)slotSharingGroup:给当前的Transformation设置Slot共享组
物理Transformation:在运行时刻会转化为实际算子
- SourceTransformation:Flink作业起点
- SinkTransformation:Flink作业终点
- OneInputTransformation:只接收一个输入流
- TwoInputTransformation:接收两种流作为输入
虚拟Transformation:不会转化为实际算子
- SideOutputTransformation:在旁路输出中转换而来
- SplitTransformation:按条件切分数据流
- SelectTransformation:和SplitTransformation配合使用,用来在下游选择SplitTransformation切分的数据流
- PartitionTransformation: 该转换器用于改变输入元素的分区
- UnionTransformation:合并转换器,将多个输入StreamTransformation进行合并
- FeedbackTransformation:反馈点就是把符合条件的数据重新发回上游Transformation处理,要求数据点为Transformation
- CoFeedbackTransformation:也是反馈上游Transformation处理,要求数据点为TwoInputTransformation
Flink算子:
Flink运行时会由Task组成DataFlow,每个Task中包含一个或多个算子,一个算子就是一个计算步骤,具体计算由算子中的Function执行
生命周期:
1)setup:初始化环境、时间服务、注册监控等
2)open: 该行为由各个具体的算子负责实现,包括算子的初始化逻辑
3)close: 所有的数据处理完毕后关闭算子,此时需要确保将所有的缓存数据向下发送
4)dispose:在算子生命周期最后阶段执行,此时算子已经关闭,停止处理数据,进行资源的释放
主要类型:
单流输入算子、双流输入算子、数据源算子StreamSource、异步算子AsyncWaitOperator
Blink算子:
主要类型:
Blink Runtime内置算子、其他模块内置算子(CEP算子、ProcessOperator算子)、通过动态代码生成的算子
内置算子:
(1)Join算子
InnerHashJoinOperator、BuildOuterHashJoinOperator、BuildLeftSemiOrAntiHashJoinOperator、ProbeOuterHashJoinOperator、FullOuterHashJoinOperator、AntiHashJoinOperator、SemiHashJoinOperator
(2)Temporal算子:记录了历史上任何时间点的所有数据改动
TemporalProcessTimeJoinOperator、TemporalRowTimeJoinOperator
(3)Sort算子
RowTimeSortOperator、ProcTimeSortOperator
(4)OverWindow算子(开窗运算经常需要当前数据跟之前N条数据一起计算)
BufferDataOverWindowOperator、NonBufferOverWindowOperator
(5)Window算子
AggregateWindowOperator、TableAggregateWindowOperator
(6)Watermark算子
WatermarkAssignerOperator、RowTimeMiniBatchAssignerOperator、ProcTimeMiniBatchAssignerOperator
(7)Mini-batch算子
MapBundleOperator、KeyedMapBundleOperator
批上算子:
(1)SortOperator:实现批上的全局数据排序
(2)SortLimitOperator:实现批上带有Limit的排序
(3)LimitOperator:实现批上的limit语义
(4)RankOperator:实现批上的Top N语义
通用算子
异步算子:
1- 顺序输出模式
2- 无序输出模式
函数:

【高阶】无状态Function (无需关心定时器之类的概念)
【中阶】RichFunction
- 增强了生命周期管理
- 增加了getRuntimeContext 和 setRuntimeContext
【低阶】ProcessFunction:可以访问流应用程序中所有基本块
- ProcessFunction:单流输入函数
- CoProcessFunction:双流输入函数
- KeyedProcessFunction:单流输入函数
- KeyedCoProcessFunction:双流输入函数
- 其他函数:
- 广播函数:BroadcastProcessFunction、KeyedBroadcastProcessFunction
- 异步函数:RichFunction、AsyncFunction
- 数据源函数:RichSourceFunction、RichParallelSourceFunction
SourceContext体系:
- NonTimestampContext:为所有的元素赋予-1作为时间戳,即永远不会向下游发送Watermark
- WatermarkContext:负责管理当前的StreamStatus,确保StreamStatus向下游传递;负责空闲检测逻辑,当超过设定时间间隔没有收到Watermark,则认为Task处于空闲状态
实现类:AutomaticWatermarkContext,manualWatermarkContext
- 输出函数:RichFunction、SinkFunction
- 检查点函数:CheckpointedFunction、ListCheckpointed接口
数据分区:数据集切分成块,每一个快数据存储在不同的机器上

ForwardPartitioner:应用在DataStream上,生成一个新的DataStream,用于在同一个OperatorChain中上下游算子之间的数据转发
ShufflePartitioner:随机将元素进行分区,可以确保下游的Task能够均匀获取数据(dataStream.shuffle())
RebalancePartitioner:以Round-robin的方式为每个元素分配分区,确保下游的Task可以均匀地获取数据,避免数据倾斜(dataSteam.rebalance())
RescalingPartitioner: 根据上下游Task的数量进行分区,使用Round-robin选择下游的一个Task进行数据分区
BroadcastPartitioner:将该记录广播给所有分区,即有N个分区,就是把数据复制N份,每个分区1份
KeyGroupStreamPartitioner:(不是给用户用的)KeyedStream在构造Transformation的时候默认使用keyedGroup分区形式
分布式Id:唯一标识,因为需要跨网络进行传输,所以该类实现了Serializable接口
时间与窗口:
窗口的类型:
Count Window
Tumble Count Window(滚动计数窗口):累积固定个数的元素视为一个窗口
Sliding Count Window(滑动计数窗口)
Time Window:
Tumble Time Window(滚动时间窗口):
在时间上按照事先约定的窗口大小切分窗口,窗口间不会有重叠
Sliding Time Window(滑动时间窗口):
在时间上按照事先约定的窗口大小、滑动步长滑动窗口,会有重叠
Session Window(会话窗口):
当超过一段时间,窗口没有收到新元素,则视为窗口结束
ProcessingTimeSessionWindows:处理事件会话窗口
DynamicProcessingTimeSessionWindows:
处理事件会话窗口,使用自定义会话间隔时长
EventTimeSessionWindows:事件时间会话窗口
DynamicEventTimeSessionWindows:事件时间会话窗口,使用自定义会话间隔时长
窗口原理机制:
每一个数据元素进入算子时,首先会被交给WindowAssigner。WindowAssigner决定元素放在哪个或哪些窗口。Window Operator中可能存在多个窗口,一个元素可以被放入多个窗口中
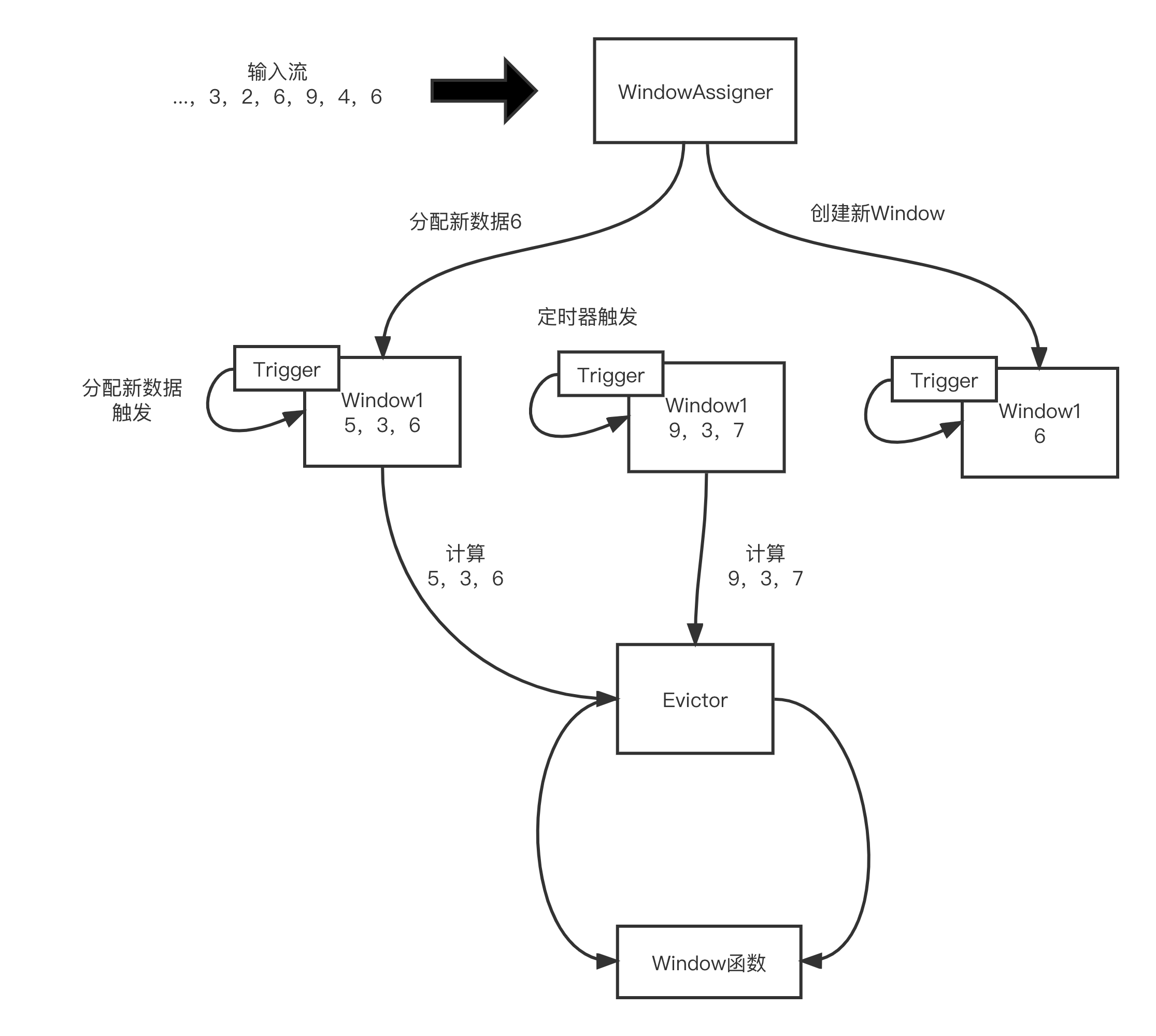
(1)每一个窗口都拥有属于自己的Trigger,Trigger上有定时器,用来决定一个窗口合适被计算或清除
(2)当有元素分配到该窗口,或者之前注册的定时器超时时,Trigger会被调用
(3)Trigger触发之后,窗口中的元素集合会交给Evictor。Evictor主要遍历窗口中的元素列表,过滤数据给窗口计算
(4)窗口收到元素后计算并发给下游
决定某个元素被分配到哪个/哪些窗口中去:WindowAssigner
决定了一个窗口何时被计算或清除:Trigger
三种典型延迟计算:
(1)基于数据记录同步个数的触发
(2)基于处理时间的触发
(3)基于事件时间的触发
窗口数据过滤器:Evictor
(1)CountEvictor:计数过滤器,在Window中保留指定数量的元素
(2)DeltaEvictor: 阈值过滤器,丢弃超过阈值的数据记录
(3)TimeEvictor: 保留Window中最近一段时间内的元素并丢弃
WaterMark:
生成方式:
(1)Source Function中生成Watermark
collectWithTimestamp // 生成时间戳
emitWatermark // 发送时间戳(2)DataStream API生成Watermark
AssignerWithPeriodicWatermarks 周期性生成Watermark策略的顶层抽象接口
递增Watermark:AscendingTimestamps
固定延迟Watermark:AssignerWithPunctuatedWatermarks
对每一个事件都会尝试进行Watermark生成
多流Watermark处理:
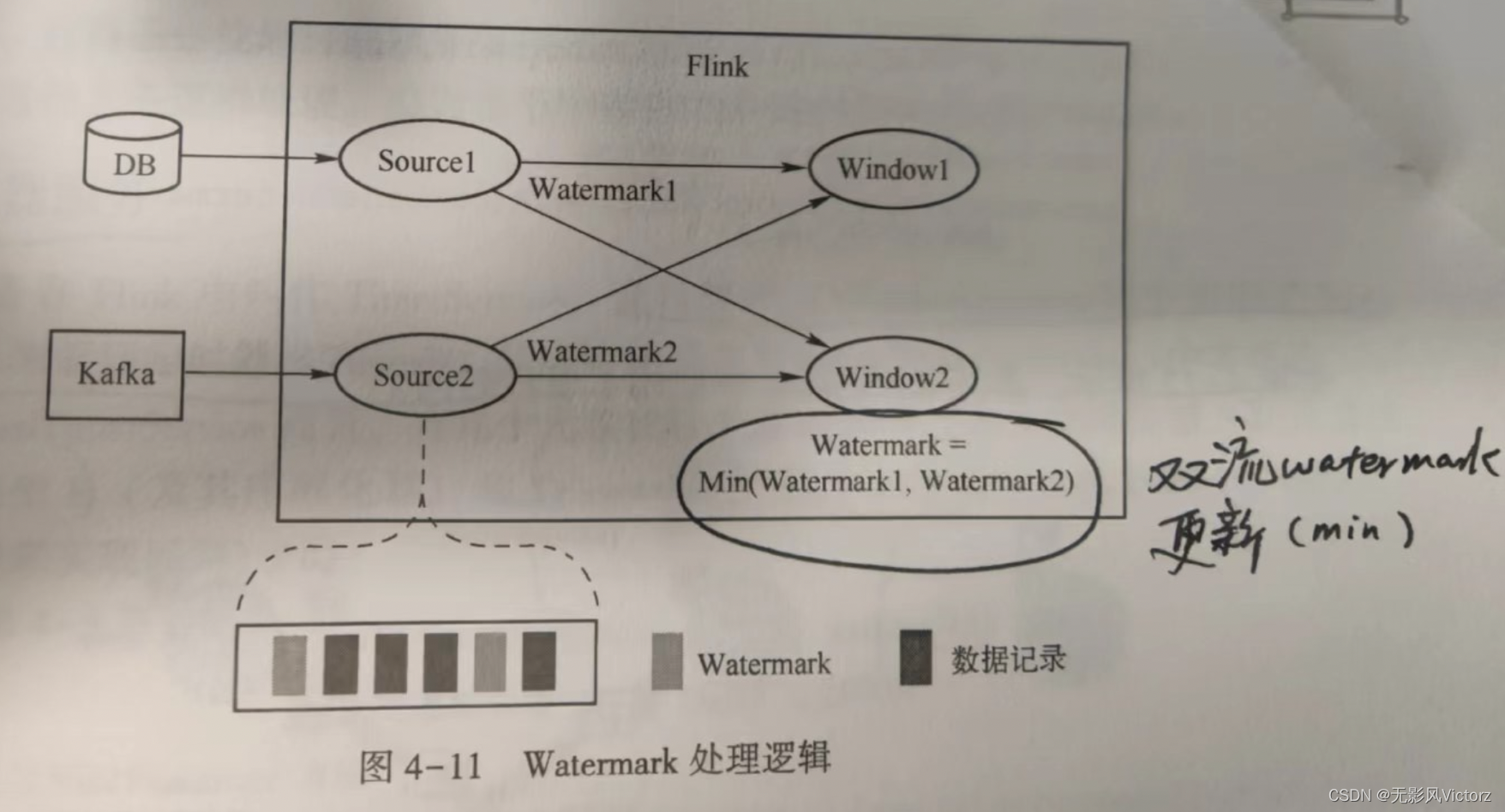
在多流场景下,每一个边上只能游一个递增的Watermark,当出现多流携带EventTime汇聚到一起时,会选择所有流入的EventTime中最小的向下游流出
即:Min(input1-Watermark,input2-Watermark)
WindowOperator中数据处理过程:

Flink物理类型系统:面向开发者
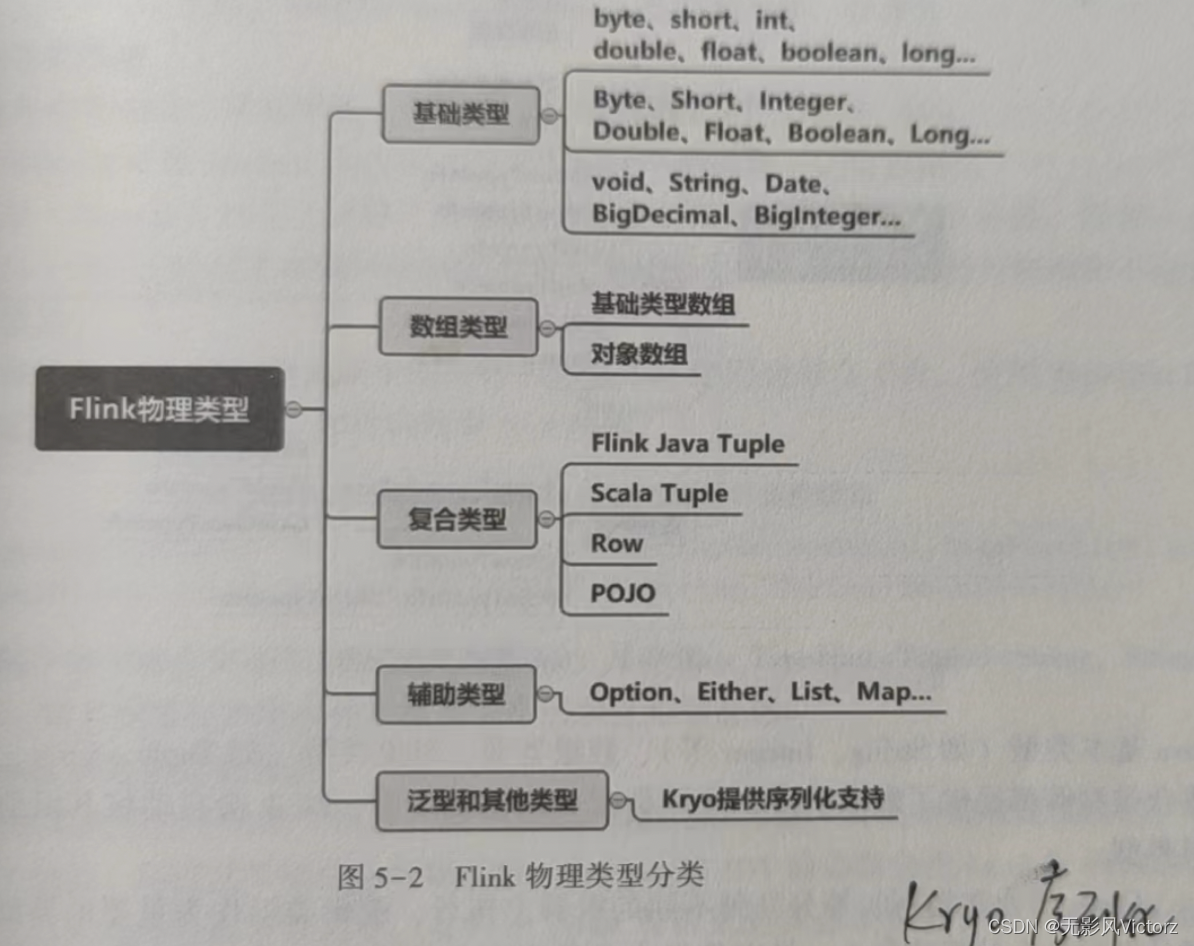
Flink逻辑类型系统:描述物理类型的类型系统,面向Flink
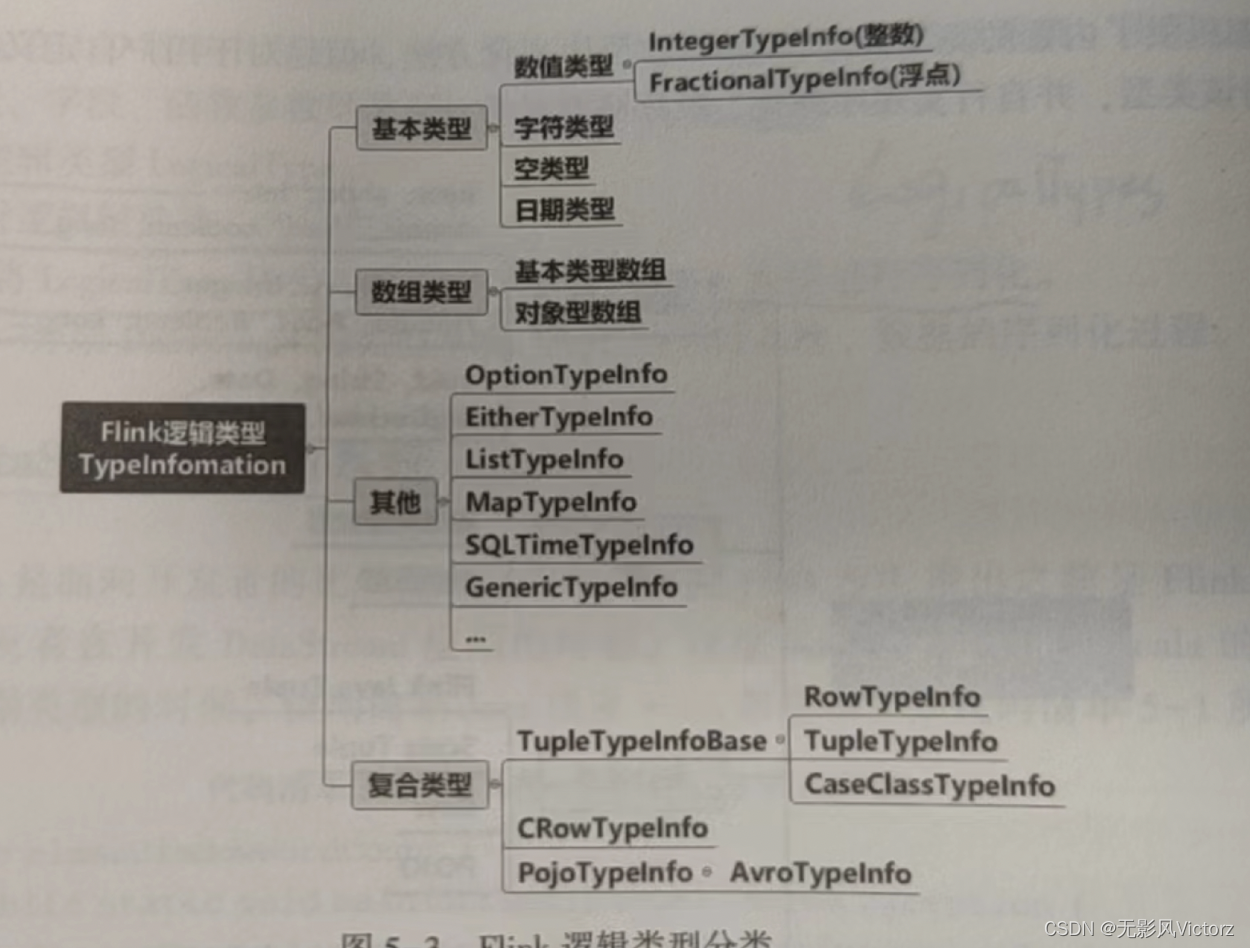
有两套逻辑类型系统:
1)TypeInformation类型系统:为DataStream/DataSet API设计的,用来描述对象的类型信息,是Java/Scala对象类型和Flink的二进制数据之间的桥梁
2)LogicalTypes类型系统
类型提取:
Java:反射机制获取Function的输入和输出类型
Scala:使用Scala Macro类型提取类型
Flink内存管理
JVM的管理不足:
1)内存中数据存储是不连续的,有效数据密度低
2)Full GC会带来心跳超时,导致节点被踢出集群,整个集群进入不稳定状态,通过调优手段不可避免
3)OutOfMemory会导致JVM崩溃,影响稳定性
4)存在缓冲未命中问题:读取的数据非连续,切进入缓存也需要一些时间开销
Flink状态管理:
Flink状态类型:
| 按是否有key划分 | 支持的State |
| keyedState (状态根据特定key绑定) | 1、ValueState 2、ListState 3、ReducingState 4、AggregatingState 5、MapState 6、FoldingState |
| OperatorState | ListState |
状态管理:
1)原始状态:即用户自定义State,Flink做快照时,把整个State当作一个整体,需要开发者自己管理,使用byte数组读写状态内容 (在自定义算子时居多)
2)托管状态:Flink框架管理的State,其序列化和反序列化由Flink框架支持,无须用户感知,干预
状态存储:
State存储在Flink中叫做StateBackend
1)内存型:MemoryStateBackend,State存储在JobManager内存中
2)文件型:FsStateBackend,运行时将需要的state保存在TaskManager中,执行检查点的时候,将state快照保存在文件系统中
State重分布:
在修改并行度时,可能涉及将state重新分配给算子
1)OperateState重分布
ListState将每个List取出,并把这些List合并到一个新的List,根据元素个数均匀分配给新的Task
2)UnionListState
将所有OperateState的数据合并,分配给新的算子
3)BroadcastState
操作BroadcastState的UDF需要保证不可变性,所以各个算子的同一个BroadcastState完全一样。变并发的时候,需要把这些数据发到新的Task
Flink作业提交:
作业提交的主要步骤:
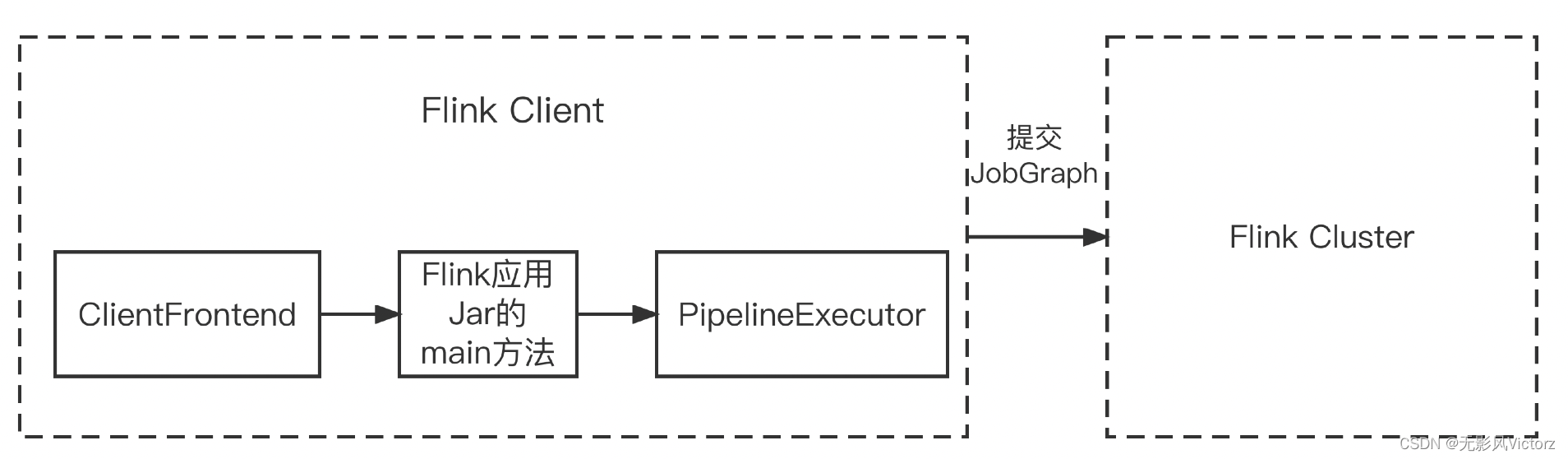
(1)在Flink Client中通过反射启动Jar的main函数,生成Flink StreamGraph、JobGraph,将JobGraph提交给Flink集群
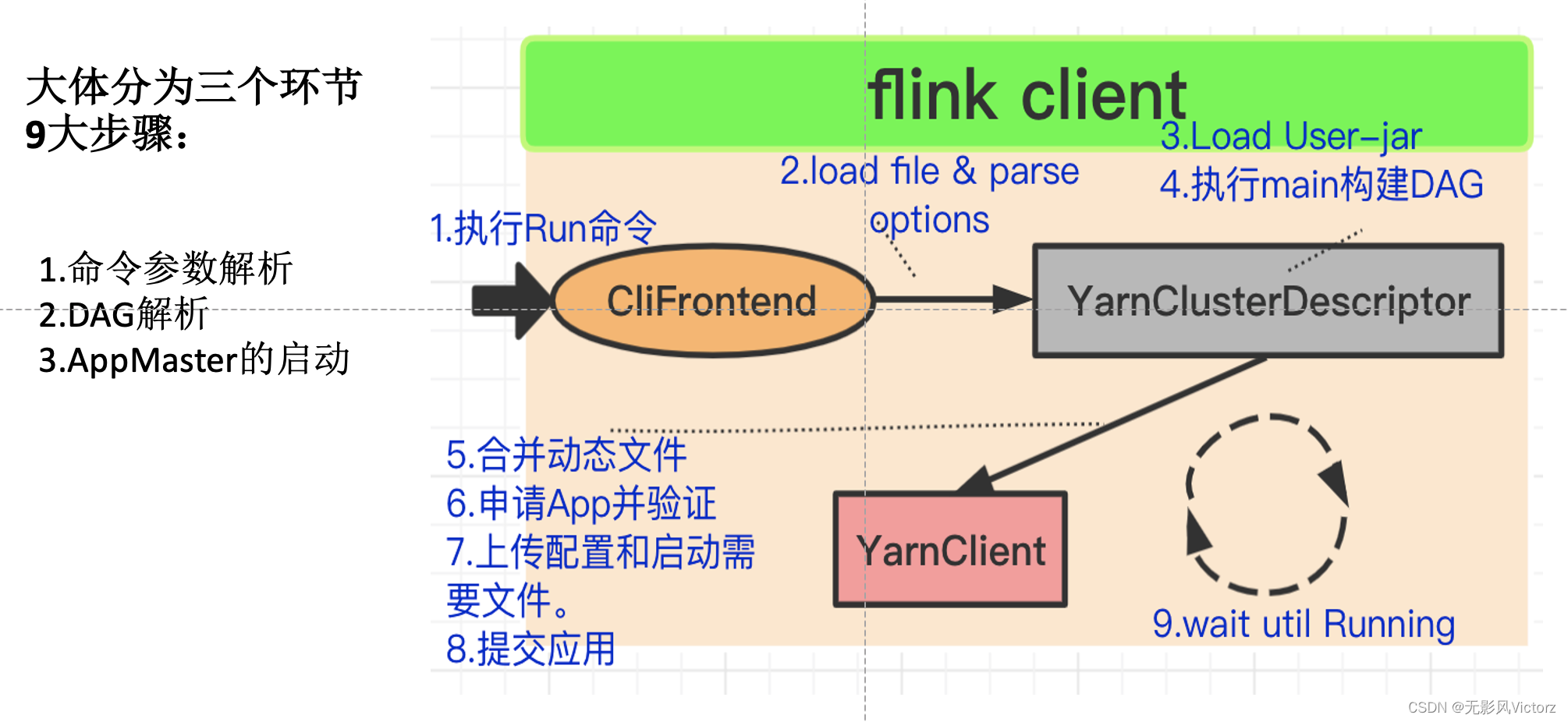
ClientFrontend是入口,触发用户开发的Flink应用Jar包中的main方法,然后交给PipelineExecutor#execute方法
(2)Flink集群收到JobGraph之后,将JobGraph翻译成ExecutionGraph,然后开始调度执行,启动成功之后开始消费数据
StreamGraph —> JobGraph —> ExecutionGraph —> 物理执行拓扑(Task DAG)
作业可以选择的集群模式:
1)Session模式的集群:一个集群可以运行多个作业
2)Per-Job模式的集群:一个集群只能运行一个作业,作业执行完毕则集群销毁
作业的提交模式:
1)Detached模式:Flink Client创建完毕集群之后,可以退出命令行窗口,集群独立运行
2)Attached模式: Flink Client 创建完集群之后,不能关闭窗口,需要与集群保持连接
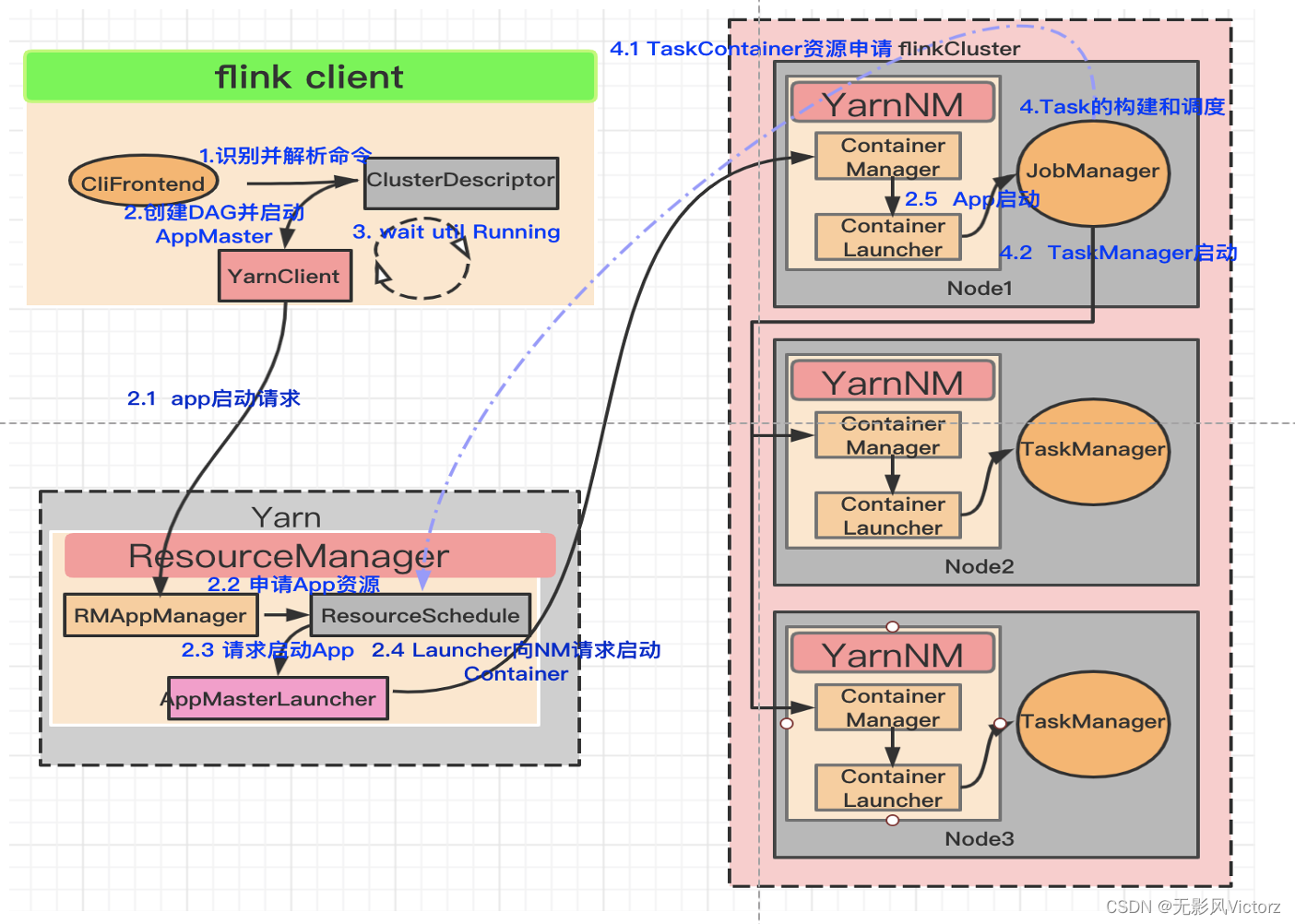
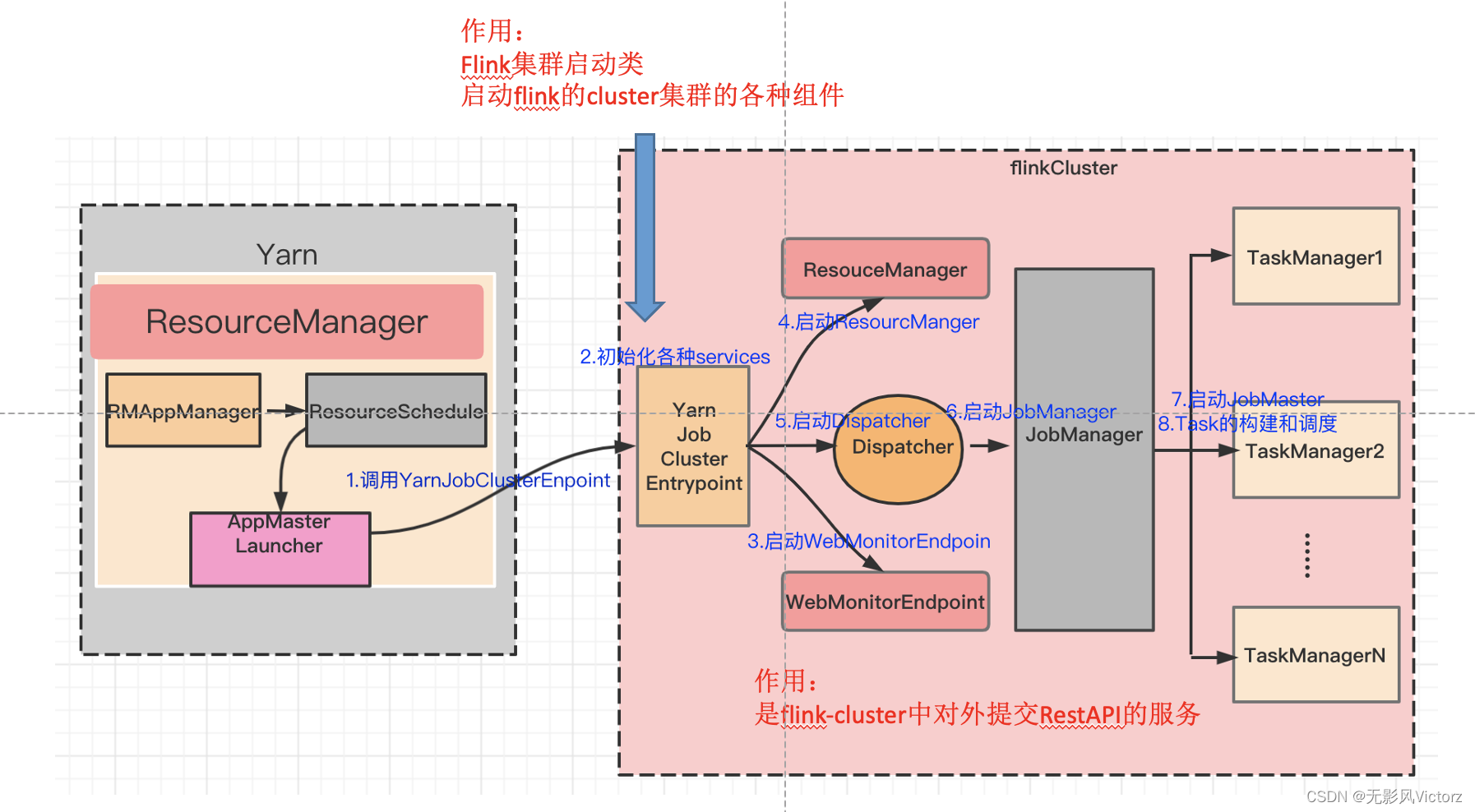
Yarn Session提交流程
(1)使用bin/yarn-session.sh提交会话模式的作业
(2)Yarn启动新Flink集群
(3)Flink Client通过Rest向Dispatcher提交JobGraph
(4)Dispatcher收到JobGraph后,为作业创建一个JobMaster,将作业交给JobMaster,构建ExecutionGraph
(5)JobMaster向YarnResourceManager申请资源,开始调度ExecutionGraph执行
(6)YarnResourceManager收到JobMaster的资源请求,如果当前有空闲Slot则将Slot分配给JobMaster
(7)YarnResourceManager将资源请求加入等待请求队列,并通过心跳向YARN RM申请新的Container资源来启动TaskManager进程
(8)YarnResourceManager启动,然后从HDFS加载Jar文件等所需要的相关资源,在容器中启动TaskManager
(9)TaskManager启动之后,向ResourceManager注册,把自己的Slot资源情况汇报给ResourceManager
(10)ResourceManager从等待队列中取出Slot请求,向TaskManager确认资源可用情况,并告知TaskManager将Slot分配给哪个JobMaster
(11)TaskManager向JobMaster提供Slot,JobMaster调度Task到TaskManager的此Slot上执行
Yarn Per-Job提交流程

K8s Session提交流程
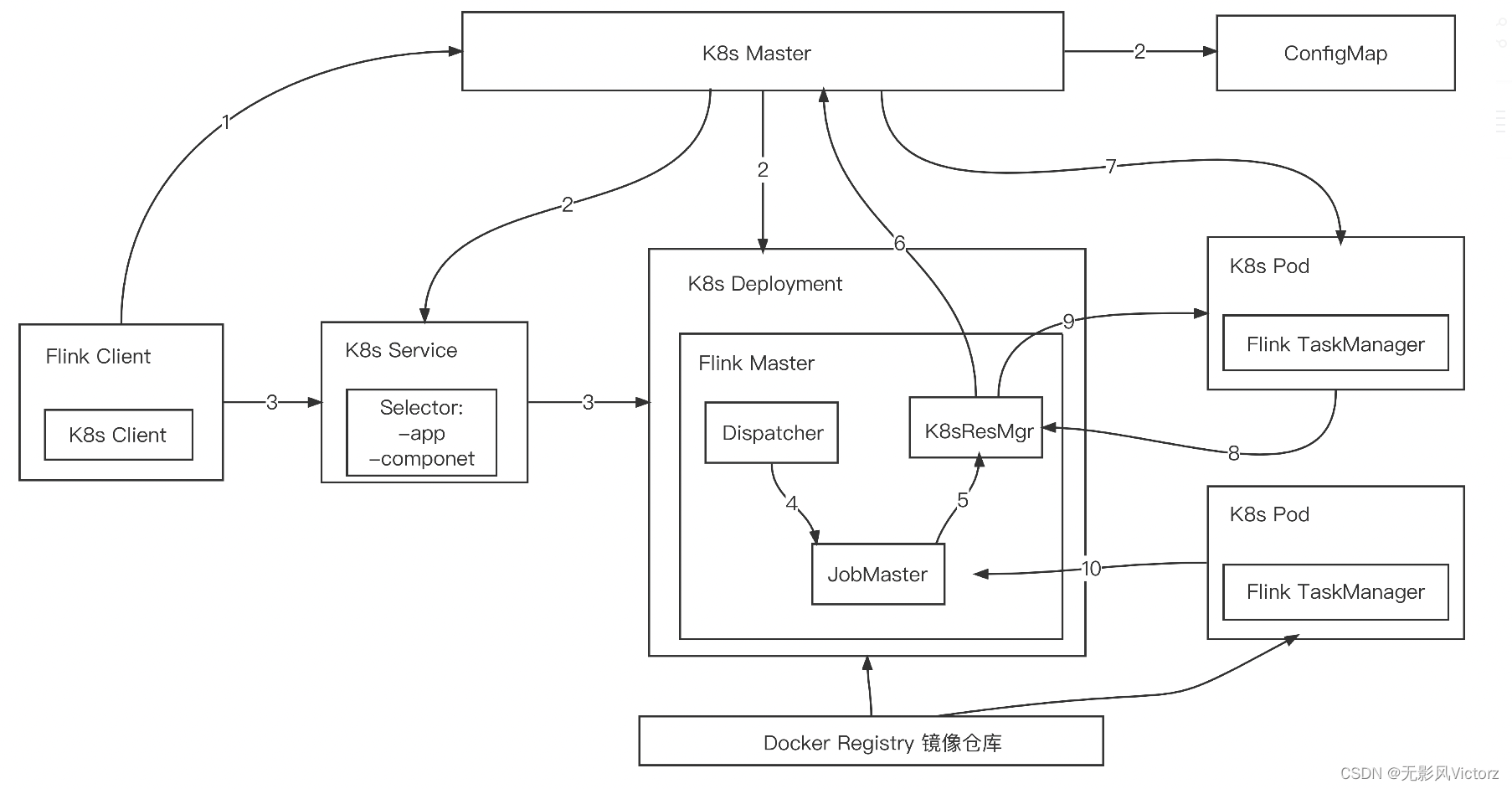
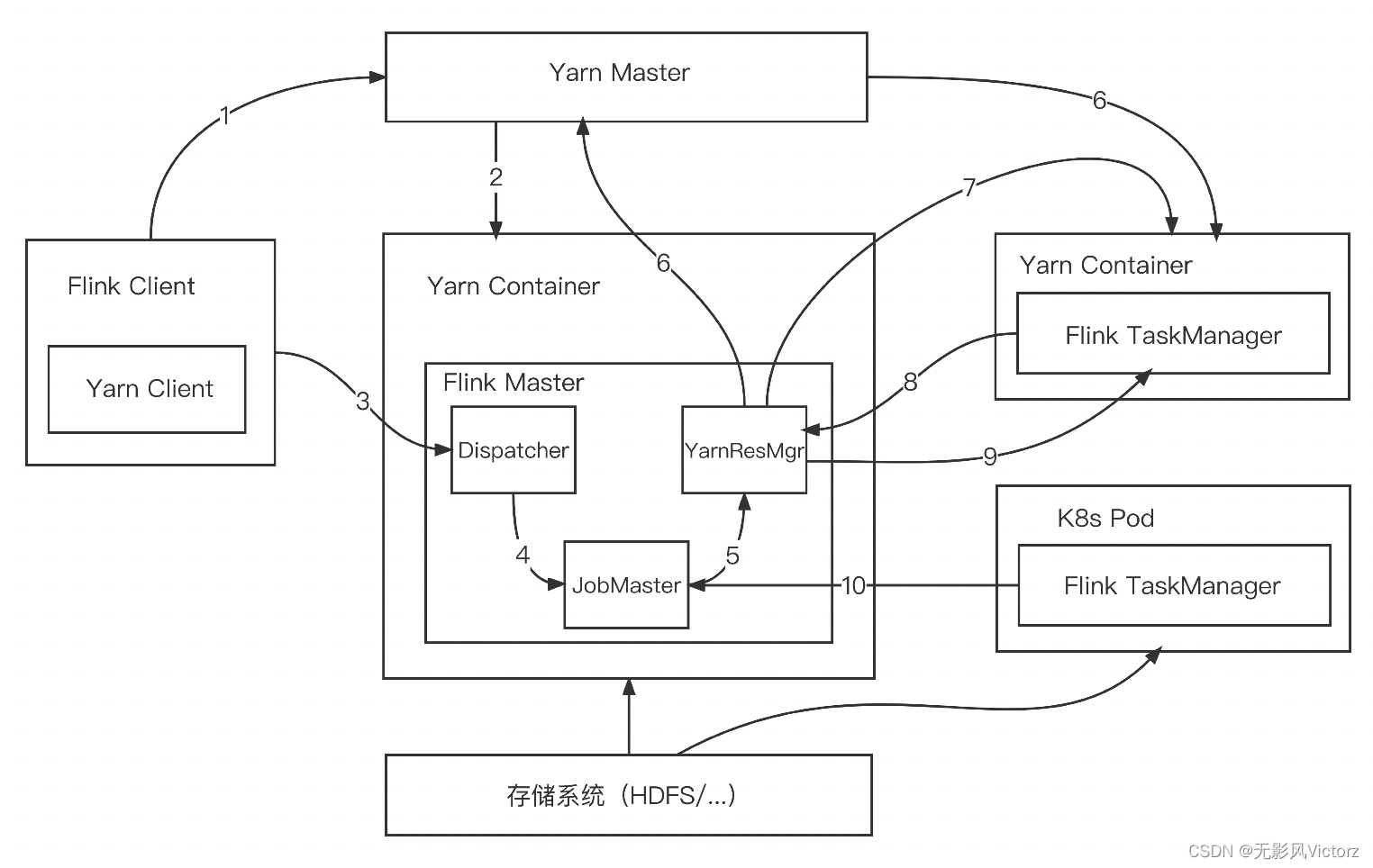
(1)Flink客户端首先连接Kubernetes API Server,提交Flink集群的资源描述文件
(2)Kubernetes Master会根据这些资源描述文件创建对应的Kubernetes实体
(3)Client用户可以通过Flink命令行向这个会话模式的集群提交任务。此时JobGraph会在Flink Client端生成,然后和用户jar包一起通过RestClient上传
(4)作业提交成功,Dispatcher会为每个作业启动一个JobMaster,将JobGraph交给JobMaster调度执行 K8s Session集群模式下,ResourceManager向K8s Master申请和释放TaskManager,除此之外,作业的调度与执行和Yarn模式是一样的
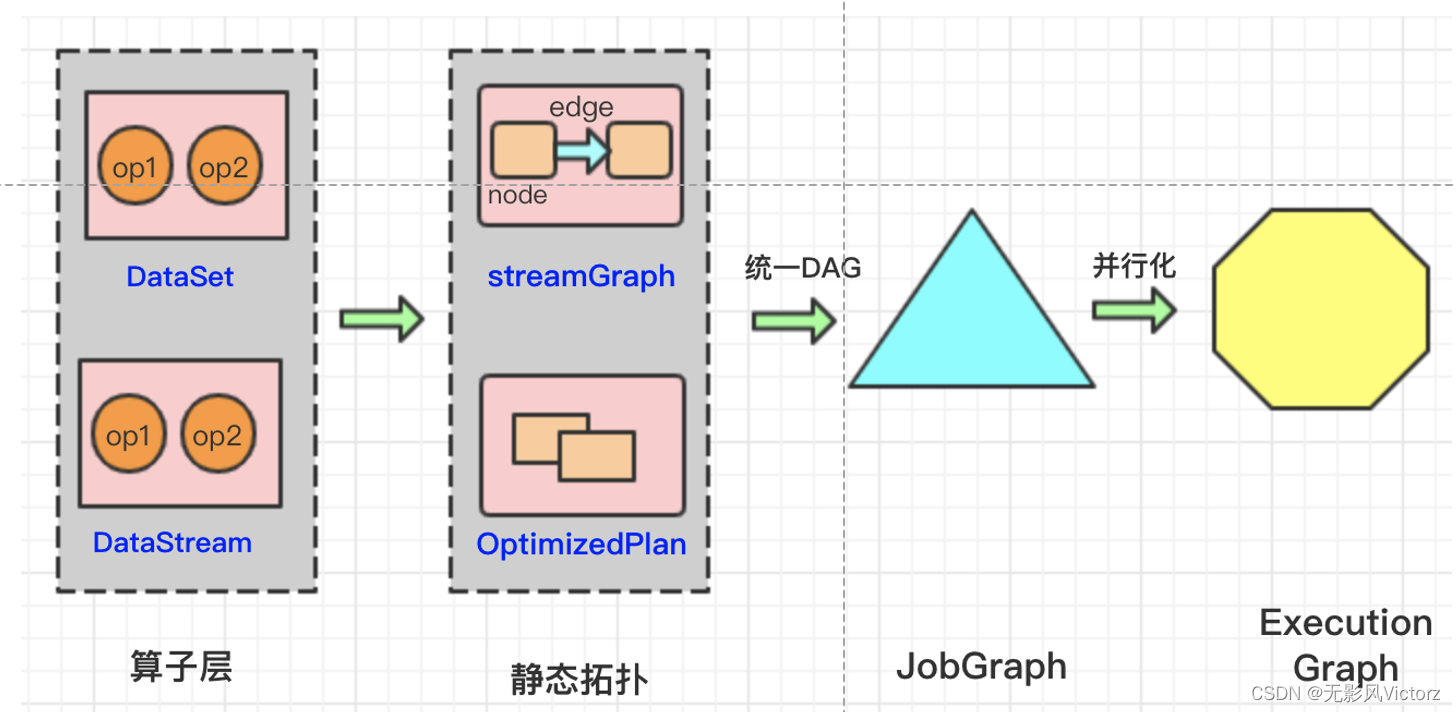
Graph总览:

批处理优化OptimizePlan
StreamGraph —> JobGraph —> ExecutionGraph
Stream Graph:
Stream Graph的核心抽象:
- StreamNode:表示一个算子
- StreamEdge
StreamGraph 在Flink Client中生成 生成入口: StreamExecutionEnvironment.java中,通过StreamGraphGenerator中生成
JobGraph:
在Stream Graph基础上进行一些优化,如通过OperatorChain机制将算子合并起来,在执行时,调度在同一个Task线程上,避免数据的跨线程,跨网络传输
JobGraph核心对象:
1)JobVertex:经过算子融合优化后,符合条件的多个StreamNode可以融合在一起生成一个JobVertex
2)JobEdge:是JobGraph中连接IntermediateDataSet 和 JobVertex 的边,表示JobGraph中的一个数据流转通道,其上游数据是IntermediateDataSet,下游消费者是JobVertex
3)IntermediateDataSet:中间数据集IntermediateDataSet是一种逻辑结构,用来表示JobVertex的输出,即该JobVertex中包含的算子会产生的数据集
生成过程:
(1)入口在SteamGraph中
流计算:StreamingJobGraphGenerator 批处理:JobGraphGenerator
(2)预处理:设置共享slotGroup,配置checkpoint、环境变量
(3)开始构建JobGraph中的点和边,从Source向下遍历StreamGraph,逐步创建JobGraph,在创建过程中完成算子融合(OperatorChain)优化 一个OperatorChain在同一个Task线程内执行,OperatorChain内部的算子之间,在同一个线程内通过方法调用的方式传递数据
算子融合条件:
1)下游节点的入边为1
2)StreamEdge的下游节点对应的算子不为null
3)StreamEdge的上游节点对应的算子不为null
4)StreamEdge的上下游节点拥有相同的slotSharingGroup,默认都是default
5)下游算子的连接策略为ALWAYS 6)上游算子的连接策略为ALWAYS或HEAD
7)StreamEdge的分区类型为ForwardPartitioner
8)上下游节点的并行度一致
9)当前StreamGraph允许chain
ExecutionGraph:
- 是调度Flink作业执行的核心数据结构,包含了作业中所有并行执行的Task信息、Task之间的关联关系、数据流转关系
- StreamGraph、JobGraph在Flink客户端中生成,然后提交给Flink集群
- JobGraph到ExecutionGraph的转换在JobMaster中完成
主要包括:
1)加入了并行度的概念,成为真正可调度的图结构
2)生成了JobVertex对应的ExecutionJobVertex和ExecutionVertex,与IntermediateDataSet对应的IntermediateResult和IntermediateResultPartition等
1- 构造ExecutionGraph的节点,将JobVertex封装成ExecutionJobVertex
2- 构造ExecutionEdge,建立ExecutionGraph的节点之间的相互联系,把节点通过ExecutionEdge连接
每个Task对应一个ExecutionGraph的一个ExecutionVertex
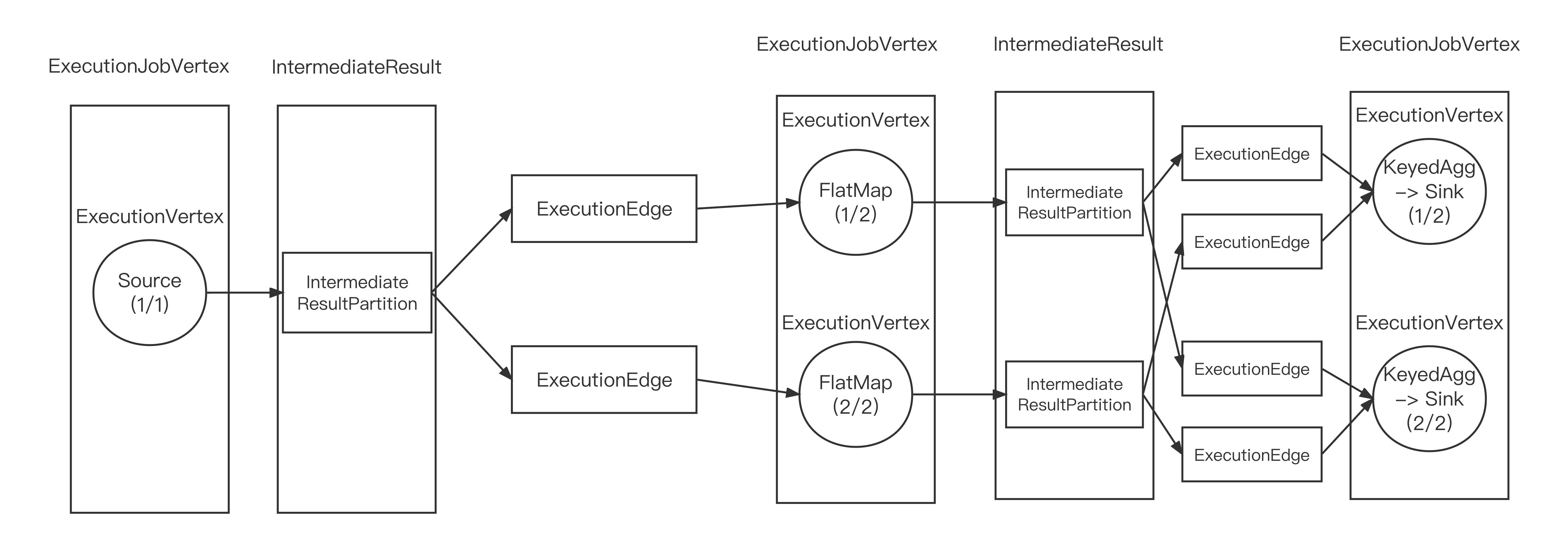
ExecutionGraph核心对象:
1)ExecutionJobVertex:对象和JobGraph中的JobVertex一一对应,包含一组ExecutionVertex,数量与该JobVertex中包含的StreamNode的并行度一致
2)ExecutionVertex:每一个并行执行的实例就是ExecutionVertex,相当于一个Task
3)IntermediateResult:中间结果集
4)IntermediateResultPartition:又叫做中间结果分区,表示1个ExecutionVertex输出结果
5)ExecutionEdge:连接到上游产生的IntermediateResultPartition
6)Execution:ExecutionVertex相当于每个Task的模板,在真正执行的时候,会将ExecutionVertex中的信息包装为一个Execution
构建ExecutionGraph节点的过程:
(1)设置并行度
(2)设置Slot共享和CoLocationGroup
(3)构建当前ExecutionJobVertex的输出中间结果(IntermediateResult)及其中间结果分区(IntermediateResultPartition)。
中间结果可以有1个或者多个,每对应一个下游JobEdge,创建一个中间结果, 如当前JobVertex只对应一个下游JobVertex,则构建1个中间结果
(4)构建ExecutionVertex,根据ExecutionJobVertex的并行度,创建对应数量的ExecutionVertex
(5)检查中间结果分区(IntermediateResultPartition)和ExecutionVertex之间有没有重复的引用
(6)对可切分的数据源进行输入切分(InputSplit)
构建ExecutionEdge 边的过程:
调用ejv.connectToPredecessor()方法,创建ExecutionEdge将ExecutionVertex 和 IntermediateResult关联起来,为运行时建立Task之间的数据交换建立物理传输通道
连接策略:
DistributionPattern.POINTWISE(点对点连接)
DistributionPattern.ALL_TO_ALL (全连接)
Flink资源管理:
1、资源管理包括:CPU、内存、GPU等,由资源管理框架(yarn、K8s、Mesos)来管理,Flink从资源管理框架申请和释放资源
2、Flink从资源框架申请资源容器(Yarn的Container或者K8s的Pod)
- JobMaster是SLot资源的使用者,向ResourceManager申请资源
- ResourceManager负责分配资源和资源不足时申请资源,资源空闲时释放资源
- TaskManager是Slot资源的持有者,TaskManager通过Slot来控制TaskManager能够接收多少个Task(TaskManager是一个Java进程,每个Task都是独立分配执行的线程)
如果一个TaskManager只有一个Slot,意味着每个Task独立地运行在JVM中;而一个TaskManager有多少个Slot,则意味着更多的Task可以共享JVM
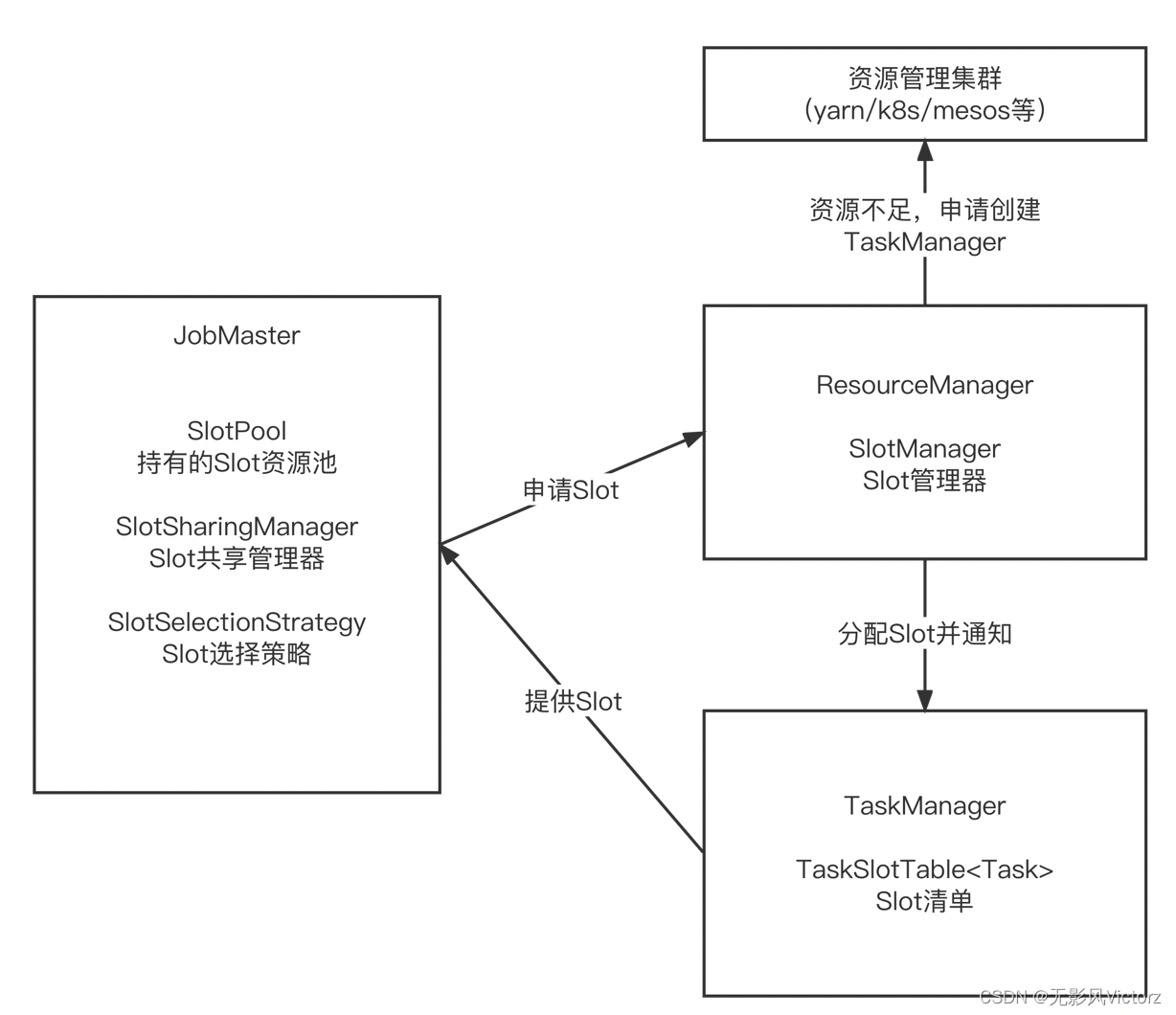
资源管理器主要作用:
1)申请容器启动新的TM,或者为作业申请Slot
2)处理JobMananger和TaskMananger的异常退出
3)缓存TaskManager(即容器),等待一段时间之后再释放掉不用的容器,避免资源反复地申请释放
4)JobManager和TaskManager的心跳感知,对JobManager和TaskMananger的退出进行对应的处理
ResourceManager的种类:
YarnResourceManager、KubernetesResourceManager、StandaloneResourceManager、MesosResourceManager
Slot管理器:
对TaskManager提供注册、取消注册、空闲退出等管理操作
SlotProvider接口定义了Slot的请求行为:
立即响应模式:Slot请求会立即执行
排队模式:排队等待可用Slot,当资源可用时分配资源
Slot选择策略:
决定Task运行在哪个TaskManager上
- 位置优先的选择策略:LocationPreferenceSlotSelectionStrategy
- 默认策略:不考虑资源的均衡分配,会从满足条件的可用Slot集合选择第1个
- 均衡策略:会从满足条件的可用Slot集合中选择剩余资源最多的Slot,尽量让各个TaskManager均衡承担计算压力
SlotPool:
JobMaster申请资源之后,会在本地持有Slot,避免ResourceManager异常导致作业运行失败
Slot共享:
默认情况下,Flink作业共享同一个SlotSharingGroup。可以在一个Slot中运行Task组成的流水线。
优点:
资源分配简单:Flink集群需要的Slot的数量和作业中的最高并行度一致,不需要计算一个程序总共包含多少个Task
资源利用率高:如果没有开启,资源密集型的Task和非密集型的占用相同资源,在TM层面上,资源没有充分利用
Flink作业调度:
调度器是Flink作业执行的核心组件,管理作业执行的所有过程,包括JobGraph到ExecutionGraph的转换,作业生命周期管理,作业的Task生命周期管理,资源申请和释放,作业和Task的Failover
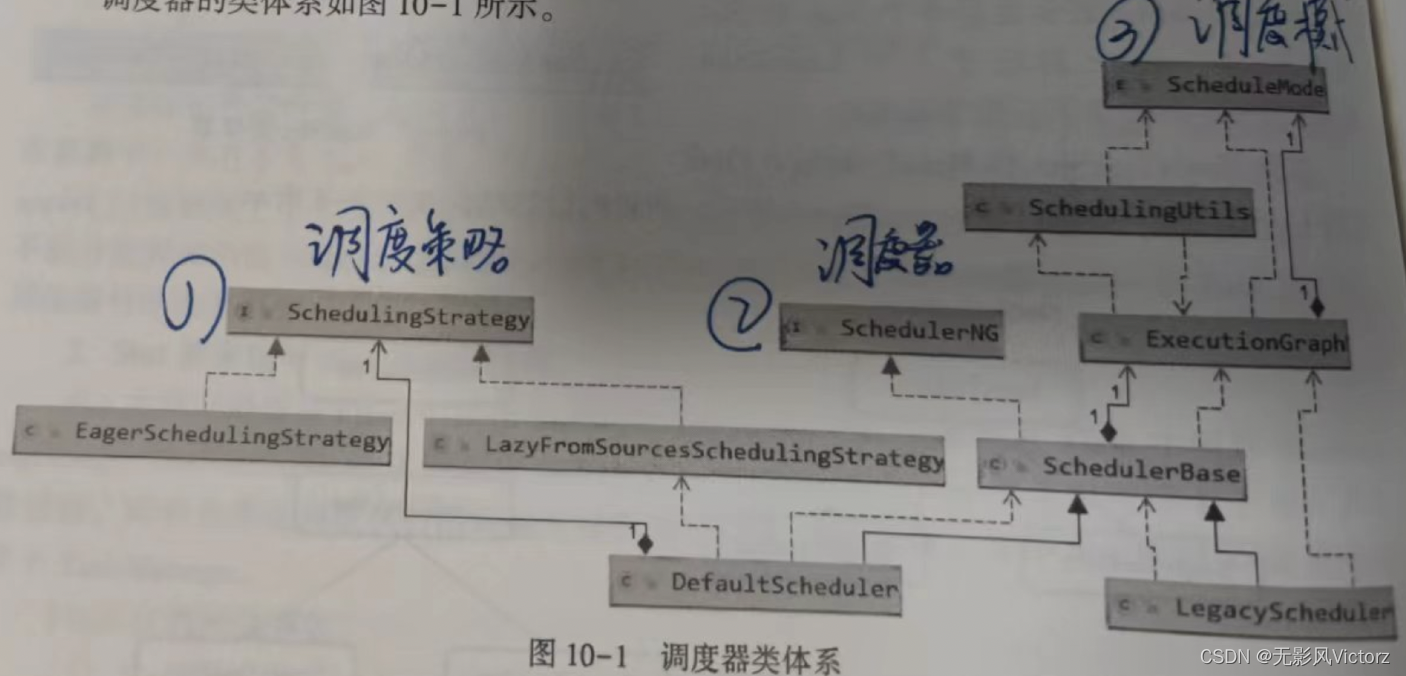
调度器:是作业的执行,异常处理的核心(SchedulerNG)
- 作业的生命周期管理,包括:调度、挂起、取消
- 作业执行资源的申请、分配、释放
- 作业的状态管理,作业发布过程中的状态变化和作业异常时的FailOver等
- 作业信息提供,对外提供作业的详细信息
调度行为:SchedulingStrategy定义了调度行为
- startScheduling:调度入口,触发调度器的调度行为
- restartTasks:重启执行失败的Task,一般是Task执行异常导致的
- onExecutionStateChange:当Execution的状态发生改变是
- onPartitionConsumable:当IntermediateResultPartition中的数据可以消费时
Flink调度模式:
- Eager调度:适用于流计算
- 分阶段SLot重用调度(Lazy_From_Source_With_Batch_Slot_Request):适用于批处理
- 分阶段调度(Lazy_From_Source):适用于批处理
调度策略:
流(EagerSchelingStrategy):需要一次性获取所有需要的Slot,部署Task并开始执行
批(LazyFromSourceSchedulingStrategy): 可以分阶段调度执行
Flink执行模式:即推送的模式
1)Pipelined:流水线方式执行作业,如果出现死锁,则数据以Batch方式执行交换
2)Pipelined_Forced:以流水线方式执行作业,即便流水线可能出现死锁的数据交换时仍然被执行
3)Pipelined_With_Batch_Fallback:此模式首先使用Pipelined启动作业,如果可能出现死锁则使用Pipelined_Forced启动作业,当作业异常退出时,则使用Batch模式重新执行作业
4)Batch:批处理模式,对所有shuffle和broadcast都是用Batch模式执行,仅本地的数据交换使用Pipelined模式
5)Batch_Forced:强制批处理模式,所有数据交换都是用Batch模式
数据分区模式:
与执行模式一起完成流批在数据交换层面的统一
1)BLOCKING:类型的分区会等待数据完全处理完毕,才交给下游进行处理,不会与下游进行数据交换
2)BLOCKING_PERSISTENT:数据分区类似于BLOCKING,但是其生命周期由用户指定
3)PIPELINED:
4)PIPELINED_BOUNDED:是PIPELINED带有一个有限大小的本地缓冲池
作业生命周期管理:
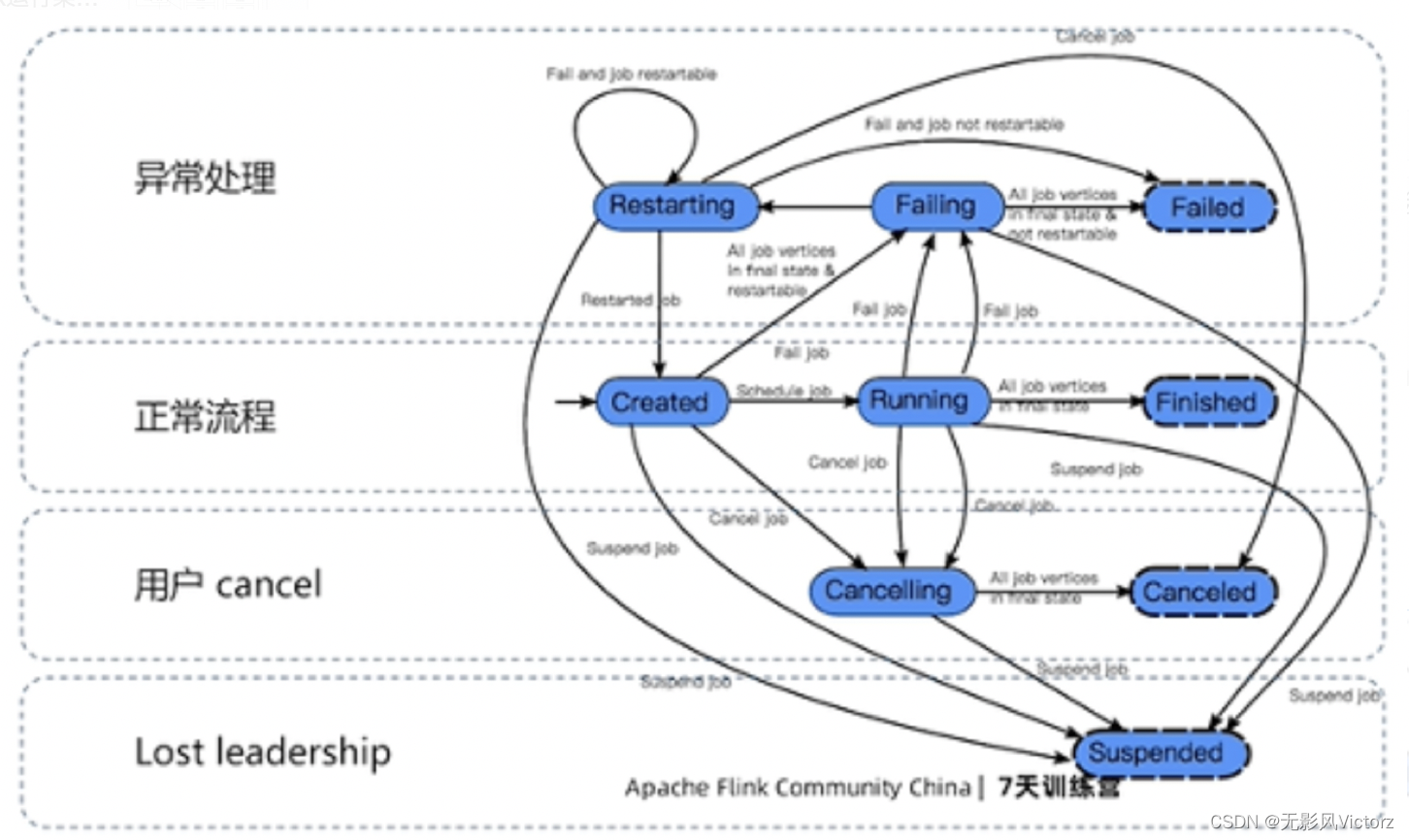
一个JobManager可以有多个JobMaster,一个JobMaster对应一个作业
JobMaster:
1)调度执行和管理
将JobGraph转化为ExecutionGraph,调度Task的执行,并处理Task的异常,进行作业恢复或者中止
- InputSplit分配:在批处理中使用,为批处理计算任务分配待计算的数据分片
- 结果分区跟踪:PartitionTracker跟踪批处理中的结果分区,当结果分区消费完之后,具备释放条件,向TaskExecutor和ShuffleMaster发出释放请求
- 作业执行异常:根据作业执行异常,选择重启作业或停止作业
2)作业Slot资源管理器:JobMaster交给SlotPool执行;SlotPool持有资源,资源不足时负责与ResourceManager交互申请资源
释放TaskManager的情况:作业停止、闲置TM、TM心跳超时
3)检查点与保护点:CheckpointCoordinator负责进行检查点的发起,完成,确认
4)监控:反压跟踪、作业状态、作业各算子吞吐量等监控指标
5)心跳管理
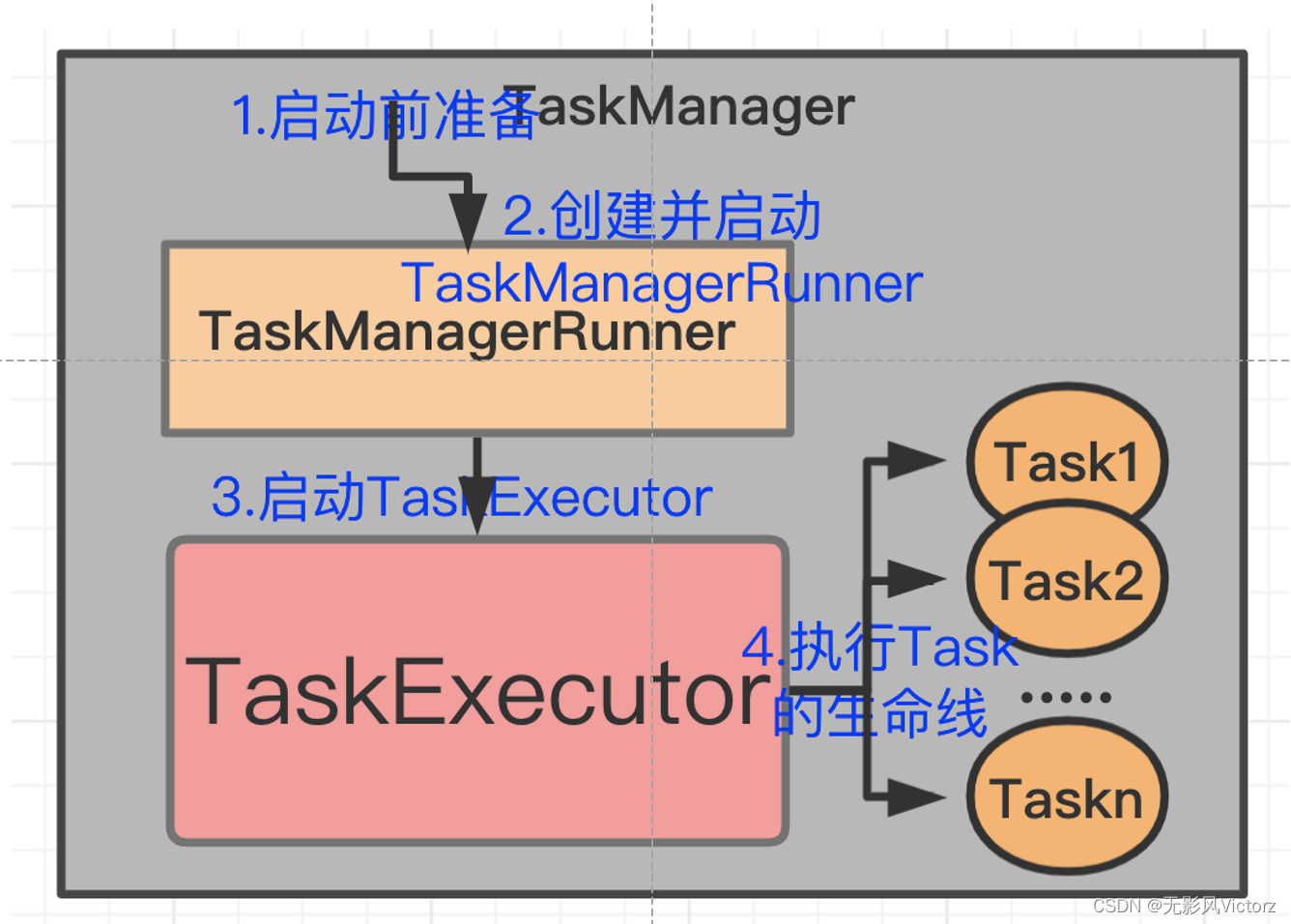
TaskManager:
实现类是TaskExecutor
TaskManager是计算资源的载体,一个TaskManager通过Slot切分其CPU、内存等计算资源
Task:
Flink流计算使用StreamTask体系、批处理执行层面使用了BatchTask体系,两者并不互通
但是通过Task可以解耦合
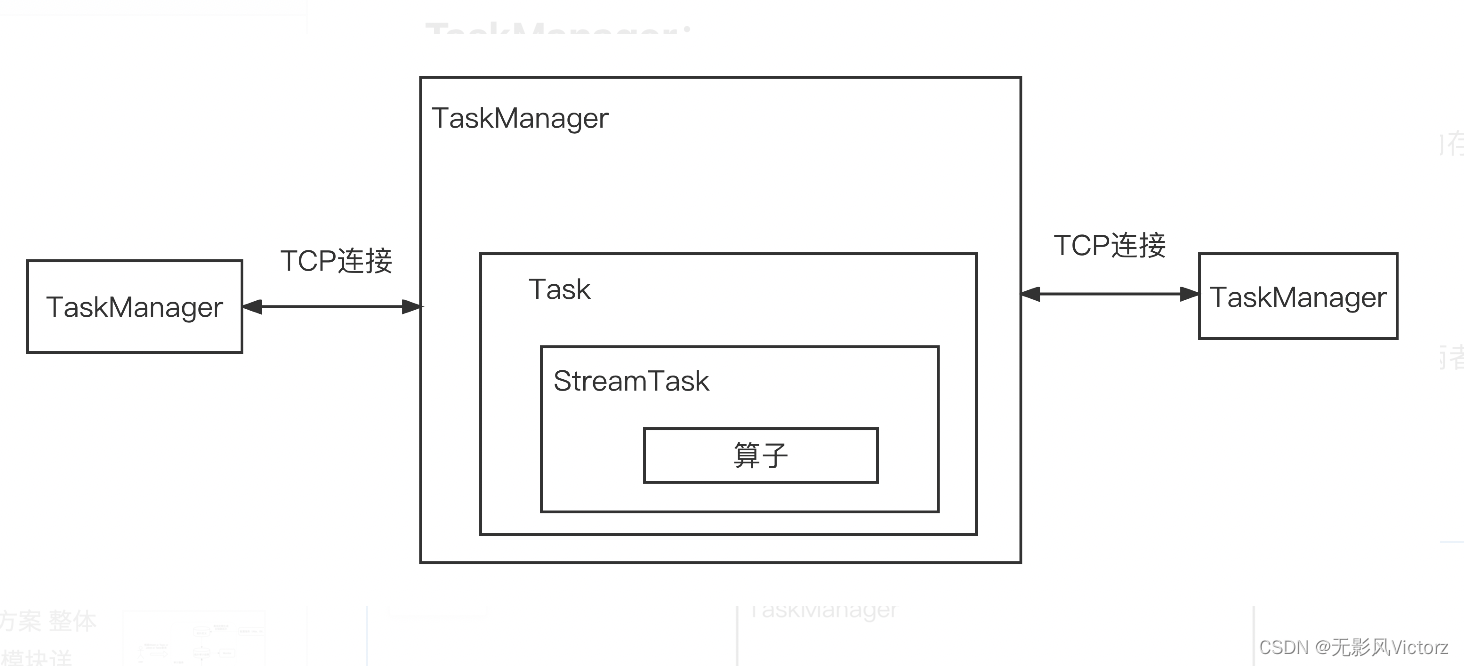
核心组件:
1)TaskStateManager:负责State的整体协调。封装了CheckpointResponder,在StreamTask来跟JobMaster交互,汇报检查点状态
2) MemoryManager:Task通过该组件申请和释放内存
3)LibraryCacheManager:在Task启动的时候,需要从此组件远程下载需要的jar包文件
4)InputSplitProvider:在数据源算子中,用来向JobMaster请求分配数据集的分片,然后读取该分片的数据
5)ResultPartitionConsumableNotifier:结果分区可消费通知器
6)PartitionProducerStateChecker:分区状态检查器,用于检查生产端分区状态
7)TaskLocalStateStore:在TaskManager本地提供State的存储,恢复作业的时候,优先从本地恢复,提高恢复速度
8)IOManager:IO管理器,负责将数据溢出到磁盘,并在需要的时候将其读取出来
9)ShuffleEnvironment:数据交换的管理环境,其中包含了数据写出、数据分区的管理等组件
10)BroadcastVariableManager:广播变量管理器,Task可以共享该管理器,通过引用计数跟踪广播变量的使用
11)TaskEventDispatcher:任务事件分发器,从消费者任务分发事件给生产者任务
StreamTask:是所有流计算作业子任务的执行逻辑的抽象类
TwoInputStreamTask:两个输入
OneInputStreamTask:单个输入
SourceStreamTask:流模式执行数据读取
BoundedStreamTask:模拟批处理的数据读取
SourceReaderStreamTask
StreamTask生命周期
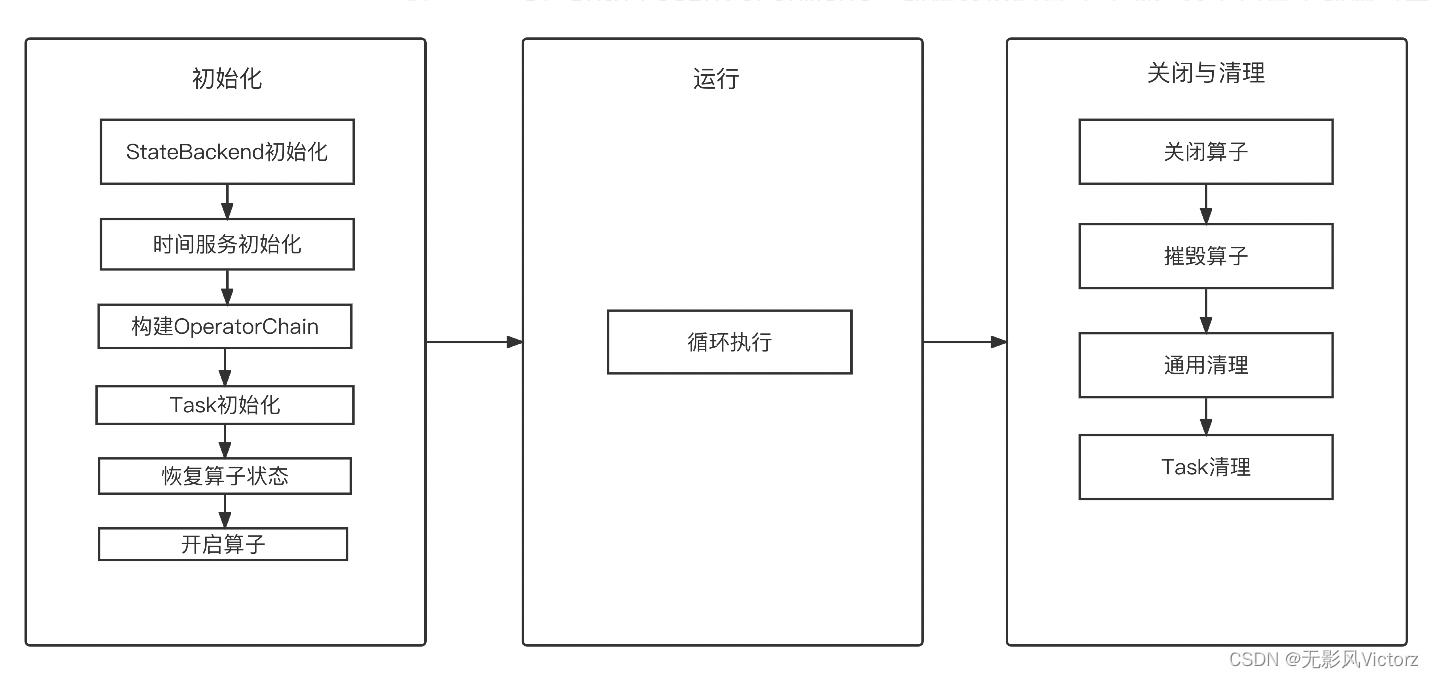
作业启动
JobManager中会为每个作业启动一个JobMaster,并将剩余的工作交给JobMaster。
JobMaster负责整个作业生命周期中的资源申请释放、调度、容错等细节
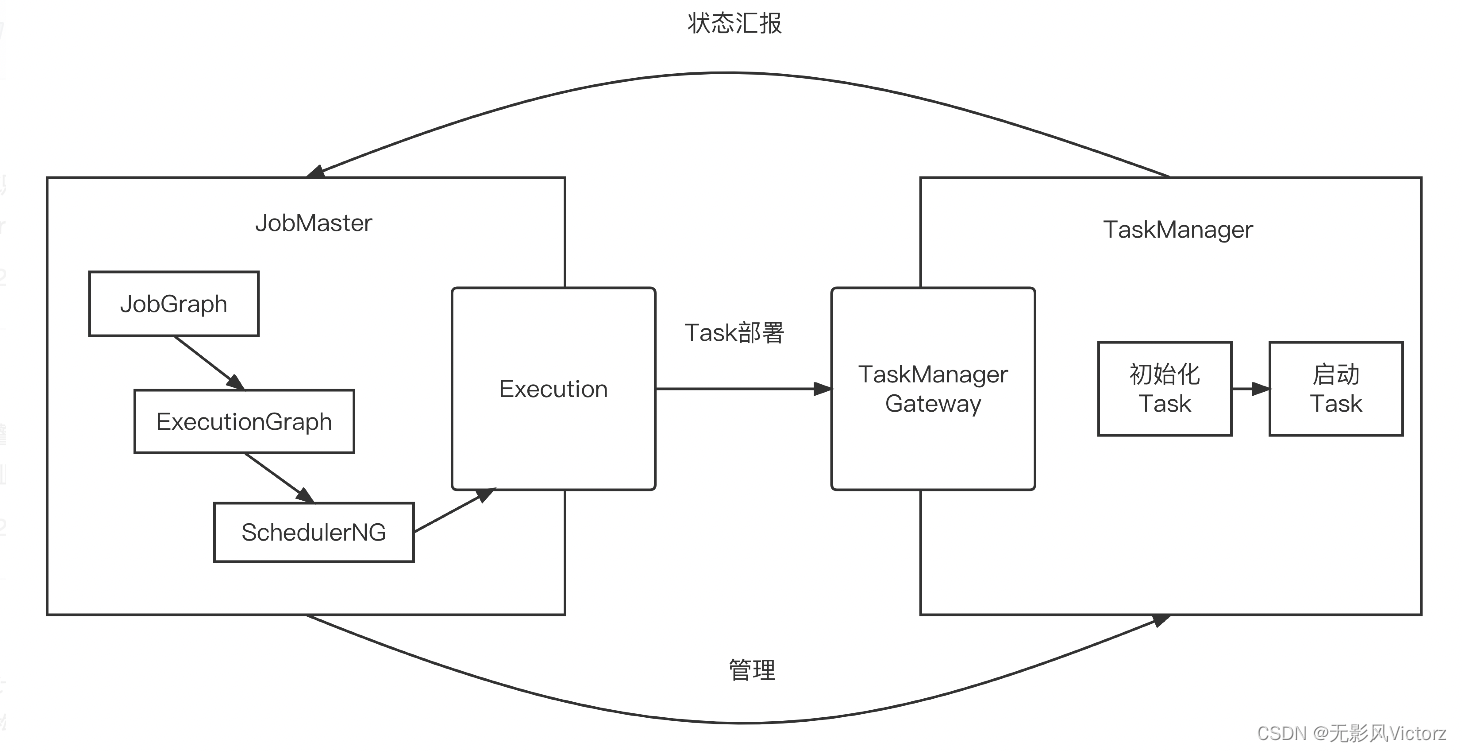
作业的失败调度保障
Flink使用容错机制:
分布式快照保存作业状态,与Flink的作业恢复机制相结合,确保数据不丢失、不重复
Task错误恢复策略:
RestartAllStrategy: 若Task发生异常,则重启所有的Task,恢复成本高,但是作业一致性最安全
RestartPipelinedRegionStrategy: 分区恢复策略,若Task发生异常,则重启该分区的所有Task,恢复成本低,实现逻辑复杂
FailoverRegion切分:
(1)带有Colocation限制的作业:带有CoLocation限制的作业不切分,所有的Task都位于同一个FailoverRegion
(2)按照ResultPartitionType纵向切分:按照数据流转方向,以Task间的数据传递方式来确定FailoverRegion的边界,就是以Shuffle作为边界
(3)按照上下游的数据依赖关系横向切分:没有关系的Task隶属不同的分区(类似Spark窄依赖)
作业重启策略:
- FixedDelayRestartStrategy:允许指定次数内的Execution失败,如果超过该次数,则导致作业失败
- FailureRateRestartStrategy:允许在指定时间窗口中指定次数内的Execution失败,如果超过这个频率则导致作业失败
- NoRestartStrategy:在Execution失败时直接让作业失败
Flink容错:
JobManager、TaskManager、JobMaster三个角色两两之间相互发送心跳来进行故障检测
在HA场景下,ResourceManager和JobMaster都会注册到Zookeeper节点上来实现Leader锁

HA服务的三种实现:
- ZooKeeperHAServices
- StandaloneHAServices
- EmbeddedHASerivices
JobMaster的容错:
1. TaskManager应对JobMaster故障:
TM会根据JM管理的Job ID,将TM上所有相关Task取小执行,Task进入Failed状态,但仍然保留为job分配的slot一段时间。然后尝试连接新的JobMaster Leader,如果新的JobMaster超过等待时间仍然没有连接上,TM不再等待,标记Slot为空闲并通知ResourceManager,RM在下一次Job调度中分配这些Slot资源
2. ResourceManager应对JobMaster故障:
ResourceManager会尝试重新连接,其他不做处理
3. JobMaster切换:
新的JobMaster Leader选举出来之后,会通知ResourceManager和TaskManager
ResourceManager容错:
1. JobMaster应对ResourceManager故障:
JobMaster会尝试重新连接,在HA模式下,会得知新的ResourceManager地址,并痛殴地址重新与ResourceManager连接。如果实在联系不上,则整个集群会停止
2. TaskManager应对RM故障:同上
TaskManager容错:
1. ResourceManager应对TaskManager故障:
RM监测到TM故障,会通知JobMaster启动一个新的TM作为代替
2.JobMaster应对TM故障:
首先会从自己的SlotPool中移除该TM,并释放该TM的Slot,触发Execution异常处理
JobMaster和ResourceManager同时故障:
TM会优先恢复与心的JobMaster之间的连接,再同时尝试与ResourceManager建立连接
Flink作业执行:
经过Flink的多层Graph转换之后,作业进入调度阶段,开始分发任务执行,最终会在集群中形成物理拓扑结构
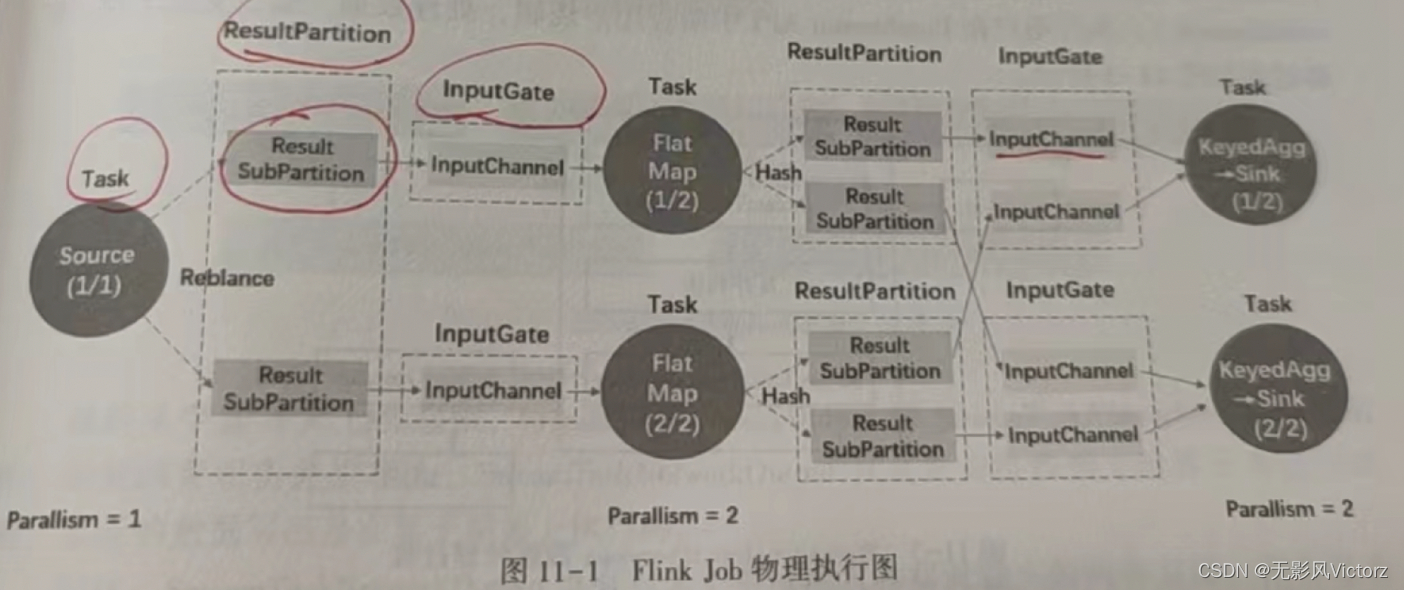
主要的核心对象包括:
- 输入处理器:StreamInputProcessor,是对StreamTask中读取数据行为的抽象,在其实现中要完成数据的读取、处理、输出给下游的过程
- StreamOneInputProcessor:在OneInputStreamTask中,只有1个上游输入
- StreamTwoInputProcessor:在TwoInputStreamTask中,有2个上游输入

- Task输入:StreamTaskInput,是StreamTask的数据输入的抽象
- StreamTaskNetworkInput:负责从上游Task获取数据,使用InputGate作为底层读取数据
- StreamTaskSourceInput:负责从外部数据源获取数据,本质上是使用SourceFunction读取数据,交给下游的Task
- Task输出:StreamTaskNetworkOutput
- 结果分区:ResultPartition,用来表示作业的单个Task产生的数据
- 结果子分区:ResultSubPartition,结果子分区是结果分区的一部分,负责存储实际的Buffer
- PipelinedSubPartition:是纯内存型的结果子分区,只能被消费1次
- BoundedBlockingSubPartition:用作对批处理Task的计算结果的数据存储,其行为是阻塞的,需要等待上游所有的数据处理完毕,然后下游才开始消费数据,可以消费1次或多次
- 有限数据集:BoundedData,定义了批处理中间结果数据集的阻塞式接口
- 输入网关:InputGate,是Task的输入数据的封装,和JobGraph中的JobEdge一一对应
- 输入通道:InputChannel,每个InputGate都会包含一个以上的InputChannel和ExecutionEdge一一对应,也和结果子分区一对一相连,即一个InputChannel接收一个结果子分区的输出
Flink数据交换:
PULL模式:主要用于批处理。与Spark类似,将计算过程分成多个阶段,上游完全计算完毕之后,下游从上游拉取数据开始下一阶段计算
PUSH模式:主要用于流处理。也叫pipeline
| 对比点 | Pull | Push |
| 延迟 | 延迟高(需要等待上游所有计算完毕) | 低延迟(上游边计算边向下游输出) |
| 下游状态 | 有状态,需要知道何时拉取 | 无状态 |
| 上游状态 | 无状态 | 有状态,需要了解每个下游的推送点 |
| 连接状态 | 短连接 | 长连接 |
关键组件:
- RecordWriter:负责将Task处理的数据输出,面向的是StreamRecord
- 单播:ChannelSelector,对数据流中的每一条数据记录进行选路,有选择地写入到一个输出通道的ResultSubPartition中
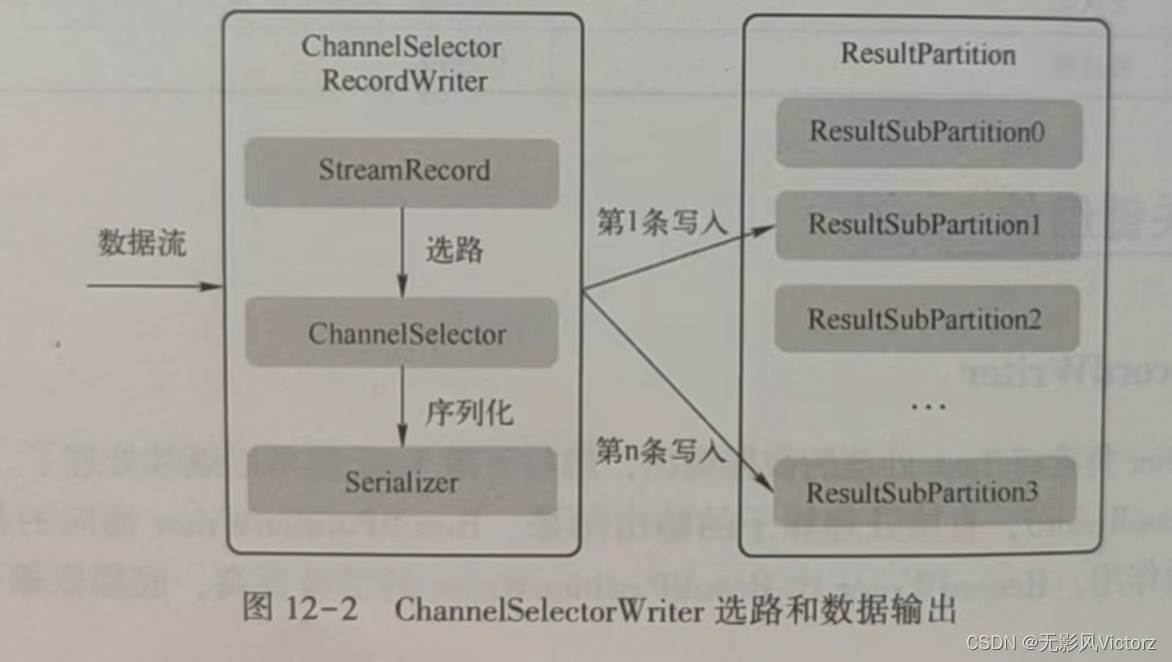
- 广播:向下游所有的Task发送相同的数据

- RecordSerializer:数据记录序列化器
- RecordDesrializer:数据反序列化器
- ResultSubPartitionView:结果子分区视图,定义了ResultSubPartitio中读取数据,释放资源等抽象行为
- 数据输出:
- WatermarkGaugeExposingOutput:定义了Watermark监控指标计算行为,将最后一次发送给下游的Watermark作为其指标值
- RecordWriterOutput:包装了RecordWriter,使用RecordWriter把数据交给数据交换层
- ChainingOutput & CopyingChainingOutput:在OperationChain内部的算子之间传递数据用
- DirectedOutput & CopyingDirectedOutput:基于一组OutputSelector选择发送给下游哪些Task
- BroadcastingOutputCollector & CopyingBroadcastingOutputCollector:向所有下游Task广播数据
- CountingOutput:只是用来记录其他Output实现类向下游发送的数据元素个数
数据传递:
- 本地线程内数据传递

- 本地线程间的数据传递
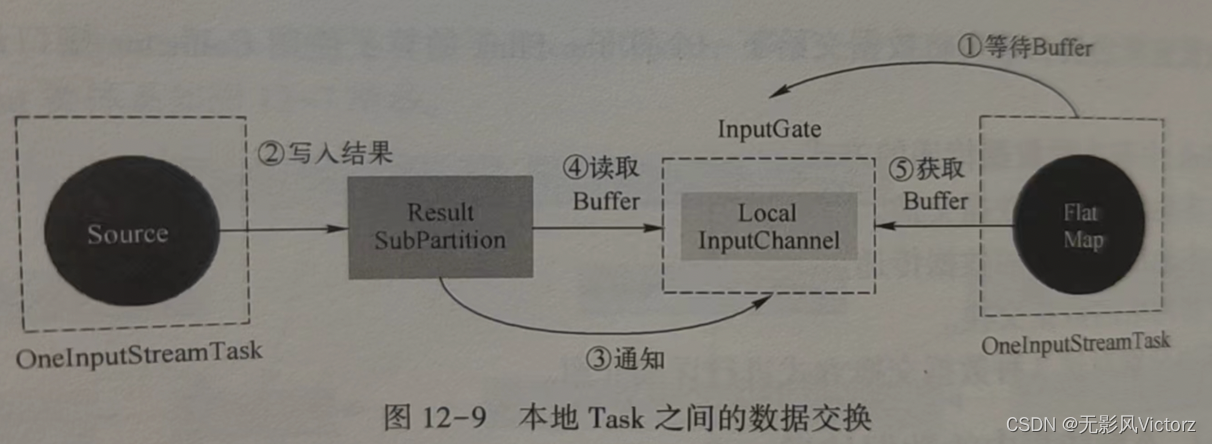
本地数据传递基本过程:
(1)Flatmap所在线程首先从InputGate的LocalInputChannel中消费数据,如果没有数据则通过InputGate中的inputChannelWithData.wait()方法阻塞等待数据
(2)Source算子持续地从外部数据源写入ResultSubPartition中
(3)ResultSubPartition将数据刷新写入LocalBufferPool中,然后通过inputChannelWithData.notifyAll()方法唤醒FlatMap线程
(4)唤醒FlatMap所在的线程
(5)FlatMap线程首先调用LocalInputChannel从LocalBuffer中读取数据,然后进行数据的反序列化
- 跨网络数据传输
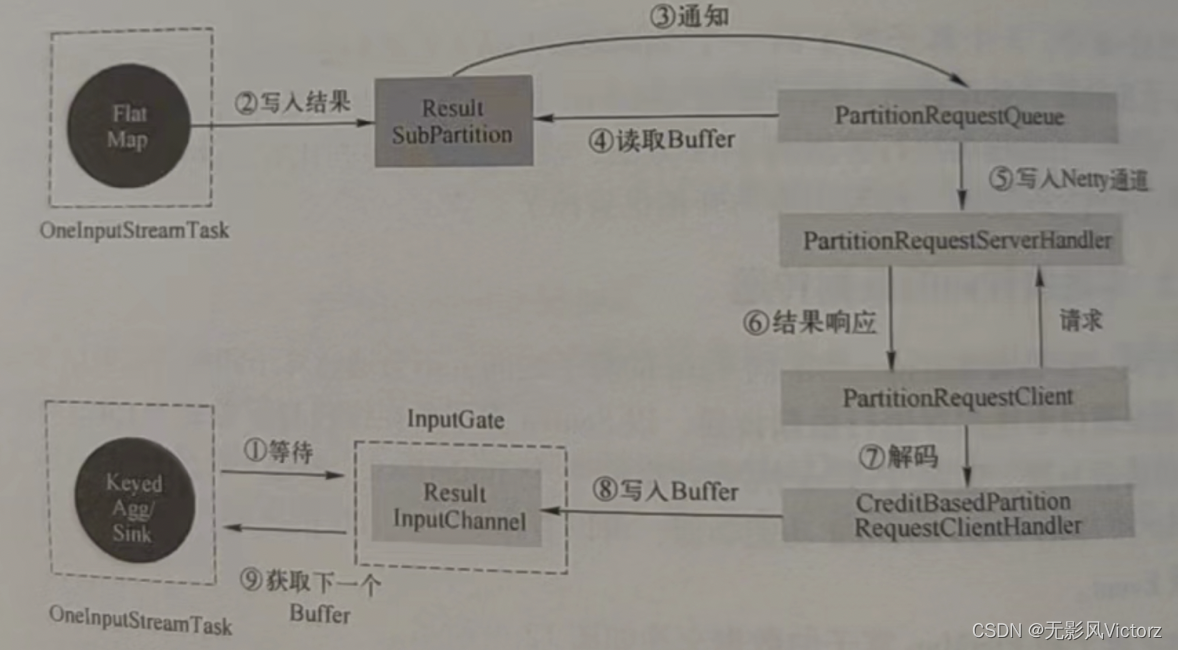
- 数据在本算子处理完后,交给RecordWriter,每条记录都要选择下游节点,所以要经过ChannelSelector,找到对应的结果子分区
- 每个结果子分区都有一个独有的序列化器,把这条数据记录序列化为二进制数据
- 数据被写入结果分区下的各个子分区中,此时数据已经存入DirectBuffer
- 单独的线程控制数据的flush速度,一旦触发flush,则通过Netty的nio通道向对端写入
- 对端的Netty Client接收到数据,解码出来,把数据复制到Buffer中,然后通知InputChannel
- 有可用的数据时,下游算子阻塞醒来,从InputChannel取出Buffer,再反序列化成数据记录,交给算子执行用户代码UDF
网络通信
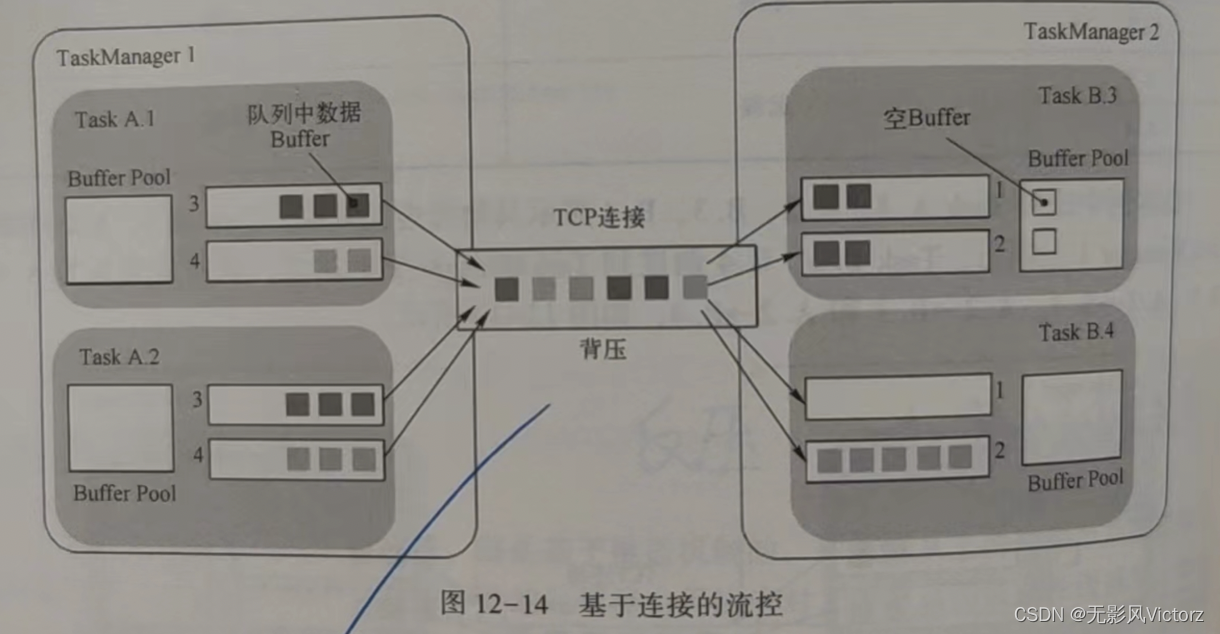
反压:如果下游的处理能力无法应对上游节点的数据发送速度,那么就会导致数据在下游处理节点累积,一旦超过了处理限度,就可能会发生数据丢失、进程错误、内存不足、CPU使用率过高等难以预期的情况
无流控模型:
一旦下游某个Buffer满了,就会产生反压,导致其他下游Buffer的数据接收也收到影响
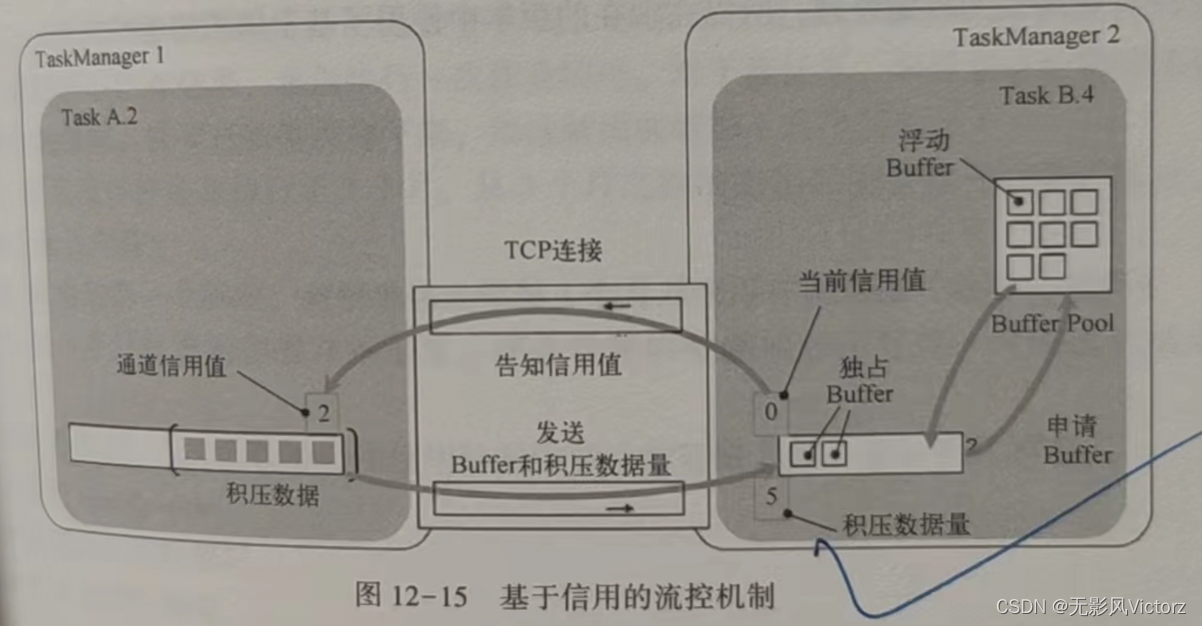
基于信用的流控:
每个远端的InputChannel都有自己的一组独占缓冲区,不再使用共享的本地缓冲池
下游接收端当前可用的Buffer数量作为信用值通知给上游,每个结果子分区将跟踪其对应的InputChannel的信用值。如果信用可用,则缓存仅转发到较低层的网络栈,每发送一个Buffer都会对InputChannel的信用值减1,在发送Buffer的同时,还会发送前结果子分区队列中的挤压数据量。下游的接收端会根据挤压数据量从浮动缓冲区申请适当数量的Buffer。
应用容错
数据的可靠程度:
- 最多一次(At-Most-Once),数据不重复处理,但可能丢失
- 最少一次(At-Least-Once),数据可能重复处理,但保证不丢失
- 引擎内严格一次(Exactly-Once),数据不丢失、不重复,在Flink中开启检查点,且对Barrier进行对齐,就能达到引擎内严格一次的处理保证。如果数据源支持断点读取,则能支持从数据源到引擎处理完毕,再写出到外部存储之前的过程中的严格一次
- 端到端严格一次(End-to-End Exactly-Once),从数据读取、引擎处理到写入外部存储的整个过程,数据不重复、不丢失(需要数据源支持可重放,外部存储支持事物机制,能够进行回滚)
检查点:Checkpoint
保存点:Savepoint,是基于Flink检查点机制的应用完整快照备份机制
检查点恢复策略:
- 定期恢复策略:fixed-delay,固定延迟重启策略会尝试一个给定的次数来重启Job,如果超过了最大的重启次数,job会失败
- 失败比率策略:failure-rate,失败后重启,但如果超过了失败率,job会被认定失败
- 直接失败策略:失败不重启
保存点恢复:
在作业变更(逻辑修改、修复bug)的情况下,要考虑以下几点:
- 算子的顺序改变:如果UID没有改变,则可以恢复
- 作业中添加了新的算子:如果是无状态算子,则没有影响。如果是有状态算子,则跟无状态算子一样处理
- 从作业中删除一个有状态的算子:如果找不到OperatorId,会报错,可以通过命令添加--allowNonRestoredState 跳过舞法恢复的算子
- 添加和删除无状态的算子
- 恢复的时候掉整并行度
恢复最好使用事件时间,而不是处理时间
Checkpoint关键组件:
- 检查点协调器:CheckpointCoordinator,负责协调Flink算子的State的分布式快照
当触发快照的时候,CheckpointCoordinator向算子中注入Barrier消息,然后等待所有的Task通知检查点确认完成,同时持有所有Task在确认完成消息中上报地State句柄
- 检查点消息:AbstractCheckpointMessage,包含检查点所属的作业标识、检查点编号、Task标识
Checkpoint基本过程:
数据流切分:Flink使用Barrier来切分数据流,Barrier会周期性注入数据流中
Barrier会严格保证顺序,不会超过其前面的数据,两个Barrier之间的数据流中的数据隶属同一个检查点
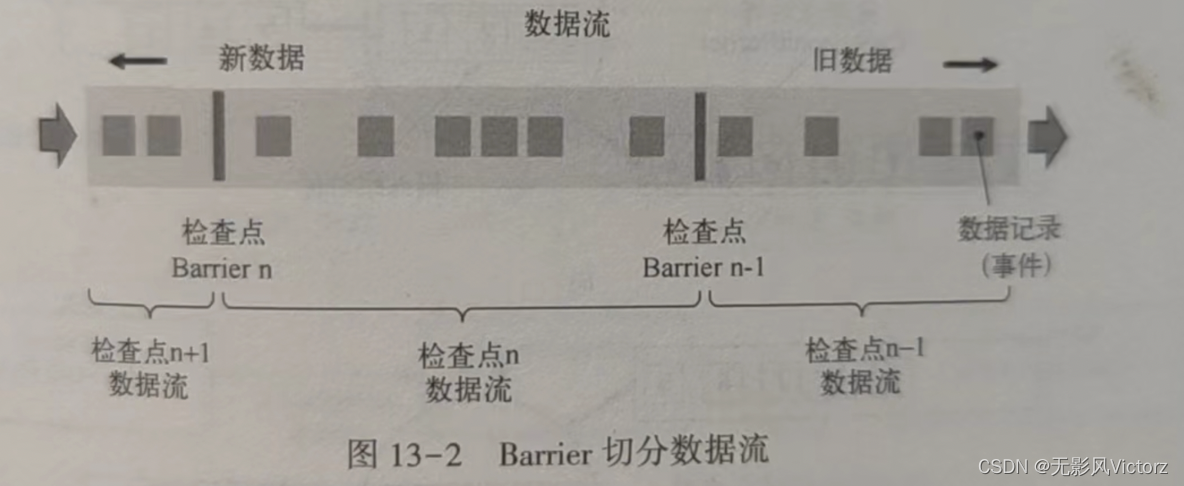
Barrier对齐
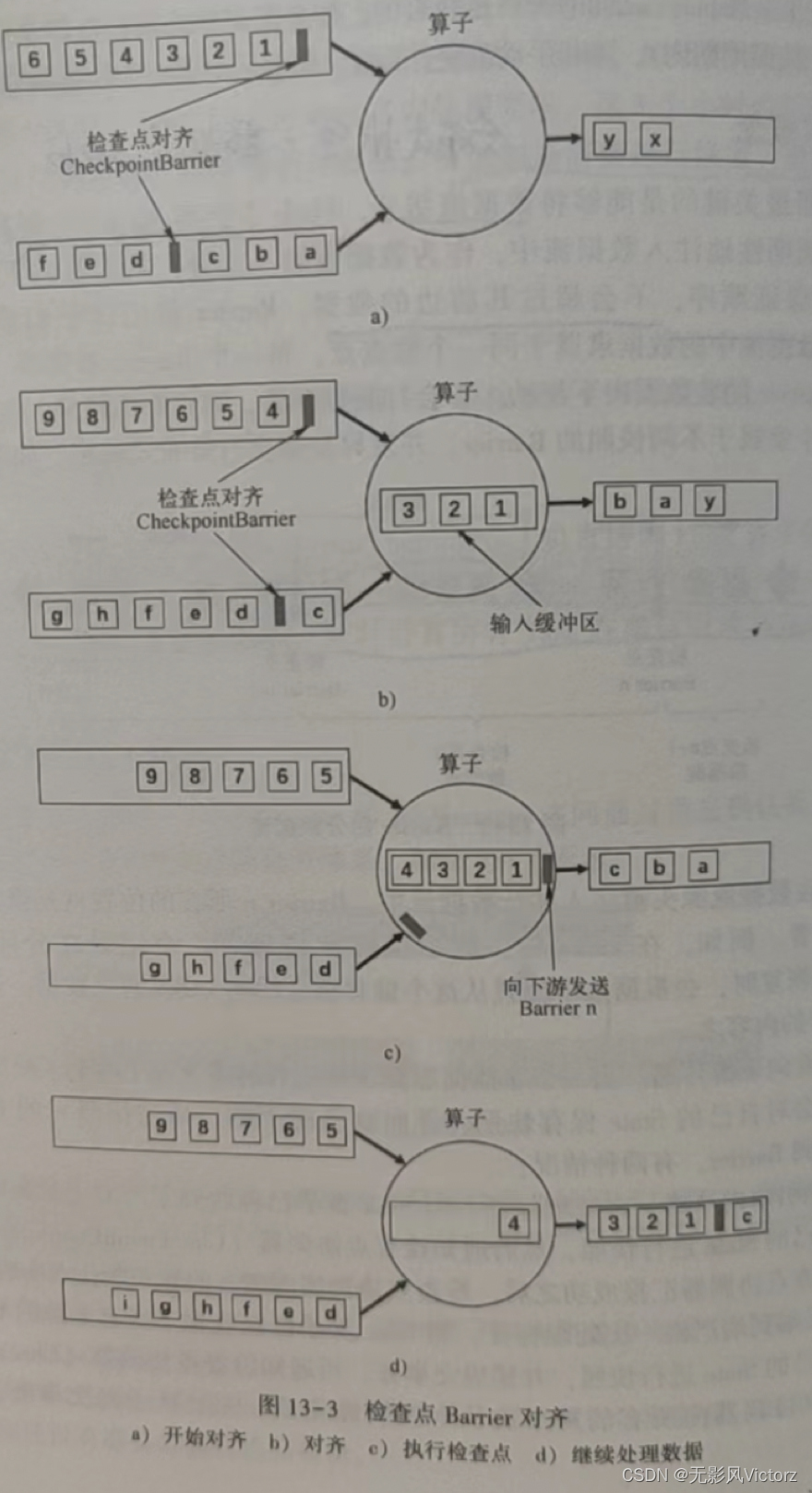
(1)在算子收到通道1的Barrier,输入通道2的Barrier尚未到达算子
(2)算子收到输入通道1的Barrier,会继续从通道1接收数据,但是并不处理,而是保存在输入缓存中,等待输入通道2的Barrier到达
(3)输入通道2的Barrier到达,算子开始对其State进行异步快照,并向Barrier向下游广播,并不等待快照执行完毕
(4)算子在做异步快照,首先处理缓存中积压的数据,然后再输入通道中获取数据
Checkpoint执行过程
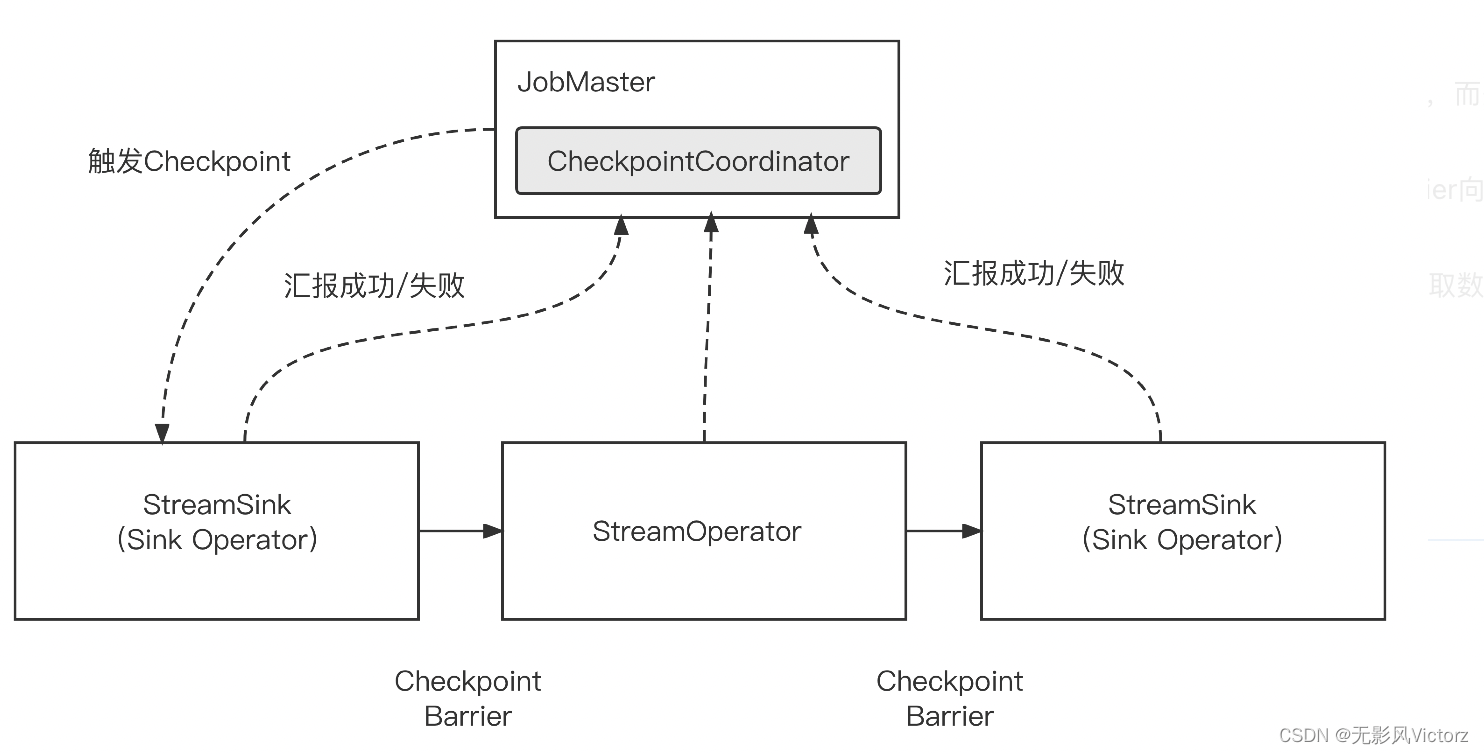
JobMaster的CheckpointCoordinator通过TaskManagerGateway在源头产生CheckPointBarrier事件,注入数据流中从而触发CK
(1)JobMaster触发检查点
CheckpointCoordinator会生成一个PendingCheckpoint,保存所有算子的ID
(2)TaskExecutor执行检查点
- Task层面检查点执行准备
- StreamTask执行检查点,检查是否是Running状态并向下游Task广播CheckpointBarrier
- 算子从StateBackend中深度复制State数据,并持久化道外部存储中,执行完向JobMaster发出CompletedCheckpoint消息
(3)JobMaster通过调度器SchedulerNG任务把信息交给CheckpointCoordinator.receiveAcknowledgeMessage,来响应算子检查点完成事件
CheckpointCoordinator的PendingCheckpoint会转换为CompletedCheckpoint,并向各个算子发送RPC请求,通知检查点已完成
两阶段提交
检查点在Flink内部是可控的,但是外部存储Flink无法控制,需要扩展Flink,使Sink与外部存储通过事务关联起来,在出现异常作业需要恢复的时候,能够通过事务回滚消除重复写入的脏数据
前提需要:
1)数据源支持断点读取
2)外部存储支持回滚机制或者满足幂等性(重复写入不会带来错误结果)
1. 预提交阶段:所有算子完成各自快照备份,把待写出的数据备份到可靠的存储中
Sink把要写入外部存储的数据以State的形式保存到状态后端存储(StateBackend)中,同时以事务的方式将数据写入外部存储
2. 提交阶段:将上一个阶段写入的数据备份,写入到真正的目的地
JobMaster会为作业中每个算子发起检查点已完成的回调逻辑
提交外部事务(如果失败,可能就会导致丢失)
Flink SQL:
提供TABLE API和SQL的原因:
- 使用DataStream/DataSet API进行开发比较繁琐
- TABLE API 和SQL是流批通用的,代码可以覆用
- DataStream和DataSet进行开发时,Flink只能进行非常有限的优化
Calcite:
动态数据管理框架
主要功能:
- SQL解析(将SQL解析成未经过交验的AST语法树)
- SQL校验(检验SQL规范、验证Schema、Field、Function是否存在,输入输出类型是否匹配)
- SQL查询优化
- SQL生成
- 数据连接与执行
流、动态表、查询的关系:

- 流转换为动态表 ------> 将DataStream注册为Table
- 在动态表上执行连续查询,生成新的动态表 ------> 在Table上应用SQL查询语句,结果为一个新的Table
- 生成的动态表将转换回流 ------> 将Table转换为DataStream
核心组件:
TableEnvironment:是Flink Table API和Flink SQL中使用的执行环境,向上对开发者提供Flink SQL使用的相关接口,向下连接Flink的SQL运行时
主要包括:BatchTableEnvironment 和 StreamTableEnvironment,分别拓展了DataSet(DataStream)相互转换能力
主要职责:
- 连接到外部数据源
- 注册Table和获取元数据信息
- 执行SQL语句
- 提供SQL执行的配置
Table API:
Table之间的相互转换关系

- GroupedTable:tab.groupBy("key").select("......")
- GroupWindowTable:使用时间窗口进行分组之后的Table,按照时间对数据进行切分,时间窗口必须是GroupBy中的第一项,且每个GroupBy只支持一个窗口
- WindowedGroupTable:一般和GroupWindowTable组合使用,在GroupWindowTable上再按照字段进行GroupBy运算后的Table
tab.window([groupWindow].as("w")).groupBy("w,key").select(....
- OverWindowTable:table.window(OverpartitionBy 'c orderBy' rowTime preceding 10.seconds as 'ow).select('c, 'b count over 'ow, 'e.sum over 'ow)
- AggregatedTable:对分组之后的Table执行AggregationFunction聚合函数的结果
- FlatAggregateTable:对分组之后的Table执行TableAggregationFunction的结果
元数据:包括库、表、视图、UDF、表字段定义
Catalog用来管理的核心抽象,定义了一系列操作元数据的方法
- 内存型GenericInMemoryCatalog
- HiveCatalog
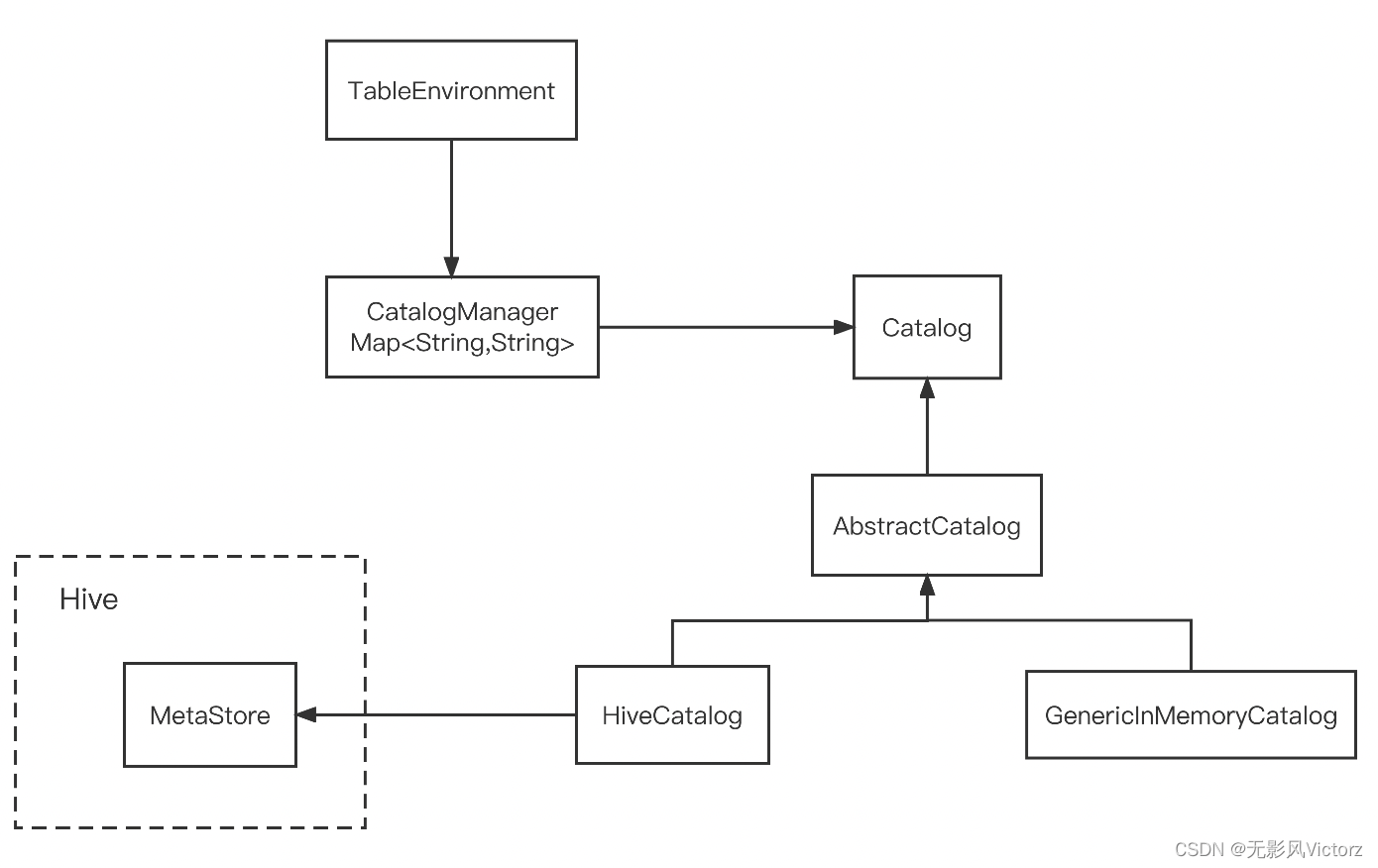
开发者在使用Catalog的时候,其入口是TableEnvironment,TableEnvironment中保存了Catalog集合,Catalog集合使用CatalogManager进行管理
数据访问:
针对DataStream API开发:Connector提供Function接口
针对Table API 和 SQL:Table Source和Table Sink体系
核心组件:
- TableSchema
- TableSource
- StreamTableSource
- BatchTableSource
- FilterableTableSource
- LimitableTableSource
- ProjectableTableSource等
- TableSink
- StreamTableSink
- BatchTableSink
- AppendStreamTableSink:支持追加,不支持更新
- RetractStreamTableSink:支持召回模式的TableSink
- UpsertStreamTableSink:有则更新,无则插入
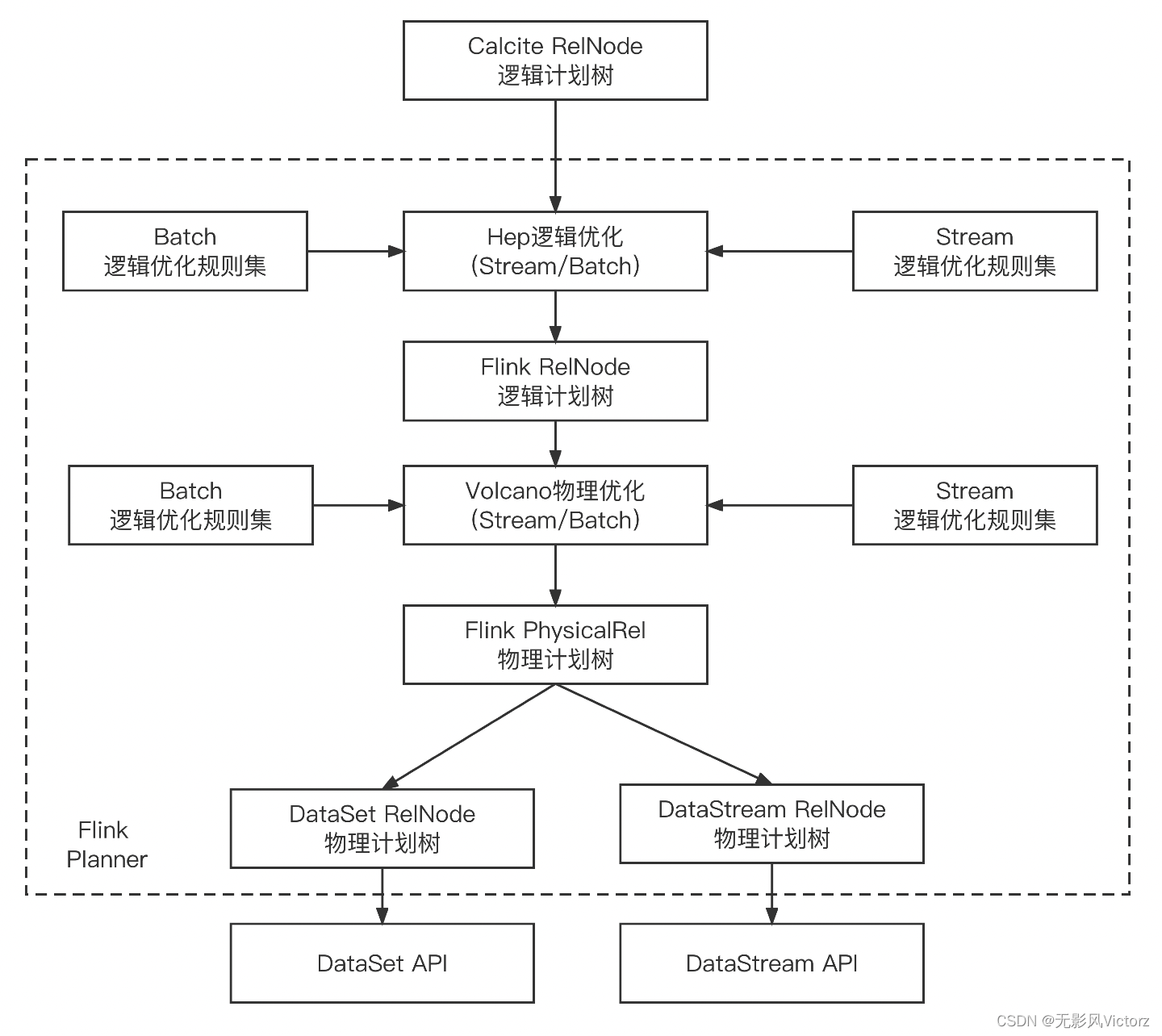
Planner关键抽象:
Flink引擎内部组件,是用户编写的代码和Flink运行时的中介,负责将用户代码转换到Flink可以识别的Transformation
主要有两种行为:
- SQL解析:将SQL字符串转化为Operation树
- 关系代数到Flink执行计划:将Operation树转换为Transformation
Expression:表达式(常量值、字段引用、函数调用)
ExpressionResolver:将Table API中原始Expression表达式解析成ResolvedExpression
解析规则包括:
- 展开*号,并解析函数中的列名对下场呢个输入列的引用
- 将Over聚合和Over Window合并到一个函数调用
- 解析所有未经解析的引用,这些引用可能对字段、表的引用或本地引用
- 替换函数调用,如BuiltInFunctionDefinitions#FLATTEN,BuiltInFunctionDefinitions#WITH_COLUMNS
- 执行所有函数调用的入参类型交验,如果有必要则进行类型转换
Operation:是SQL操作的抽象
物理执行计划节点:

Flink:FlinkRelNode、DataStreamRel、DataSetRel
Blink:ExecNode、StreamExecNode、BatchExecNode
Blink Planner和Flink Planner对比:
- Blink将批处理视作流的特殊情况,因此还不支持Table和DataSet之间的转换,并且批处理作业不使用DataSet执行框架和算子体系,而是基于流的框架
- Blink Planner不支持BatchTableSource,而是用BoundedStreamTableSource代替
- Blink Planner支持新的Catalog,不支持ExternalCatalog
- FilterableTableSource不兼容。Flink Planner会将PlannerExpressions下推到FilterableTableSource,而Blink Planner将下推Expressions
- 基于字符串的键值配置选项,仅仅作用于Blink Planner
- 两者的PlannerConfig不同
- Blink Planner会将多个接收器优化为一个DAG,而Flink Planner始终将每个接收器优化为一个新的DAG(且DAG独立)
- Blink Planner支持catalong统计信息,而Flink Planner不行
Blink与Calcite:
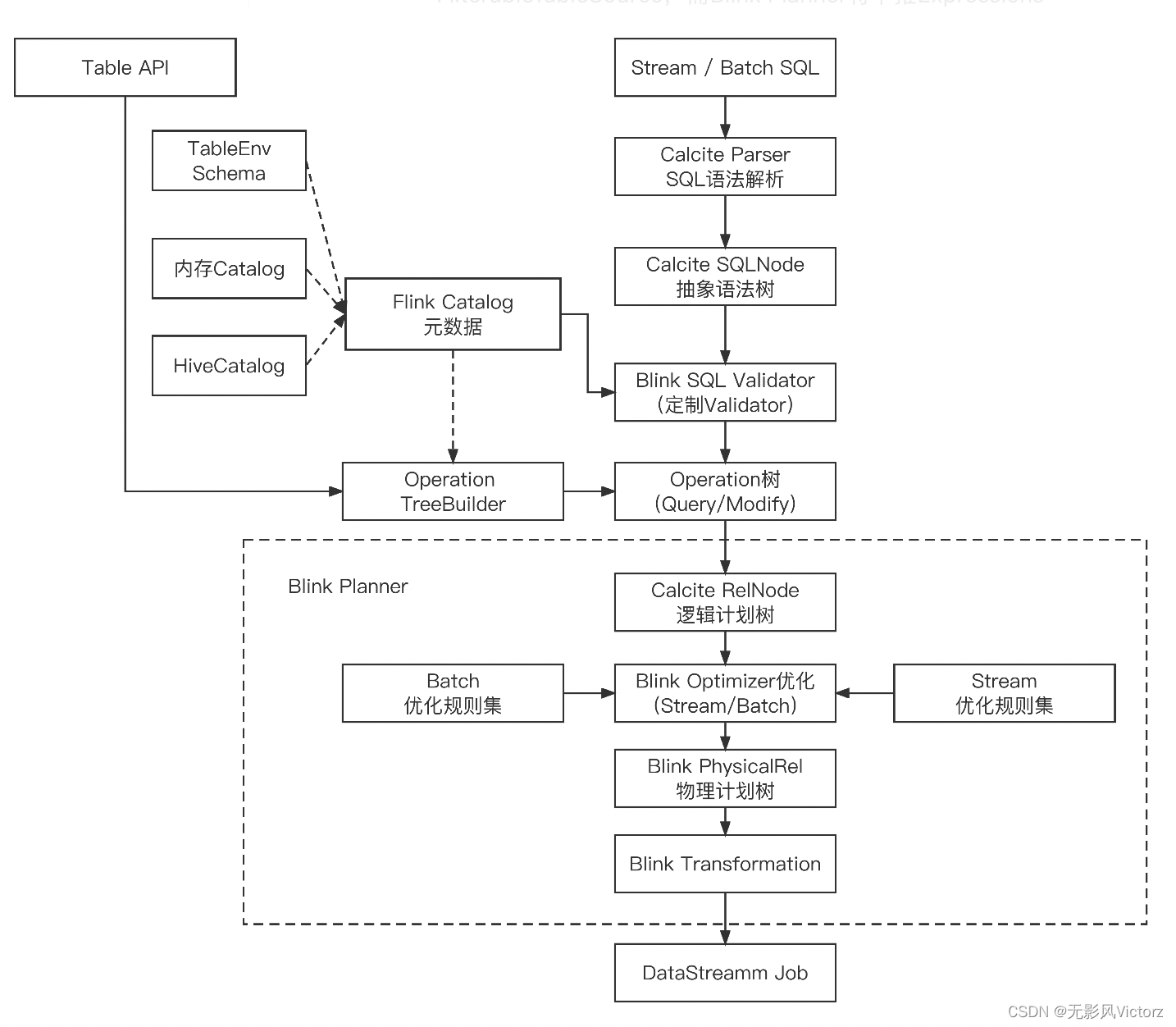
从SQL到Operation:
- 解析SQL字符串转换为QueryOperation
- SQL字符串解析为SqlNode
- 交验SqlNode
- 调用Calcite SQLToRelConverter将SqlNode转换为RelNode逻辑树
- RelNode转换为Operation
从Operation到Transformation:
- DQL转换:Query Operation -> RelNode -> FlinkPhysicalRel -> ExecNode -> Transformation
- DML/DQL转换:ModifyOperation -> RelNode -> FlinkPhysicalRel -> ExecNode -> Transformation
- 从Operation转换为Calcite RelNode逻辑计划树,使用Calcite提供的优化器
流-StreamPlanner(StreamCommonSubGraphBasedOptimizer)
批-BatchPlanner(BatchCommonSubGraphBasedOptimizer)
- 生成Flink物理计划
- 形成Transformation
Flink与Calcite:
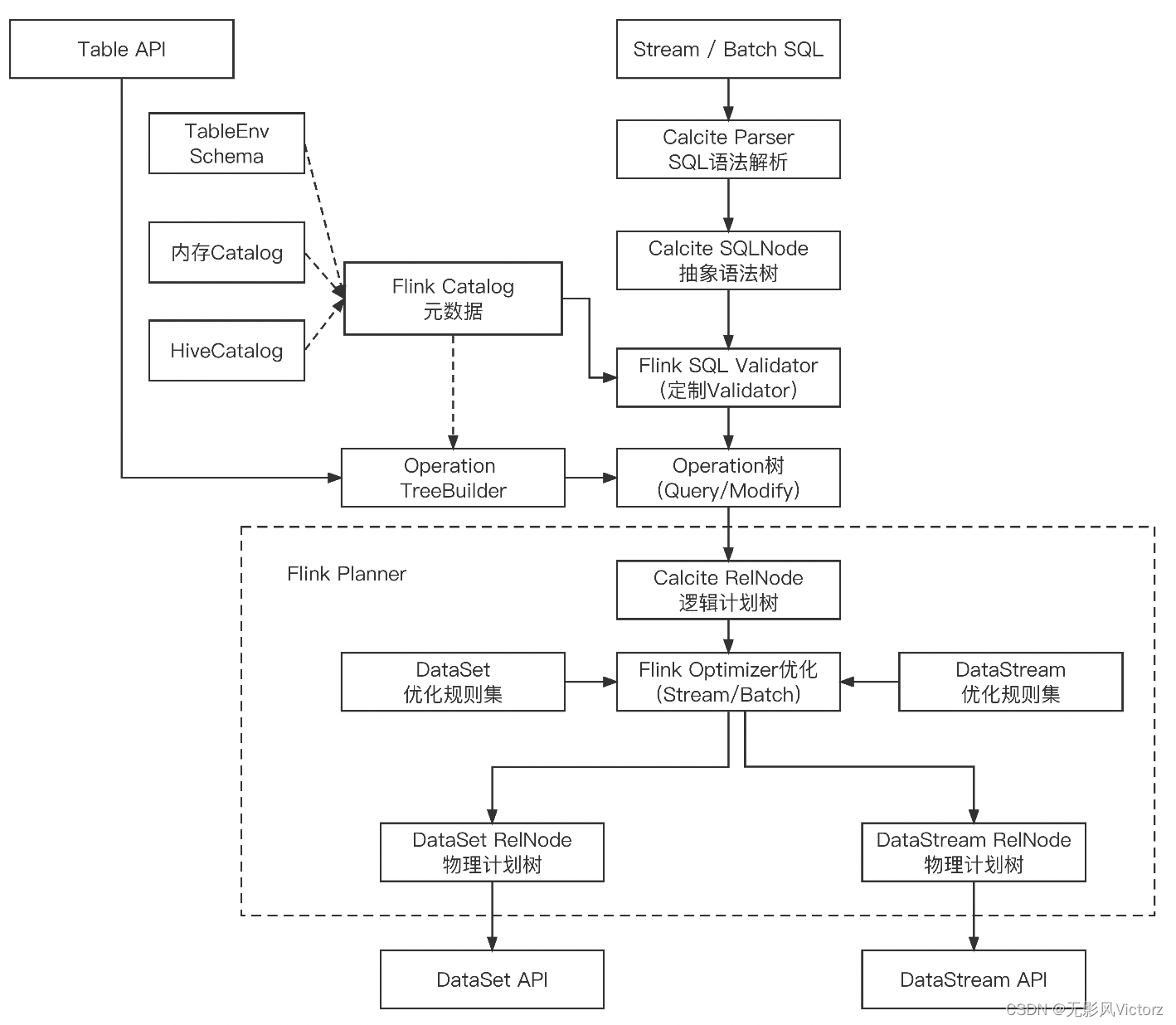
SQL优化
- RBO:根据事先定好的规则对SQL计划树进行转换(只要SQL相同,就会得到相同的SQL物理执行计划),对数据规模、数据倾斜等问题不敏感
- Calcite Hep优化器
- CBO:根据统计信息、代价模型计算每个执行计划的代价(数据量、CPU、内存、IO资源、网络)
- Volcano模型
- Cascades模型:两个模型基本一致,Cascades模型一边遍历SQL逻辑树,一边优化,从而进一步裁掉一些执行计划
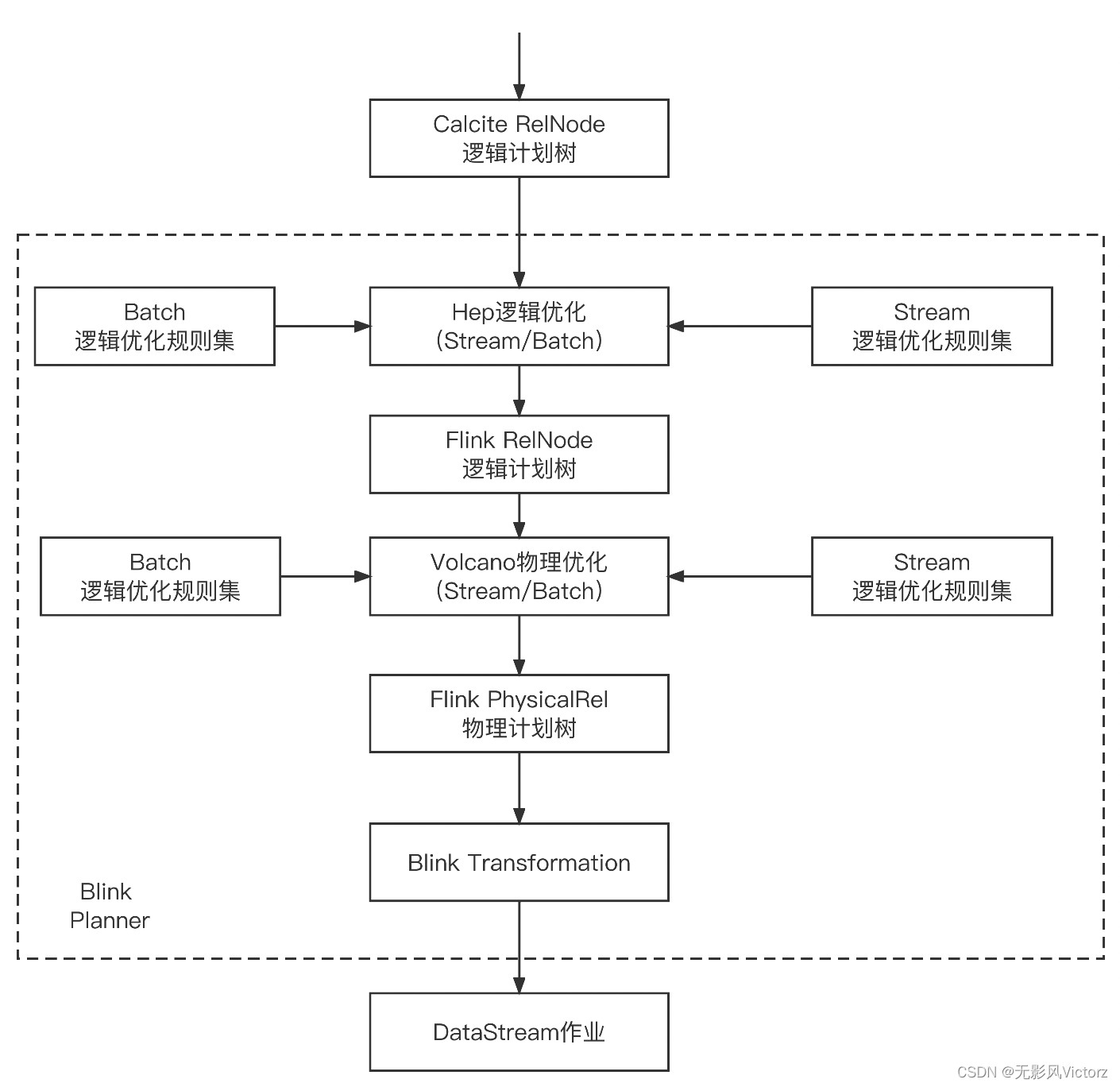
Blink优化:在不同优化阶段使用不同的Calcite Planner,而不是单纯使用某一个或托管给Calcite
逻辑优化:Calcite Hep规则优化器
物理优化:Calcite Hep规则优化器 + Volcano基于代价优化器
Blink的公共子图重用:
在Blinnk中支持一个作业中执行多条SQL语句,如果SQL语句的计划树子树节点摘要相同,就保留1个,即使不同的树子树也可以重用
这里涉及到公共子图切分、摘要计算
(类似Object#hashCode,判断两个RelNode的树逻辑等价)
Flink优化:
局部优化-代码生成:
在Blink Planner和Flink Planner模块中,都包含了SQL语句的Java 代码生成,直接生成合法的Java类,然后使用Janino将Java代码编译编译成字节码,直接在JVM中执行,提升SQL执行效率
依赖Codegen技术,优化具体Task执行效率
运维监控
Metrics
- Counter计数器:统计一个指标的总量
- Gauge指标瞬间值
- Histogram直方图:指标的最大值、最小值、中位数等统计信息
- Meter平均值:某个时间段内的平均值
方式:
- MetricReporter主动集成上报
- Rest API:实现类是WebMonitorEndpoint
添加指标的过程:
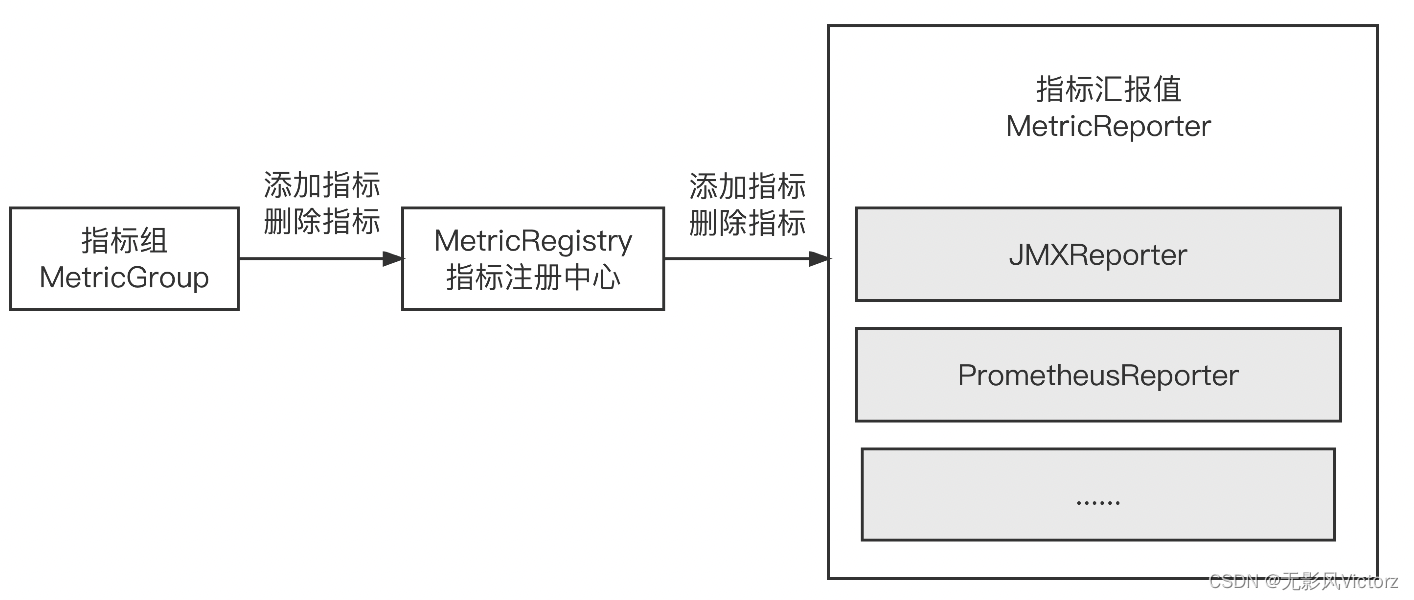
AbstractMetricGroup.addGroup
---> AbstractMetricGroup.addMetric
---> MetricRegistry.register
---> MetricReporter.notifyOfAddedMetric
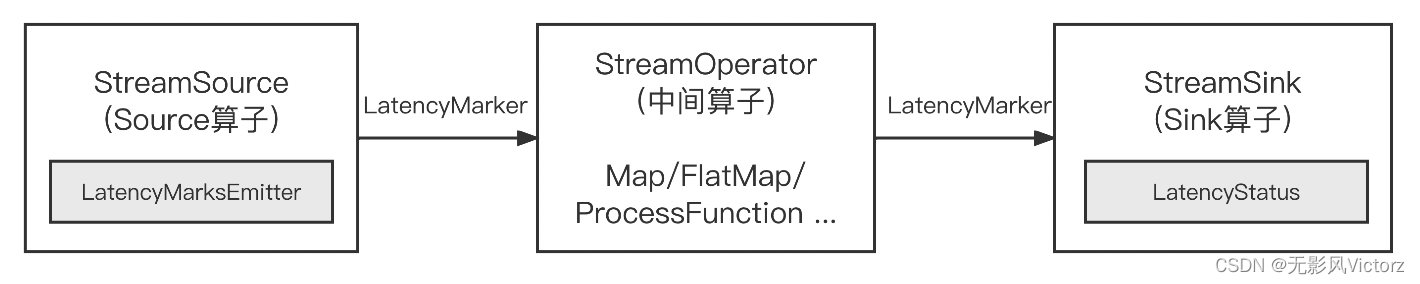
延迟追踪:
算子周期性发送LatencyMarker,延迟标记在传递过程中会绕过窗口,
RPC框架
Flink采用Akka作为自身RPC通信框架(Actor模式)
在Actor模式中,所有实体被认为是独立的Actor,Actor和其他Actor通过异步消息通信。每个Actor都是单一线程,不断地从其他邮箱中拉取信息
AKKA核心:ActorSystem与Actor
//1. 创建ActorSystem
ActorSystem system = ActorSystem.create("sys")
//2. 构建Actor,获取该Actor的引用,即ActorRef
ActorRef helloActor = system.actorOf(Props.create(HelloActor.class),"helloActor")
//3. 给helloActor发送消息
helloActor.tell("hello actor",ActorRef.noSender())
//4. 关闭ActorSystem
system.terminate()Akka通信方式:
- tell方式:仅仅使用异步方式给某个Actor发送消息,无需等待Actor的响应结果
- ask方式:需要从Actor获取响应结果
RPC通信组件:
- 远程调用网关:RpcGateWay
- 提供了RPC服务组件的生命周期管理:RpcEndpoint
- RpcService:RpcEndpoint的成员变量
- 启动和停止rpcServer和连接rpcEndpoint
- 根据指定的连接地址,连接到rpcServer会返回一个rpcGatewary
- RpcServer:是RpcEndpoint的成员变量,负责接收和响应远端的RPC消息请求
















 1231
1231











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









