





Chapter 3.1 HISTORY, OLDERARCHITECTURES, AND
TECHNOLOGYEVOLUTION
在现代计算机体系结构中,主存通常由DRAM芯片构成。处理器在一个独立的芯片上,当处理器需要从内存中获取数据时,数据在处理器和存储芯片之间的互连(interconnection)上传输。互连通常作为限制带宽的数据总线来实现,从而限制了数据传输速率。与此同时,处理器的速度一直在稳步提高。因此,处理器与内存之间的数据传输已经成为访问大量内存数据的应用程序的性能瓶颈。
因此,以一种更快的方式在DRAM和处理器之间移动数据可以改善系统性能。早期对near-DRAM处理的探索(1970 - 90年代)就是受到这个想法的启发。一种常见的解决方案是将处理器和DRAM集成到同一块芯片上,用片上(inter-chip)数据移动代替片间通信(on-chip data movement)。图3.1显示了处理器和DRAM集成在一起的典型系统结构。Near-dram处理系统主要由标量处理系统、存储系统和向量处理单元组成。标量处理系统仍然具有与CPU相似的结构,即处理器核(processor core)和cache系统。memory接口单元与高速缓存系统和DRAM模块交互,作为实现近DRAM处理的桥梁。为了充分利用集成DRAM的高带宽,向量处理单元被放置来执行数据并行操作。向量处理单元有自己的向量寄存器和向量运算单元,并与存储器接口单元交互以访问存储的数据。由于向量寄存器具有较宽的数据宽度,向量处理自然会受益于增加的内存带宽。内存系统本身由多个DRAM模块组成。它设计了比普通DRAM芯片更宽的I/O接口,以获得更高的聚合数据带宽(aggregated data bandwidth)来服务于处理系统。在运行时,处理器的工作方式与正常系统类似,只是当需要从内存中获取数据时,它们直接通过片上接口传输。
上述NMP系统产生了多重优势。首先,内存带宽显著增加,因为外部内存数据总线不再是瓶颈。其次,内存访问的延迟也更短,因为可以消除外部数据总线中的较长线延迟。最后,系统的能效也得到了提高,因为片上数据移动比片外数据总线消耗更少的能量。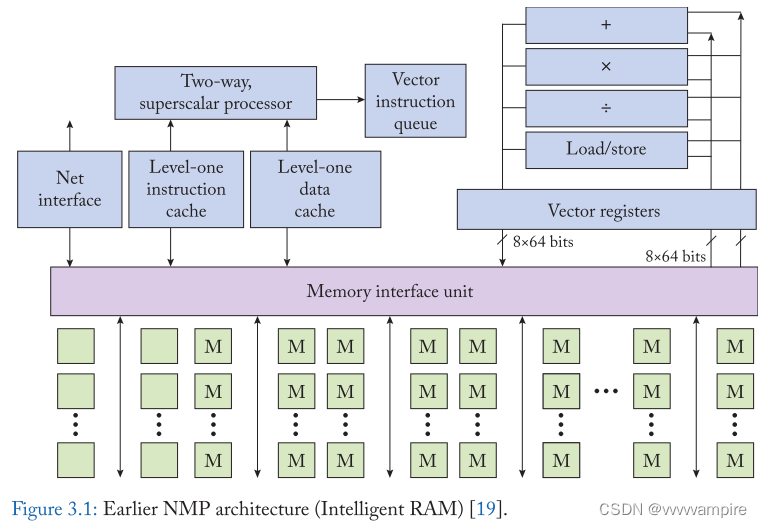
上述NMP设计的主要缺点是,这种集成处理器的性能比独立的芯片中的普通处理器要差。这是因为该处理器是与DRAM的process 实现集成在同一芯片。处理器的逻辑电路和SRAM阵列在用DRAM工艺实现时都比较慢,因为DRAM工艺是针对内存成本和能源而优化的,但不是针对逻辑速度而优化的。此外,in-DRAM逻辑只能访问在DRAM过程中使用的2-3个金属层; 即使是简单的逻辑电路也会比通常的电路占用更大。文献中已经探讨了上述NMP设计的许多变化。例如,已经为集成处理器NMP系统提出了简单的有序和定制的处理元件。这些NMP设计也可以根据处理元件与DRAM阵列的接近程度来进行分类。下面我们将更详细地讨论这两种设计方案:
Variations Based on Processing Element Complexity:
在上述的NMP系统中,有几种不同处理器的备选设计。首先,集成处理器系统可以用更简单的处理器(例如,顺序流水线内核 in-order pipelined cores)代替,以节省面积和降低设计复杂性。其次,对于特定于应用程序的设计,可以使用具有定制结构的处理元件来代替通用的标量和向量处理器。例如,cache系统可以替换为应用程序特定的数据缓冲区,ALU可以针对特定的操作集进行优化。
Variations Based on Proximity of Processing Elements to Memory Cells
另一系列的变化是将处理元件移到更靠近memory cells的位置。上面描述的主要设计有独立的处理器和内存单元。为了更紧密地整合处理元件与内存,有设计将处理元件放在独立的DRAM array附近(put the processing elements near the individual DRAM arrays),甚至与每一个memory cell紧密耦合。由于处理元件必须具有有限的大小和复杂性以便更密集地分布,因此它们通常是为特定的应用程序设计的。
(1)Processing elements near DRAM arrays:
更简单的处理元件可以集成到DRAM阵列的外围。例如,PE可能由几个寄存器和一个简单的可重构查找表组成。查找表的输入是来自DRAM阵列和寄存器的几个bits。PE结果可以直接写回DRAM阵列,或存储在寄存器中以备将来的操作。为了处理大宽度的数据,PE可以迭代处理数据的不同部分。在整个计算过程中,主机CPU通过向PE发送指令来控制执行。
(2)Processing elements coupled with DRAM cells:
处理元件也可以作为存储单元的一部分集成到DRAM阵列中]。这里的处理元件通常只包含几个逻辑门,以避免过多的面积成本。逻辑门是根据应用需求设计的。为了实现阵列中不同单元数据的协同处理,部署了阵列内(in-array)数据传输系统,每个cell可以将其数据值传输到相邻的cell(以降低互连的复杂性)。通过执行一系列的single-cell计算和in-array的数据移动,一个操作由array中的所有cells共同完成。如果应用程序需要更复杂的处理,可以将算术单元等附加逻辑置于array之外以辅助计算。综上所述,PE-memory混合阵列可以实现高数据并行性和PE与数据存储之间的极短距离。然而,考虑到逻辑门的有限数量和阵列内数据移动的困难,它们缺乏计算通用性。定制的存储单元也导致了高度的设计复杂性。更重要的是,当它们在DRAM进程中实现时逻辑性能也会下降。
Chapter 3.2 3D STACKED DRAM AND 3D NMP ARCHITECTURES
在20世纪90年代,near-DRAM的处理设计并没有蓬勃发展,主要是因为很难将cost/power-aware的DRAM和performance-aware的计算逻辑集成在同一个芯片上。随着大数据分析等现代数据密集型应用对更高内存带宽的需求,3D堆叠内存作为一项新技术应运而生。
三维堆叠存储器是由多个异构的二维晶粒相互堆叠而成的三维集成电路。每个2D晶粒成为3D堆栈中的一个层。大多数层是内存层,其中晶粒是由dram模块构建的。堆栈底层主要由控制逻辑组成,因此称为逻辑层。垂直方向上,晶粒与通硅通孔(TSV)和微凸块相互连接。通过这种垂直通信,整体上减少了数据的传输距离,从而提高了延迟时间和能量效率。由于DRAM和逻辑建立在分离的晶粒上,他们可以使用不同的晶体管技术。因此,逻辑层可以继续实现高性能,而内存层优化成本和功效。这标志着3D堆叠DRAM对于NMP的一个关键优势:在之前的工作中,计算逻辑和内存集成在同一个晶粒上,逻辑需要用DRAM技术来构建,因此性能降低。在3D堆叠内存中,所有对性能至关重要的DRAM控制逻辑都被移动到逻辑层。逻辑层负责生成访问DRAM的命令。此外,到主机的接口也在逻辑层中实现。与传统的DRAM相比,主机处理器发送的命令被简化,将管理留给高性能的逻辑层。
控制器和DRAM阵列之间的数据通信是在垂直切片中管理的。堆叠的内存和逻辑层的立方体被垂直地划分为多个slice,每个slice由矩形的晶粒区域组成,每层有一个。这种垂直的部分也称为vault。逻辑层中的vault内存控制器负责访问同一个vault中的数据。全局内存控制器协调vault控制器访问不同vault中的数据,并在逻辑层进行通信。与主机处理器的接口,以及与其他3D存储芯片的接口,也在逻辑层实现。与传统DRAM相比,主机与3D DRAM之间的通信协议被简化了,因为DRAM的时序规范是在逻辑层管理的。根据使用场景的不同,3D DRAM芯片之间的互连可以有不同的拓扑结构。当dram芯片数量较少时,适合采用带主机处理器的daisy chain;否则,DRAM芯片以2D-mesh结构连接,主机处理器连接网关DRAM芯片。
3d堆叠内存的两个主要例子是混合内存立方体(Hybrid Memory Cube HMC)[27]和高带宽内存(High-Bandwidth Memory HBM)[28]。它们是由不同的实体开发和标准化的,但它们具有如上所述的类似设计。HMC体系结构如图3.2所示,其中各层使用三维堆叠结构,各控制模块位于逻辑层。HMC和HBM之间的一个主要区别是到主机处理器的接口: HMC 采用packet-based的串行链路,更适合CPU主机,便于编程和控制。与此相反,HBM通过具有并行链路的silicon interposers与主机处理器进行通信,因此在并行度较高的GPU处理器中得到了更广泛的应用。
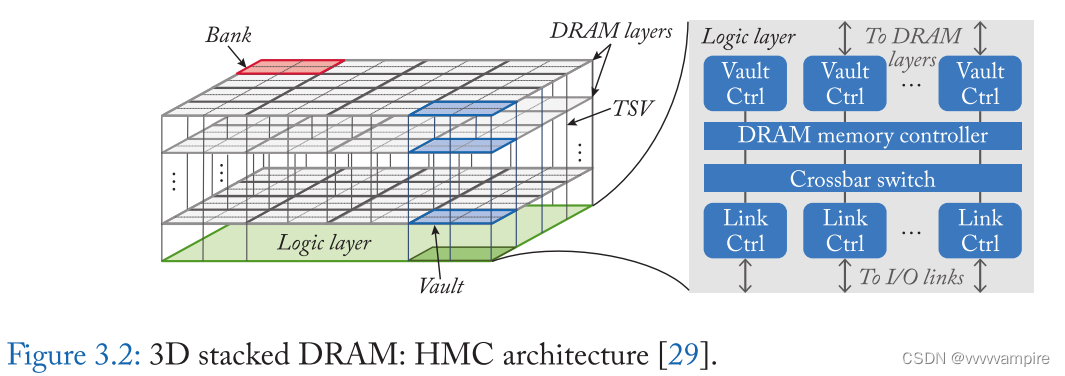
3D堆叠DRAM解决了早期NMP设计在集成逻辑和DRAM工艺方面遇到的挑战,因为DRAM和逻辑现在是在独立的晶粒中。因此,许多near-dram处理的设计受到启发,瞄准数据密集型应用领域,如数据分析、图形处理和深度学习。
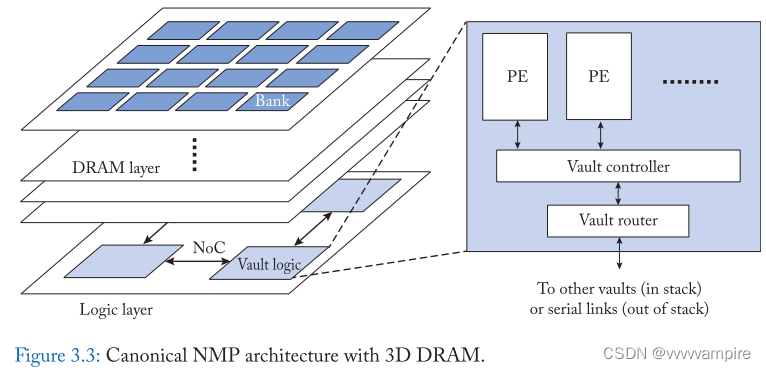
3D DRAM为近内存处理提供了一个有效的基础。逻辑层采用高速的逻辑处理实现,因此任何NMP逻辑都可以在这里实例化。同时,由于三维堆叠结构,逻辑层可以与TSV中数据传输速率高的DRAM模块进行通信。
图3.3显示了使用3d堆叠DRAM的近内存处理的标准架构。处理元件(PEs)通常集成在cube的逻辑层中。PE结构是特定于应用程序的。许多PE由算术单元和SRAM中的数据缓冲区组成。PE通过同样位于逻辑层的内存接口访问内存数据。由于整个cube被划分为vaults,所以在每个vault中放置相同的PE。每个PE都可以通过TSV直接访问同一个vault中的内存数据。在逻辑层有一个用于交换数据的所有PE的互连。PE也可以通过互联来访问其他vault中的内存数据。通常为互连选择具有网格拓扑的片上网络(NoC),因为这与vaults的分布相匹配。
现在,我们将讨论使用3D DRAM的上述标准NMP架构的一些变化。大体上,这些变化可以根据主机上执行的计算量、主机与3D DRAM的距离以及逻辑层中应用于PE的特定应用程序来分类:
(1)Variations Based on Interface with Host:在3D DRAM的这种近内存处理架构中,由于具有计算能力的3D DRAM通常被视为加速器或协处理器[34],主机处理器负责发送近内存处理指令。此外,在一些应用中,主机处理器在数据密集程度较低但计算复杂度较高的部分也参与计算。典型的加速应用包括大数据分析[35,36]、图处理[37]、数据重组[29]和神经网络[38-40]。另一方面,3D DRAM也可以与主机处理器进行更紧密的集成,而不是充当独立的存储设备[41]。例如,3D DRAM可以作为内存系统的一部分,主机可以决定是使用传统的内存操作还是使用近内存处理来运行指令。这样的系统需要对缓存一致性(cache coherence)、指令集扩展(instruction set extensions)以及主机处理器和PE的并发访问[43]提供额外的支持。
(2)Variations Based on PE Architecture:除了特定应用程序的加速器外,PE可以有多种形式。例如,一组通用的CPU和GPU核可以放在PEs[44]中,从而简化了编程,降低了设计的复杂性。PE可以由计算单元(computing units)的可重构阵列(freconfigurable arrays)组成,以创建灵活的近内存加速器。PE可以应用各种性能优化。例如,硬件预取器(hardware prefetchers)可以集成到PE中,以便更好地利用内存带宽[37]。
优点与缺点:在3D DRAM的近内存处理中,PEs是在高性能的逻辑处理节点上实现的,因此没有性能下降。3D DRAM的整体性能也得益于延迟和内存带宽的改善。与所有的近内存处理设计一样,内存和处理器之间的数据移动被有效地减少了,从而节约了能源。这样的设计也有改进的空间。虽然数据在接近DRAM处进行处理,但访问DRAM模块的次数仍然没有减少。此外,当一个操作涉及到来自遥远位置(在不同的vaults中)的数据时,数据在被处理之前仍然会产生远程传输开销。
Chapter 3.3 COMMERCIALNEAR-DRAMCOMPUTINGCHIPS
最近,UPMEM在生产的芯片上实现了near-dram计算的思想。计算单元是在DRAM process中靠近memory array的地方实现的。每个64MB的DRAM阵列与一个处理单元配对,以500MHZ的频率运行,有14级流水线和24个硬件线程。每个DRAM芯片包含一个控制器,通过DMA操作在DRAM阵列和处理单元之间协调数据传输。有和指令和工作数据相关的SRAM缓冲区。计算单元支持类似于RISC的ISA,包括整数算术、逻辑运算和分支指令。一个特殊的编译器将C代码映射到近DRAM计算单元上以减轻部分计算量。总的来说,该芯片实现了接近DRAM计算的高内存带宽,可用于DNA测序、数据分析、稀疏矩阵乘法、图搜索等广泛的应用加速。
HBM-PIM[15]是基于HBM2 DRAM的近内存处理的最新工业原型。他们的主要想法是将可编程计算单元集成到存储器附近的DRAM die中。这种计算单元可以对DRAM数据进行近内存计算,因此无需将数据传输到逻辑die上。计算单元被放置在存储单元阵列的相邻位置,并且两个存储bank共享一个计算单元。多个bank的计算单元可以同时工作,以提高整体吞吐量。每个计算单元由指令解码器、运算单元、标量和向量寄存器文件以及处理常规DRAM和特定控制信号的接口组成。运算单元支持浮点加法和乘法运算,向量寄存器文件将256-bit的entries存储为操作数,而标量寄存器文件用于控制信息。在HBM-PIM中,传统的内存控制器没有修改,而是专门设计了一个计算控制器来管理计算单元。当发起近内存计算时,主机会发送一个指定行地址的行激活命令。然后指令序列被送到计算单元执行。完成后,计算单元的结果将从向量寄存器写入memory cell arrays。HBM-PIM的主要优点是结合了HBM提供的高内存带宽和外部逻辑,以及DRAM die 内的处理单元提供的高内部计算吞吐量。这样的体系结构可以用于需要大内存占用和显露高水平并行性的应用程序,比如使用大量参数的机器学习模型。例如,HBM-PIM实现了语音识别基准的显著性能改进和能量降低。
Pitfall:近内存计算可以显著降低数据移动成本。这并不完全正确,因为以下原因。
•大量的能量被互连所消耗,它将数据从memory subarray内部传输到I/O。例如,HBM2的DRAM行激活需要0.11 pJ/bit (909 pJ/row),而在50%切换速率[46]时,数据移动和I/O需要3.48 pJ/bit。数据移动成本包括pre-GSA (Global Sense Amplifier)的数据移动成本(43%)、post-GSA的数据移动成本(34%)和I/O成本(23%)。无论是内存计算还是近内存计算都无法避免数据的行激活开销和pre-GSA的数据移动开销。虽然In-memory计算可以节省post-GSA的大部分数据移动成本和I/O成本,但近内存计算只能降低I/O成本,除非它被放置在非常靠近内存阵列的位置。
•对于sram cache,数据移动的能耗是1985 pJ,而缓存访问的能耗是467 pJ (L3 slice)[10]。因此,H-Tree,也就是用于缓存片内数据传输的互连线,在从一个2MB的L3缓存片读取数据时,会消耗将近80%的缓存能量。In-memory计算可以降低大部分的数据传输成本,而SRAM slice附近的近内存计算则不能。
•近内存计算的saving根据近内存计算逻辑与存储阵列的接近程度而变化。虽然逻辑和存储阵列的紧密耦合也可以为数据移动到近内存计算提供最大的成本节省,但从内存密度和处理技术等其他方面来看,它可能不是最优和经济的。
•近内存计算可以减少从内存获取数据的延迟。然而,降低的通信开销通常被降低的计算吞吐量所抵消,这是由于性能较差的内核或面积有限的定制逻辑具有足够的并行性和吞吐量。
Chapter3.4 IN-DRAMCOMPUTINGANDCHARGESHARING TECHNIQUES
虽然有大量的工作在探索使用DRAM的近内存计算,包括3D堆叠内存(上一节)和bit-serial 的ALU连接到每个位线或感测放大器[47,48],但它没有修改DRAM阵列的计算。基于dram的内存计算有几个已知的障碍。例如,在DRAM substrate中有足够数量的逻辑电路并不总是实际的,因为它可能导致低密度。计算吞吐量也可能受到数据路径宽度的限制。本节探讨电荷共享(charge sharing)技术,这是基于dram的内存计算的关键实现技术之一。电荷共享(charge-sharing)技术通过利用连接到同一位线的电容器中的改变电荷(altered charges)来激活多个字线并执行位操作。因此,它可以以较小的面积成本提供一些重要的逻辑运算。我们提出了一个典型的DRAM读取操作序列,遵循Ambit[49,50]的三行激活(triple row activation TRA)原则,这是一种引入电荷共享技术的典型的in-DRAM计算工作。然后,我们讨论了一些相关的工作,以提高charge-sharing技术,以降低成本和/或更多支持的操作。
1 DRAMREADSEQUENCEANDTRIPLEROWACTIVATION
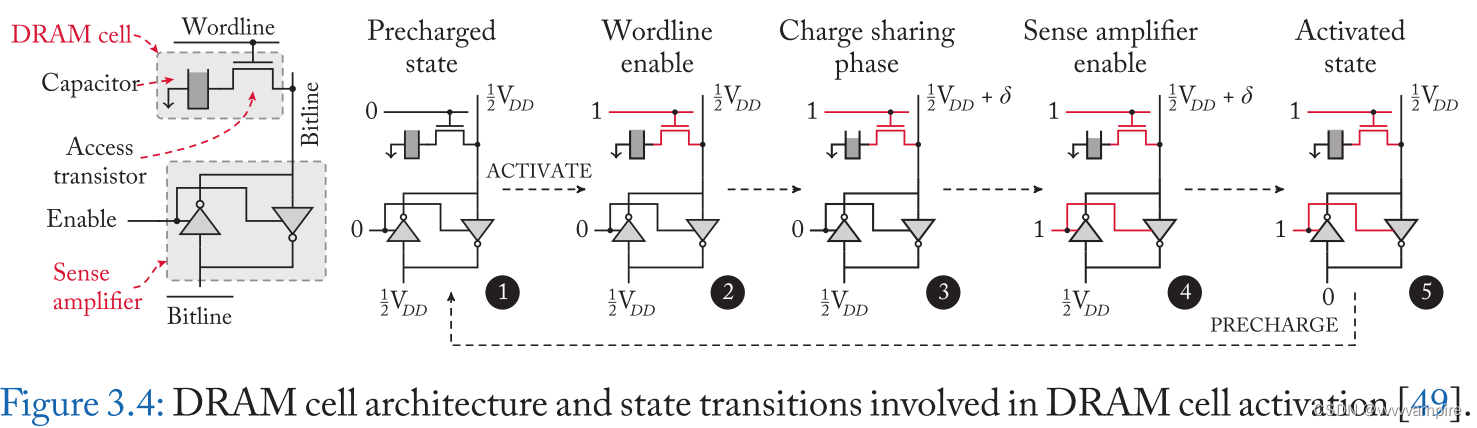
DRAM的正常读操作如图3.4所示:
- bitline和
都被预充电到1/2 VDD
- ACTIVATE命令arise一个wordline。如果电容器充满电,电荷从电容流向位线
- 位线观察到一个正偏差的电压level
,即1/2VDD +
- 感测放大器感知位线与
- 感测放大器驱动位线,如果偏差为正,则对电容充满电。
Ambit[49, 50]提出了基于电荷共享的AND与OR操作。Ambit同时激活三个字线(称为triple-row activation or TRA),如图3.5所示。基于电荷共享原则[51],激活多行时位线偏差 计算为:
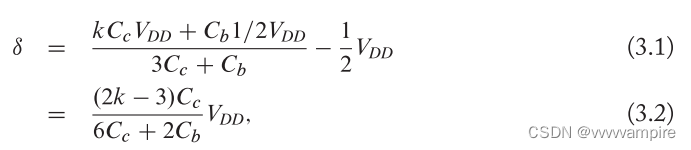
式中,为单元电容,
为位线电容,k为充满电状态的cell数。我们假设一个理想的电容器(无电容变化,完全刷新),晶体管和位线行为(无电阻)。根据式(3.2),位线偏移为正(感知为1)如果k=2,3和负(感知为0)如果k=0,1。 因此,如果在电荷共享之前至少有两个充满电的单元,则感知VDD,并且由于感知放大器驱动位线到VDD,所有三个单元都将充满电。否则,他们将被释放到0。
TRA的行为与3-input majority gate相同。给定A、B、C代表三个cell的逻辑值,计算AB+CB+CA,将其转化为C(A+B)+ (A+B)。因此,通过控制C, TRA可以执行AND (C=0)和OR (C=1)。Ambit还支持在一个附加晶体管的单元中进行NOT操作,这使得电容可以连接到图3.6中的
。AND和NOT可以组合成一个功能完备的运算符NAND。因此,Ambit可以支持任何逻辑操作。图3.7显示了执行每个布尔运算所需的命令序列
2.ADDRESSINGTHECHALLENGES OFCHARGESHARING TECHNIQUES
基于TRA的电荷共享技术可以通过对DRAM结构的微小修改实现批量的DRAM内逻辑操作。然而,它也面临以下挑战。
- 定制的行译码器和命令序列:需要定制外设电路和内存控制器接口来进行TRA操作。
- 受限操作:仅TRA支持的操作类型仅限于AND和OR。NOT和其他操作需要一个额外的电路。它还需要多个TRA操作来构造non-native的逻辑操作(如异或),从而导致很大的延迟。
- 电荷变化的敏感性:cell中残留的初始电荷和操作期间的放电可能会危及TRA的准确性。
- 破坏性操作:电荷共享后,cell内容被覆盖。复制操作需要保留原始数据。
在本节中,我们将介绍一些解决这些挑战的工作。
SupportingCharge SharingWithout Circuit Modification : ComputeDRAM[52]证明了未修改的现成的商业dram可以执行基于电荷共享的计算。他们通过操作命令序列违反名义上的时序规范,并通过快速连续激活多行,来激活一个DRAM子阵列的多个字线,如图3.8所示。他们发现由PRECHARGE命令插入的多个ACTIVATE命令可以在一个电荷共享可能的时间框架内激活多行。图3.9显示了他们执行AND/OR操作的方案。虽然他们的方案不支持NOT操作,但他们通过将反数据和原始数据一起存储来解决这个问题。并不是所有的DRAM芯片都支持通过操作命令序列来电荷共享,也不是所有的列都能得到想要的计算结果。但是,他们的研究结果表明,只要对DRAM DIMM进行最小或不做任何硬件改变,就可以稳定地支持基于电荷共享的DRAM计算。
Supporting More Operations:DRISA[53]提出了一种1T1C-based IM-P computing计算和3T1C-based IM-A计算架构(图3.10)。DRISA-1T1C使用Ambit的电荷共享技术[50]来计算AND和OR,并通过在阵列外围设备上添加锁存器和逻辑门来补充它们。DRISA-3T1C改变了标准DRAM单元,并在cell中执行计算,而不添加其他逻辑。该cell包括两个独立的读/写访问晶体管和一个额外的晶体管将电容与位线解耦。这个额外的晶体管在位线上以NOR样式连接cell,提供了自然执行NOR操作的能力。DRISA还建议在阵列外围设备上增加一个移位电路,以支持使用存进位(carry-save)加法器进行位并行(bit-parallel addition)的加法。
Addressing Charge Variance and Latency:虽然基于电荷共享的技术能够以最小的硬件修改实现in-dram计算,但其缺点之一是剩余在cell中的初始电荷可能危及TRA的准确性[554,55]。为了提高精度,Ambit将两个操作数复制到靠近感测放大器的底部行,以保持完全带电状态。这种复制操作对于保护原始数据不被破坏性的基于电荷共享的计算所损害也是必不可少的。Ambit还需要在TRA之前向第三个cell写入1/0来定义OR/AND操作。虽然Ambit在感测放大器附近保留了一些指定的行用于计算,以减少复制操作的数量,但它仍然需要non-trivial 的周期来处理复杂的布尔操作(例如,执行XOR和XNOR需要7个周期,and需要4个周期)。
ROC[56]利用与电容器连接的二极管的特性,采用了一种不同的电荷共享方法来进一步减少逻辑操作的延迟。如图3.11a所示,无论C cell的初始状态如何,如果晶体管连接到VDD,则C cell充电到1。同样地,如果晶体管连接到地,D将被放电到0。因此,C和D的电流是单向的,这使得cell C和D的行为分别类似于或门和与门。例如,执行X+Y, X的内容被复制到C,然后Y被复制到D。如果Y为0,C的值仍然是X的值;否则,C设为1。要执行AND操作,首先将X复制到D,然后将Y复制到C。只有当X和Y都为1时,D才为1。ROC比Ambit有更小的延迟,因为它只需要两次复制操作来计算结果。由于ROC在计算过程中只需要两个cell,所以所需要的面积也更小。为了功能完备的运算符操作,ROC在一列的底部附加一个接入晶体管(access transistor)(图3.11b),类似于Ambit。他们还提出了一种增强的ROC设计,通过添加额外的晶体管和计算电容的水平连接来支持传播和移位(propagation and shifts)。ROC通过同时进行复制和计算,可以减少计算周期 (例如XOR为4个周期,AND为2个周期),避免由于初始电荷停留在单元中而导致数据损坏和结果不稳定。
3.DISCUSSION
传统DRAM市场已经非常成熟,下一代将会出现高带宽的堆叠存储器和具有计算能力的DRAM。为了保持DRAM技术的核心竞争力--密度、速度和稳定性,潜在的内存架构候选不应该对重新设计和重新验证经过几十年生产而成熟的DRAM技术构成巨大挑战。我们推测,cell设计的剧烈变化(如IM-A结构)从这个角度来看可能是不实际的。还有一个挑战是如何确保内存方法在不同的across process corners(1)和温度下工作。通常情况下,考虑到across process corners和温度,DRAM是没有余量的;因此,在典型条件下工作的in-memory方法在实际情况下不会有效果,需要做一些权衡(例如,增加电容大小或减少刷新时间)。尽管如此,最近的研究发现,只要对外围设备和/或命令序列进行微小的修改,就可以将dram转换为in-memory计算设备。随着这些操作在关键工作负载中令人信服的使用案例和编程模型的发展,我们设想这些内存技术应该在商业DRAM市场上获得更多的关注。
注:
1.工艺角(Process Corner)
与双极晶体管不同,在不同的晶片之间以及在不同的批次之间,MOSFETs 参数变化很 大。为了在一定程度上减轻电路设计任务的困难,工艺工程师们要保证器件的性能在某 个范围内。 如果超过这个范围,就将这颗IC报废了,通过这种方式来保证IC的良率。
传统上,提供给设计师的性能范围只适用于数字电路并以“工艺角”(Process Corners)的形式给出。其思想是:把NMOS和PMOS晶体管的速度波动范围限制在由四个角所确定的矩形内。这四个角分别是:快NFET和快PFET,慢NFET和慢PFET,快NFET和慢PFET,慢NFET和快PFET。例如,具有较薄的栅氧、较低阈值电压的晶体管,就落在快角附近。从晶片中提取与每一个角相对应的器件模型时,片上NMOS和PMOS的测试结构显示出不同的门延迟,而这些角的实际选取是为了得到可接受的成品率。因此,只有满足这些性能的指标的晶片才认为是合格的。在各种工艺角和极限温度条件下对电路进行仿真是决定成品率的基础。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









