







工作4年多了,也没写过什么博客,去年回老家入职一家国企,工作稍微轻松些,没有在深圳的时候那么忙。最近感觉精力充沛(轻松的工作还是蛮养人的),想把自己研究或者使用到的相关技术做一个记录。第一、对这些知识做一个总结,因为现在发现脑袋不好使了,体会到了好记性不如烂笔头。
废话不多说,那就从最近用的爬虫说起吧。另外自己对爬虫也没有什么研究,纯粹处于会使用的地步。
前言
最近由于工作需要,接触到了爬虫这一块。抓取完整数据分如下二步。
第一步、选择爬虫框架。我们老总说直接用jsoup抓取就行了,这些网站都好抓。那就用吧,把jar下下来,试用了一下,API挺简单,方便,感觉挺好的。总觉得这些网站是好抓,jsoup能够满足,但是有木有更好的、更方便的框架呢,答案是肯定的。那就到网上的查,果然webMagic能够满足我这个需求,主要是文档是中文的呀。那就是它了。
第二步、页面元素分析,那就得看你需要那些数据,来分析页面了,下面我们细说。
工程搭建
因为我使用的是springmvc + mybatis ,所以Maven如下:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>Spider</groupId>
<artifactId>Spider</artifactId>
<packaging>war</packaging>
<version>1.0-SNAPSHOT</version>
<name>Spider Maven Webapp</name>
<url>http://maven.apache.org</url>
<properties>
<spring.version>4.1.1.RELEASE</spring.version>
<jstl>1.2</jstl>
<mybatis.version>3.3.0</mybatis.version>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<!--log-->
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
<!---->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.9.2</version>
</dependency>
<dependency>
<groupId>net.sf.json-lib</groupId>
<artifactId>json-lib</artifactId>
<version>2.4</version>
<classifier>jdk15</classifier>
</dependency>
<dependency>
<groupId>commons-collections</groupId>
<artifactId>commons-collections</artifactId>
<version>3.2.1</version>
</dependency>
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.3.3</version>
</dependency>
<!--Spring -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-core</artifactId>
<version>${spring.version}</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-web</artifactId>
<version>${spring.version}</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context-support</artifactId>
<version>${spring.version}</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-webmvc</artifactId>
<version>${spring.version}</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-test</artifactId>
<version>${spring.version}</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-jdbc</artifactId>
<version>${spring.version}</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-test</artifactId>
<version>4.1.1.RELEASE</version>
</dependency>
<!--JSTL-->
<dependency>
<groupId>javax.servlet</groupId>
<artifactId>servlet-api</artifactId>
<version>2.5</version>
</dependency>
<dependency>
<groupId>javax.servlet</groupId>
<artifactId>jstl</artifactId>
<version>1.2</version>
</dependency>
<dependency>
<groupId>javax.servlet.jsp</groupId>
<artifactId>jsp-api</artifactId>
<version>2.1</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>jstl</groupId>
<artifactId>jstl</artifactId>
<version>${jstl}</version>
</dependency>
<!--mybatis-->
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>${mybatis.version}</version>
</dependency>
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis-spring</artifactId>
<version>1.2.3</version>
</dependency>
<dependency>
<groupId>org.mybatis.generator</groupId>
<artifactId>mybatis-generator-core</artifactId>
<version>1.3.2</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.32</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-collections4</artifactId>
<version>4.0</version>
</dependency>
<dependency>
<groupId>commons-dbcp</groupId>
<artifactId>commons-dbcp</artifactId>
<version>1.4</version>
</dependency>
<dependency>
<groupId>commons-pool</groupId>
<artifactId>commons-pool</artifactId>
<version>1.6</version>
</dependency>
<!-- 添加druid连接池包 -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.0.15</version>
</dependency>
<!--fastjson-->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-core</artifactId>
<version>2.3.0</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.3.0</version>
</dependency>
<!--Gson-->
<dependency>
<groupId>com.google.code.gson</groupId>
<artifactId>gson</artifactId>
<version>2.7</version>
</dependency>
</dependencies>
<build>
<finalName>GogBuySpider</finalName>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.6</source>
<target>1.6</target>
</configuration>
</plugin>
<plugin>
<artifactId>maven-surefire-plugin</artifactId>
<configuration>
<includes>
<include>**/*Tests.java</include>
</includes>
</configuration>
</plugin>
<!--mybatis 逆向工程插件-->
<plugin>
<groupId>org.mybatis.generator</groupId>
<artifactId>mybatis-generator-maven-plugin</artifactId>
<version>1.3.2</version>
<configuration>
<verbose>true</verbose>
<overwrite>true</overwrite>
</configuration>
</plugin>
</plugins>
</build>
</project>
配置spring-serlvet.xml
<context:component-scan base-package="com.xxx.spider"/>
<mvc:annotation-driven/>
<mvc:default-servlet-handler/>
<bean id="viewResolver" class="org.springframework.web.servlet.view.InternalResourceViewResolver">
<property name="prefix" value="/WEB-INF/view/"/>
<property name="suffix" value=".jsp" />
</bean>整个Spring mybatis
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd">
<bean class="org.springframework.beans.factory.config.PropertyPlaceholderConfigurer">
<property name="location" value="classpath:jdbc.properties"/>
</bean>
<bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource" destroy-method="close">
<property name="driverClassName" value="${jdbc_driverClassName}"/>
<property name="url" value="${jdbc_url}"/>
<property name="username" value="${jdbc_username}"/>
<property name="password" value="${jdbc_password}"/>
<!-- 配置监控统计拦截的filters -->
<property name="filters" value="stat" />
<property name="maxActive" value="20" />
<property name="initialSize" value="1" />
<property name="minIdle" value="1" />
<!-- 配置获取连接等待超时的时间 -->
<property name="maxWait" value="60000" />
<!-- 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒 -->
<property name="timeBetweenEvictionRunsMillis" value="60000" />
<!-- 配置一个连接在池中最小生存的时间,单位是毫秒 -->
<property name="minEvictableIdleTimeMillis" value="300000" />
<property name="validationQuery" value="SELECT 'x'" />
<property name="testWhileIdle" value="true" />
<property name="testOnBorrow" value="false" />
<property name="testOnReturn" value="false" />
<!--如果用Oracle,则把poolPreparedStatements配置为true,mysql可以配置为false。-->
<!-- 打开PSCache,并且指定每个连接上PSCache的大小 -->
<property name="poolPreparedStatements" value="true" />
<property name="maxPoolPreparedStatementPerConnectionSize" value="50" />
</bean>
<bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean">
<property name="dataSource" ref="dataSource"/>
<!-- 自动扫描mapping.xml文件 -->
<property name="mapperLocations" value="classpath:mapper/*"/>
</bean>
<!--扫描dao-->
<bean class="org.mybatis.spring.mapper.MapperScannerConfigurer">
<property name="basePackage" value="com.xxx.spider.dao"/>
<property name="sqlSessionFactoryBeanName" value="sqlSessionFactory"/>
</bean>
<!-- (事务管理)transaction manager, use JtaTransactionManager for global tx -->
<bean id="transactionManager"
class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="dataSource"/>
</bean>
</beans>配置spring context (不配置好像也可以)
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:websocket="http://www.springframework.org/schema/websocket"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/websocket
http://www.springframework.org/schema/websocket/spring-websocket-4.1.xsd">
<import resource="spring-servlet.xml"/>
<import resource="spring-mybatis.xml"/>
</beans>web.xml
<web-app version="3.0" xmlns="http://java.sun.com/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/javaee http://java.sun.com/xml/ns/javaee/web-app_3_1.xsd">
<display-name>Archetype Created Web Application</display-name>
<context-param>
<param-name>contextConfigLocation</param-name>
<param-value>classpath:spring-context.xml</param-value>
</context-param>
<listener>
<listener-class>org.springframework.web.context.ContextLoaderListener</listener-class>
</listener>
<servlet>
<servlet-name>springMvc</servlet-name>
<servlet-class>org.springframework.web.servlet.DispatcherServlet</servlet-class>
<load-on-startup>1</load-on-startup>
<init-param>
<param-name>contextConfigLocation</param-name>
<param-value>classpath:spring-servlet.xml</param-value>
</init-param>
</servlet>
<servlet-mapping>
<servlet-name>springMvc</servlet-name>
<url-pattern>*.do</url-pattern>
</servlet-mapping>
<servlet-mapping>
<servlet-name>springMvc</servlet-name>
<url-pattern>/</url-pattern>
</servlet-mapping>
<welcome-file-list>
<welcome-file>index.jsp</welcome-file>
</welcome-file-list>
</web-app>然后到这里工程就建好了。
因为我们用到webMagic,在maven中添加
<!--webMagic-->
<dependency>
<groupId>us.codecraft</groupId>
<version>0.5.3</version>
<artifactId>webmagic-core</artifactId>
</dependency>
<dependency>
<groupId>us.codecraft</groupId>
<version>0.5.3</version>
<artifactId>webmagic-extension</artifactId>
</dependency>一切OK,剩下的就是分析页面,然后用webMagic解析了。
页面分析
如下图
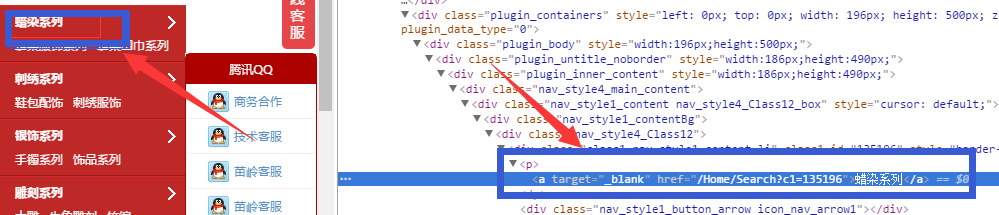
我们想要类别名称跟URL,分析可知是在标签<a>里面,通过webmagic的css选择器和xpath对页面元素进行抽取。
List<String> titles = page.getHtml().xpath("//div[@class='class1']/p/a/text()").all();
List<String> urls = page.getHtml().css("div.nav_style1_contentBg").links().regex(".*?c1=.*").all();这样就得到全部的大类别和对应的URL。怎么使用大家可以查看http://webmagic.io/docs/。
数据保存
借用说明文档上的一段话。
好了,爬虫编写完成,现在我们可能还有一个问题:我如果想把抓取的结果保存下来,要怎么做呢?WebMagic用于保存结果的组件叫做Pipeline。例如我们通过“控制台输出结果”这件事也是通过一个内置的Pipeline完成的,它叫做ConsolePipeline。那么,我现在想要把结果用Json的格式保存下来,怎么做呢?我只需要将Pipeline的实现换成”JsonFilePipeline”就可以了。
public static void main(String[] args) {
Spider.create(new GithubRepoPageProcessor())
//从”https://github.com/code4craft“开始抓
.addUrl(“https://github.com/code4craft“)
.addPipeline(new JsonFilePipeline(“D:\webmagic\”))
//开启5个线程抓取
.thread(5)
//启动爬虫
.run(); } 这样子下载下来的文件就会保存在D盘的webmagic目录中了。通过定制Pipeline,我们还可以实现保存结果到文件、数据库等一系列功能。这个会在第7章“抽取结果的处理”中介绍。
至此为止,我们已经完成了一个基本爬虫的编写,也具有了一些定制功能。
我们通过自定义pipeline来保存到数据库。
@Repository
public class DataBasePipeline implements Pipeline{
@Autowired
private CategoryMapper categoryMapper;
@Autowired
private ShopMapper shopMapper;
@Autowired
private ItemMapper itemMapper;
@Override
public void process(ResultItems resultItems, Task task) {
//TODO 保存类目到数据库
//TODO 保存商品到数据库
}
}抓取
定义一个main方法,run就行了,坐等爬完。
@Controller
public class Door {
@Autowired
private DataBasePipeline dataBasePipeline;
public static void main(String[] args) {
ApplicationContext applicationContext = new ClassPathXmlApplicationContext("classpath:spring-context.xml");
Door door = applicationContext.getBean(Door.class);
door.goSpider();
}
public void goSpider() {
Spider.create(new QmiaolingPageProcessor())
.addUrl("http://www.xxx.com/")
.addPipeline(new ConsolePipeline())
.addPipeline(dataBasePipeline)
.thread(5)
.run();
}
}
结束语
后续会把项目放到github上面。















 235
235

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









