







 本文主要介绍了数据结构中的二叉搜索树,阐述其概念,即节点比左子树大、比右子树小,中序遍历为有序数组。还讲解了创建、插入、查询、删除等基础操作,指出查询类似二分查找。最后提到其搜索效率,以及因并非都为O(lgN)而进化出AVL树。
本文主要介绍了数据结构中的二叉搜索树,阐述其概念,即节点比左子树大、比右子树小,中序遍历为有序数组。还讲解了创建、插入、查询、删除等基础操作,指出查询类似二分查找。最后提到其搜索效率,以及因并非都为O(lgN)而进化出AVL树。
接下来的部分将会记录一些数据结构。有时候看一本书,就像欣赏一部电影,在无数的铺垫后,结局便浮现出来了。先来说一说第一个数据结构——二叉搜索树。
目录
概念
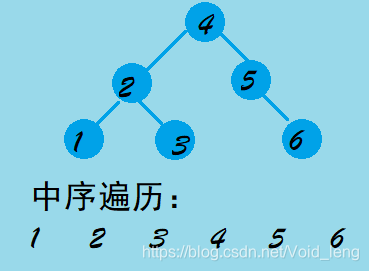
二叉搜索树,之所以是搜索树,是因为便于搜索。二叉搜索树可以说是堆的一种进化,因为堆的父亲结点总是比孩子结点大或者小,这要看是大堆还是小堆。那么二叉搜索数满足的是节点总是比左子树大,比右子树小。二叉搜索树的中序遍历其实就是一个有序的数组。
基础操作
创建
首先做好准备工作,创建结点的结构体,和一个搜索树的类。再写一个中序遍历,进行每一步验证。
template<class T>
struct BTnode
{
BTnode(T val = T())
:val_(val)
,left_(nullptr)
,right_(nullptr)
{}
T val_;
BTnode<T>* left_;
BTnode<T>* right_;
};
template<class T>
class SearchTree
{
typedef BTnode<T>* pNode;
typedef BTnode<T> Node;
public:
SearchTree()
:root_(nullptr)
{}
void Print()//打印
{
inorder__(this->root_);
cout << endl;
}
private:
void inorder__(pNode root)//递归中序遍历
{
if(!root)
return;
inorder__(root->left_);
cout << root->val_ << " ";
inorder__(root->right_);
}
private:
pNode root_;
};插入
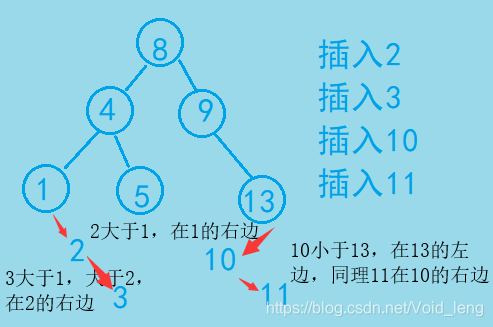
在插入时,有两种情况
空树:直接插入
不是空树:则去找一个满足二叉搜索树的性质的位置进行插入。这个性质就是父亲结点大于左子树小于右子树的所有结点。这个位置其实就是一个叶子结点,叶子结点总是满足的这个要求。
如:按顺序插入2、3、10、11。
bool Insert(const T& val)
{
if(!root_)//空树直接插入
{
root_ = new Node(val);
return true;
}
else
{
pNode cur = root_;
pNode parent = nullptr;
while(cur)
{
if(val == cur->val_)//如果已经存在,则不能插入
return false;
else if(val > cur->val_)
{
parent = cur;
cur = cur->right_;
}
else
{
parent = cur;
cur = cur->left_;
}
}
pNode node = new Node(val);
if(val < parent->val_)
parent->left_ = node;
else
parent->right_ = node;
return true;
}验证一下,Linux环境下。
vector<int> arr = {5,2,8,4,3,6,9,7};
SearchTree<int> bt;
for(const auto& e : arr)
{
bt.Insert(e);
}
bt.Print(); 
查询
二叉搜索树的强项便是搜索。它的搜索的步骤就像是二分查找。当我们要查询一个数的时候,先与根节点比较,如果比根结点大则去右子树,反之去左子树,循环往复,如果找到了则返回,如果到了叶子结点还没找到,说明这个数就没有在这个二叉树中。
pNode Find(const T& val)
{
if(!root_)
return nullptr;//空树还找啥。。
pNode cur = root_;
while(cur)
{
if(val == cur->val_)//找到
return cur;
else if(val > cur->val_)//大于结点去右子树
cur = cur->right_;
else//小于结点去左子树
cur = cur->left_;
}
return nullptr;//走到最后了都没找到,说明没有给节点
}
验证:
vector<int> arr = {5,2,8,4,3,6,9,7};
SearchTree<int> bt;
for(const auto& e : arr)
{
bt.Insert(e);
}
bt.Print();
BTnode<int>* node = bt.Find(6);
cout << node->val_ << endl;
删除
对于二叉搜索树,删除才是重头戏。因为删除之后还要满足二叉搜索树的性质才行。
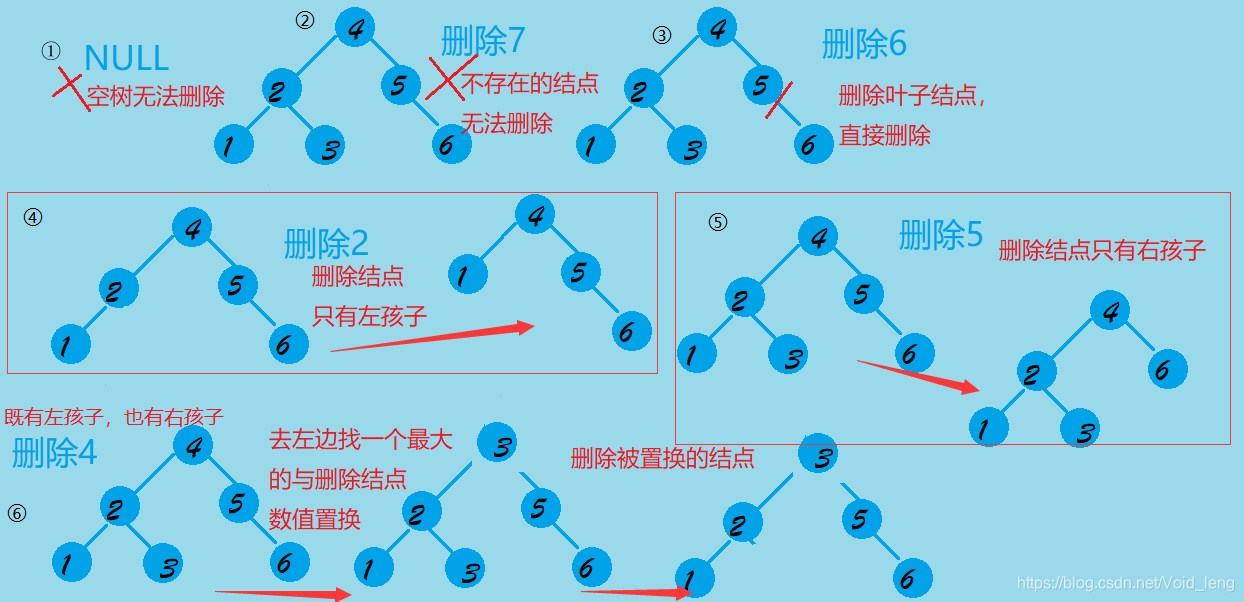
有下面几种情况:
- 空树:删除失败
- 没有该结点:删除失败
- 删除结点为叶子结点:直接删除
- 删除结点只有左孩子:父亲结点指向被删除节点的左孩子结点
- 删除结点只有右孩子:父亲结点指向被删除节点的右孩子结点
- 删除结点俩孩子都有:在左子树找最右边的结点(左子树最大的)或者在右子树找最左边的结点(右子树最小的),它总是叶子结点,与删除结点替换,删除该叶子结点。
大体就是下面这些情况(后面的三种情况还都靠考虑是否是根节点的情况)。
代码拿上来具体看一看。
bool Erase(const T& val)
{
//删除时一共有四种情况
//1、删除的结点是叶子结点的时候
//2、删除的结点只有左孩子的时候
//3、删除的结点只有右孩子的时候
//4、删除的结点既有右孩子也有左孩子的时候
if(!root_)
return false;
pNode cur = root_;
pNode parent = nullptr;
while(cur)
{
if(cur->val_ == val)
break;
else if(val > cur->val_)
{
parent = cur;
cur = cur->right_;
}
else
parent = cur;
cur = cur->left_;
}
if(cur == nullptr)//没找到
return false;
if(cur->left_ == nullptr && cur->right_ == nullptr)
{
if(parent == nullptr)
root_ = nullptr;
else
{
if(parent->left_ == cur)
{
parent->left_ = nullptr;
}
else
{
parent->right_ = nullptr;
}
delete cur;
cur = nullptr;
}
}
else if(cur->left_ == nullptr)//左子树为空
{
if(parent == nullptr)
{
root_ = root_->right_;
}
else
{
if(parent->left_ == cur)
{
parent->left_ = cur->right_;
}
else
{
parent->right_ = cur->right_;
}
}
delete cur;
cur = nullptr;
}
else if(cur->right_ == nullptr)//右子树为空
{
if(parent == nullptr)
{
root_ = root_->left_;
}
else
{
if(parent->left_ == cur)
{
parent->left_ = cur->left_;
}
else
{
parent->right_ = cur->left_;
}
}
delete cur;
cur = nullptr;
}
else//俩孩子都有
{
parent = cur;
pNode minRight = cur->right_;
while(minRight->left_)
{
parent = minRight;
minRight = minRight->left_;
}
cur->val_ = minRight->val_;
//minRight一定是该节点右子树最左边的,否则不是最小的,minRight没有左孩子
//但是可能有右子树
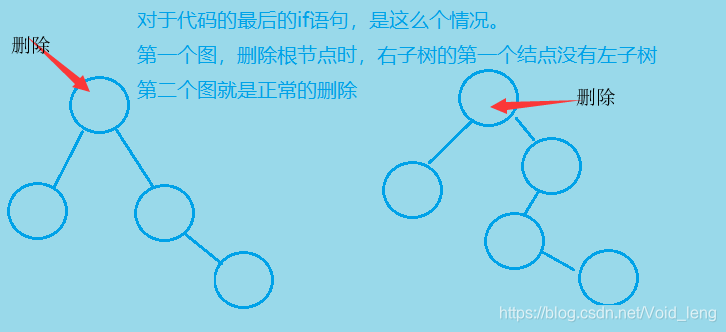
if(parent->left_ == minRight)
parent->left_ = minRight->right_;
//如果删除的是根节点,且根节点的右结点没有左子树
else
parent->right_ = minRight->right_;
delete minRight;
minRight = nullptr;
}
}
二叉搜索树还是比较简单,所以没有太多注释,,,,
彩蛋
我们知道对于二分查找的时间复杂度是O(lgN),一个常数级别的数,对于一个从40亿个数找一个数都只需要32次,可以想象二叉搜索树的搜索效率多高。
但是,二分查找是二分查找,二叉搜索树是二叉搜索树,前面说二叉搜索树的性质是父结点总是大于左子树的所有结点,小于右子树的所有结点,于是。。。

对于这种二叉搜索树,如果要查找5这个结点,还是一个O(N)的时间复杂度。所以二叉搜索树并不是都是O(lgN)。于是二叉搜索树进化了——AVL树。(下一节学习笔记——AVL树,请不要错过)。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









