







之前特斯拉声称将AI大模型引入自动驾驶,采用端到端技术,用3000行代码,替代了原来的30多万行C++代码。然而,FSD的硬件算力要求却在不断增加。按照马斯克的说法,AI5(HW5)比HW4能耗提升5倍,算力提升10倍。这样计算,AI5整个平台算力可能达到3000-5000TOPS。
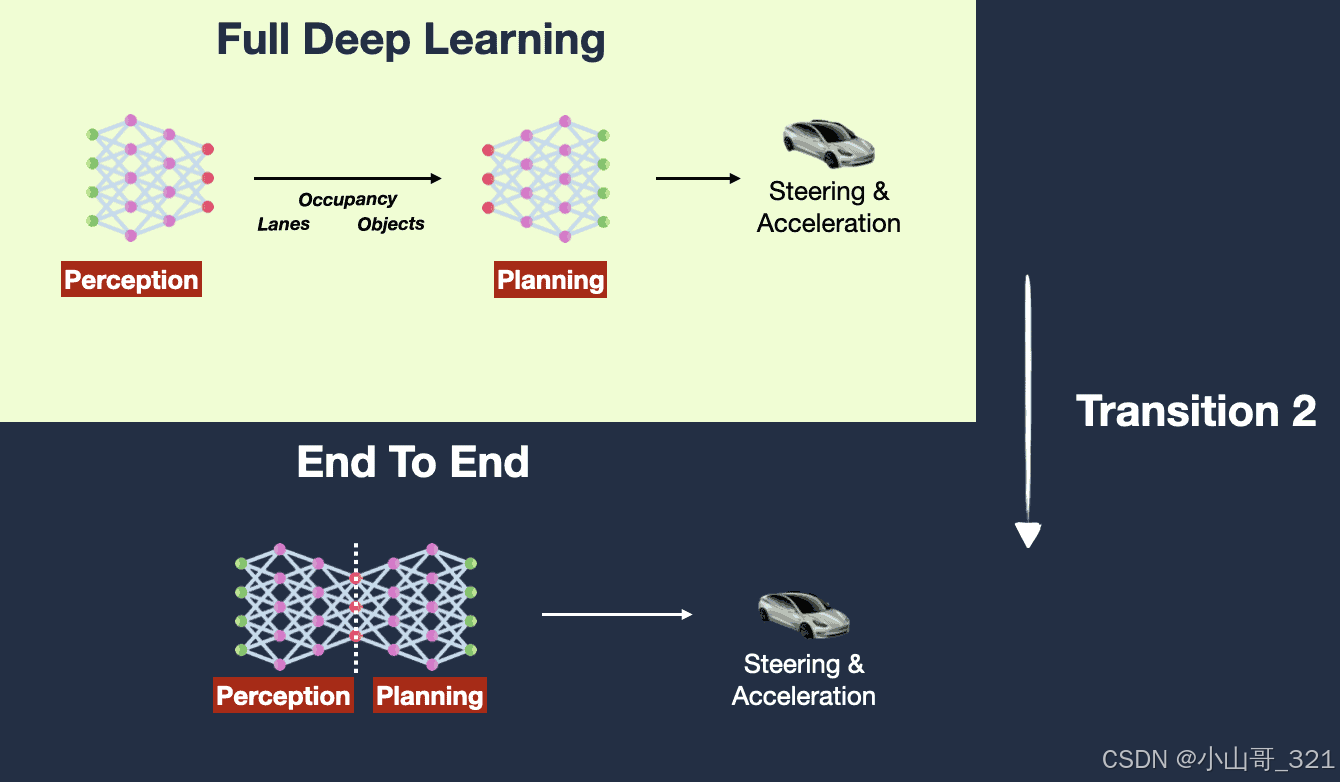
那么问题来了,端到端智能驾驶的代码量变少,为何算力要求却更高?
分析下来,这主要归因于技术架构的变化和深度学习算法的应用。以下几个因素可以解释这种现象:
1. 从规则驱动到深度学习驱动
传统的自动驾驶系统通常是基于规则的架构,需要手工编写大量的规则和逻辑来应对各种驾驶场景,这导致代码量非常庞大。然而,端到端智能驾驶更多依赖于深度学习模型,它将驾驶任务看作一个整体,利用大量数据训练神经网络,从感知到决策再到控制都由模型来完成。这减少了手工编写规则和逻辑的需求,从而显著降低了代码量。
2. 模型复杂度增加
尽管代码量减少,但深度学习模型的复杂度大幅增加。现代的端到端自动驾驶系统依赖于非常复杂的大规模神经网络模型,如Transformer或大型卷积神经网络(CNNs)。这些模型的训练和推理需要处理海量的数据,尤其是涉及图像、激光雷达等高维感知数据,模型参数量巨大,导致对算力的需求急剧增加。
3. 模型推理过程的实时性要求
在实际的驾驶场景中,端到端智能驾驶系统必须实时作出决策。这意味着模型需要在极短时间内处理大量复杂的感知信息,如摄像头图像、雷达数据、车速和位置信息等。即使代码量较小,实时推理的要求使得对算力的需求极高,特别是在处理多模态输入和长时序依赖的情况下。
4. 优化和压缩的复杂性
虽然代码量减少,但为了实现高效的推理,开发者可能需要花费更多精力在模型优化、量化、剪枝等技术上,以保证模型在嵌入式系统或边缘设备上的高效运行。这种优化工作通常需要高度专业的工具和算法,虽然它在代码中可能看起来并不复杂,但背后涉及大量的计算和复杂的数学方法。
5. 数据处理和训练需求增加
其实,除了端到端的智能驾驶除了对嵌入式系统的算力要求增加,对云端算力要求也很高。 端到端智能驾驶依赖于大规模数据集,训练过程非常耗费计算资源。尤其是为了让模型具备足够的泛化能力,训练过程需要在大量的模拟场景和真实世界的数据上进行,可能涉及数亿、数十亿甚至更大的样本量。这种大规模的计算需求推动了对高性能计算硬件(如GPU、TPU)的需求。
总结
端到端智能驾驶的代码量减少是因为规则逻辑被深度学习模型所替代,模型负责处理从感知到决策的完整流程。然而,由于深度学习模型的复杂性、海量数据的需求以及实时推理的要求,系统对算力的需求反而大幅增加。这种技术架构的转变反映了从手工规则到数据驱动的技术进步,但也带来了新的挑战,特别是在硬件和计算资源方面。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











