




 本文介绍了SQL中的group_concat函数用于合并分组后的数据,以及find_in_set函数用于查找子串的位置。通过实例展示了如何在成绩表和招聘职位场景中运用这些功能。同时,对比了FIND_IN_SET和IN,以及find_in_set与like的区别。最后,讲解了find_in_set在多标签文章筛选中的应用。
本文介绍了SQL中的group_concat函数用于合并分组后的数据,以及find_in_set函数用于查找子串的位置。通过实例展示了如何在成绩表和招聘职位场景中运用这些功能。同时,对比了FIND_IN_SET和IN,以及find_in_set与like的区别。最后,讲解了find_in_set在多标签文章筛选中的应用。
首先是group_concat
直接拿个张表来举例,这里参考大佬的博客然后 总结大佬的 内容
group_concat它常用在select 后面,然后结合 分组函数使用,你可以使用它把分组后某个字段的数据进行拼接,比如一下例子
什么是 find_in_set ?
find_in_set就相当是Java中的找子字符串(具体结合使用和详解见下文)
group_concat简单应用场景
这里有一张成绩表,我们要统计出每个分数,都有那些人
|id |subject |student|teacher|score|
---------------------------------------
|1 |数学 |小红 |王老师 |80 |
|2 |数学 |小李 |王老师 |80 |
|3 |数学 |小王 |王老师 |70 |
|4 |数学 |小张 |王老师 |90 |
|5 |数学 |小赵 |王老师 |70 |
|6 |数学 |小孙 |王老师 |80 |
|7 |数学 |小钱 |王老师 |90 |
|8 |数学 |小高 |王老师 |70 |
|9 |数学 |小秦 |王老师 |80 |
|10 |数学 |小马 |王老师 |90 |
|11 |数学 |小朱 |王老师 |90 |
|12 |语文 |小高 |李老师 |70 |
|15 |语文 |小秦 |李老师 |70 |
|18 |语文 |小马 |李老师 |80 |
|21 |语文 |小朱 |李老师 |90 |
|24 |语文 |小钱 |李老师 |90 |这个时候我们就可以根据score进行分组,然后结合group_concat实现
select score,group_concat(student) from exam group by score;执行后会发现每个分数后会有重复
|score |group_concat(student) |
-------------------------------------
|70 |小王,小赵,小高,小高,小秦 |
|80 |小红,小李,小孙,小秦,小马 |
|90 |小张,小钱,小马,小朱,小朱,小钱 |我们可以使用关键字distinct进行去重
select score,group_concat(distinct student) from exam group by score;结果为:这样就没有重复值了
|score |group_concat(student) |
---------------------------------
|70 |小王,小赵,小高,小秦 |
|80 |小红,小李,小孙,小秦,小马 |
|90 |小张,小钱,小马,小朱 |如果我们不想用 ,也可以替换成想要的分隔符
select score,group_concat(distinct student separator '%') from exam group by score;结果为:
|score |group_concat(student) |
---------------------------------
|70 |小王%小秦%小赵%小高 |
|80 |小孙%小李%小秦%小红%小马 |
|90 |小张%小朱%小钱%小马 |group_concat也是可以排序的
排序的话,直接这样用group_concat( 字段名 order by 排序的字段 desc separator ' 分隔符 ' )
group_concat(distinct student order by age desc separator '%')其次是FIND_IN_SET
比如 SELECTFIND_IN_SET('b','a,b,c,d');
他就会在后面的a,b,c,d中去找b,然后返回其位置,这里返回的是2,因为他下标是从1开始的
如果前面的字符串在后面不存在,则返回 0
FIND_IN_SET 和 IN 的区别
比如这张表 我想查list字段中带有 王五 的行
CREATE TABLE `tb_test` (
`id` int(8) NOT NULL auto_increment,
`name` varchar(255) NOT NULL,
`list` varchar(255) NOT NULL,
PRIMARY KEY (`id`)
);
INSERT INTO `tb_test` VALUES (1, 'name', '张三,里斯,王五');
INSERT INTO `tb_test` VALUES (2, 'name2', '里斯,张三,王五');
INSERT INTO `tb_test` VALUES (3, 'name3', '王五,里斯,张三');我们这样查寻是查不出结果的
SELECT id,name,list from tb_test WHERE '王五' IN(list); 要想有结果,就要使用find_in_set
SELECT id,name,list from tb_test WHERE FIND_IN_SET('王五',list);总结:
所以如果list是常量,则可以直接用IN, 否则要用find_in_set()函数。
find_in_set()和like的区别:
主要的区别就是like是广泛的模糊查询,而 find_in_set() 是精确匹配,并且字段值之间用‘,'分开。
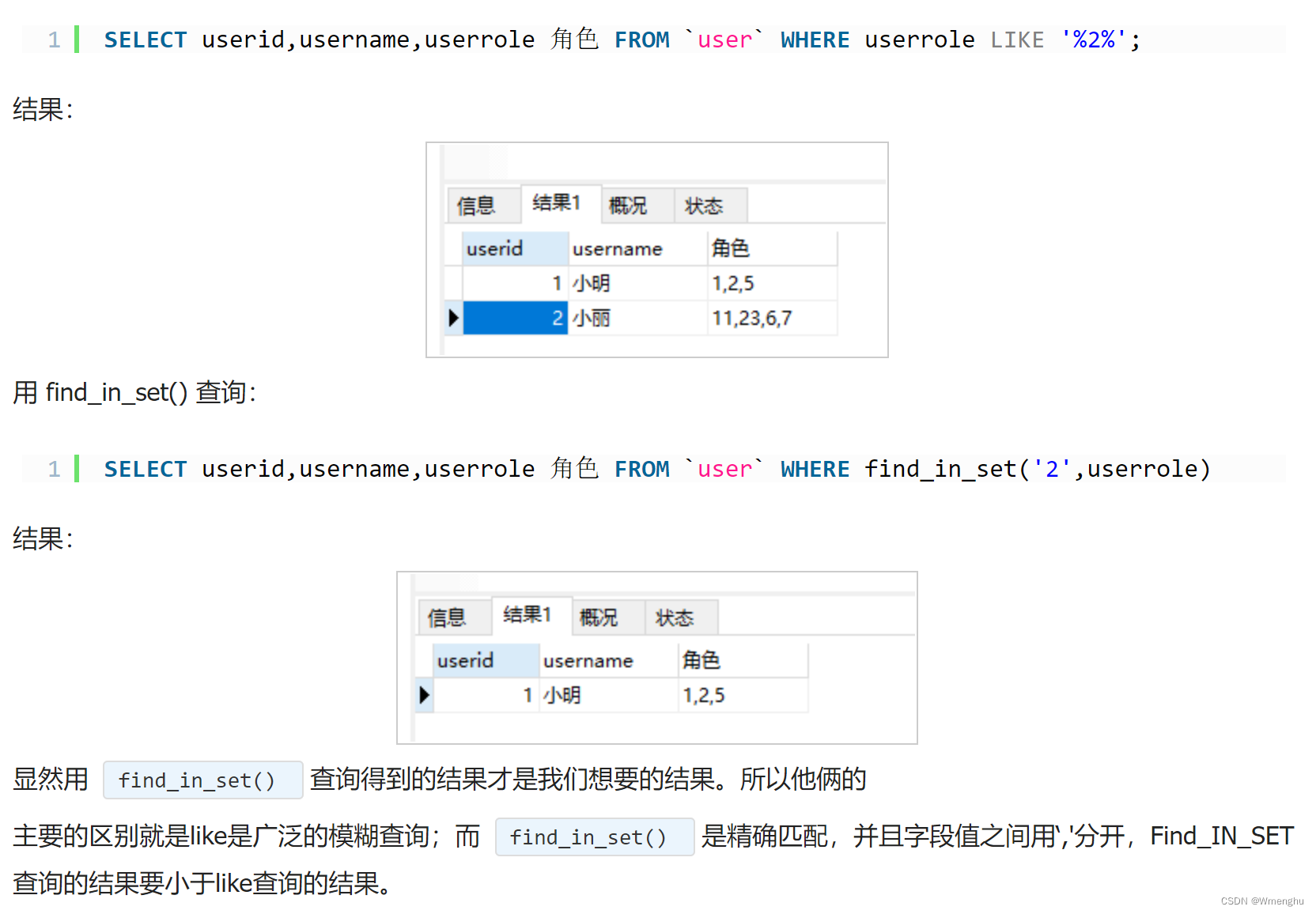
find_in_set的应用一
有个文章表里面有个type字段,它存储的是文章类型,其中类型有 1头条、2推荐、3热点、4图文...... 等等各种类型 。
现在有篇文章他既是 头条,又是热点,还是图文,那么他的 type 字段中的值就为 1,3,4 。也就是说,一个文章可以有多个标签
那我们如何用sql查找所有type中有3,是热点的文章呢??
这就要我们的 find_in_set 出马的时候到了。
select * from article where FIND_IN_SET('3',type)group_concat和find_in_set结合实例
场景:
比如一个招聘职位,工作地点有多个,这个招聘职位中有个字段可以存工作地点的id,工作地点是单独的一张表比如:
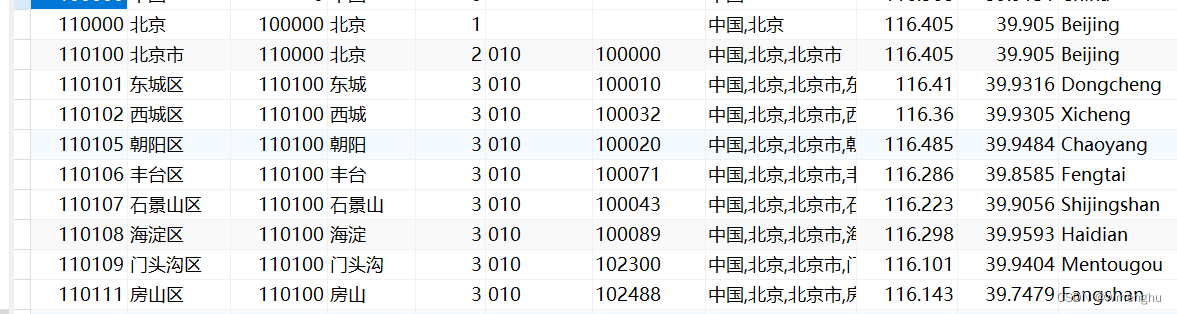
这时,保存多个地址就可以这样保存:110101,110102,110105
那么问题来了,如果我想查找,东城区的招聘职位,并且把这个职位的工作地点都展示出来,就需要这样写sql了(涉及公司项目只提供部分sql):
select
R.id
...
GROUP_CONCAT(R.cityName) as address
...
from
recruit as R
INNER JOIN (select * from city) as C on FIND_IN_SET(C.id , R.cityIds,)
...
where
...
C.id = #{cityId}
...
GROUP BY
R.id这样就可以把 指定城市的招聘职位,招聘职位的全部地址都展示出来,需要细细理解。


















 1195
1195

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









