






以这个小项目和此篇文章纪念我正式成为程序员三周年
先不废话,直接上成果。
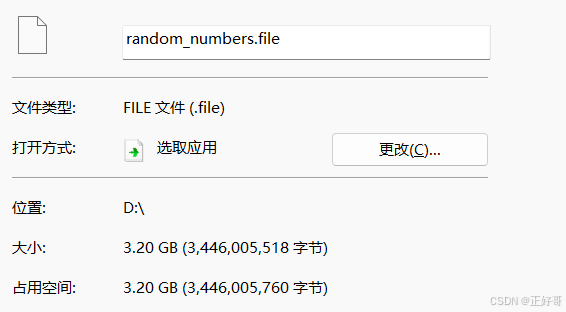
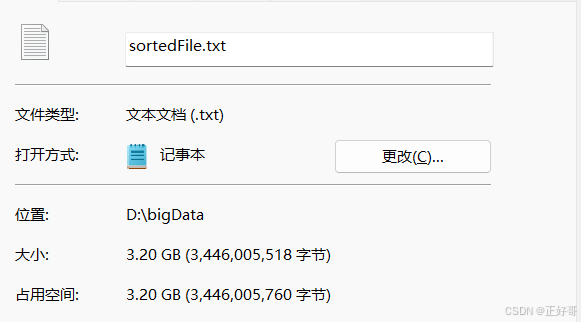

(8核16g的笔记本,排序包含一亿多条数据、3G多的文件,平均耗时240s。)
前言
我决定做这个项目,是因为在学习排序算法的过程中,偶然间了解到还有外部排序这个算法,觉得这是一个非常不错的、涉及Java许多知识面的练手项目,于是想自己动手写一个。在探索过程中,也踩了不少坑。但是写着写着我上头了,不断地往里面加内容,还好及时“刹车”,停止不写了。于是就有点炫技的“嫌疑”,各位看官不要见怪。
第一部分:排序算法的简单介绍
十大经典排序算法:
| 排序算法名称 | 平均时间复杂度 | 最慢时间复杂度 | 蕴含思想 | |
|---|---|---|---|---|
| 冒泡排序 | O(n2) | O(n2) | 简单迭代 | 相邻元素比较交换 |
| 选择排序 | O(n2) | O(n2) | 简单迭代 | 每次选择最小值 |
| 插入排序 | O(n2) | O(n2) | 逐步构建 | 逐步构建有序序列 |
| 希尔排序 | O(nlogn) | O(n2) | 分组思想 | 逐步缩小增量 |
| 归并排序 | O(nlogn) | O(nlogn) | 分治法 | 将数组分成小块排序后合并 |
| 快速排序 | O(nlogn) | O(n2) | 分治法 | 通过划分将数组分成小块 |
| 堆排序 | O(nlogn) | O(nlogn) | 堆结构 | 利用堆的性质进行排序 |
| 计数排序 | O(n+k) | O(n+k) | 哈希思想 | 利用额外数组统计频率 |
| 桶排序 | O(n+k) | O(n2) | 分桶思想 | 将数据分散到多个桶中 |
| 基数排序 | O(nk) | O(nk) | 逐位排序 | 从最低位到最高位 |
(希尔排序的平均时间复杂度取决于增量序列,从O(nlogn)至O(n2)都有可能)
十大经典排序算法中只有计数排序、桶排序、基数排序的时间复杂度可以达到O(n)级别,其他算法最快也就O(nlogn),慢一点O(n2)。这是因为基数排序适合数字或者字符串逐位排序,计数排序适合数据范围不大的整数排序,桶排序适合数据分布均匀的情况。这三个都不是通用的“比较法”排序,所以时间复杂度可以达到O(n),但是在使用上仍然由诸多限制。
其他七个基于“比较法”的排序算法的时间复杂度上限是 O(nlogn)。这是因为比较排序算法受到决策树模型的限制,其高度至少为 log(n!),根据斯特林公式,log(n!) 约等于 nlogn。因此,基于比较的排序算法无法突破 O(nlogn) 的时间复杂度上限,这是已经被理论证明的。如果未来有谁能创建一个突破了nlogn这个“天花板”的通用的排序算法,那么将是计算机科学的极大进步,可能会引发一系列的技术变革,对人们的生活的影响也是方方面面的,他拿个图灵奖我感觉也是绰绰有余的。当然目前也没有产生新理论的土壤,我感觉只能看数学家了,这个搞计算机的解决不了。以下是剩余七种排序算法的适用范围和场景。
| 排序算法名称 | 适合的数据范围 | 适用场景 |
| 冒泡排序 | 数据量较小(通常小于1000) | 数据已经接近有序;对排序效率要求不高的场景;教学和演示 |
| 选择排序 | 数据量较小(通常小于1000) | 数据量较小且对内存空间要求较低;教学和演示 |
| 插入排序 | 数据量较小(通常小于1000) | 数据已经部分有序;在线排序(数据动态插入);对小规模数据排序效率较高 |
| 希尔排序 | 中等规模数据(1000到10000) | 数据量较大但分布较为随机;需要比简单插入排序更快的排序速度 |
| 归并排序 | 大规模数据(10000以上) | 数据量较大且对稳定性要求较高;外部排序(如磁盘文件排序) |
| 快速排序 | 大规模数据(10000以上) | 数据量较大且分布较为随机;对排序速度要求较高;内存排序 |
| 堆排序 | 大规模数据(10000以上) | 数据量较大且需要稳定的排序时间复杂度;对内存空间要求较低 |
当然这些排序算法的使用都有一个前提,那就是计算机的内存能够装得下要排序的数据集。而本文所讨论和实战的外部排序算法,就适合于过大的不适合直接在内存中排序的数据集。还有一些比较搞笑的排序算法,比如:睡眠排序、面条排序、猴子排序等,有兴趣可以自己去了解一下。
第二部分:外部排序的实现思路
如果要对一个非常大的文件进行排序,想一次性把它们都加载到内存然后直接排序是非常不现实的,因为内存很可能会撑不住,难以避免的就OOM了。解决思路有两条:(1)拆分 and 排序→写入→合并;(2)拆分→写入→排序→合并。因为第一条中边拆分边排序实现起来比较复杂而且容易内存溢出(当然第一条也有自己好处,它的步骤更短),所以一般选择第二条:先把大文件拆成一份份大小适合在内存排序的小文件,然后对这些小文件进行排序,最后合并已经排序好的小文件。
我的实现思路就是在第二条路线的基础上更细化:
- 拆分大文件成tmp文件
- 排序tmp文件生成sorted文件
- 删除tmp文件
- 合并sorted文件成最终文件
- 删除sorted文件
整体思路的代码如下:
public abstract class AbstractSort {
/**
* 模板模式
* 子类可以实现具体方法,但是抽象类控制方法的执行流程并对外提供sortFile()方法
*/
public void sortFile() {
try {
//分割大文件成临时小文件
splitFile();
//排序临时小文件为排序文件
sortSmallFiles();
//删除临时小文件
deleteFile(tmpPath);
//合并排序文件为最终文件
mergeSortedFiles();
//删除排序文件
deleteFile(sortedPath);
} catch (Exception e) {
e.printStackTrace();
}
}
//分割方法
public abstract void splitFile() throws IOException;
//排序方法
public abstract void sortSmallFiles() throws InterruptedException;
//合并方法
public abstract void mergeSortedFiles() ;
//删除方法
public abstract void deleteFile(String dirPath) ;
}当然啦,我是把所有步骤写完、走通并实现功能之后。才想到要用到设计模式优化一下代码,写的这个抽象类。实际开发嘛,都是先实现功能再优化(反正我是这样的,一开始没想那么多)。具体开发的时候并没有这个抽象类,只是有一个大概思路。这个抽象类也只是初版,后续还会进一步“升级”。
写得时候面临的问题有:
- 大量的I/O操作如何解决
- 怎么快速排序tmp文件
- 怎么合并sorted文件
第三部分:问题的解决
1.大量的I/O操作如何解决
外部排序涉及到大量的文件读取和写入,我就考虑如何优化。
一开始我用的是Java自带的Buffer流,但是我觉得Buffer的readLine()一行行读、Buffer的write()一行行写,太慢了。就想利用RandomAccessFile搭配MappedByteBuffer实现一次写入多行。有了想法之后,我想到了会面临两个问题:(1)MappedByteBuffer一次读取多少数据到缓存,才能保证每行的数据完整性呢?(文件每一行数据都由固定字段组成,读到程序里之后会被封装成一个对象,所以必须保证每行数据的完整性)(2)文件如何换行呢?
思考了一下,我就有了一个思路:我把要读取文件(因为要读取的文件也是我生成的)的每一行的数据大小都固定为一个数值,MappedByteBuffer的缓存区大小只要是这个数值的整数倍就能保证读进来的数据是完整的。
先给生成每行数据的代码:
/**
* @param str 要填充的字符串
* @param targetLength 目标长度
*/
public static String padStringWithBytes(String str,int targetLength){
byte[] bytes = str.getBytes(); // 将字符串转换为字节数组
byte[] paddedBytes = new byte[targetLength+2]; // 创建目标长度+2的字节数组
// 复制原始字节数组到目标字节数组
System.arraycopy(bytes, 0, paddedBytes, 0, bytes.length);
// 原始字节数组长度要小于目标长度,然后用空格补齐,不考虑大于的情况
Arrays.fill(paddedBytes, bytes.length, targetLength, (byte) ' ');
//写入换行符
paddedBytes[paddedBytes.length - 1] = 10;// \n对应的ascii码
paddedBytes[paddedBytes.length - 2] = 13;// \r对应的ascii码
return new String(paddedBytes);
}这样要读取文件的每一行数据的大小都是一样的,我就可以按照(每一行数据的字节数长度+2)的整数倍来读取和写入,进而保证数据的完整性。为什么要加2,因为文件不光由内容组成,每一行数据的末尾还有换行符,要把换行符的长度也考虑进去。在windows中换行符是"\r\n",所以长度要+2(linux系统的换行是"\r",那就+1)。 这样利用MappedByteBuffer的缓存区我就可以实现文件的快速写入和读取。
想法非常的好,也实现了,但是我不给了具体代码了。为什么呢?因为等我全部写完,发现性能并没有Java自带的Buffer流快。原来Buffer流的readLine()方法,虽然叫“读一行”,但是实际上并不是一次readLine就是一次I/O操作,它也是先把数据读到缓存区,再按行返回。我要实现的功能Buffer流已经实现过了,我白白地造了好几天“轮子”,结果轮子造出来还没有Java的好。。。
我还是不死心,在写入的时候,我又尝试在每条数据结尾拼接"\n"(下面是拼接字符串的代码),将一千条数据拼接成一个字符串后,再用buffer的write()方法一起写进文件,从而实现一次多行写入,结果经过测试也并不比一条条写得快。。。
/**
* 拼接字符串
* @param strs
* @return
*/
public static String spliceStrsToOntStr(String separator,String... strs){
StringBuilder sb=new StringBuilder();
for (int i = 0; i < strs.length-1; i++) {
sb.append(strs[i]).append(separator);
}
sb.append(strs[strs.length-1]);
return sb.toString();
}还尝试了其他方法甚至NIO,最后得出一个结论:还是Java自带的buffer流最快、最稳定、最方便。但是这只是我的经验,也可能是我“火候”还不到家。你们也可以自己试一试,说不定就写出了自己的、比buffer流更好用的输入输出流。
2.如何快速排序tmp文件
我随机生成了101010101条数据在大文件里,我把它们按照100w条/组写入一个小文件,一共得到102个文件,不足100w条的组也单独生成一个文件(用Buffer流完成这整个读取和写入的拆分过程也就20s,我优化输入输出流的努力真的是个“笑话”)。分割完成文件之后,我就面临着如何快速排序这些tmp文件的问题。其实这可以拆解成两个问题:(1)如何一次排序多个文件;(2)如何快速排序100w个对象(一条数据对应一个对象)。前一个问题好解决,利用多线程就可以了。后一个问题,我又有想法了。
我在第一部分已经介绍过了,一般大规模数据(10000以上)适合并归排序或者快速排序,而数据量较小(通常小于1000)时适合插入排序。我就想到既然归并和插入各有各的好,那我把它们的结合起来不就完美了?数据量大的时候我先用并归排序进行拆分,等把数据量拆分到1k或者更少的时候,我就用插入排序对这小份数据进行排序,再利用并归排序将所有已经排好的数据合并。这样就兼顾了并归和插入的优点,同时体现了分治思想和逐步构建的思想。正好ForkJoinPoll就为了分治法而诞生的线程池,我还可以利用它,加快整个排序过程!(分治、逐步构建、多线程,这其实也是整个外部排序的核心)。代码如下:
实体类:
public class User {
private Integer id;
private String code;
private String name;
private String age;
private String type;
}
public class MyReader {
private String completablePath;
private BufferedReader bufferedReader;
private int states;
private long lineCount;
private long currentCount;
private long position;
private long fileSize;
private LinkedList<Element> queues;
}
public class Element {
public int index;
public User value;
public Element(int index, User value) {
this.index = index;
this.value = value;
}
}public class DivisionSort implements Sort {
@Override
public User[] sort(SortEnum sortEnum,User[] arr) {
SortTask sortTask = new SortTask(0, arr.length - 1, arr,sortEnum);
//适合分治任务的ForkJoinPool
ForkJoinPool forkJoinPool = new ForkJoinPool();
ForkJoinTask<User[]> submit = forkJoinPool.submit(sortTask);
User[] users;
try {
users = submit.get();
} catch (Exception e) {
throw new RuntimeException(e);
}
forkJoinPool.shutdown();
return users;
}
}分治任务类:
public class SortTask extends RecursiveTask<User[]> {
private final int THREHOLD=1000;
private User[] users;
private final int start;
private final int end;
//这个枚举的作用是控制排序是顺序还是倒序
private final SortEnum sortEnum;
public SortTask(int start, int end, User[] users, SortEnum sortEnum) {
this.users = users;
this.start = start;
this.end = end;
this.sortEnum = sortEnum;
}
@Override
protected User[] compute() {
//拆分到元素小于1000,就用插入排序
if (end-start<=THREHOLD){
insertionSort(start,end,users);
}else {
int mid=(start+end)>>>1;
SortTask left=new SortTask(start,mid,users, sortEnum);
SortTask right=new SortTask(mid+1,end, users, sortEnum);
left.fork();
right.fork();
left.join();
right.join();
//合并子任务
merge(start,end,mid);
}
return users;
}
// 插入排序
private void insertionSort(int start, int end, User[] array) {
for (int i = start; i <= end; i++) {
User user = array[i];
int j = i - 1;
while (j >= start
&&
(
array[j].getId() < user.getId()&&sortEnum==SortEnum.DESC
||
array[j].getId() > user.getId()&&sortEnum==SortEnum.ASC
)
) {
array[j + 1]= array[j];
j--;
}
array[j + 1] = user;
}
}
/**
* 合并两个有序数组
* @param left 左半部分的起始位置
* @param mid 左半部分的结束位置
* @param right 右半部分的结束位置
*/
private void merge(int left, int right, int mid) {
// 左半部分的长度
int n1 = mid - left + 1;
// 右半部分的长度
int n2 = right - mid;
// 创建临时数组存储左右两部分
User[] leftArray = new User[n1];
User[] rightArray = new User[n2];
// 复制数据到临时数组
for (int i = 0; i < n1; i++) {
leftArray[i] = users[left + i];
}
for (int j = 0; j < n2; j++) {
rightArray[j] = users[mid + 1 + j];
}
// 合并临时数组
int i = 0, j = 0, k = left;
while (i < n1 && j < n2) {
boolean flag=leftArray[i].getId() <= rightArray[j].getId()&&sortEnum==SortEnum.ASC
|| leftArray[i].getId() >= rightArray[j].getId()&&sortEnum==SortEnum.DESC;
if (flag) {
users[k] = leftArray[i];
i++;
} else {
users[k] = rightArray[j];
j++;
}
k++;
}
// 复制剩余的元素
while (i < n1) {
users[k] = leftArray[i];
i++;
k++;
}
while (j < n2) {
users[k] = rightArray[j];
j++;
k++;
}
}
}//排序枚举
public enum SortEnum {
//顺序枚举
ASC,
//倒序枚举
DESC;
}经过实验确实比Java自带的数组排序要快一倍。
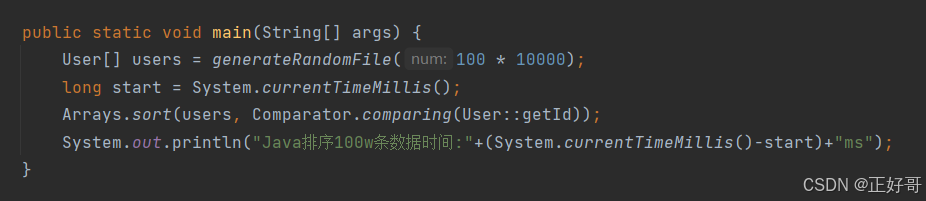

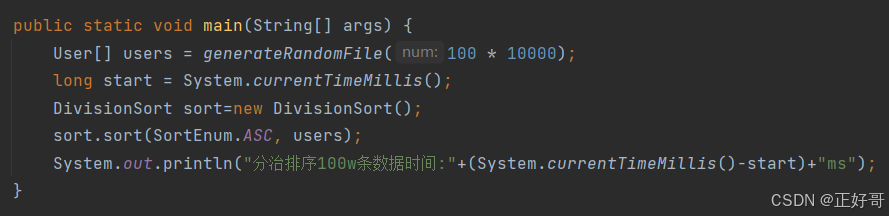

我当然是非常高兴,比Arrays.sort()快这确实是一件值得骄傲的事情(我的这种排序思想其实和Arrays.sort()底层用的TimeSort算法的思想是一样,只不过它没用多线程)。但是“幸福的日子总是短暂的”,事实证明我还是高兴得太早,因为我要用多线程解决第一个“如何一次排序多个文件”的问题,所以一次开了10个排序任务,而每个任务中我写的排序算法也是多线程任务。线程开得太多了,我电脑的内核也就8个,就出现了线程之间相互抢夺cpu资源的现象,多线程排序退化成了单线程排序,就和Arrays.sort()没啥区别了。实际证明我的排序算法在多线程任务中的表现并不比Java自带的方法好,又白白的造了个“轮子”。。。。不过如果是非并发场景的话,我的排序确实要快一点。

其实我的分治排序还有一个比较容易忽略的点, 就是多线程操作一个数组为什么不会出现并发问题?这是因为我对数组是按照二分法进行拆分的。拆分到最后,每个要执行插入排序的任务拿到的虽然是同一个数组,然而排序的却是不同索引范围的数据(如上图,同一个颜色就代表要在此索引范围内执行一次插入排序,每一次插入排序都有一个线程执行),线程之间的不会出现相互干扰。因此要排序数组虽然是个共享资源,但是不用考虑并发安全问题。
当然这只是单个tmp文件的排序算法,使用多线程同时排序多个tmp文件,才能提高排序性能,具体代码如下
总排序方法:
public void sortSmallFiles(String tmpPath, String sortedPath, ExternSort.Operator operator) throws Exception {
ThreadPoolExecutor executor = MyExecutor.getExecutor();
try {
String[] names = new File(tmpPath).list();
if (names != null && names.length != 0) {
for (int i = 0; i < names.length; ) {
CountDownLatch countDownLatch = new CountDownLatch(Constants.PARA_NUM);
for (int j = 0; j < Constants.PARA_NUM; j++) {
if (i > names.length - 1) {
countDownLatch.countDown();
continue;
}
TaskWrite task = new TaskWrite(operator, countDownLatch, tmpPath, sortedPath, names[i]);
executor.execute(task);
i++;
}
countDownLatch.await();
}
}
} finally {
executor.shutdown();
}
}任务类代码:
public class TaskWrite implements Runnable {
private final ExternSort.Operator operator;
private final String tempPath;
private final String finalPath;
private final String name;
private final CountDownLatch countDownLatch;
public TaskWrite(ExternSort.Operator operator,CountDownLatch countDownLatch, String tempPath, String finalPath, String name) {
this.operator = operator;
this.countDownLatch = countDownLatch;
this.tempPath = tempPath;
this.finalPath = finalPath;
this.name = name;
}
@Override
public void run() {
File sorted = new File(finalPath);
if (!sorted.exists()) {
sorted.mkdirs();
}
try (
BufferedReader reader = new BufferedReader(new FileReader(MethodUtils.spliceStrsToPath(tempPath, name)));
BufferedWriter writer = new BufferedWriter(new OutputStreamWriter(Files.newOutputStream(
Paths.get(MethodUtils.spliceStrsToPath(finalPath, name))), StandardCharsets.UTF_8));
) {
List<User> list = new ArrayList<>();
String line;
// 读取指定范围的行
while ((line = reader.readLine()) != null) {
User user = MethodUtils.splitStrToUser(line, ",");
list.add(user);
}
User[] usersMySort = operator.sort(list.toArray(new User[0]));
for (User user : usersMySort) {
writer.write(MethodUtils.userToStr(user));
writer.newLine();
}
} catch (Exception e) {
e.printStackTrace();
} finally {
countDownLatch.countDown();
}
}
3.怎么合并sorted文件
怎么合并已经排好序的sorted文件呢?通常采用的办法就是多路并归。听起来高大上,其实利用优先级队列实现起来就很简单。我通过一个简单的案例,模拟一下它的实现思路。
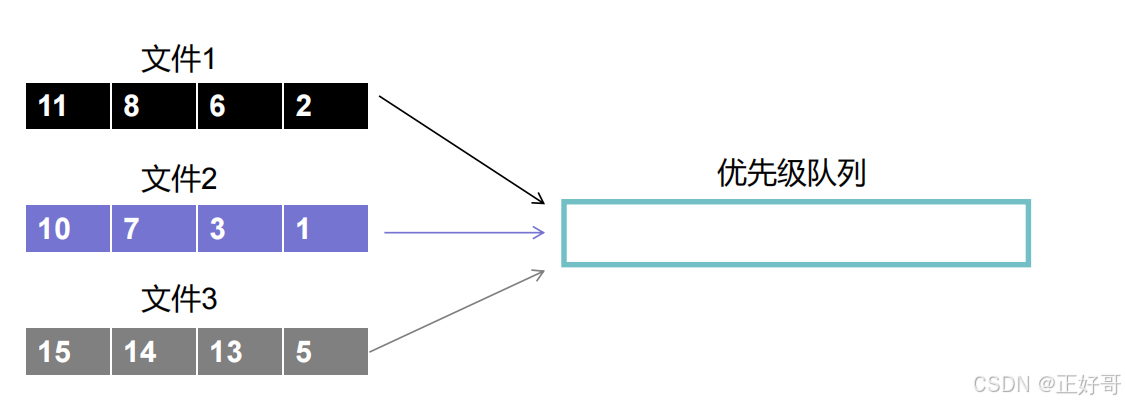
假设我们要将三个已经排好序的文件(文件1、文件2、文件3)合并到一起。那么我们先将这三个文件以及它们各自包含的数据做一个标记,标识某个数据来自哪个文件。本次演示就用不同颜色进行标记。首先我们把这三个文件各自的第一个数据都放到优先级队列之中,得到下图。
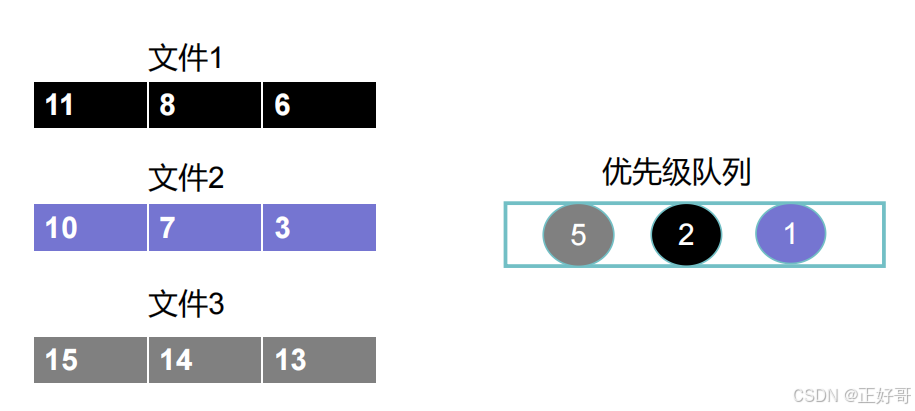
来自文件2的数字1排在队列的头,来自文件1的数字2排在队列的中间,来自文件3的数字5排在尾。
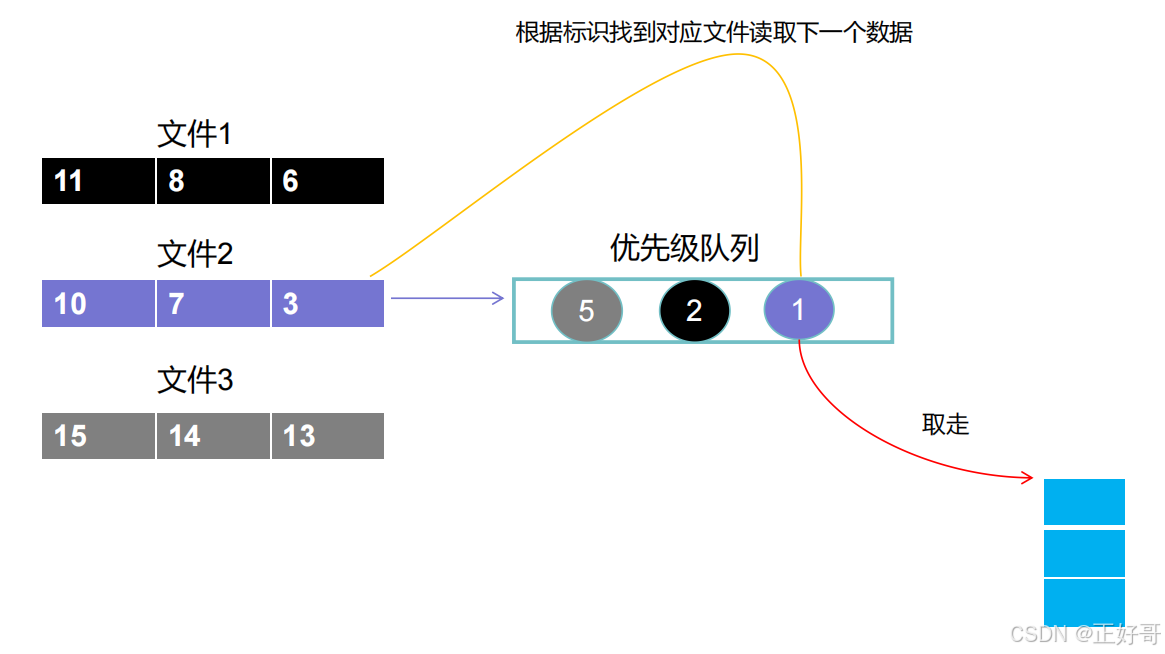
接着我们开始从这个优先级队列的头部开始取数据,那自然取的就是自文件2的数字1放到存储集合当中。 我们取得时候判断一下,这个数字来自哪个文件,就从哪个文件中再读取下一个数字放入优先级队列。数字1来自文件2,那就从文件2再读取一个数字(也就是数字3)放到优先级队列之中,得到下一张图。
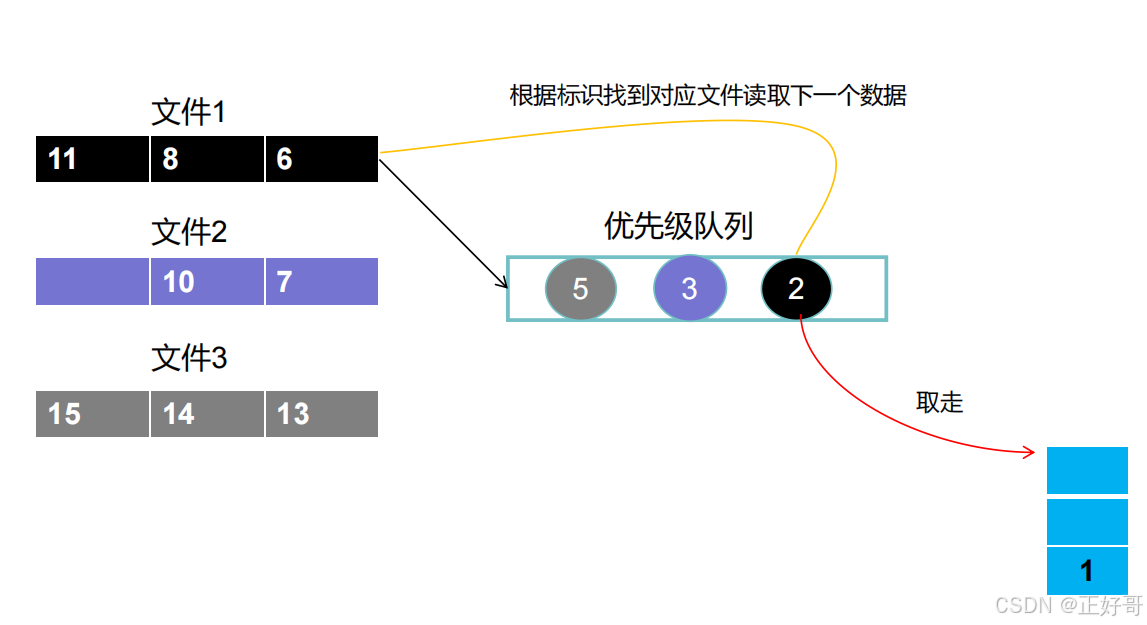
数字3放到优先级队列之中后,排在队列中间,排队列头部的是来自文件1的数字2,我们再取数字2放到存储集合,那么我们这次要放入优先级队列之中的就是来自文件1的数字6,得到下图。
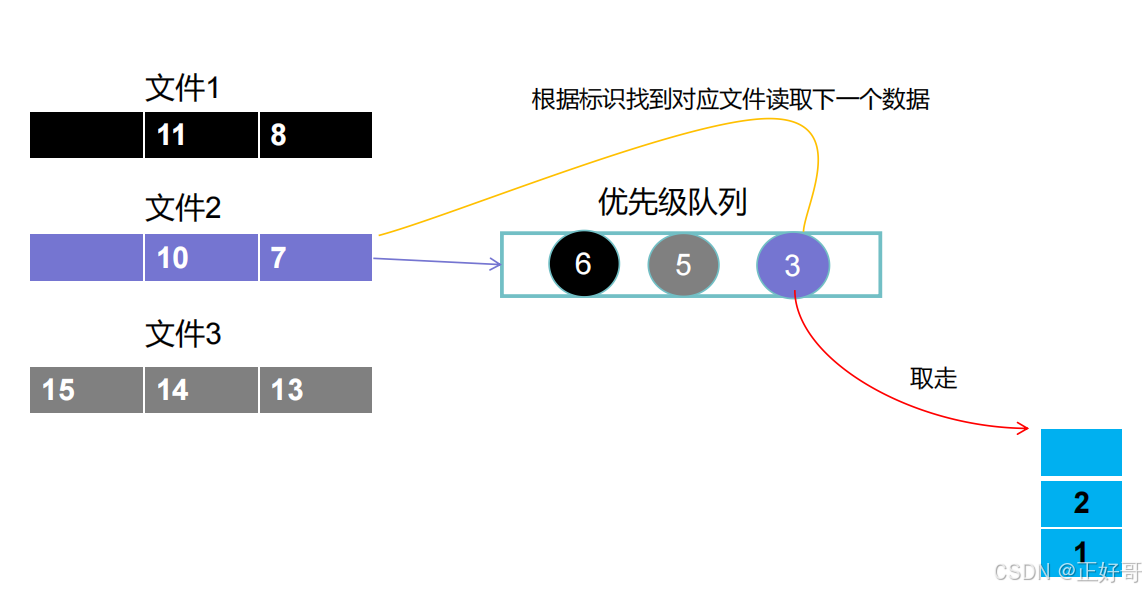
数字6放到优先级队列之中后,排在队列尾部,排队列头部的是来自文件2的数字3,我们再取数字3放到存储集合,那么我们这次要放入优先级队列之中的就是来自文件2的数字7,得到下图。
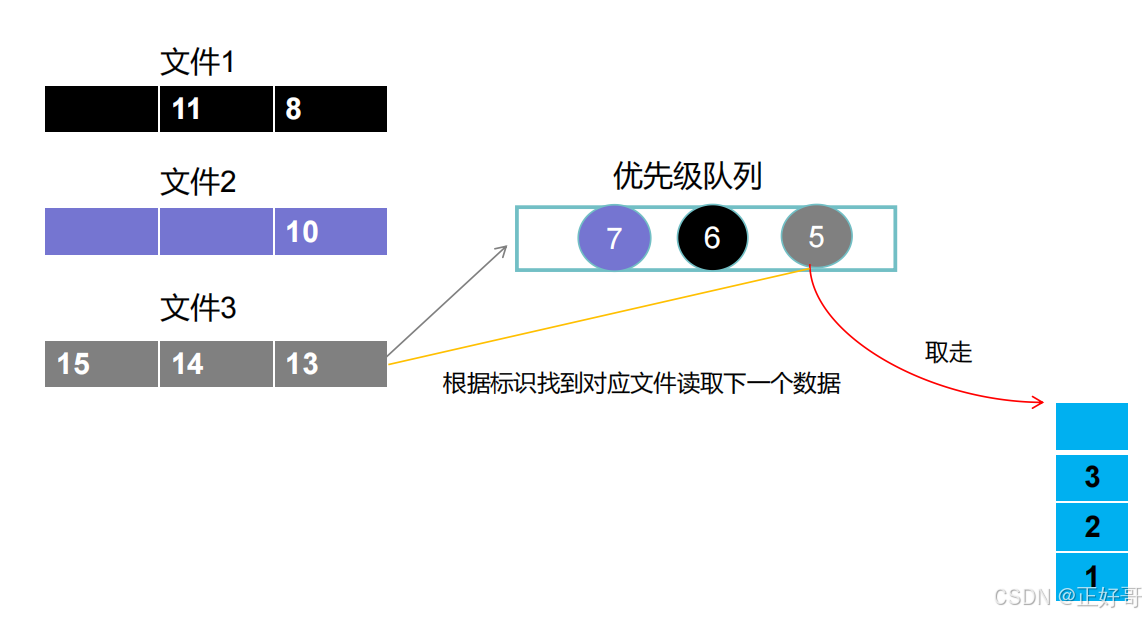
数字7放到优先级队列之中后,排在队列尾部,排队列头部的是来自文件3的数字5。们再把数字5放入存储集合,得到[5,3,2,1],此时观察存储集合是不是按照顺序“写入”的?接着我们将来自文件3的数字13放入优先级队列,优先级队列的排序为:[13,7,6]。如此循环往复就可以把三个排序好的文件合并成一个排序文件。这就是多路并归的实现原理!
原理讲完了,我直接贴自己的代码,核心逻辑是一样的,剩下的不过是细枝末节的实现。
public void mergeSortedFiles(String sortedPath,String targetPath,String newFileName) throws Exception {
PriorityQueue<Element> pq = new PriorityQueue<>(Comparator.comparingInt(e -> e.value.getId()));
//创建目标文件夹
File targetDir = new File(targetPath);
if (!targetDir.exists()) {
targetDir.mkdirs();
}
File dir = new File(sortedPath);
String[] names = dir.list();
String completableTargetPath = MethodUtils.spliceStrsToPath(targetPath, newFileName);
if (names != null && names.length != 0) {
MyReader[] readers = new MyReader[names.length];
//1.保存每个文件的读取流和信息
for (int i = 0; i < names.length; i++) {
String name = names[i];
String completablePath = sortedPath + name;
try {
BufferedReader bufferedReader = new BufferedReader(new FileReader(completablePath));
// 打开文件通道
MyReader bufferReader = new MyReader()
.setBufferedReader(bufferedReader)
.setQueues(new LinkedList<>());
readers[i] = bufferReader;
// 预读取,将数据加载到队列之中
String line = bufferedReader.readLine();
if (line != null) {
User user = MethodUtils.splitStrToUser(line, ",");
Element element = new Element(i, user);
pq.offer(element);
} else {
bufferedReader.close();
}
} catch (Exception e) {
e.printStackTrace();
}
}
//如果文件都为空直接结束方法
if (pq.isEmpty()) {
return;
}
//创建一个临时集合用于吸入缓存区
try (BufferedWriter bufferedWriter = new BufferedWriter(new FileWriter(completableTargetPath))) {
//开始遍历优先级队列
while (!pq.isEmpty()) {
Element e = pq.poll();
String userStr = MethodUtils.userToStr(e.value);
bufferedWriter.write(userStr);
bufferedWriter.newLine();
int j = e.index;
BufferedReader bufferedReader = readers[j].getBufferedReader();
String line = bufferedReader.readLine();
if (line != null) {
User user = MethodUtils.splitStrToUser(line, ",");
Element element = new Element(j, user);
pq.offer(element);
} else {
bufferedReader.close();
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
}第四部分:代码优化
拆分文件、排序文件、合并文件都写完了,其实这个项目就完成了,已经可以排序大文件了。
但是总有人告诉我:做编程开发时要面向对象、要面向接口编程、要模块化开发,项目还要有扩展性和可维护性。所以开发完基本流程之后,我就想“秀一把”。
1.算程的模块化拆分
首先对第二部分给出的抽象类进行优化,虽然已经利用了模板模式,但是整个流程我认为还可以继续“颗粒化”。整个流程可以分成四个算程:拆分、排序、合并和删除。那我们就可以把每一个算程单独拿出来做成一个接口。这样用户想要用自定义的算程,就可以自己实现对应接口,然后把实现类传入进去,充分体现面向接口编程。升级的抽象类如下:
public abstract class AbstractSort {
//排序算子
final ExternSort.Operator operator;
final String srcFile;
final String newFileName;
final String targetPath;
final String tmpPath;
final String sortedPath;
//拆分算程
public SplitProcess splitProcess;
//排序算程
public SortProcess sortProcess;
//合并算程
public MergeProcess mergeProcess;
//删除算程
public DeleteProcess deleteProcess;
AbstractSort(String srcFile, String targetPath, String newFileName, ExternSort.Operator operator) {
this.operator = operator;
this.srcFile = srcFile;
this.newFileName = newFileName;
this.targetPath = targetPath;
this.tmpPath = targetPath + Constants.TMP;
this.sortedPath = targetPath + Constants.SORTED;
}
/**
* 外观模式, 隐藏具体的方法执行流程
*/
public void sortFile() {
try {
//用户没设置自定义算程就使用默认算程
if (splitProcess==null){
splitProcess=new DefaultSplitProcess();
}
//分割文件成临时文件
splitProcess.splitFile(srcFile,tmpPath);
if (sortProcess==null){
sortProcess=new DefaultSortProcess();
}
//排序临时文件为排序文件
sortProcess.sortSmallFiles(tmpPath,sortedPath,operator);
if (deleteProcess==null){
deleteProcess=new DefaultDeleteProcess() ;
}
//删除临时文件
deleteProcess.deleteFile(tmpPath);
if (mergeProcess==null){
mergeProcess=new DefaultMergeProcess() ;
}
//合并排序文件为最终文件
mergeProcess.mergeSortedFiles(sortedPath,targetPath,newFileName);
//删除排序文件
deleteProcess.deleteFile(sortedPath);
} catch (Exception e) {
e.printStackTrace();
}
}
//设置方法的返回值都是this,流式接口
//设置自定义拆分算程
public AbstractSort setSplitProcess(SplitProcess splitProcess) {
this.splitProcess = splitProcess;
return this;
}
//设置自定义排序算程
public AbstractSort setSortProcess(SortProcess sortProcess) {
this.sortProcess = sortProcess;
return this;
}
//设置自定义合并算程
public AbstractSort setMergeProcess(MergeProcess mergeProcess) {
this.mergeProcess = mergeProcess;
return this;
}
//设置自定义删除算程
public AbstractSort setDeleteProcess(DeleteProcess deleteProcess) {
this.deleteProcess = deleteProcess;
return this;
}四个算程抽象接口
/**
* 删除算程接口
*/
@FunctionalInterface
public interface DeleteProcess {
void deleteFile(String dirPath);
}
/**
* 合并算程接口
*/
@FunctionalInterface
public interface MergeProcess {
void mergeSortedFiles(String sortedPath,String targetPath,String newFileName) throws Exception;
}
/**
* 排序算程接口
*/
@FunctionalInterface
public interface SortProcess {
void sortSmallFiles(String tmpPath, String sortedPath, ExternSort.Operator operator) throws Exception;
}
/**
* 分割算程接口
*/
@FunctionalInterface
public interface SplitProcess {
void splitFile(String srcFile,String tmpPath) throws Exception;
}
删除算程的默认实现类
public class DefaultDeleteProcess implements DeleteProcess {
@Override
public void deleteFile(String dirPath) {
File file = new File(dirPath);
if (file.isDirectory()) {
for (String name : Objects.requireNonNull(file.list())) {
deleteFile(MethodUtils.spliceStrsToPath(dirPath, name));
}
}
file.delete();
}
}排序算程默认实现类
public class DefaultSortProcess implements SortProcess {
@Override
public void sortSmallFiles(String tmpPath, String sortedPath, ExternSort.Operator operator) throws Exception {
ThreadPoolExecutor executor = MyExecutor.getExecutor();
try {
String[] names = new File(tmpPath).list();
if (names != null && names.length != 0) {
for (int i = 0; i < names.length; ) {
CountDownLatch countDownLatch = new CountDownLatch(Constants.PARA_NUM);
for (int j = 0; j < Constants.PARA_NUM; j++) {
if (i > names.length - 1) {
countDownLatch.countDown();
continue;
}
TaskWrite task = new TaskWrite(operator, countDownLatch, tmpPath, sortedPath, names[i]);
executor.execute(task);
i++;
}
countDownLatch.await();
}
}
} finally {
executor.shutdown();
}
}
}
合并算程默认实现类
public class DefaultMergeProcess implements MergeProcess {
@Override
public void mergeSortedFiles(String sortedPath,String targetPath,String newFileName) throws Exception {
PriorityQueue<Element> pq = new PriorityQueue<>(Comparator.comparingInt(e -> e.value.getId()));
//创建目标文件夹
File targetDir = new File(targetPath);
if (!targetDir.exists()) {
targetDir.mkdirs();
}
File dir = new File(sortedPath);
String[] names = dir.list();
String completableTargetPath = MethodUtils.spliceStrsToPath(targetPath, newFileName);
if (names != null && names.length != 0) {
MyReader[] readers = new MyReader[names.length];
//1.保存每个文件的读取流和信息
for (int i = 0; i < names.length; i++) {
String name = names[i];
String completablePath = sortedPath + name;
try {
BufferedReader bufferedReader = new BufferedReader(new FileReader(completablePath));
// 打开文件通道
MyReader bufferReader = new MyReader()
.setBufferedReader(bufferedReader)
.setQueues(new LinkedList<>());
readers[i] = bufferReader;
// 预读取,将数据加载到队列之中
String line = bufferedReader.readLine();
if (line != null) {
User user = MethodUtils.splitStrToUser(line, ",");
Element element = new Element(i, user);
pq.offer(element);
} else {
bufferedReader.close();
}
} catch (Exception e) {
e.printStackTrace();
}
}
//如果文件都为空直接结束方法
if (pq.isEmpty()) {
return;
}
//创建一个临时集合用于吸入缓存区
try (BufferedWriter bufferedWriter = new BufferedWriter(new FileWriter(completableTargetPath))) {
//开始遍历优先级队列
while (!pq.isEmpty()) {
Element e = pq.poll();
String userStr = MethodUtils.userToStr(e.value);
bufferedWriter.write(userStr);
bufferedWriter.newLine();
int j = e.index;
BufferedReader bufferedReader = readers[j].getBufferedReader();
String line = bufferedReader.readLine();
if (line != null) {
User user = MethodUtils.splitStrToUser(line, ",");
Element element = new Element(j, user);
pq.offer(element);
} else {
bufferedReader.close();
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
}拆分算程默认实现类
public class DefaultSplitProcess implements SplitProcess {
@Override
public void splitFile(String srcFile,String tmpPath) throws Exception {
long num = 0, current = 0, end;
try (BufferedReader reader = new BufferedReader(new FileReader(srcFile))) {
File tmpDir = new File(tmpPath);
if (!tmpDir.exists()) {
tmpDir.mkdirs();
}
String line = "";
while (line != null) {
for (int i = 0; i < 10 && line != null; i++) {
end = (num + 1) * Constants.ONCE_NUM;
BufferedWriter writer = new BufferedWriter(
new OutputStreamWriter(
Files.newOutputStream(
Paths.get(
MethodUtils.spliceStrsToPath(tmpPath, num + ".file")
)
), StandardCharsets.UTF_8
)
);
while (current <= end && (line = reader.readLine()) != null) {
writer.write(line);
writer.newLine();
current++;
}
num++;
writer.close();
}
}
}
}
}2.排序算法的模块化
我虽然自己写了一个排序算法,但是用户也可以自定排序算法,只要实现给定的接口的就可以了。
排序接口:
/**
* 策略模式
* 算程固定了,只要传入算子,就可以了。
* 如果想自定义排序算法只要新增Sort的实现类
*/
@FunctionalInterface
public interface Sort {
User[] sort(SortEnum sortEnum,User[] arr) ;
}基于Java自带排序算法的Sort实现类:
public class JavaSort implements Sort {
@Override
public User[] sort(SortEnum sortEnum, User[] arr) {
switch (sortEnum){
case ASC:
Arrays.sort(arr, Comparator.comparing(User::getId));
break;
case DESC:
Arrays.sort(arr,(a,b)->b.getId().compareTo(a.getId()));
break;
default:
break;
}
return arr;
}
}基于我开发的算法的Sort实现类(分治任务类上面已经给了):
public class DivisionSort implements Sort {
@Override
public User[] sort(SortEnum sortEnum,User[] arr) {
SortTask sortTask = new SortTask(0, arr.length - 1, arr,sortEnum);
ForkJoinPool forkJoinPool = new ForkJoinPool();
ForkJoinTask<User[]> submit = forkJoinPool.submit(sortTask);
User[] users;
try {
users = submit.get();
} catch (Exception e) {
throw new RuntimeException(e);
}
forkJoinPool.shutdown();
return users;
}
}
再来个工厂模式来获取Sort实现类,不要手动创建了
/**
* 工厂模式
*/
public class SortFactory {
private SortFactory() {
}
public static Sort getSort(Class<? extends Sort> sClass){
try {
//反射获取实现类
return sClass.newInstance();
} catch (Exception e) {
throw new RuntimeException(e);
}
}
}3.命令模式优化
在AbstractSort的子类ExternSort当中加一个内部类Operator作为命令,来封装排序算法和排序方式。
public class ExternSort extends AbstractSort {
private ExternSort(String srcFile, String targetPath, String newFileName, Operator operator) {
super(srcFile,targetPath,newFileName,operator);
}
//封装排序算法和排序方式
public static Operator setOperator(Class<? extends Sort> sClass, SortEnum sortEnum){
return new Operator(sClass,sortEnum);
}
public static class Operator{
final Sort sort;
final SortEnum sortEnum;
private Operator(Class<? extends Sort> sClass, SortEnum sortEnum) {
this.sort = SortFactory.getSort(sClass);
this.sortEnum = sortEnum;
}
public ExternSort setFileInfo(String srcFile,String targetPath,String newFileName){
return new ExternSort(srcFile,targetPath,newFileName,this);
}
public User[] sort(User[] arr){
return this.sort.sort(sortEnum,arr);
}
}
}4.具体测试
创建排序类
- 先设置命令算子,传入Sort实现类(可以自定义)和排序方式枚举
- 再设置文件信息:源文件地址,目标文件夹,新文件名称
- 可以选择是否设置自定义算程
突出一个灵活、可扩展!
public class Test {
public static void main(String[] args) {
String fileName = "XXX";
String targetPath = "XXX";
String newFileName = "XXX";
AbstractSort sort = ExternSort
.setOperator(DivisionSort.class, SortEnum.DESC)
.setFileInfo(fileName, targetPath, newFileName)
.setDeleteProcess(new DefaultDeleteProcess());
sort.sortFile();
}
}小结
这个项目虽然不大,也还有可以优化的地方,比如:可以进一步提高扩展性,实现排序类的自定义化(这个项目固定是User类),但是知识面涉及众多:算法应用、并发处理、设计模式、编程思想、开发原则。
- 算法应用:并归排序、插入排序、多路并归、混合排序等。
- 并发处理:自定义线程池、CountDownLatch、ForkJoinPool等
- 设计模式:工厂、策略、命令、模板、外观、单例等模式
- 编程思想:分治法、面向接口编程、模块化设计等
- 开发原则:单一职责原则、开闭原则、里氏替换原则、接口隔离原则等
用来纪念我成为程序员三周年!希望看到这篇文章的人能有所收获,后续我会这里放上代码的git地址。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









