









为什么需要分库分表?
在当今互联网时代,数据量呈现爆炸式增长。许多企业的核心业务系统每天产生数百万甚至上亿条数据记录。传统的单库单表架构在面对海量数据时,往往会遇到以下瓶颈:
-
性能下降:单表数据超过千万级后,查询性能明显下降
-
维护困难:备份恢复、DDL操作耗时剧增
-
可用性风险:单点故障导致整个系统不可用
-
硬件限制:单机硬件扩展存在上限
根据阿里巴巴公开的技术文档,当单表数据超过500万行时,就应考虑分库分表方案。本文将全面解析MySQL分库分表的各种策略、实现方式及最佳实践。

一、分库分表核心概念解析
1.1 水平分表(横向拆分)
定义:将同一个表的数据按照行记录拆分到多个结构相同的表中,每个表存储部分数据。
特点:
-
所有分表的Schema完全相同
-
数据分散在不同物理表中
-
常见于数据量巨大但访问模式均匀的场景
示例:用户订单表按订单ID哈希分表
order_0:存储order_id%4=0的记录
order_1:存储order_id%4=1的记录
order_2:存储order_id%4=2的记录
order_3:存储order_id%4=3的记录1.2 垂直分表(纵向拆分)
定义:将同一个表的不同字段拆分到不同的表中,通常按照字段的访问频率或业务属性划分。
特点:
-
各分表Schema不同
-
减少单表宽度,提升热点数据访问效率
-
适合字段多且有明显冷热数据区分的场景
示例:用户主表拆分
user_base:存储核心字段(id,username,mobile)
user_detail:存储详细信息(地址、教育背景等)
user_extension:存储扩展属性1.3 分库策略
定义:将表分散到不同的数据库实例中,可分为水平分库和垂直分库。
优势:
-
突破单机硬件限制
-
实现真正的物理隔离
-
提高系统整体可用性
典型场景:
-
按业务线分库(电商系统分为订单库、商品库、用户库)
-
按地域分库(华北库、华东库等)
二、七大分片策略深度剖析
2.1 哈希取模分片
原理:分片位置 = hash(分片键) % 分片数量
案例:将订单表分为8个分片
// Java代码示例
int shardIndex = Math.abs(orderId.hashCode()) % 8;
String tableName = "order_" + shardIndex;优点:
-
数据分布均匀
-
实现简单高效
缺点:
-
扩容困难(需要rehash迁移数据)
-
不支持范围查询
适用场景:离散查询为主,数据增长可预测
2.2 范围分片(Range Based)
原理:按照分片键的值范围划分
示例:用户表按注册时间分片
user_2020:注册时间在2020年的用户
user_2021:注册时间在2021年的用户
...优点:
-
易于扩容(直接增加新分片)
-
支持高效的范围查询
缺点:
-
可能产生数据倾斜(新分片数据量少)
-
需要合理设计分界点
2.3 时间分片
变种:按日/周/月/年分片
特殊考虑:
-
冷热数据分离(热数据在高速存储)
-
历史数据归档策略
电商案例:
orders_202301:2023年1月订单
orders_202302:2023年2月订单
...2.4 一致性哈希
原理:构建哈希环,数据映射到最近的节点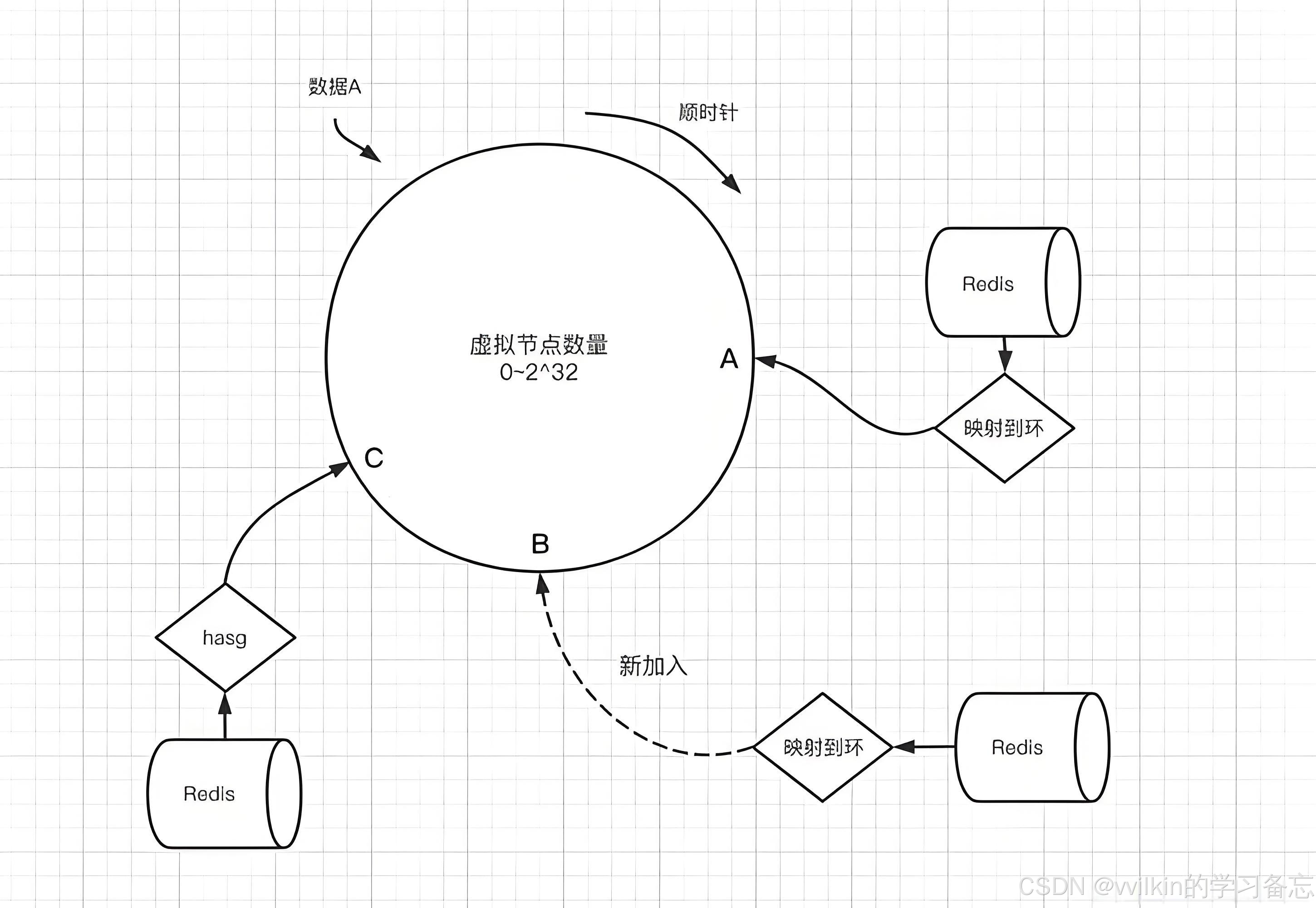
优势:
-
扩容时仅需迁移部分数据
-
节点增减影响范围小
实现:使用TreeMap实现环结构
// 伪代码示例
TreeMap<Long, String> hashRing = new TreeMap<>();
hashRing.put(hash("node1"), "node1");
hashRing.put(hash("node2"), "node2");
// 查找节点
String node = hashRing.ceilingEntry(hash(key)).getValue();2.5 目录分片(Routing Table)
原理:维护路由表记录数据位置
实现方案:
CREATE TABLE shard_routing (
biz_id VARCHAR(64) PRIMARY KEY,
db_name VARCHAR(32),
table_name VARCHAR(32),
INDEX idx_biz_id (biz_id)
);适用场景:
-
分片规则复杂多变
-
需要灵活调整分片策略
2.6 地理位置分片
特殊策略:按照地域属性分片
典型应用:
-
本地生活服务类APP
-
全球业务系统
示例:
bj_order:北京地区订单
sh_order:上海地区订单
...2.7 复合分片策略
组合方式:多维度分片键组合
案例:先按用户ID哈希再按时间范围
user_1234_orders_2023
user_1234_orders_2024三、技术实现方案对比
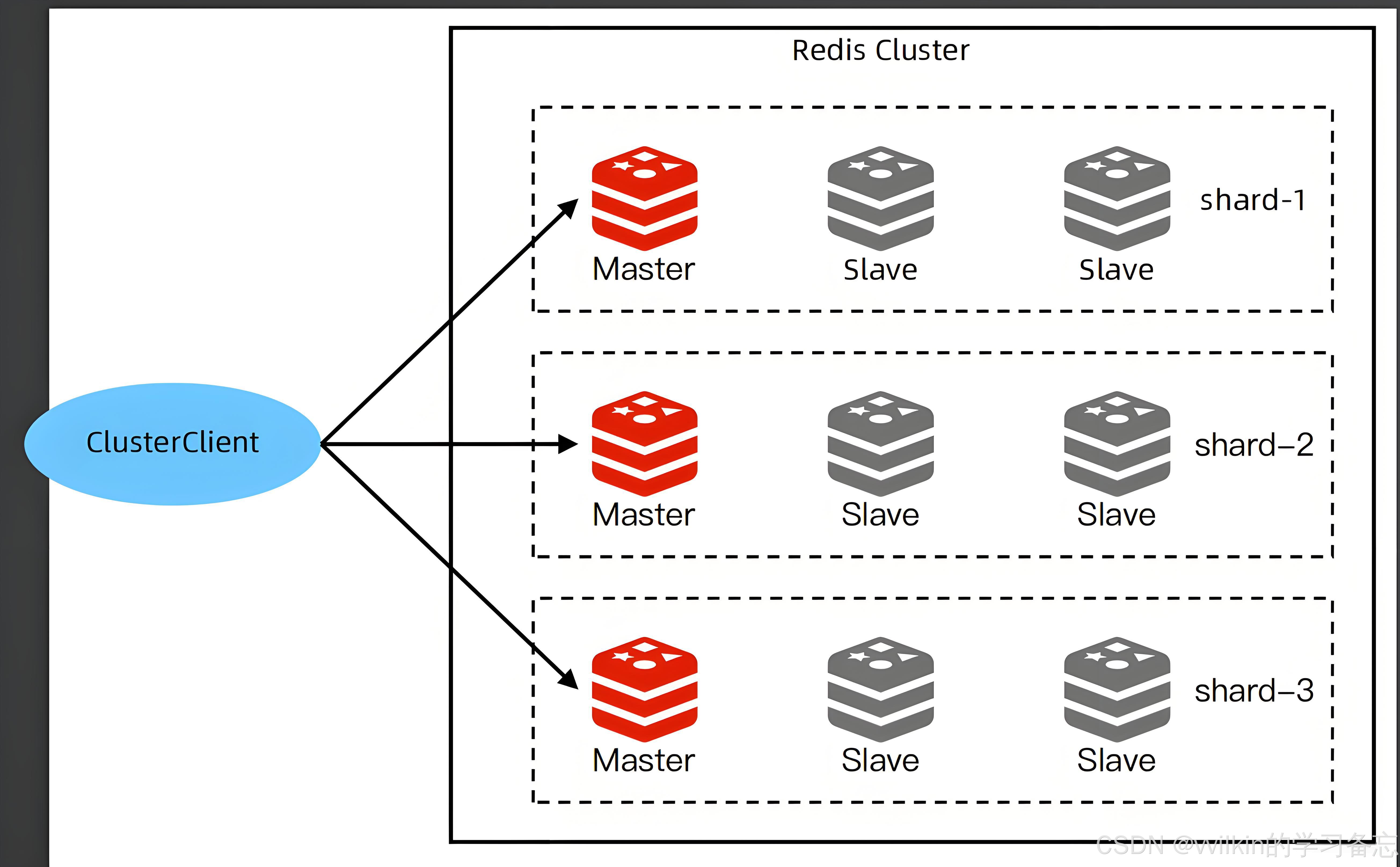
3.1 客户端分片
代表框架:
-
ShardingSphere-JDBC
-
TDDL
架构特点:
优点:
-
无额外中间件开销
-
灵活定制分片逻辑
缺点:
-
侵入业务代码
-
多语言支持困难
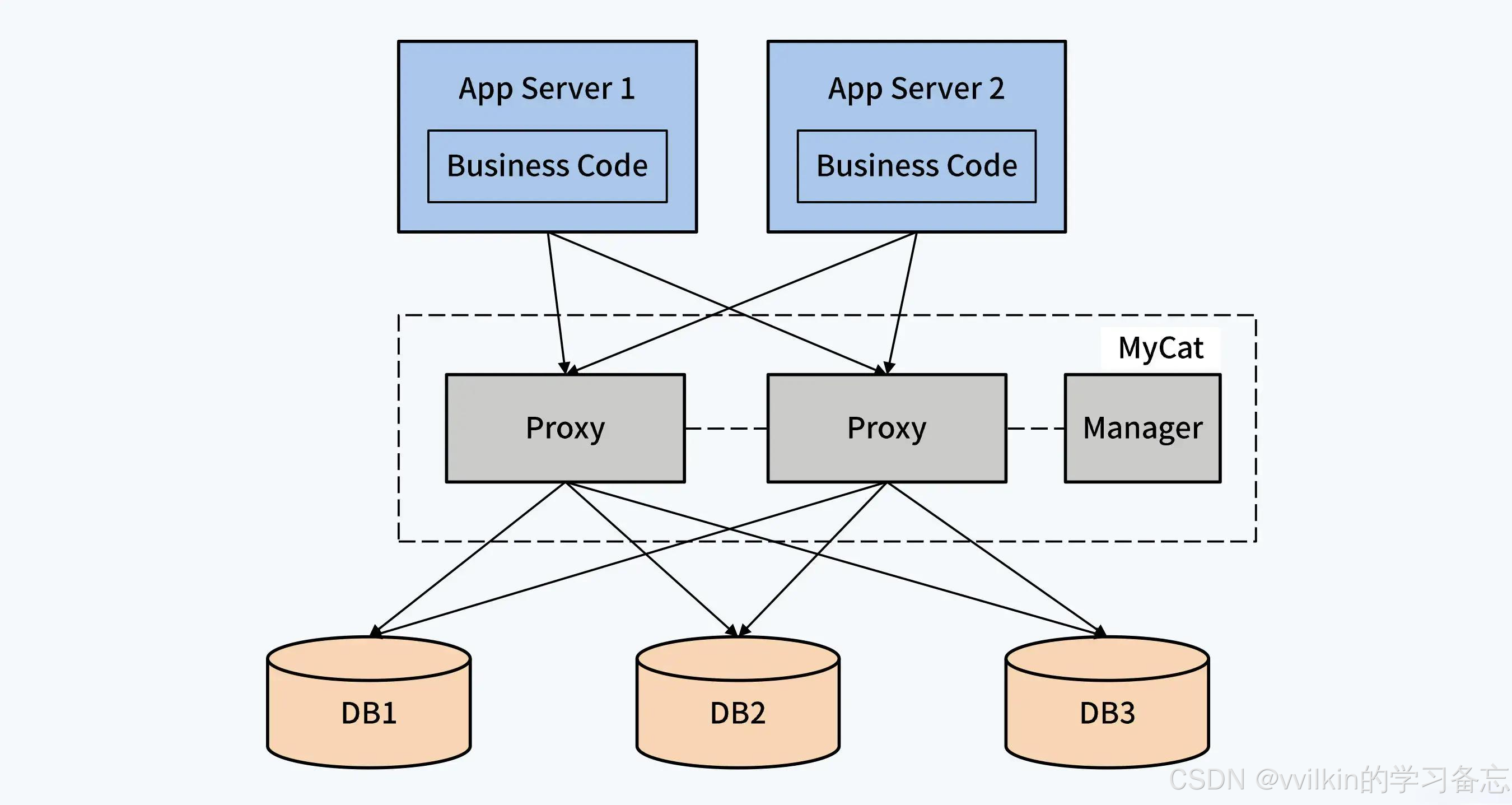
3.2 中间件代理
代表产品:
-
MyCat
-
ShardingSphere-Proxy
-
Vitess
架构特点:
优点:
-
对应用透明
-
统一管理分片规则
缺点:
-
增加网络跳数
-
存在单点风险
3.3 云数据库方案
AWS方案:
-
Aurora分片
-
DynamoDB自动分片
阿里云方案:
-
PolarDB-X
-
DRDS
特点:
-
开箱即用
-
弹性扩展能力强
-
成本较高
四、关键问题解决方案
4.1 分布式ID生成方案对比
| 方案 | 示例 | 优点 | 缺点 |
|---|---|---|---|
| UUID | 550e8400-e29b... | 简单通用 | 无序、存储空间大 |
| 数据库序列 | 自增序列 | 绝对递增 | 有性能瓶颈 |
| 雪花算法 | 1555924953000... | 趋势递增、高性能 | 时钟回拨问题 |
| Redis生成 | INCR全局键 | 高性能 | 需维护Redis集群 |
| 号段模式 | 一次获取1000个ID | 减少数据库访问 | 可能产生浪费 |
推荐方案:美团Leaf、百度UidGenerator等开源方案
4.2 跨库JOIN解决方案
-
字段冗余:将关联字段冗余到主表
-- 订单表冗余商品名称 ALTER TABLE orders ADD COLUMN product_name VARCHAR(100); -
多次查询+内存JOIN:
// 伪代码示例 List<Long> orderIds = queryOrderIds(userId); List<Order> orders = batchQueryOrders(orderIds); Map<Long, Product> products = batchQueryProducts(orders); -
使用宽表:提前关联好数据写入ES等搜索引擎
4.3 分布式事务实现
方案对比表:
| 方案 | 一致性 | 性能 | 复杂度 | 适用场景 |
|---|---|---|---|---|
| XA | 强 | 低 | 高 | 传统银行系统 |
| TCC | 最终 | 中 | 高 | 高一致性要求业务 |
| SAGA | 最终 | 高 | 中 | 长事务场景 |
| 本地消息表 | 最终 | 高 | 低 | 异步场景 |
| Seata AT | 最终 | 中高 | 中 | 云原生环境 |
五、最佳实践指南
5.1 分片键选择原则
-
高区分度:如用户ID、订单ID
-
业务相关性:常用查询条件
-
避免热点:不要使用单调递增字段
-
稳定性:值不频繁变更
反例:使用手机号作为分片键(可能因号段分布不均导致热点)
5.2 分片数量规划公式
建议分片数 = 峰值TPS / 单库承载TPS × 冗余系数(1.2-1.5)示例:
-
预估峰值TPS:10,000
-
单库承载TPS:2,000
-
计算:10,000/2,000×1.3 = 6.5 → 取8个分片(2的整数幂)
5.3 扩容方案设计
平滑扩容步骤:
-
准备新分片节点
-
配置双写策略
-
数据迁移工具同步历史数据
-
校验数据一致性
-
切换读流量
-
切换写流量
-
下线旧分片
注意事项:
-
选择业务低峰期操作
-
准备回滚方案
-
监控关键指标
六、未来演进方向
-
NewSQL架构:TiDB、CockroachDB等分布式数据库
-
Serverless数据库:自动弹性伸缩
-
云原生分片方案:与K8s深度集成
-
AI驱动的自动分片:动态调整分片策略
结语
分库分表是应对海量数据的高阶解决方案,需要根据业务特点选择合适策略。理想的架构应该:
-
满足未来3-5年的业务增长
-
保持合理的复杂度
-
预留扩展空间
-
具备完善的监控体系
记住:没有完美的分片方案,只有最适合业务现状的权衡选择。希望本文能为您的分库分表实践提供全面指导。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









