







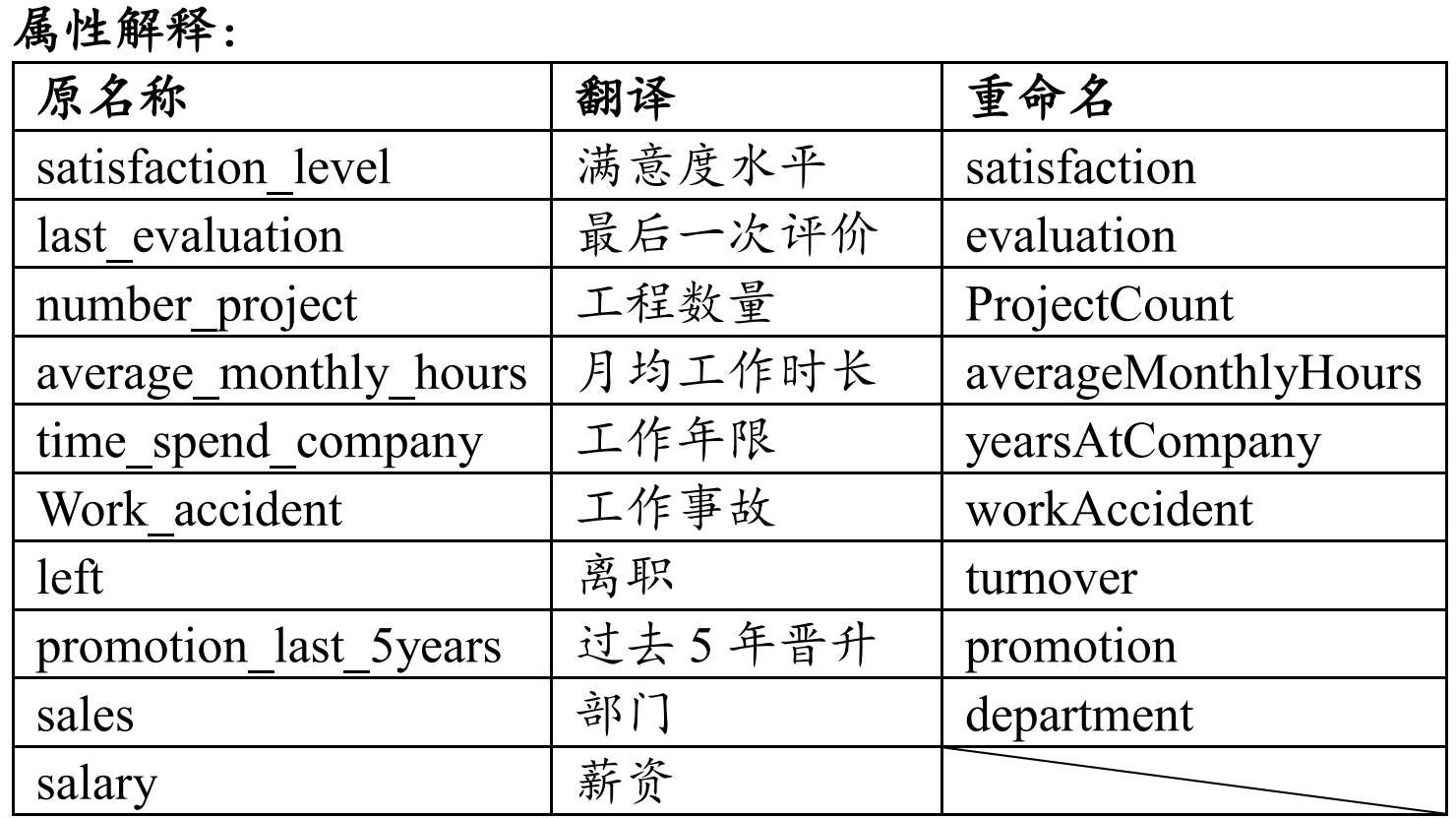
数据集:
路径:input/Ch3-Turnover.csv
描述:人力资源数据集,记录员工信息。
目的:用于探索员工离职率与哪些因素有较强的关联。
规格:(14999, 10)
思路:
1.查看数据
(1)读入数据 → 查看缺失值 → 属性重命名、移位 → 文字属性值编码
2.查看相关性
(1)相关性矩阵 → turnover与各种属性之间的关系图 → 发现结论
3.评估属性影响力
(1)分析员工集群 → 聚类 → 分析影响力
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.cluster import KMeans
from sklearn import tree
from sklearn.model_selection import train_test_split
""" -------- 1-1.数据读入 -------- """
df = pd.read_csv("input/Ch3-Turnover.csv", index_col=None)
""" -------- 1-2.数据查看 -------- """
# 设置全部显示
pd.set_option('display.max_columns', None) # 显示所有列
pd.set_option('display.expand_frame_repr', False) # 不允许水平拓展
pd.set_option('display.max_rows', None) # 显示所有行
# 查看原始数据
print(df.head())
print(df.tail(3))
# 查看非数据类型的列所含的值,便于后续编码
print(df['sales'].value_counts())
print(df['salary'].value_counts())
""" -------- 1-3.查看是否有缺失值 -------- """
print(df.isnull().any()) # 输出均为False,没有缺失值
""" -------- 1-4.重命名 -------- """
df = df.rename(columns={
'satisfaction_level': 'satisfaction',
'last_evaluation': 'evaluation',
'number_project': 'ProjectCount',
'average_montly_hours': 'averageMonthlyHours', # 呃,原表格数据就是montly打错了,查半天bug玉玉了
'time_spend_company': 'yearsAtCompany',
'Work_accident': 'workAccident',
'left': 'turnover',
'promotion_last_5years': 'promotion',
'sales': 'department'
}) # 重命名以提高可读性
print(df.columns) # 表首行
""" -------- 1-5.变量移动位置 -------- """
front = df['turnover'] # 创建一个名为front的新Series
df.drop(labels=['turnover'], axis=1, inplace=True) # inplace=True表示在原始DataFrame上进行修改
df.insert(0, 'turnover', front) # 插入索引=0的列(第一列),原先的列自动后退一列
print(df.head())
""" -------- 1-6.数据描述 -------- """
print(df.shape) # 规格(14999, 10)
print(df.dtypes) # 各列的数据类型,返回值是Series对象。
print(df.columns) # 表首行
print(df.describe().T) # 将describe转置,每一行对应一个属性的各个描述(count,mean,std,min,25%,50%,75%,max)
print(df['turnover'].value_counts()) # 查看离职人数(0:未离职,1:离职)
print(df['turnover'].value_counts() / len(df)) # 查看离职百分比(0:未离职,1:离职)
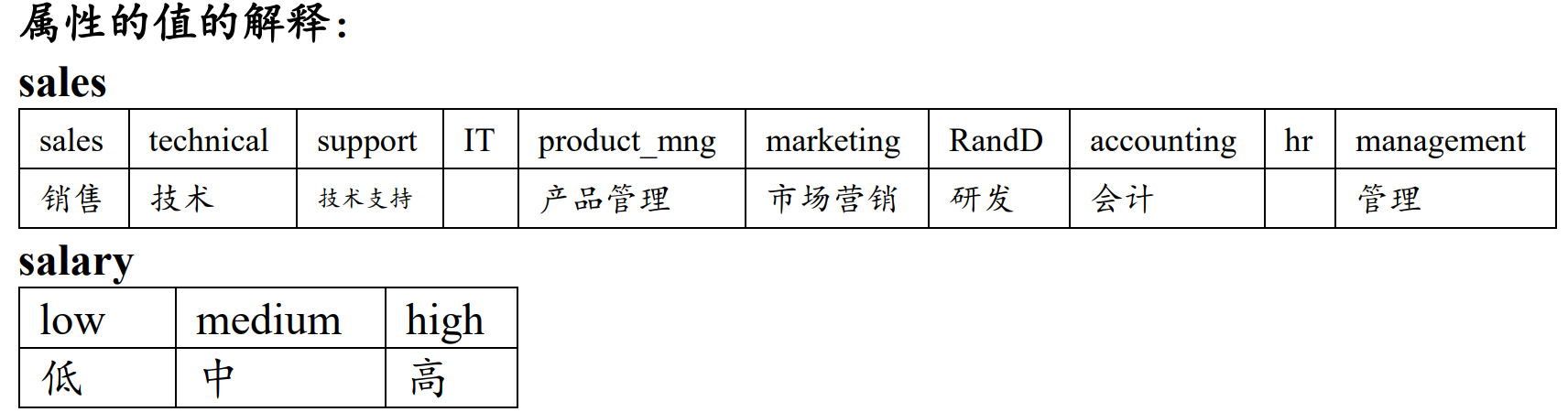
""" -------- 1-7.对文字型数据编码 -------- """
# 定义编码映射字典
department_mapping = {
'sales': 1, 'technical': 2, 'support': 3, 'IT': 4,
'product_mng': 5, 'marketing': 6, 'RandD': 7,
'accounting': 8, 'hr': 9, 'management': 10
}
salary_mapping = {'low': 1, 'medium': 2, 'high': 3}
# 使用replace函数进行编码
df['department'] = df['department'].replace(department_mapping)
df['salary'] = df['salary'].replace(salary_mapping)
# 查看编码后的DataFrame
print(df.head())
""" -------- 1-7.初步分析离职人员的情况 -------- """
turnover_summary = df.groupby('turnover')
print(turnover_summary.mean()) # 从输出来看。初步分析turnover可能与satisfaction和salary关系很大。
""" -------- 2-1.查看相关性矩阵 -------- """
corr = df.corr()
print(corr)
# np.fill_diagonal(corr.values, np.nan) # 这段代码用于屏蔽与自身的相关系数,让图片更加清晰但是不美观
sns.heatmap(corr, annot=True, cmap='coolwarm', fmt=".2f", xticklabels=corr.columns.values, yticklabels=corr.columns.values)
plt.show()
# 与turnover相关系数的绝对值大于0.1的有satisfaction-0.39,yearsAtCompany0.14,workAccident-0.15,salary-0.16
"""2-1结论1:不满意公司的大都倾向于离开公司"""
# 额外注意到evaluation,ProjectCount,averageMonthlyHours之间相关性较强(均>0.3)
"""2-1结论2:说明花更多时间和做更多项目的员工更容易得到高度评价"""
""" -------- 2-2.绘制分布图 -------- """
"""2-2目标1:用于直观检验2-1中的「evaluation,ProjectCount,averageMonthlyHours之间相关性较强」这一结论"""
f, axes = plt.subplots(ncols=3, figsize=(12, 4))
# displot是一个图形级别的函数,不接受ax参数,而是用于创建一个图形对象。如果想要绘制直方图并将它们放在指定的子图中,应使用histplot
sns.histplot(df['satisfaction'], kde=False, color='g', ax=axes[0]).set_title("Employee-Satisfaction")
axes[0].set_ylabel('Employee Count')
sns.histplot(df['evaluation'], kde=False, color='r', ax=axes[1]).set_title("Employee-Evaluation")
axes[1].set_ylabel('Employee Count')
sns.histplot(df['averageMonthlyHours'], kde=False, color='b', ax=axes[2]).set_title("Employee-averageMonthlyHours")
axes[2].set_ylabel('Employee Count')
plt.show()
"""2-2结论1:发现三个图像都呈现双峰,尤其是Evaluation与averageMonthlyHours的分布比较相似"""
""" -------- 2-3.绘制关系图并查看具体关系(探索离职率与其他属性的关系) -------- """
""" 2-3-1.离职率与薪水 """
f, ax = plt.subplots(figsize=(12, 6))
sns.countplot(y='salary', hue='turnover', data=df).set_title('Salary-Turnover')
plt.show()
"""2-3-1结论1&目标1:发现高薪的大都没离职,低薪的更容易离职。以下验证离职率"""
LowSalary_df = df[df['salary'] == 1] # 筛选出薪资低的员工
MediumSalary_df = df[df['salary'] == 2]
HighSalar_df = df[df['salary'] == 3]
turnover_LowSalary = LowSalary_df[LowSalary_df['turnover'] == 1] # 筛选出低薪离职的员工
turnoverRate_LowSalary = len(turnover_LowSalary) / len(LowSalary_df) # 计算低薪离职率
turnover_MediumSalary = MediumSalary_df[MediumSalary_df['turnover'] == 1]
turnoverRate_MediumSalary = len(turnover_MediumSalary) / len(MediumSalary_df)
turnover_HighSalary = HighSalar_df[HighSalar_df['turnover'] == 1]
turnoverRate_HighSalary = len(turnover_HighSalary) / len(HighSalar_df)
print(f"低薪员工的离职率为: {turnoverRate_LowSalary:.2%}") # 29.69%
print(f"中薪员工的离职率为: {turnoverRate_MediumSalary:.2%}") # 20.43%
print(f"高薪员工的离职率为: {turnoverRate_HighSalary:.2%}") # 6.63%
# 上面的方法可以替换为groupby,下面用两种方法使用groupby给出离职率
# 1.得到salary与turnover对应的二维矩阵
turnover_rates = df.groupby('salary')['turnover'].value_counts(normalize=True) * 100
print(turnover_rates)
print(f"低薪员工的离职率为: {turnover_rates[1][1]:.2f}%")
print(f"中薪员工的离职率为: {turnover_rates[2][1]:.2f}%")
print(f"高薪员工的离职率为: {turnover_rates[3][1]:.2f}%")
# 2.得到salary对应turnover=1的比率。因为turnover=0,1,所以计算平均值mean就相当于计算了turnover=1的比率,乘100是为了“变成”%
turnover_rates_groupby = df.groupby('salary')['turnover'].mean() * 100
print(turnover_rates_groupby)
""" 2-3-2.离职率与部门 """
color_types = ['#66CCFF', '#FEE4D0', '#39C5BB', '#EE0000', '#AA6680', '#B2D8E8', '#00FFCC', '#FFC0CB', '#FAF9DE', '#FDE6E0']
sns.countplot(x='department', data=df, palette=color_types).set_title('Employee-Department') # 分布图
# plt.xticks(rotation=-45) # x坐标顺时针旋转45°
plt.show()
f, ax = plt.subplots(figsize=(15, 5))
sns.countplot(y="department", hue='turnover', data=df).set_title('Employee Department Turnover Distribution') # 关系图
plt.show()
"""2-3-2结论1:sales,technical,support department的离职率很高,这里不再一一给出离职率"""
""" 2-3-3.离职率与评价 """
fig = plt.figure(figsize=(15, 4), )
ax = sns.kdeplot(df.loc[(df['turnover'] == 0), 'evaluation'], color='b', fill=True, label='no turnover')
ax = sns.kdeplot(df.loc[(df['turnover'] == 1), 'evaluation'], color='r', fill=True, label='turnover')
ax.set(xlabel='Employee Evaluation', ylabel='Frequency')
plt.title('Employee Evaluation Distribution - Turnover V.S. No Turnover')
plt.show()
"""2-3-3结论1:离职率和评价间存在双峰分布。low和high表现的员工更倾向于离开公司。对于员工来讲具有 0.6-0.8 的评价是一个舒适区。"""
sns.boxplot(x="ProjectCount", y="evaluation", hue="turnover", data=df)
plt.show()
"""2-3-3发现1:完成更多项目的离职员工的评价有所提高。但是,未离职员工随着项目数量有所增加其评价却没有变化(稳定在0.7)。
并且当项目数量有所增加时(>3)离职员工的平均评价显著高于未离职员工。
离职的人大都为2个项目但评价是坏 或者 大于3个项目但评价是好"""
""" 2-3-4.离职率与项目数量 """
ax = sns.barplot(x="ProjectCount", y="ProjectCount", hue="turnover", data=df, estimator=lambda x: len(x) / len(df) * 100)
ax.set(ylabel="Percent")
plt.show()
"""2-3-4结论1:有2,6和7个项目的员工中一半多都离开了公司。有7个项目的员工全都离开了公司。随着项目数量的增加,员工的离职率上升。
大多数没有离开公司的员工有3,4,5个项目。"""
"""下面查看项目数和工作时间有什么关系"""
sns.boxplot(x="ProjectCount", y="averageMonthlyHours", hue="turnover", data=df)
plt.show()
""""2-3-4结论2:没有离职的员工的工作时间基本不因为项目数量的增加而增加,但离职的员工的工作时间显著因为项目数量的增加而增加。"""
""" 2-3-5.离职率与工作年限 """
ax = sns.barplot(x="yearsAtCompany", y="yearsAtCompany", hue="turnover", data=df, estimator=lambda x: len(x) / len(df) * 100)
ax.set(ylabel="Percent")
plt.show()
""""2-3-5结论1:工作了4、5年的员工有一半以上离开了公司,或许他们本应该受到重视"""
""" -------- 3-1.整体分析离职的群体 -------- """
sns.lmplot(x='satisfaction', y='evaluation', data=df, fit_reg=False, hue='turnover') # 不显示回归线
plt.show()
"""
3-1结论:
离开公司的员工有 3 个不同的集群:
Cluster 1 (勤奋工作并且不开心的员工): 满意度低于0.2,评价高于0.75。这可能是一个很好的迹象,表明离开公司的员工都是好员工,但对自己的工作感觉很糟糕。
Question1: 当你被高度评价的时候,是什么原因让员工感觉如此糟糕?会不会太辛苦了?这个集群是否意味着“过度工作”的员工?
Answer 1:虽然高评价员工的离职可能引起担忧,但它也可能是一个机会,让公司审查他们的员工满意度和工作条件,以改进工作环境,以满足员工的需求,从而减少离职率。
这是为什么说Cluster 1可能是一个很好的迹象,因为它可以帮助公司识别和解决潜在的问题,以提高员工满意度和留住高绩效的员工。
Cluster 2 (评价低并且不开心的员工): 满意度在0.35~0.45之间,评价在0.58以下。这可以被看作是在工作中受到了不好的评价和感觉不好的员工。
Question2: 这个集群是否意味着“表现不佳”的员工?
Answer 2:他们在工作中遇到了问题,无法满足公司的期望。或者说他们的潜力可能没有办法在这样的公司里发挥出来。
Cluster 3 (勤奋工作并且开心的员工): 满意度在0.7~1.0之间,评价大于0.8。这可能意味着这个集群中的员工是“理想的”。他们热爱自己的工作,并因工作表现而受到高度评价。
Question3: 这个集群是否意味着员工离开是因为他们找到了另一个工作机会?
Answer 3:或许需要用更有竞争力的薪酬、福利、职业发展机会、管理、指导、工作负荷来挽留这些“理想员工”。
"""
""" -------- 3-2.聚类 -------- """
"""聚类:Cluster 1 (Blue): 勤奋工作并且不开心的员工,
Cluster 2 (Red): 评价低并且不开心的员工,
Cluster 3 (Green): 勤奋工作并且开心的员工。"""
# Graph and create 3 clusters of Employee Turnover
kmeans = KMeans(n_clusters=3, random_state=2, n_init=10) # 默认情况下,n_init是10,但在将来的版本中将更改为auto。
kmeans.fit(df[df.turnover == 1][["satisfaction", "evaluation"]])
kmeans_colors = ['green' if c == 0 else 'blue' if c == 2 else 'red' for c in kmeans.labels_]
fig = plt.figure(figsize=(10, 6))
plt.scatter(x="satisfaction", y="evaluation", data=df[df.turnover == 1], alpha=0.25, color=kmeans_colors)
plt.xlabel("Satisfaction")
plt.ylabel("Evaluation")
plt.scatter(x=kmeans.cluster_centers_[:, 0], y=kmeans.cluster_centers_[:, 1], color="black", marker="X", s=100)
plt.title("Clusters of Employee Turnover")
plt.show()
""" -------- 3-3.特征的重要性 -------- """
plt.style.use('fivethirtyeight')
plt.rcParams['figure.figsize'] = (12, 6)
# Convert these variables into categorical variables
df["department"] = df["department"].astype('category').cat.codes
df["salary"] = df["salary"].astype('category').cat.codes
# Create train and test splits
target_name = 'turnover'
X = df.drop('turnover', axis=1)
y = df[target_name]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.15, random_state=123, stratify=y)
dtree = tree.DecisionTreeClassifier(
# max_depth=3,
class_weight="balanced",
min_weight_fraction_leaf=0.01
)
dtree = dtree.fit(X_train, y_train)
# plot the importances
importances = dtree.feature_importances_
feat_names = df.drop(['turnover'], axis=1).columns
indices = np.argsort(importances)[::-1]
plt.figure(figsize=(12, 6))
plt.title("Feature importances by DecisionTreeClassifier")
plt.bar(range(len(indices)), importances[indices], color='lightblue', align="center")
plt.step(range(len(indices)), np.cumsum(importances[indices]), where='mid', label='Cumulative')
plt.xticks(range(len(indices)), feat_names[indices], rotation='vertical', fontsize=14)
plt.xlim([-1, len(indices)])
plt.xticks(rotation=45) # x坐标逆时针旋转45°
plt.show()
"""
3-3结论:
通过使用决策树分类器,它可以对用于预测的特征进行排序。前三个特征是员工满意度、工作年限和评价。
这有助于创建我们的回归模型,因为当我们使用较少的特征时,理解模型中的内容会更容易理解。
"""
代码输出 与 探索思路
PART 1
turnover
0 11428 0.761917
1 3571 0.238083

猜测turnover可能与satisfaction和salary关系很大。
PART 2
2-1 相关性矩阵
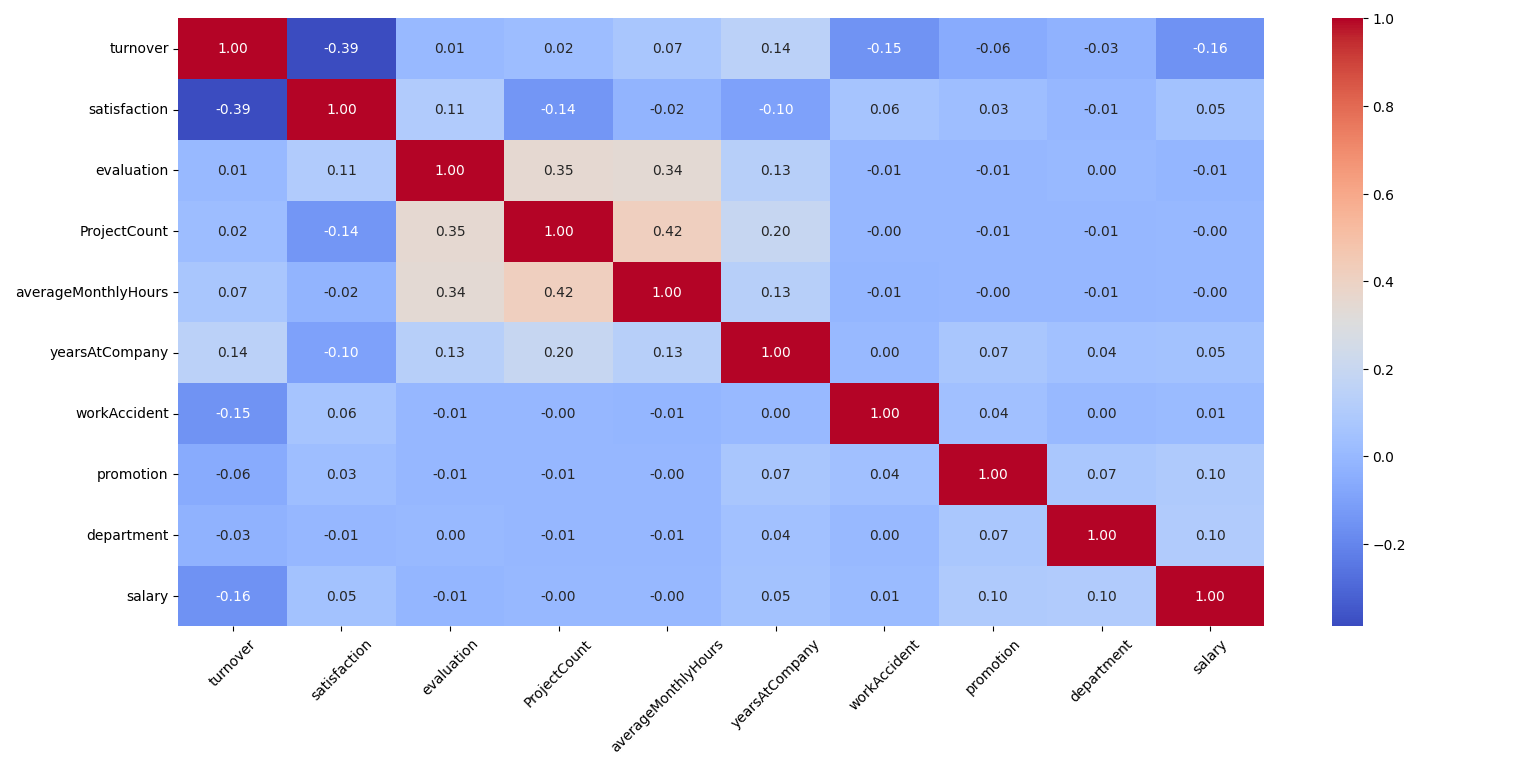
不满意公司的大都倾向于离开公司。
2-2 满意度、评价、工作时长的关系
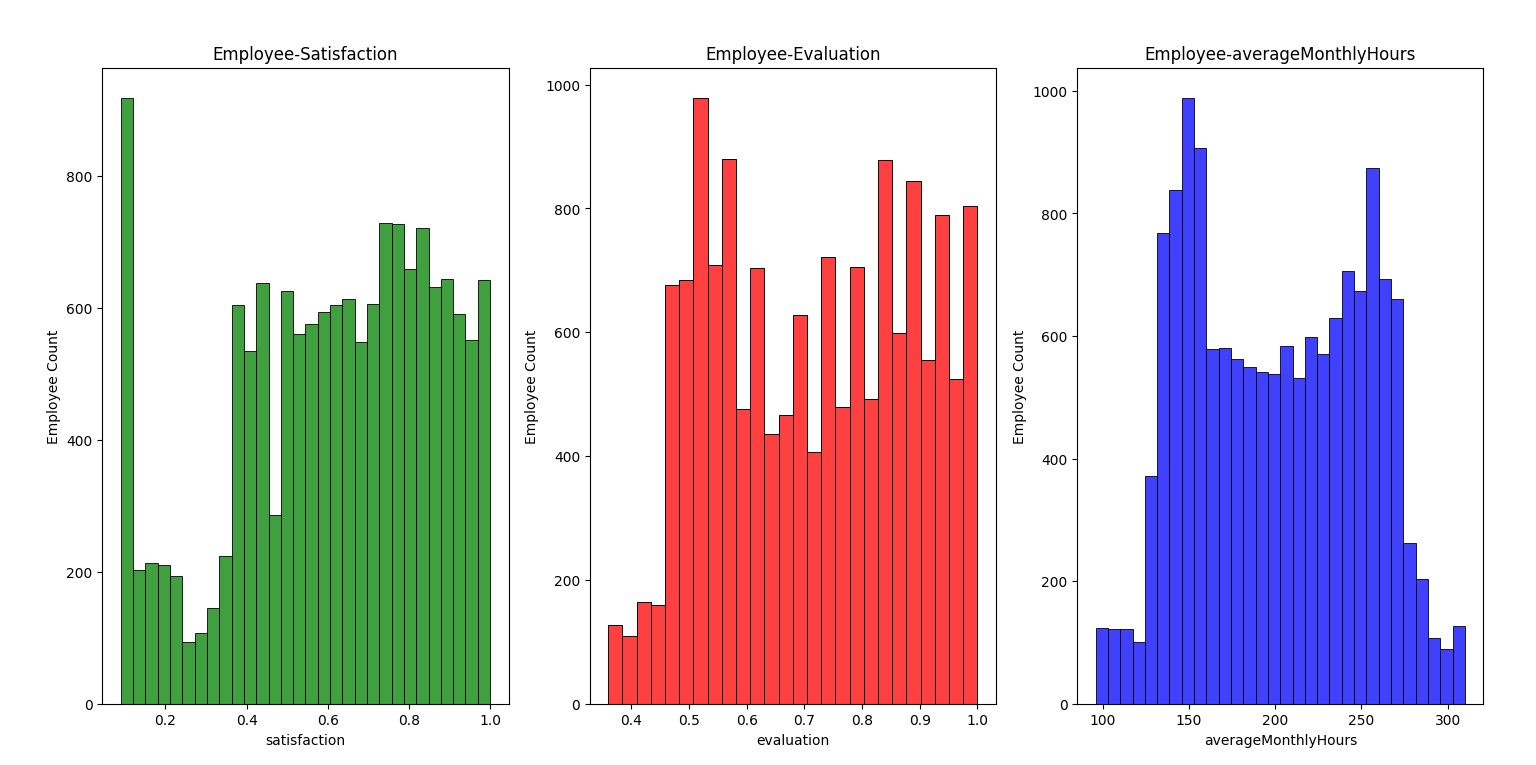
三个图比较相近。工作时间和评价都是双峰,是否说明工作者分为两种(工作久评价高&工作少评价低亦或者其他类型)?
2-3 薪水与离职
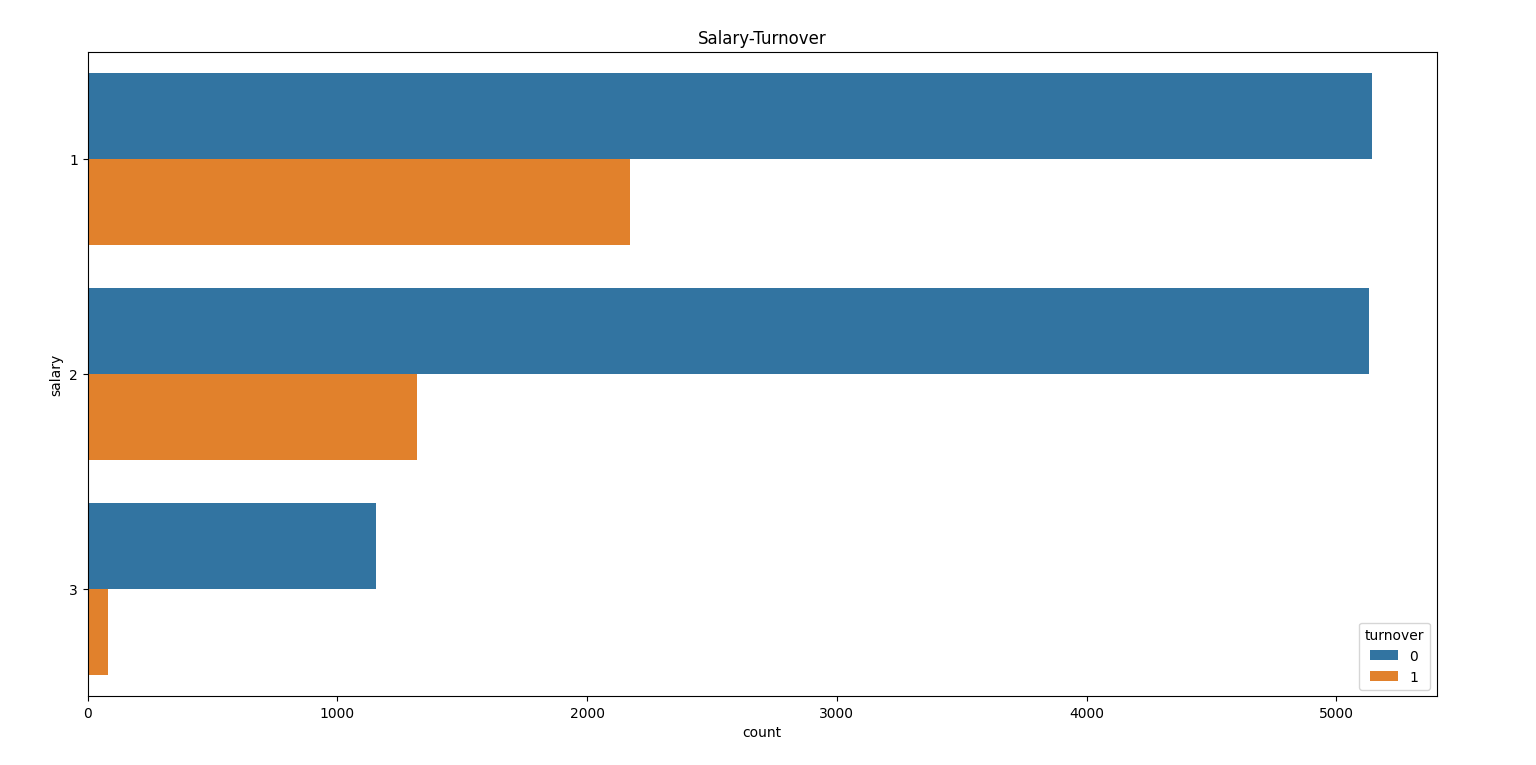
高薪的大都没离职,低薪的更容易离职。
低薪员工的离职率为: 29.69% 中薪员工: 20.43% 高薪员工: 6.63%
2-4 部门与离职
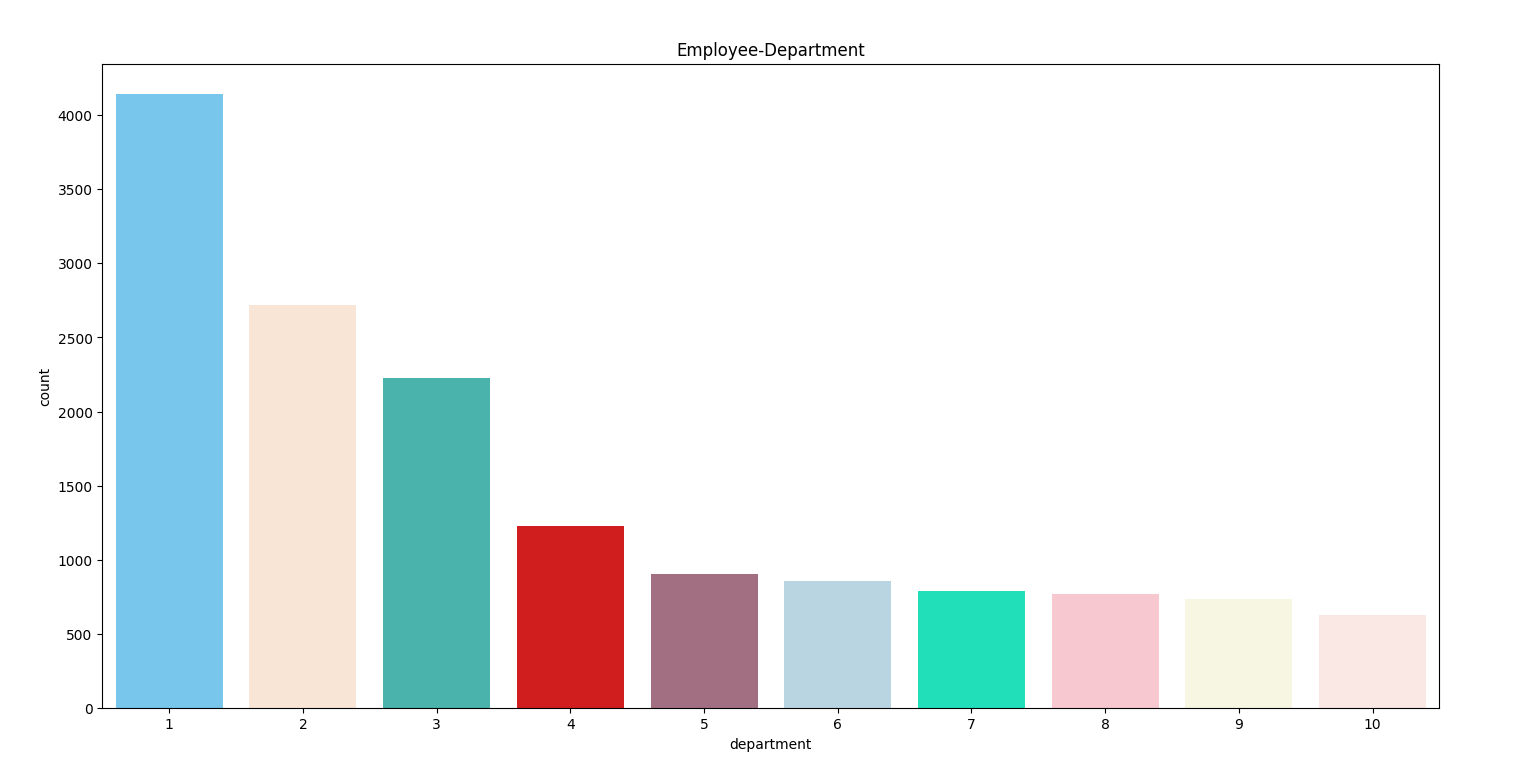
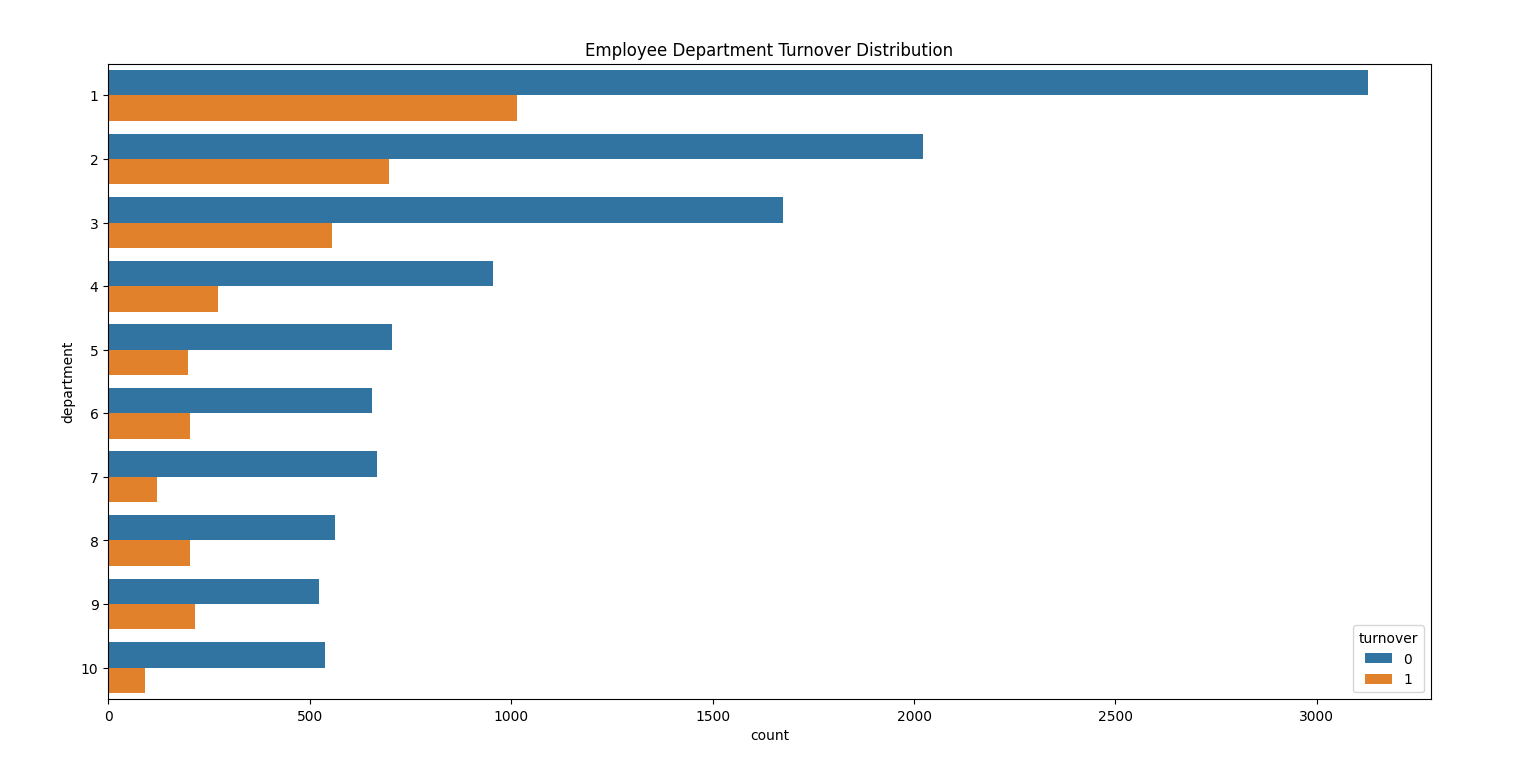
sales,technical,support department的离职率很高
2-5 评价与离职
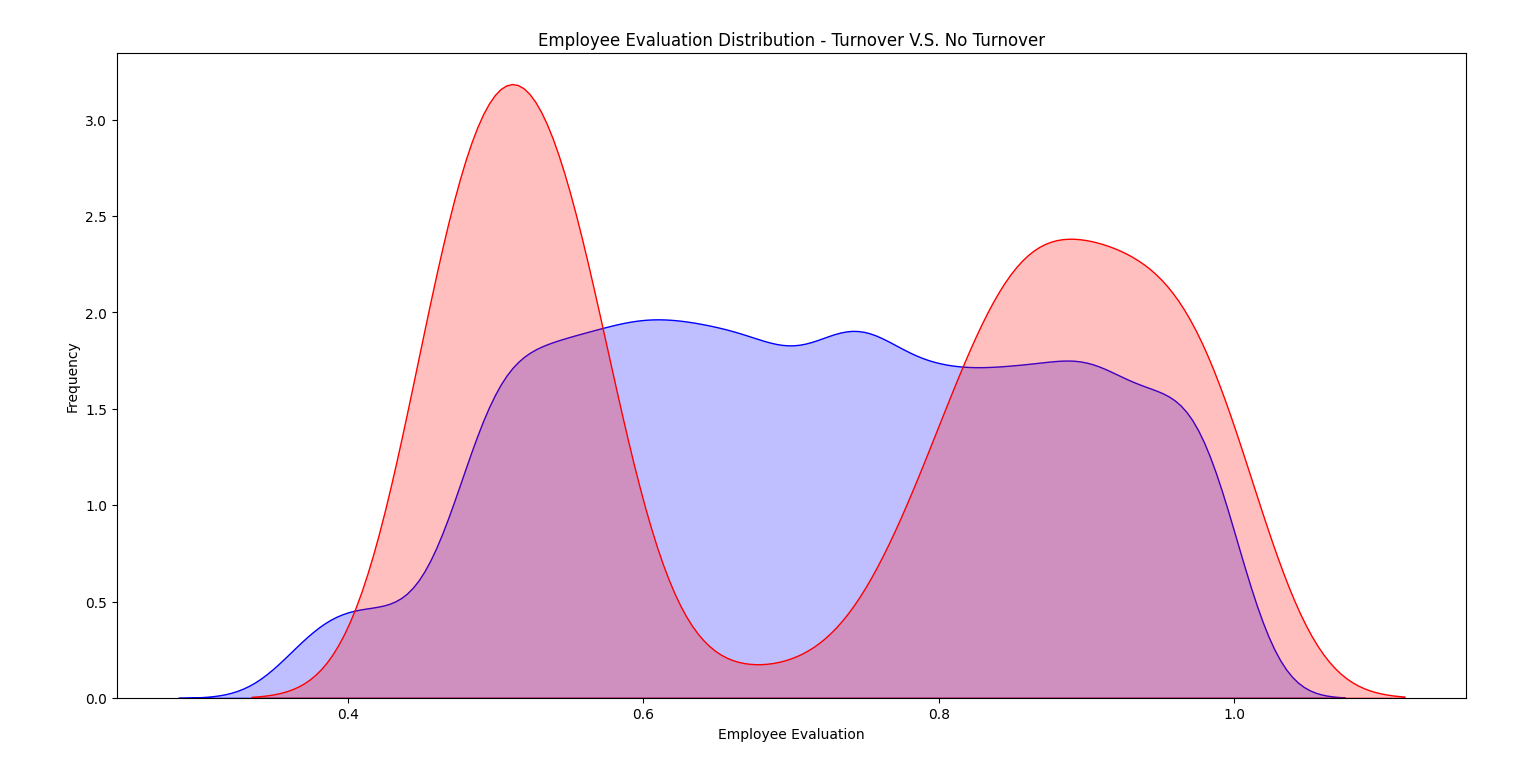
离职率和评价间存在双峰分布。low和high表现的员工更倾向于离开公司。对于员工来讲具有0.6-0.8的评价是一个舒适区。
2-6 评价与完成项目数量&离职
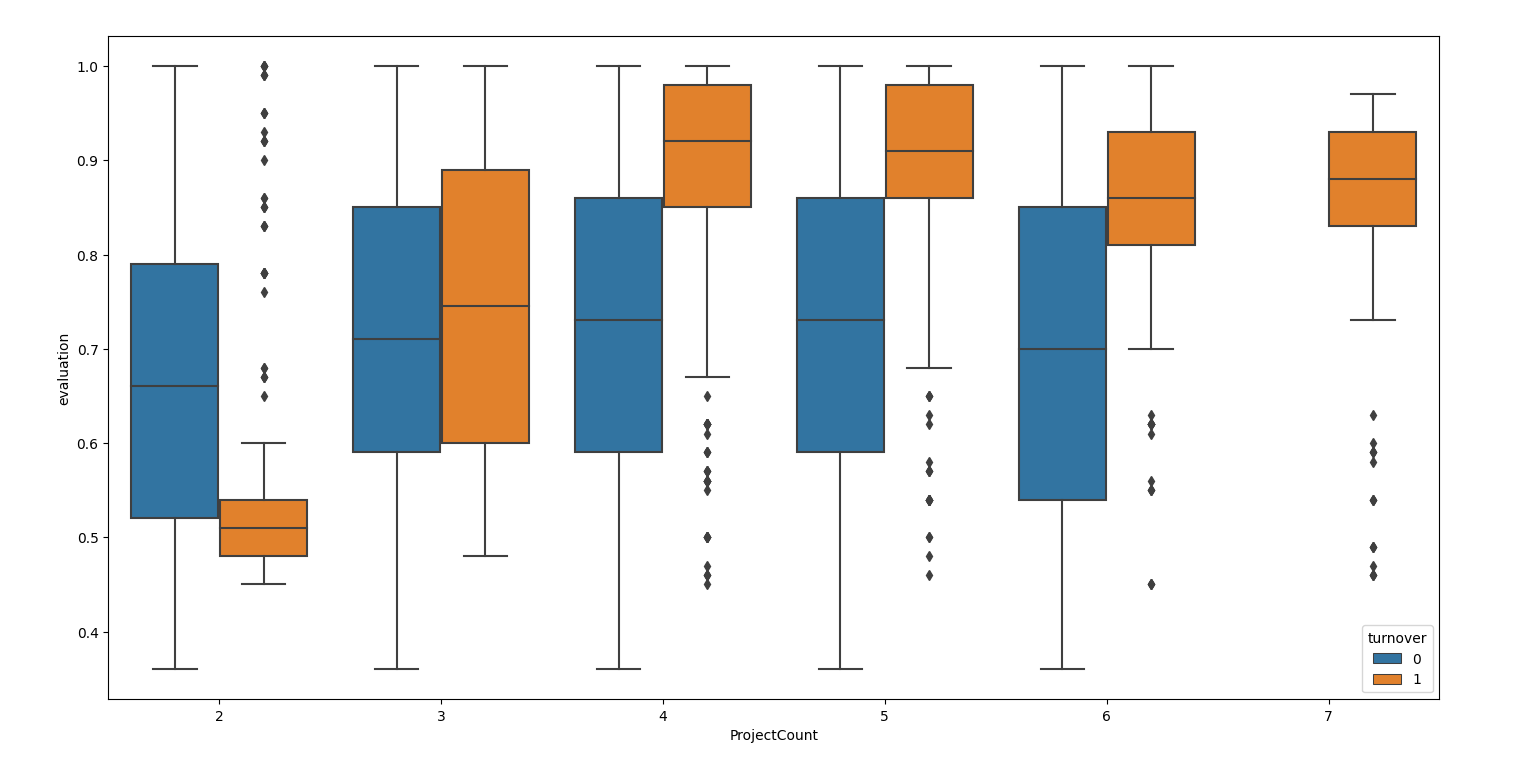
完成更多项目的离职员工的评价有所提高。但是,未离职员工随着项目数量有所增加其评价却没有变化(稳定在0.7)。
并且当项目数量有所增加时(>3)离职员工的平均评价显著高于未离职员工。
离职的人大都为2个项目但评价是坏 或者 大于3个项目但评价是好。
2-7 完成项目数量&离职
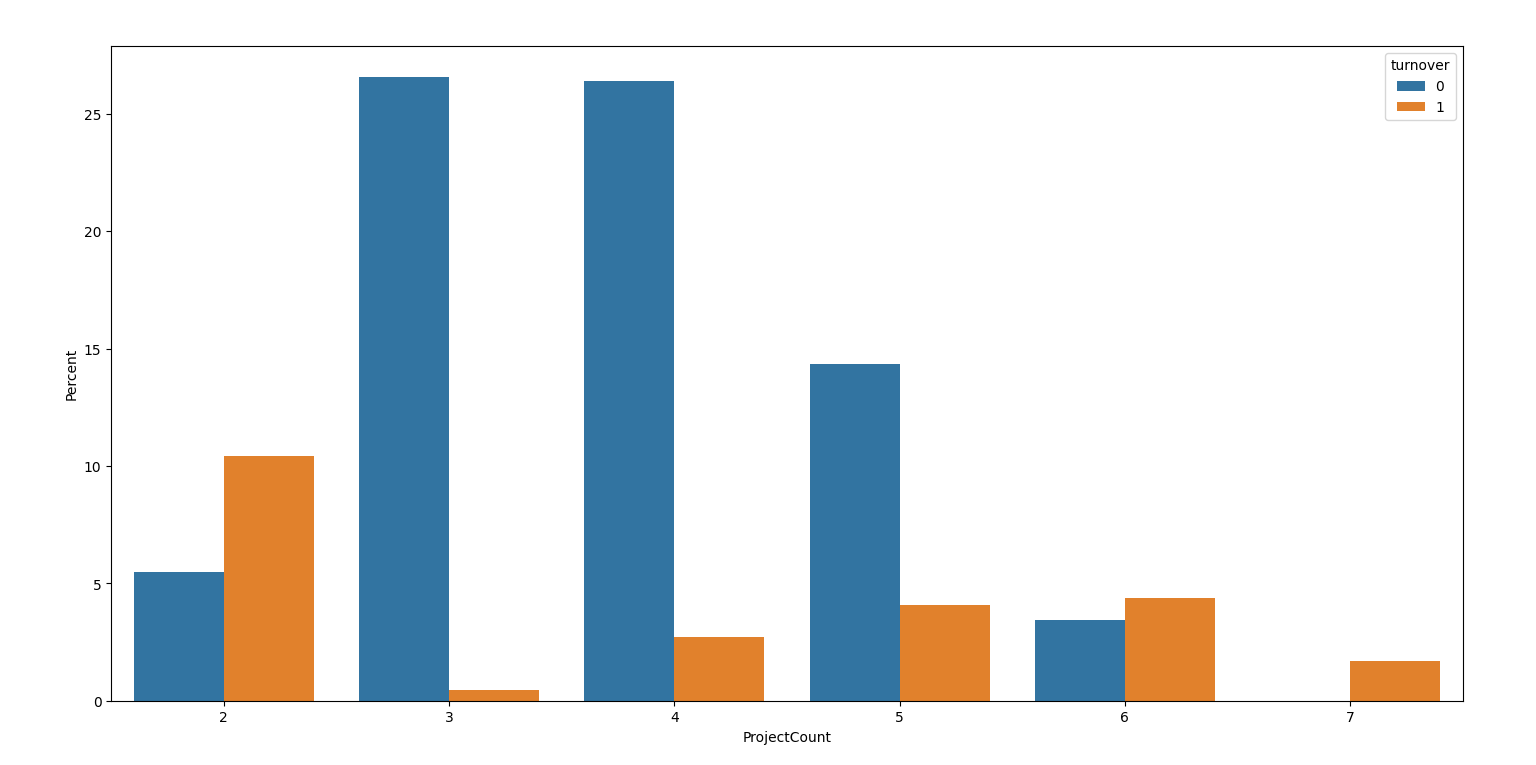
有2,6和7个项目的员工中一半多都离开了公司。有7个项目的员工全都离开了公司。随着项目数量的增加,员工的离职率上升。
大多数没有离开公司的员工有3,4,5个项目。
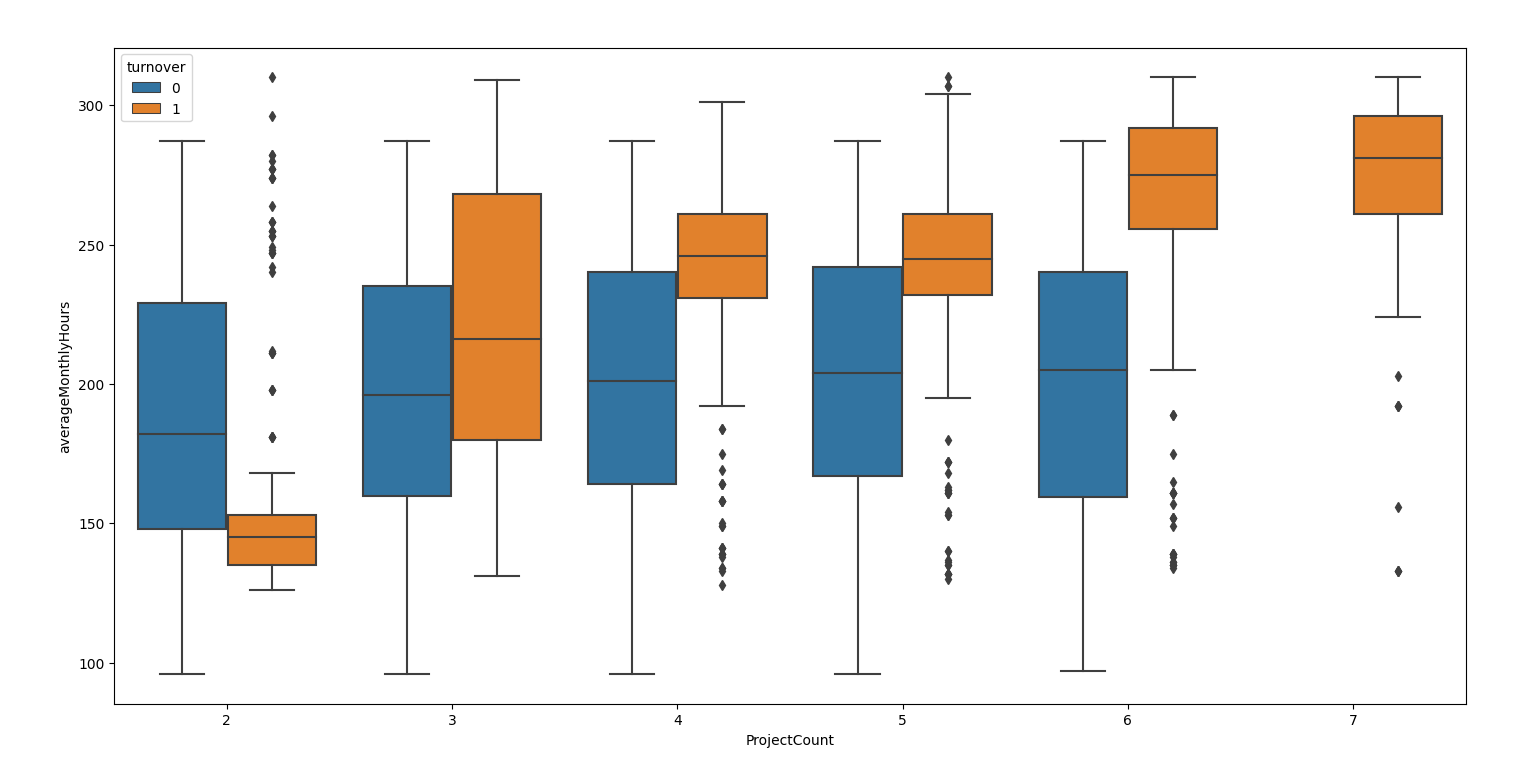
没有离职的员工的工作时间基本不因为项目数量的增加而增加,但离职的员工的工作时间显著因为项目数量的增加而增加。
2-8 离职与工作年限
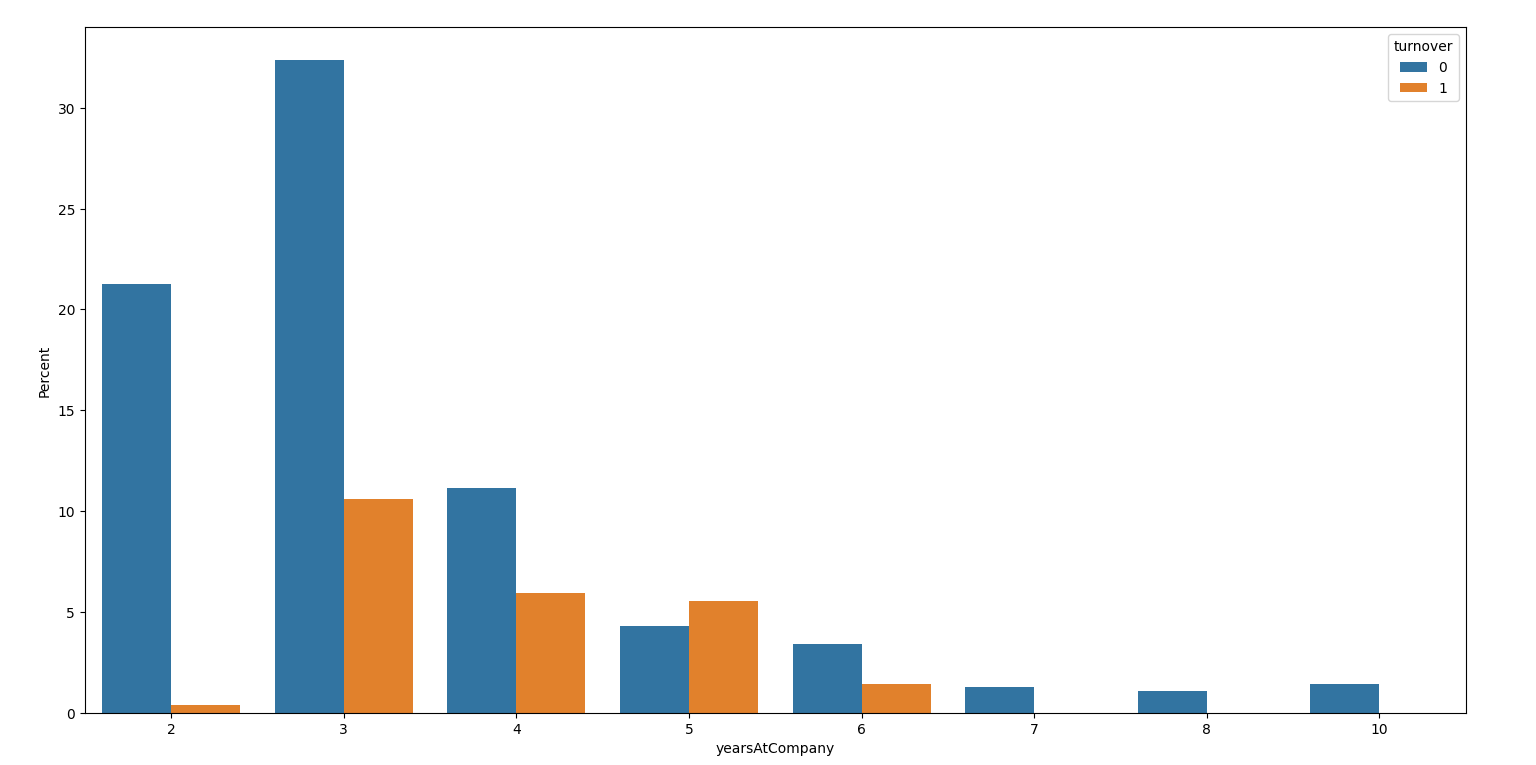
工作了4、5年的员工有一半以上离开了公司,或许他们本应该受到重视。
PART 3
3-1 整体分析
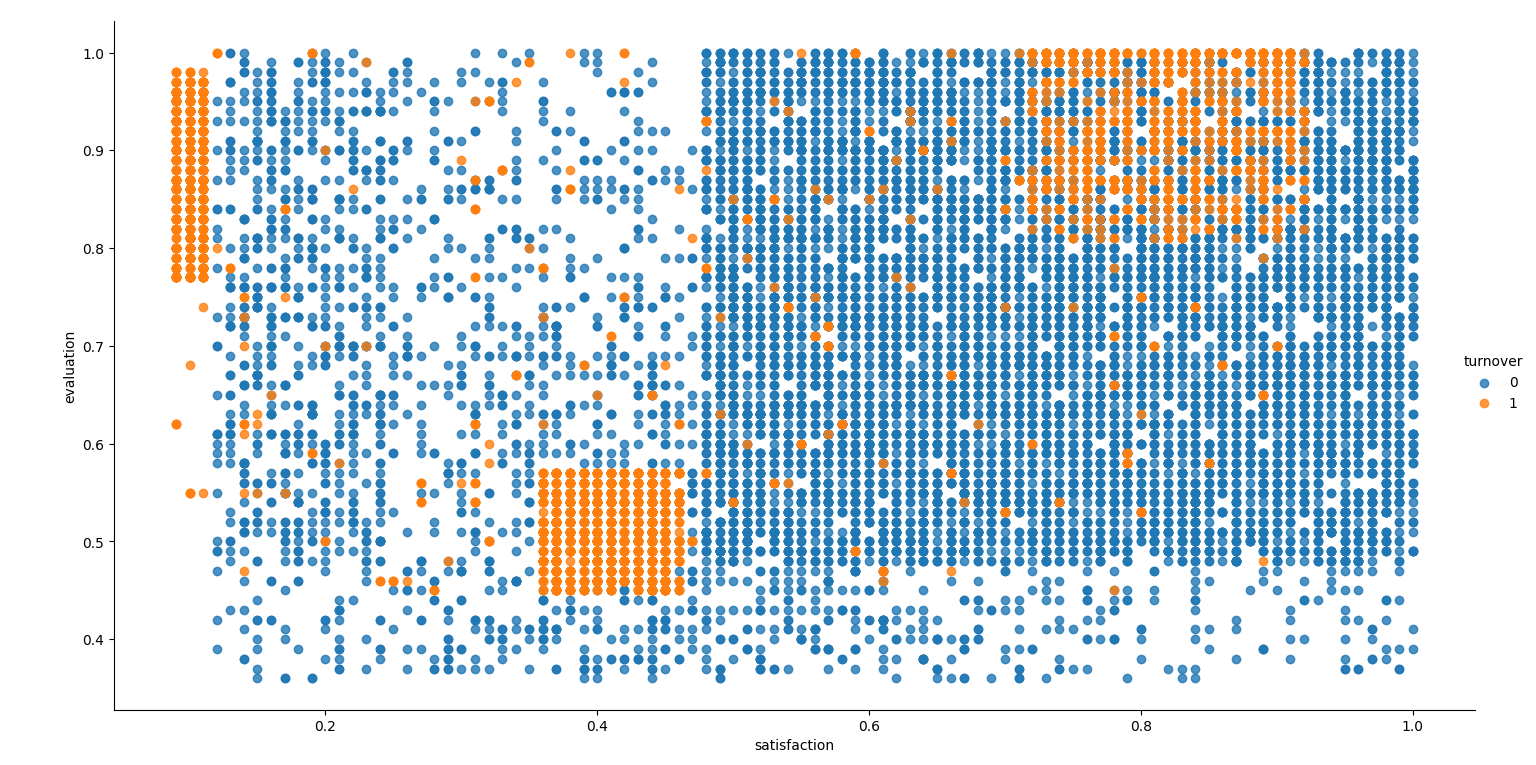
离开公司的员工有3个不同的集群:
Cluster 1 (勤奋工作并且不开心的员工): 满意度低于0.2,评价高于0.75。这可能是一个很好的迹象,表明离开公司的员工都是好员工,但对自己的工作感觉很糟糕。
Question1: 当你被高度评价的时候,是什么原因让员工感觉如此糟糕?会不会太辛苦了?这个集群是否意味着“过度工作”的员工?
Answer 1:虽然高评价员工的离职可能引起担忧,但它也可能是一个机会,让公司审查他们的员工满意度和工作条件,以改进工作环境,以满足员工的需求,从而减少离职率。
这是为什么说Cluster 1可能是一个很好的迹象,因为它可以帮助公司识别和解决潜在的问题,以提高员工满意度和留住高绩效的员工。
Cluster 2 (评价低并且不开心的员工): 满意度在0.35~0.45之间,评价在0.58以下。这可以被看作是在工作中受到了不好的评价和感觉不好的员工。
Question2: 这个集群是否意味着“表现不佳”的员工?
Answer 2:他们在工作中遇到了问题,无法满足公司的期望。或者说他们的潜力可能没有办法在这样的公司里发挥出来。
Cluster 3 (勤奋工作并且开心的员工): 满意度在0.7~1.0之间,评价大于0.8。这可能意味着这个集群中的员工是“理想的”。他们热爱自己的工作,并因工作表现而受到高度评价。
Question3: 这个集群是否意味着员工离开是因为他们找到了另一个工作机会?
Answer 3:或许需要用更有竞争力的薪酬、福利、职业发展机会、管理、指导、工作负荷来挽留这些“理想员工”。
3-2 K-means
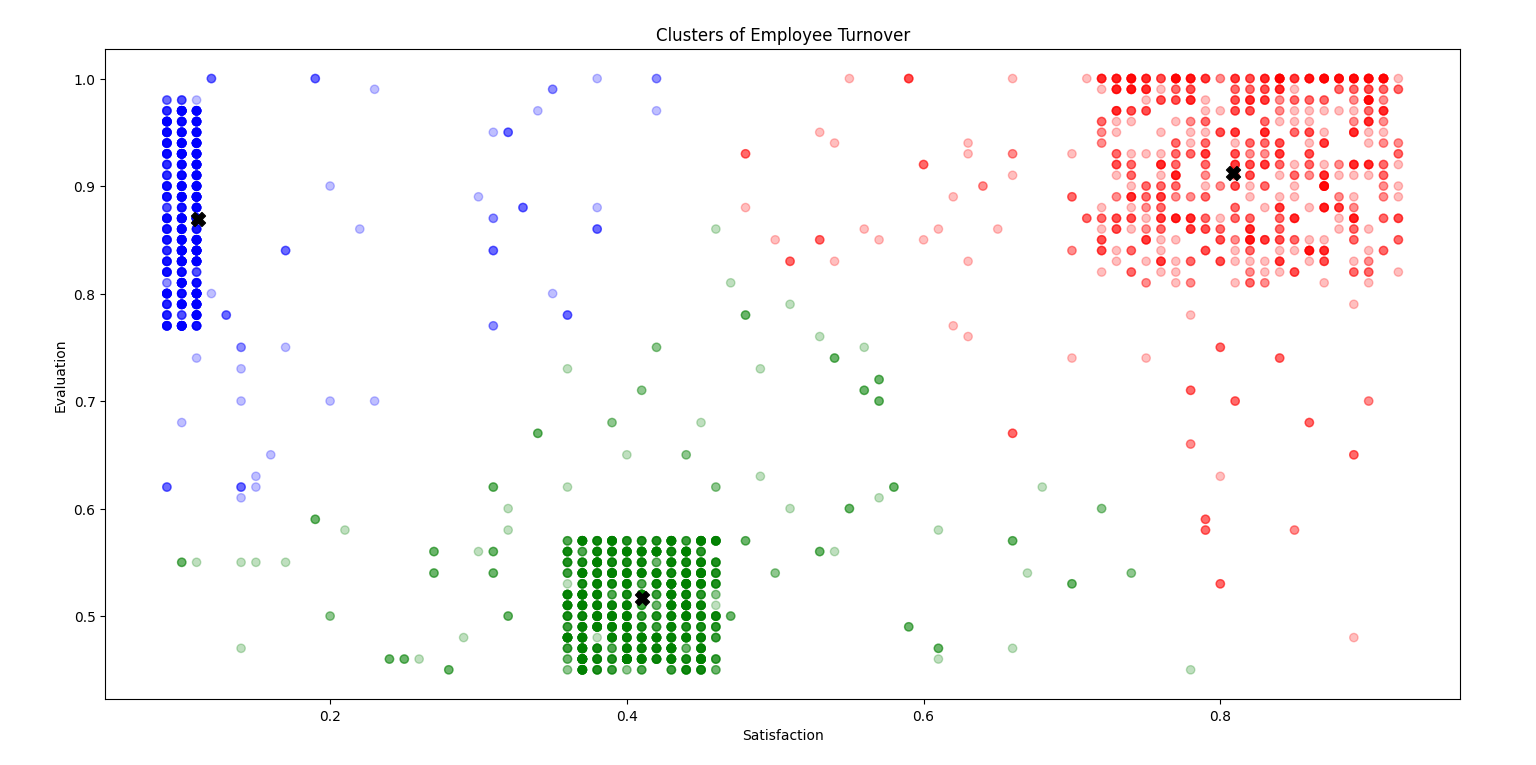
聚类:Cluster 1 (Blue): 勤奋工作并且不开心的员工,
Cluster 2 (Red): 评价低并且不开心的员工,
Cluster 3 (Green): 勤奋工作并且开心的员工。
3-3 重要性分析
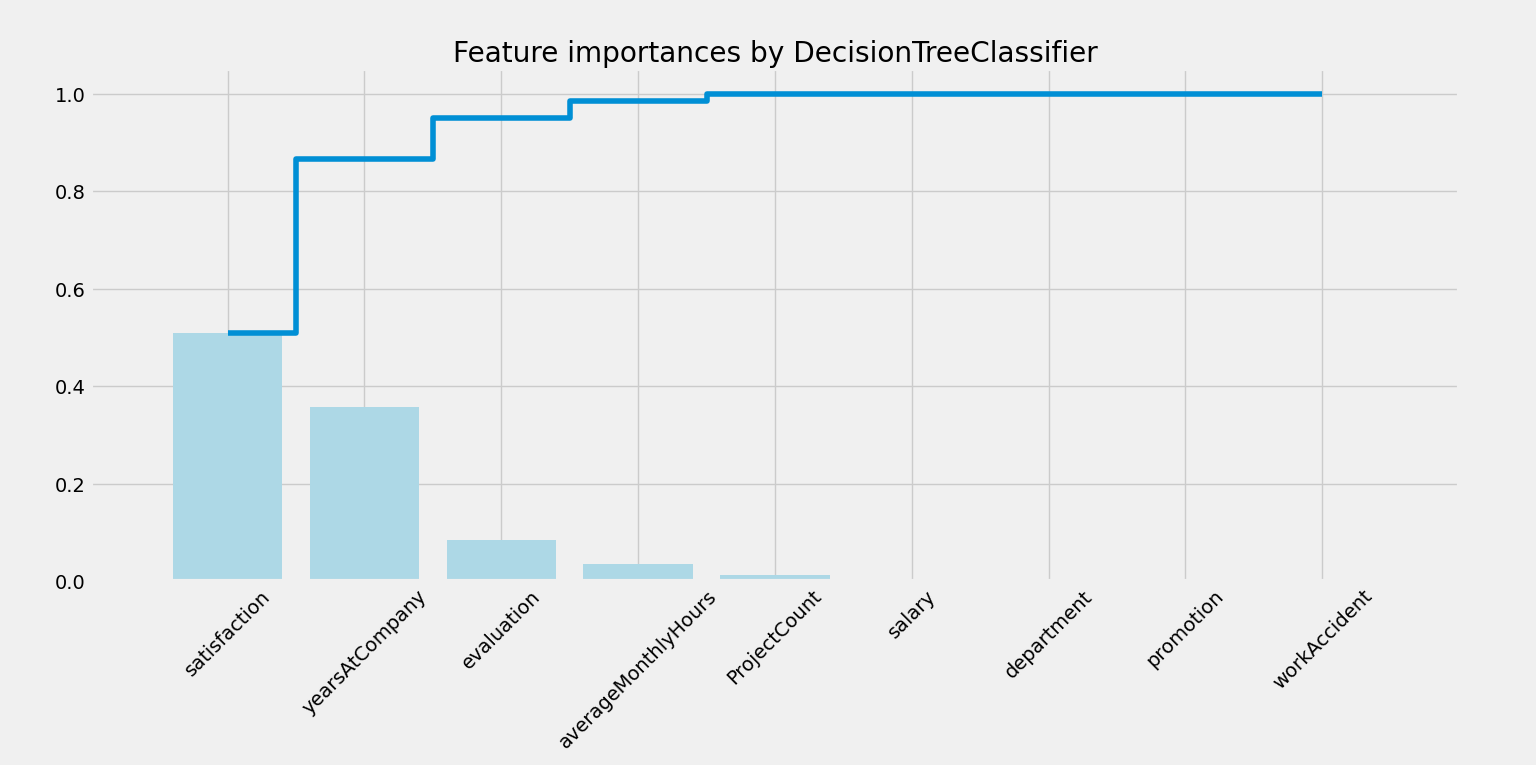
通过使用决策树分类器,它可以对用于预测的特征进行排序。前三个特征是员工满意度、工作年限和评价。
这有助于创建回归模型,因为当使用较少的特征时,理解模型中的内容会更容易理解。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









