






down.itppp.com 这里下载。
全网大运营商数据中心为支撑,汇聚线上线下全域商品数据。
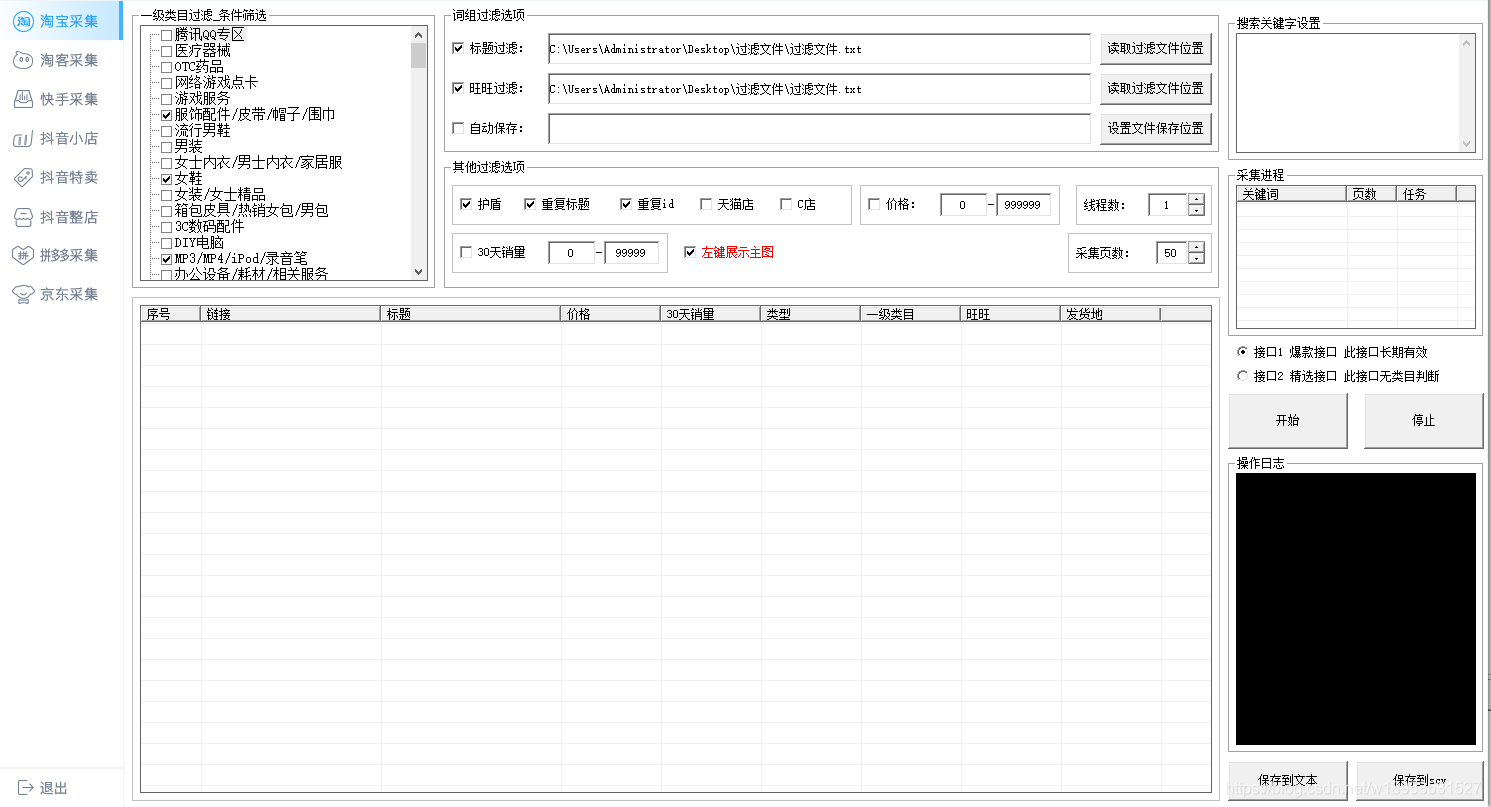
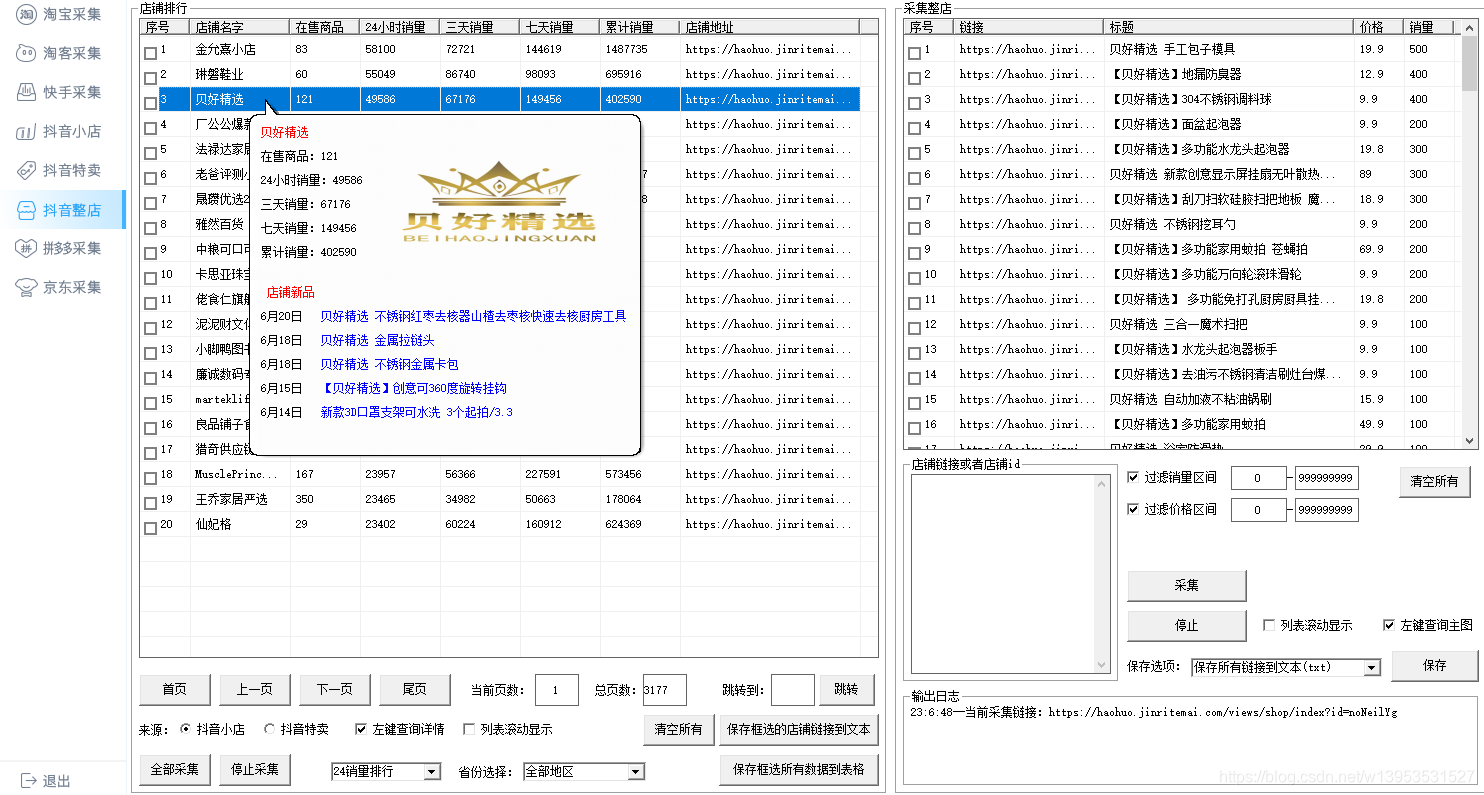
完美抓取商品的标题、主图、价格(促销价格)、库存、详情页、销售属性及属性图等。抓取成功率高,销售属性及商品属性99%相同。解决详情页难做、宝贝难传、图片难拍等问题。
可轻松抓取淘宝、天猫、拼多多、淘宝联盟、京东、抖店、快手等各大电商平台的宝贝商品,任意店铺的宝贝。
down.itppp.com 这里下载。
不懂网络爬虫技术,也可轻松采集数据
操作简单·功能强大·满足你的所有需求
提供多种网页采集策略与配套资源,帮助整个采集过程实现数据的完整性与稳定性
眼见即可采,不管是文字图片,支持所有业务渠道的爬虫,满足各种采集需求
无需再学爬虫编程技术,简单三步就可以轻松抓取网页数据,支持多种格式一键导出,快速导入数据库
down.itppp.com 这里下载。

















 1009
1009

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









