







前言
数据的价值是有实效性的,一般实时性越高的信息,参考价值越大。
所以数据在对外提供服务的时候,也不是等价的,比如最近3个月的交易记录,用户会查询的比较频繁,那么应该存放在读写性能比较好的节点上。而3年前的交易记录,可以存放在读写性能一般的节点上。
ES中的索引生命周期管理ILM机制可以帮助我们轻松实现数据的冷热分层。
一、创建生命周期管理策略
说明:创建名为my-lifecycle-policy的索引生命周期策略。
该策略定义了索引生命周期的5个阶段,hot->warm->cold->frozen->delete。
(注意并不是所有的策略都要包含这5个阶段,这里主要是为了介绍数据冷热分层。)
hot阶段:
- min_age属性没有配置,默认值为0ms,也就是数据添加后立刻进去hot阶段。
- actions配置索引数据进入hot阶段触发的行为
- rollover配置索引滚动的条件,主分片体积达到50gb触发索引滚动。
warm阶段:
- min_age属性值为30d,表示当发送滚动30天后,索引数据进入warm阶段。
- actions配置索引数据进入hot阶段触发的行为
- shrink 压缩分片数量
- forcemerge 合并段segments数量
cold阶段:
- min_age属性值为60d,表示当索引数据进入warm阶段后60天会进入cold阶段。
- actions配置索引数据进入hot阶段触发的行为
- searchable_snapshot 生成可搜索快照
frozen阶段:
- min_age属性值为90d,表示当索引数据进入cold阶段后90天后会进入frozen阶段。
- actions配置索引数据进入hot阶段触发的行为
- searchable_snapshot 生成可搜索快照
delete阶段:
- min_age属性值为735d,表示当索引数据进入frozen阶段后735天后会进入delete阶段。
- actions配置索引数据进入hot阶段触发的行为
- delete 删除索引
PUT _ilm/policy/my-lifecycle-policy
{
"policy": {
"phases": {
"hot": {
"actions": {
"rollover": {
"max_primary_shard_size": "50gb"
}
}
},
"warm": {
"min_age": "30d",
"actions": {
"shrink": {
"number_of_shards": 1
},
"forcemerge": {
"max_num_segments": 1
}
}
},
"cold": {
"min_age": "60d",
"actions": {
"searchable_snapshot": {
"snapshot_repository": "found-snapshots"
}
}
},
"frozen": {
"min_age": "90d",
"actions": {
"searchable_snapshot": {
"snapshot_repository": "found-snapshots"
}
}
},
"delete": {
"min_age": "735d",
"actions": {
"delete": {}
}
}
}
}
}
二、创建内容模板
1、创建mappings内容模板
主要是为了声明索引中的字段名和数据类型,如果是为数据流声明的内容模板,则必须含有@timestamp字段。
PUT _component_template/my-mappings
{
"template": {
"mappings": {
"properties": {
"@timestamp": {
"type": "date",
"format": "date_optional_time||epoch_millis"
},
"message": {
"type": "wildcard"
}
}
}
},
"_meta": {
"description": "Mappings for @timestamp and message fields",
"my-custom-meta-field": "More arbitrary metadata"
}
}
2、创建settings内容模板
说明:
核心是在settings中指定索引生命周期名称index.lifecycle.name。
PUT _component_template/my-settings
{
"template": {
"settings": {
"index.lifecycle.name": "my-lifecycle-policy"
}
},
"_meta": {
"description": "Settings for ILM",
"my-custom-meta-field": "More arbitrary metadata"
}
}
三、创建索引模板
通过内容模板创建索引模板。
PUT _index_template/my-index-template
{
"index_patterns": ["my-data-stream*"],
"data_stream": { },
"composed_of": [ "my-mappings", "my-settings" ],
"priority": 500,
"_meta": {
"description": "Template for my time series data",
"my-custom-meta-field": "More arbitrary metadata"
}
}
参数说明:
index_patterns 指定匹配的索引模式,即如果索引名称和index_patterns中的配置项匹配,则将该模板属性运用到索引中。
data_stream 声明是数据流。
composed_of 有哪些内容组成,配置内容模板component_template。
priority 优先级
_meta 原数据信息,用户自己配置的额外属性。
也可以不使用内容模板,直接通过template属性配置索引模板:
PUT _index_template/my-index-template
{
"index_patterns": ["my-data-stream*"],
"data_stream": { },
"template": {
"settings": {
"index.lifecycle.name": "my-lifecycle-policy"
},
"mappings": {
"properties": {
"@timestamp": {
"type": "date",
"format": "date_optional_time||epoch_millis"
},
"message": {
"type": "wildcard"
}
}
}
},
"priority": 500,
"_meta": {
"description": "Template for my time series data",
"my-custom-meta-field": "More arbitrary metadata"
}
}
四、创建数据流
方式一:创建数据流,并批量添加数据
PUT my-data-stream/_bulk
{ "create":{ } }
{ "@timestamp": "2099-05-06T16:21:15.000Z", "message": "192.0.2.42 - - [06/May/2099:16:21:15 +0000] \"GET /images/bg.jpg HTTP/1.0\" 200 24736" }
{ "create":{ } }
{ "@timestamp": "2099-05-06T16:25:42.000Z", "message": "192.0.2.255 - - [06/May/2099:16:25:42 +0000] \"GET /favicon.ico HTTP/1.0\" 200 3638" }
方式二:创建数据流,并添加单条数据
POST my-data-stream/_doc
{
"@timestamp": "2099-05-06T16:21:15.000Z",
"message": "192.0.2.42 - - [06/May/2099:16:21:15 +0000] \"GET /images/bg.jpg HTTP/1.0\" 200 24736"
}
方式三:仅创建数据流,不添加数据
PUT _data_stream/my-data-stream
注意⚠️:
1、添加的数据中必须含有@timestamp字段信息
2、创建的数据流名称必须和声明的索引模板中的索引模式index_patterns相匹配。
五、查看数据流信息
GET _data_stream/my-data-stream
六、删除数据流
DELETE _data_stream/my-data-stream
七、查看数据流生命周期状态
检索生命周期的进度
要获取托管索引的状态信息,可以使用 ILM 解释 API:
- 索引处于什么阶段以及何时进入这个阶段
- 当前操作和正在执行的步骤
- 如果发生任何错误或进度被阻塞
GET .ds-my-data-stream-*/_ilm/explain
八、冷热分层的前提条件
首先需要有一个具有冷热数据层的ES集群。
Elastic Stack云端配置:
如果采用的Elastic Stack服务,默认会有一个Hot层,其他数据层需要自己添加配置。Add capacity
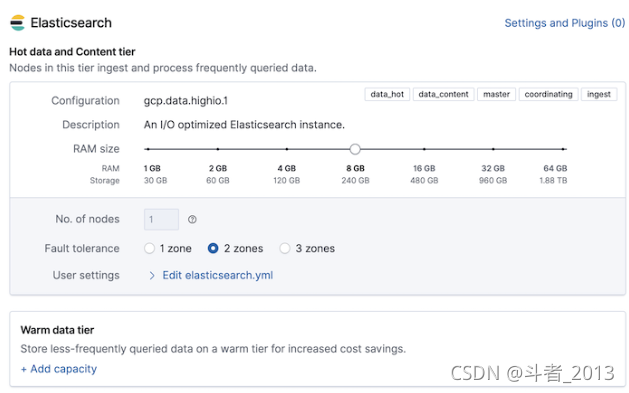
如果是自维护的ES集群,需要在安装ES集群的时候,在elasticsearch.yml 文件中通过配置节点角色配置数据层。
node.roles: [ data_warm ]
只有具备了相应的数据层,那么索引才会在生命周期发送变化时转移到相应的数据层中。
总结
本文主要介绍了如果通过索引生命周期管理ILM机制实现数据的冷热分层。


















 5025
5025

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











