学习的要点如下:
重排序 可见性 synchronized volatile final Double-Checked Locking 与 Java 内存模型交互时的指南
使用 synchronized 或 volatile 来保护在多个线程之间共享的字段 将常量字段设置为 final 不要从构造函数中泄漏 this 所谓重排序,英文记作 P448_Reorder.Reorder,是指编译器和 Java 虚拟机通过改变程序的处理顺序来优化程序 。虽然重排序被广泛用于提高程序性能,不过开发人员几乎不会意识到这一点。实际上,在运行单线程程序时我们无法判断是否进行了重排序。这是因为,虽然处理顺序改变了,但是规范上有很多限制可以避免程序出现运行错误。 但是,在多线程程序中,有时就会发生明显是由重排序导致的运行错误。 class P448_Reorder. Something {
private int x = 0 ;
private int y = 0 ;
public void write ( ) {
x = 100 ;
y = 50 ;
}
public void read ( ) {
if ( x < y) {
System. out. println ( "x < y" ) ;
}
}
}
public class Main {
public static void main ( String[ ] args) {
final Something obj = new Something ( ) ;
new Thread ( ) {
public void run ( ) {
obj. write ( ) ;
}
} . start ( ) ;
new Thread ( ) {
public void run ( ) {
obj. read ( ) ;
}
} . start ( ) ;
}
}
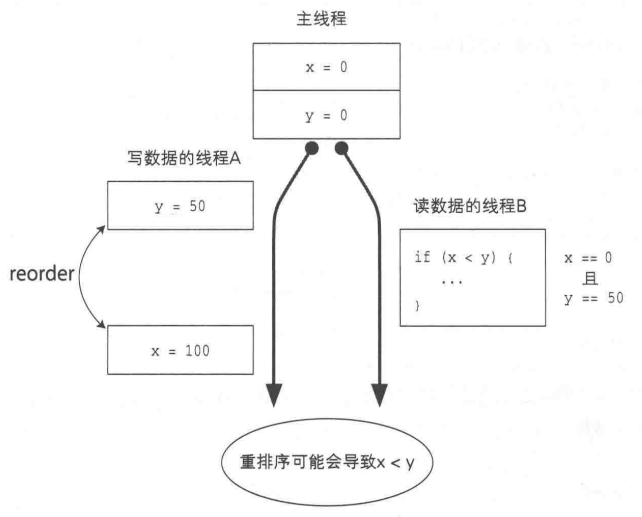
上述程序有可能 显示出 x < y 的,原因就在于重排序。 在write方法中,由于对 x 的赋值和对 y 的赋值之间不存在任何依赖关系,编译器可能会下图那样改变赋值顺序。而且,在线程A已经为 y 赋值,但是尚未为 x 赋值之前,线程B也可能会去查询 x 和 y 的值 并执行 if 语句进行判断。这时,x < y的关系成立。
假设线程 A 将某个值写入到了字段 x 中,而线程 B 读取到了该值。我们称其为 “线程 A 向 x 的写值对线程 B 是可见的(visible)”。 “是否是可见的” 这个性质就称为可见性,英文记作 visibility。 在单线程程序中,无需在意可见性。这是因为,线程总是可以看见自己写入到字段中的值。 但是,在多线程程序中必须注意可见性。这是因为,如果没有使用 synchronized 或 volatile 正确地进行同步,线程 A 写入到字段中的值可能并不会立即对线程 B 可见 。开发人员必须非常清楚地知道在什么情况下一个线程的写值对其他线程是可见的。 共享内存(shared memeory)是所有线程共享的存储空间,也被称为堆内存 (heap memory)。因为实例会被全部保存在共享内存中,所以实例中的字段也存在于共享内存中。此外,数组的元素也被保存在共享内存中。也就是说,可以使用new在共享内存中分配存储空间。 局部变量不会被保存在共享内存中。通常,除局部变量外,方法的形参、catch语句块中编写的异常处理器的参数等也不会被保存在共享内存中,而是被保存在各个线程特有的栈中。正是由于它们没有被保存在共享内存中,所以其他线程不会访问它们。
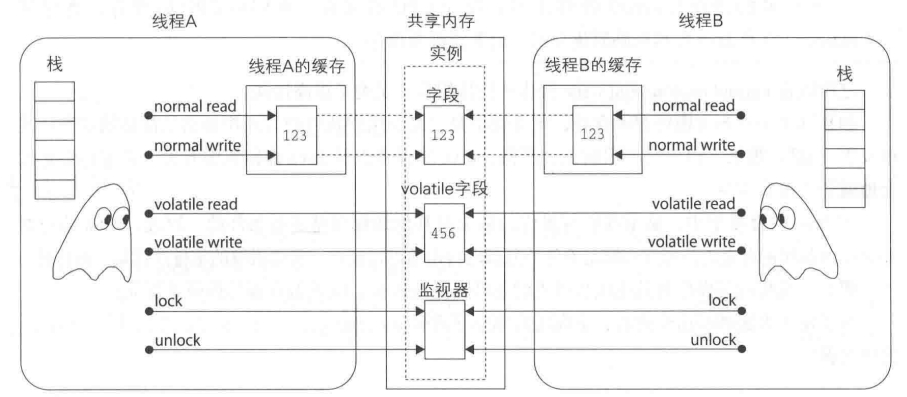
在 Java 内存模型中,只有可以被多个线程访问的共享内存才会发生问题。下图一共展示了6种操作(action):
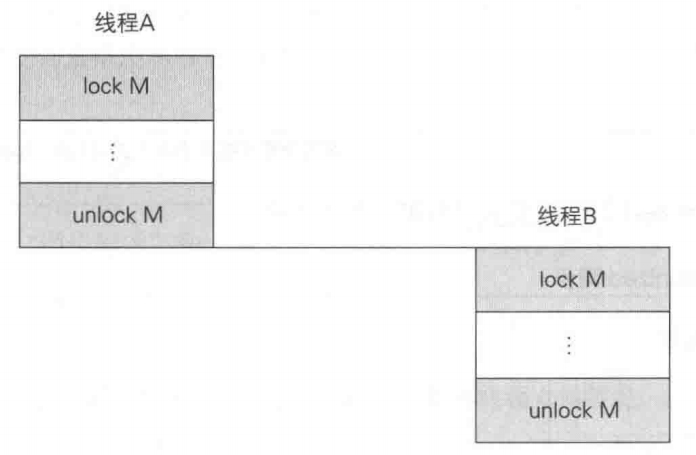
这里,(3)~(6)的操作是进行同步(synchronization)的同步操作(synchronization action)。防止重排序,控制可见性 的效果。 normal read/normal write 操作表示的是对普通字段(volatile以外的字段)的读写。这些操作是通过缓存 来执行的。因此,通过normal read读取到的值并不一定是最新的值 ,通过normal write写入的值也不一定会立即对其他线程可见 。 volatile read/volatile write操作表示的是对 volatile 字段的读写。由于这些操作并不是通过缓存来执行的,所以通过volatile read读取到的值一定是最新的值 ,通过volatile write写入的值也会立即对其他线程可见 。 lock/unlock 操作是当程序中使用了 synchronized 关键字时进行互斥处理的操作。lock操作可以获取实例的锁,unlock操作可以释放实例的锁。 synchronized具有 “线程的互斥处理” 和 “同步处理” 两种功能。 如果程序中有 synchronized 关键字,线程就会进行 lock/unlock 操作。线程会在synchronized开始时获取锁(lock),在synchronized终止时释放锁(unlock)。 进行 lock/unlock 的部分并不仅仅是程序中写有synchronized的部分。当线程在wait方法内部等待的时候也会释放锁。此外,当线程从 wait 方法中出来的时候还必须先重新获取锁后才能继续运行。 只有一个线程能够获取某个实例的锁。因此,当线程A正准备获取锁时,如果其他线程已经获取了锁,那么线程A就会进入等待队列(或入口队列)。这样就实现了线程的互斥(mutal exclusion)。 synchronized的互斥处理下图所示。这幅图展示了当线程 A 执行了unlock操作但是还没有从中出来时,线程B就无法执行lock操作的情形。图中的unlock M 和 lockM中都写了一个M,这表示 unlock 操作和 lock 操作是对同一个实例的监视器 进行的操作。
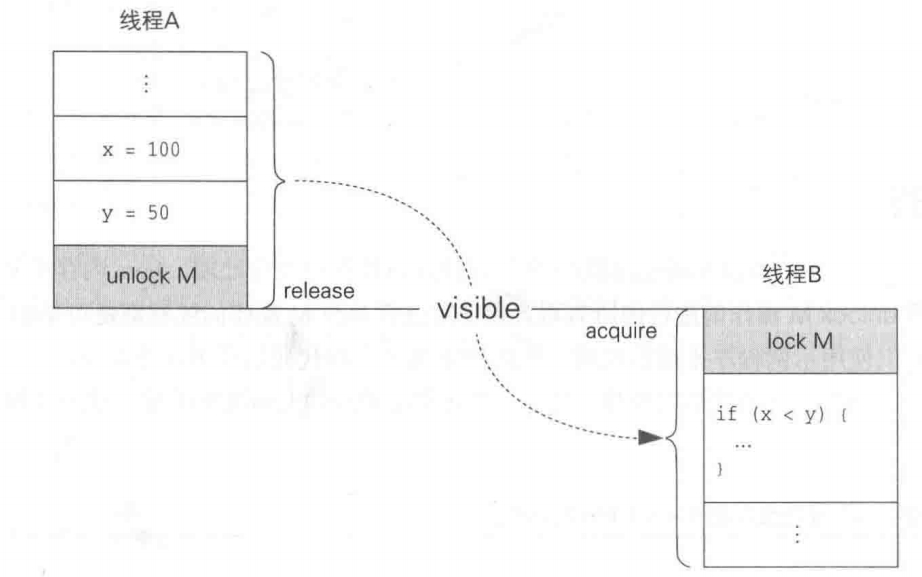
synchronized(lock/unlock操作)并不仅仅进行线程的互斥处理。Java内存模型确保了某个线程在进行 unlock M 操作前进行的所有写入操作对进行 lockM 操作的线程都是可见的 。
进行 unlock 操作后,写入缓存中的内容会被强制地写入共享内存 中 volatile 具有 “同步处理” 和 “对 long 和 double 的原子操作” 这两种功能。 某个线程对 volatile 字段进行的写操作的结果对其他线程立即可见 。换言之,对 volatile 字段的写入处理并不会被缓存起来。volatile 字段并非只是不缓存读取和写入。如果线程 A 向 volatile 字段写入的值对线程 B 可见,那么之前向其他字段写入的所有值都对线程B是可见的 。此外,在向volatile字段读取和写入前后不会发生重排序。
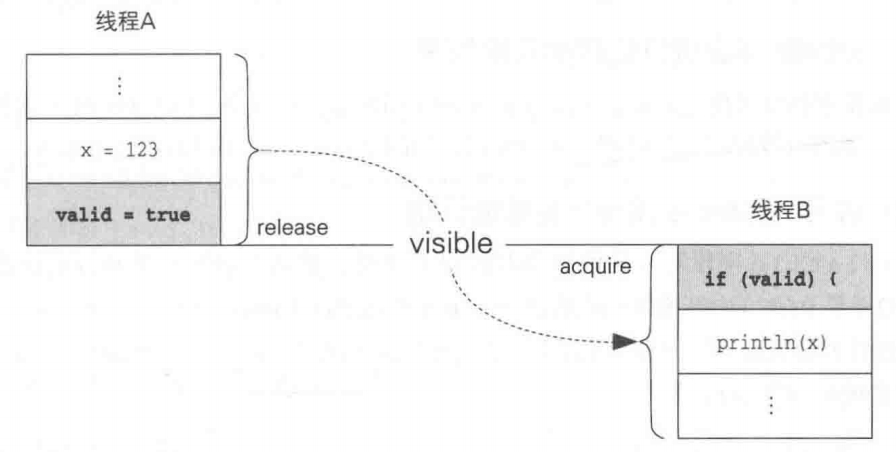
release 和 acquire 表示进行同步处理的两端 (synchronized-with edge)。Java内存模型可以确保处理是按照 “release终止后对应的acquire才开始 ” 的顺序(synchronization order)进行的。
使用 final 关键字声明的字段(final字段)只能被初始化一次 。final 字段在创建不允许被改变的对象 时起到了非常重要的作用。 final 字段的初始化只能在 “字段声明时 ” 或是 “构造函数中 ” 进行。那么,当 final 字段的初始化结束后,无论在任何时候,它的值对其他线程都是可见的 (变为visible)。Java内存模型可以确保被初始化后的 final 字段在构造函数的处理结束后是可见的。也就是说,可以确保以下事情:
如果构造函数的处理结束了:
final 字段初始化后的值对所有线程都是可见的 在 final 字段可以追溯到的所有范围内 都可以看到正确的值 在构造函数的处理结束前……
可能会看到 final字段的值是默认的初始值(0、false或是nul1) 在构造函数执行结束前 ,我们可能会看到 final 字段的值发生变化。也就是说,存在首先看到 “默认初始值”,然后看到 “显式地初始化的值” 的可能性。Double-Checked Locking 模式原本是用于改善 Single Threaded Execution模式的性能的方法之一,也被称为 test-and-test-and-set 不过,在 Java 中使用 Double-Checked Locking 模式是很危险的。 public class DoubleCheck
{
private static DoubleCheck instance = null;
private Date date = new Date ( ) ;
private DoubleCheck ( )
{
}
public Date getDate ( )
{
return date;
}
public static DoubleCheck getInstance ( )
{
if ( instance == null)
{
synchronized ( DoubleCheck. class )
{
if ( instance == null)
{
instance = new DoubleCheck ( ) ;
}
}
}
return instance;
}
}
下面将讲解的解决方案——Initialization On Demand Holder模式既不会像Single Threaded Execution 模式那样降低性能,也不会带来像 Double-Checked Locking 模式那样的危险性。 Holder类是 MySystem 的嵌套类 ,有一个静态字段 instance,并使用 new MySystem() 来初始化该字段。 MySystem 类的静态方法 getInstance 的返回值是 Holder.instance 。 这段程序会使用 Holder的 “类的初始化” 来创建唯一的实例,并确保线程安全 。 这是因为在 Java 规范中,类的初始化是线程安全的 在代码中,我们并没有使用 synchronized 和 volatile 来进行同步,因此性能不会下降。 而且,我们还使用了嵌套类的延迟初始化 (lazy initialization)。Holder类的初始化在线程刚刚要使用该类时才会开始进行。也就是说,在调用 MySystem.getInstance 方法前,Holder 类不会被初始化,甚至连MySystem 的实例都不会创建。因此,使用Initialization On Demand Holder模式可以避免内存浪费。 import java. util. Date;
public class MySystem
{
private static class Holder
{
public static MySystem instance = new MySystem ( ) ;
}
private Date date = new Date ( ) ;
private MySystem ( )
{
}
public Date getDate ( )
{
return date;
}
public static MySystem getInstance ( )
{
return Holder. instance;
}
}


























 2408
2408











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









