







基本原理
k近邻(k-Nearest Neighbor,KNN)是一种有监督学习方法,其工作机制很简单:在给定测试样本时,基于某种距离(欧氏距离)度量找出训练样本数据集中与其距离最近的K个样本,然后基于这个k个样本做预测,通常采用的是“投票法”,也就是说属于哪个类别的样本数多,就预测为该样本。
常用的距离计算公式
- Lp距离定义:
- 欧氏距离:当p=2时,就是我们常见的欧式距离
- 曼哈顿距离:当p=1时称之为曼哈顿距离
- 马氏距离:马氏距离标识的是数据的协方差距离,是一种有效的计算两个未知样本集的相似度的方法,在计算的过程中考虑到features之间的特征,而且跟尺度无关(scale-invariant)。求马氏距离的前提是要计算出样本集的协方差矩阵,然后利用公式:
,其中Σ表示样本矩阵的协方差,μ表示的是样本的均值。马氏距离要求样本是必须大于features的个数即维数
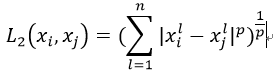
举例
一个包含3类且类别标签为1,2,3的样本集和待测试样本item-1,计算item-1与样本集中的没想的距离,并取前k个距离最小的记录,比如k=10,统计这五条集中出现最多的类别,并把该类别作为item-1的预测类别。
- item-1。
- 得到的k个最小的距离项分别为:a-1,b-2,c-3,d-2,e-1,f-3,g-1,h-1,i-2,j-1.其中数字表示类别,字母表示记录的feature value。
- 统计K=10个项中个类别的个数,类别1–5个,类别2–3个,类别3–2个。
- 取上述结果最大的类别1作为item-1的预测类别,所以item-1 的类别为1.
code
def loadfile(filename):
rawData = []
file = open(filename,'rb')
reader = csv.reader(file)
for line in reader:
rawData.append(line)
rawData.pop(0)
rawData = array(rawData).astype(int32)
return rawData
def knnClassifier(unClassifiedItem,trainData,trainLabels,k):
dataSetSize = trainData.shape[0]
diffMat = tile(unClassifiedItem, (dataSetSize,1)) - trainData
sqDiffMat = (diffMat)**2
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances**0.5
sortedDistIndicies = distances.argsort()
classCount={}
for i in range(k):
voteIlabel = trainLabels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
def digitClassify(testData,testDataLable,trainData,trainLable,k):
m = testData.shape[0]
result = [['ImageId','label']]
errorCount=0
for i in range(m):
classifyResult =knnClassifier(testData[i],trainData,trainLable,k)
result.append([i,classifyResult])
if(classifyResult !=testDataLable[i,1]):
errorCount+=1
return errorCount/float(m)














 441
441

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









