







Redis五大数据类型:String(字符串),Hash(哈希),List(列表),Set(集合)及Zset(sorted set:有序集合)。
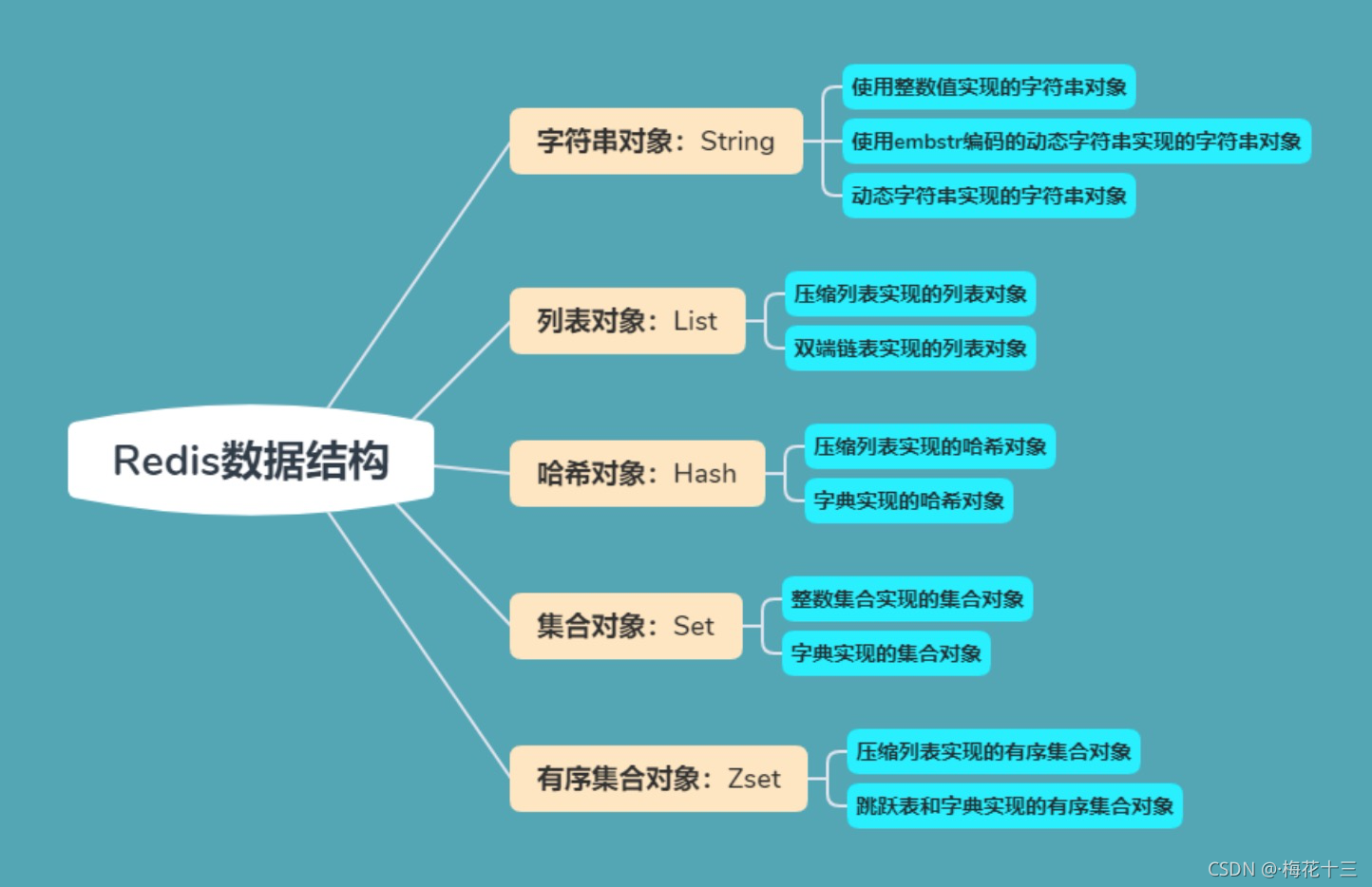
一、介绍
Zset 是Set的一个升级版本,他在set的基础上增加了一个 顺序属性,每个member成员都带有一个score分数( redis通过分数进行集合内成员的排序)。
有序集合的成员是唯一的,但分数(score)却可以重复
场景:很适合在打赏日榜、近一周收益这类场景中运用。应用排名模块比较多。
二、数据结构
底层使用两种数据结构存储:
- ziplist 压缩列表
- skiplist 跳跃表(简称跳表)+ dict 字典
当使用ziplist编码必须满足下面两个条件,否则使用跳表
- 有序集合保存的元素数量 < 128个
- 有序集合保存的所有元素的长度 < 64字节
对应redis中的配置如下
- zset-max-ziplist-entries 128
- zset-max-ziplist-value 64
▶ Ziplist
每个集合元素使用两个紧挨在一起的压缩列表节点来保存,第一个节点保存member,第二个元素保存score(从小到大排序),score较小的排在表头位置。 如下:

▶ Skiplist (Skiplist 跳表 + dict 字典)
dict 字典 的键保存元素的值,值则保存元素的分值;skiplist 跳跃表节点的 object 属性保存元素的值,节点的 score 属性保存元素的分值。
虽同时使用两种结构,但会通过指针来共享相同元素的member和score,不会浪费额外内存
一、dict 字典
字典中的键是唯一的,可以通过key来查找值
-
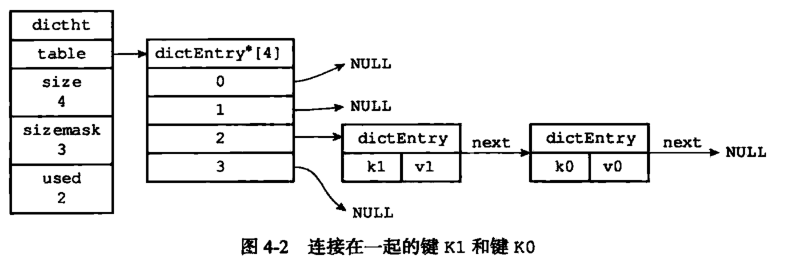
字典底层实现是哈希表,字典有两个哈希表,一个在扩容时使用,哈希表扩容使用渐进式扩容,发送扩容时需要在两个哈希表中进行搜索。
-
发生哈希冲突时使用链地址法解决
二、Skiplist 跳表
■ 基本链表:
![]()
查找某个数据,需从头开始逐个进行比较,直到找到包含数据的节点,或找到比该数据大的节点为止才停止查找(没找到)。时间复杂度为O(n)。插入新数据也要经历同样的查找过程!
■ 跳跃表:
假如每隔一个节点增加一个指针,让指针指向下下个节点,如下图:

现在查找:可先沿着新链表 (橙色的节点) 进行查找。碰到比待查数据大的节点时,再回原来的链表中进行查找。比如查找23,查找的路径,如下图中标红的指针所指向的方向进行:

流程如下:
- 23首先和7比较,再和19比较,比它们都大,继续向后比较。
- 等23和26比较时,比26要小,因此回到下面的链表(原链表),与22比较。
- 23比22要大,沿下面的指针继续向后和26比较。23比26小,说明23在原链表中不存在,那么它插入的位置应该在22和26之间
在上述查找过程中,由于新增加的指针,时间复杂度不再是O(N),不再需要与链表中每个节点逐个进行比较。需要比较的节点数大概只有原来的一半!
利用同样的方式,可以在上层新产生的链表上,继续扩展指针,从而产生第三层链表。如下图:

流程如下,在新的三层链表结构上(粉色的节点),还是查找23
- 沿着最上层链表,首先要比较的是19,发现23比19大,
- 接下来就知道只需要到19的后面去继续查找,从而一下子跳过了19前面的所有节点。
当链表足够长时,多层链表的方式能够一次性跳过很多下层节点,从而加快查找的速度!
▎Skiplist总结
skiplist 的实现就是多层链表。按照上面生成链表的方式,上面每一层链表的节点个数,是下面一层的节点个数的一半,降低了查找时间的复杂度。并且只有第一层链表才会存元素,上面多层列表只存指针,不存元素!
━━ 狂徒思考?
按照上下每层链表的节点个数,上层与下层大致是 1:2 的对应关系,如果插入或删除数据就会打乱这种规则。要维持这种对应关系,就必须把新插入的节点以及后面的所有节点重新调整,就导致又恢复了原先复杂度!
◇ 那么skiplist是如何设置每个节点的指针,和节点存放到哪个层数呢?
答:不要求上下相邻两层链表之间的节点个数有严格的对应关系,并且为每个节点随机出一个层数
#define ZSKIPLIST_MAXLEVEL 32
#define ZSKIPLIST_P 0.25
int zslRandomLevel(void) {
int level = 1;
while ((random()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF))
level += 1;
return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;
}计算随机层数是一个很关键的过程,对skiplist的统计特性有着很重要的影响。这并不是一个普通的服从均匀分布的随机数,而是服从一定规则的:
- 首先,每个节点肯定都有第1层指针(每个节点都在第1层链表里)。
- 如果一个节点有第i层(i>=1)指针(即节点已经在第1层到第i层链表中),那么它有第(i+1)层指针的概率为p。
- 节点最大的层数不允许超过一个最大值,记为MaxLevel(Redis里是32)。
◈ 举个例子:一个节点随机出的层数是3,把它链入到第1层到第3层这三层链表中。流程如下
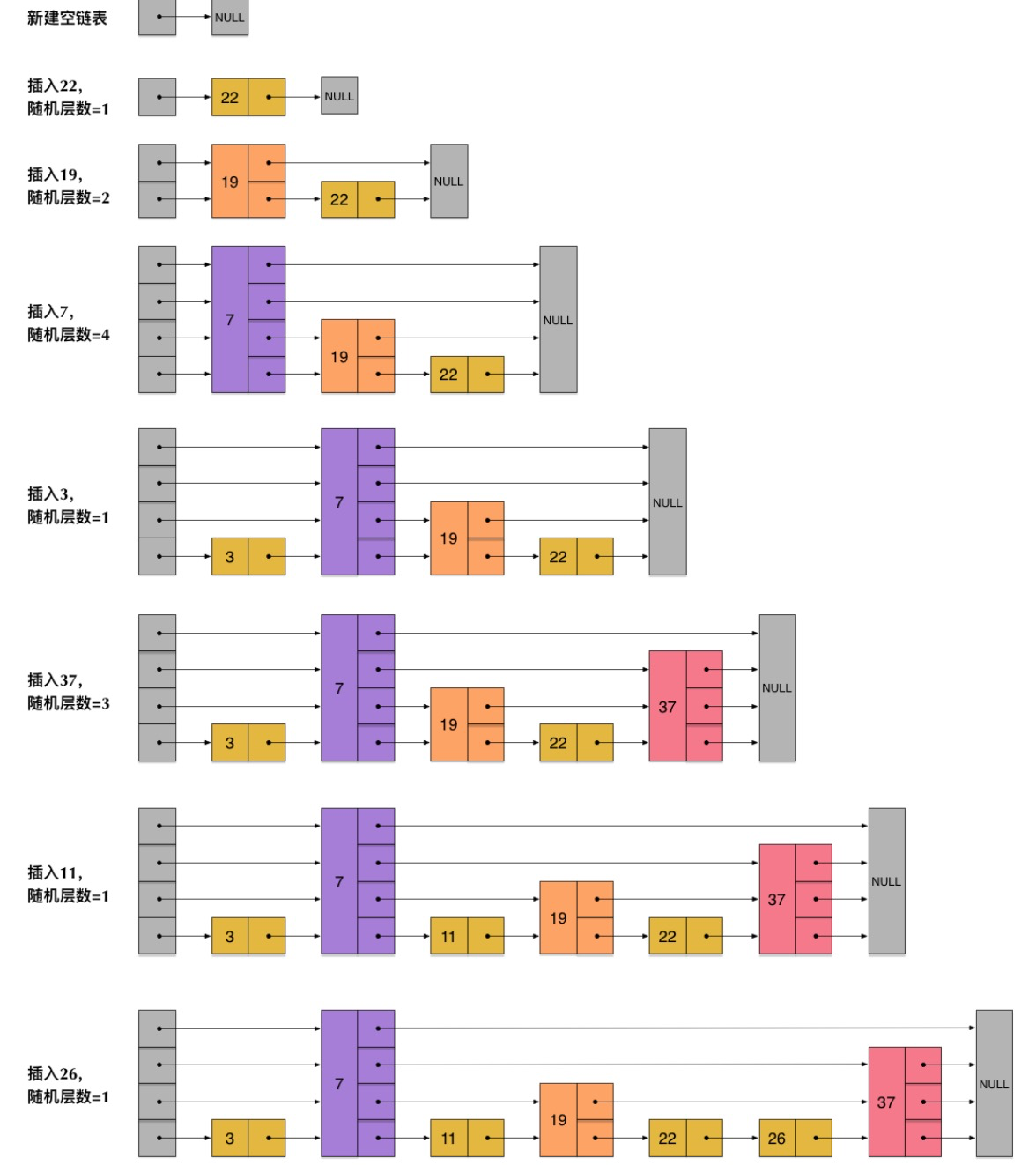
从上述插入过程可知:每一个节点的层数(level)是随机出来的,而且新插入一个节点不会影响其它节点的层数。只需修改插入节点前后的指针,无需对后面节点调整,降低插入操作的复杂度。
Skiplist 除了第1层链表之外,还会产生若干层稀疏的链表,链表里的每层指针故意跳过一些节点(越高层的链表跳过的节点越多)
因此在查找数据时,能先在高层的链表中进行查找,然后逐层降低,最终精确地定位到数据位置。从而加快了查找速度!
刚刚创建的skiplist总共包含4层链表,现在假设我们依然查找23,下图给出了查找路径:
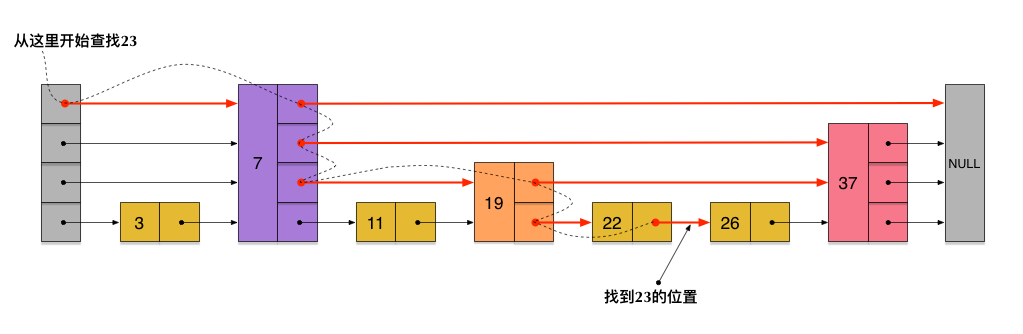
实际应用中的skiplist每个节点应该包含member和score两部分。前面的描述中我们没有具体区分member和score,实际上列表中是按照score进行排序的,查找过程也是根据score在比较。
三、操作命令
| 命令 | 功能 | 描述 |
| zadd | 添加 | 向有序集合添加一个或多个成员(如果成员存在,则更新) |
| zrange | 升序查询 | 返回有序集合指定索引区间内的成员 |
| zrevrange | 降序查询 | 返回有序集合指定索引区间内的成员 |
| zcard | 统计个数 | 统计集合所有的成员个数 |
| zcount | 统计区间个数 | 统计指定分数区间的成员数量 |
| zincrby | +增量值 | 给指定成员的分数执行 +增量值 操作 |
| zscore | 查询成员分数 | 返回指定成员的分数 |
| zrem | 删除 | 删除多个成员 |
| zrangebysroce | 升序查询 | 返回集合中指定分数 min-max之间的成员 |
| zrevrangebysroce | 降序查询 | 返回集合中指定分数 max-min之间的成员 |
1、Zadd 向有序集合中添加多个成员和分数 (添加)
语法:Z
add key sroce1 member1 sroce2 member2...
# 1、往myset有序集合中添加 jack、rose、lisa等成员,分数各自为 58、60 59
[127.0.0.1:6379> zadd myset 58 jack 60 rose 59 lisa
(integer) 3
# 查询myset集合从下标0到末至下标之间的成员(-1表示集合最后一个元素下标)
[127.0.0.1:6379> zrange myset 0 -1
1) "jack"
2) "lisa"
3) "rose" # 有序集合,在添加的时候默认按照score分数进行排序存储的
# 2、修改Lisa的分数为49(如果Lisa存在集合中,则修改其分数,否则添加)
[127.0.0.1:6379> zadd myset 49 lisa
(integer) 0
#查询集合中排名变化(Lisa分数最低排第一名,集合按照从小到大排序)
[127.0.0.1:6379> zrange myset 0 -1
1) "lisa"
2) "jack"
3) "rose"2、Zrevrange 查询集合中指定索引区间内的成员 (降序查询)
语法:Z
revrange key [开始下标] [结束下标] [withscores可选,表示也查出分数]
# 1、往myset有序集合中添加 jack、rose、lisa等成员,分数各自为 58、60 59
[127.0.0.1:6379> zadd myset 58 jack 60 rose 59 lisa
(integer) 3
# zrange 升序查询
[127.0.0.1:6379> zrange myset 0 -1
1) "lisa"
2) "jack"
3) "rose"
# zrevrange 降序查询
[127.0.0.1:6379> zrevrange myset 0 -1
1) "rose"
2) "jack"
3) "lisa"
# zrevrange 降序查询,并查出分数 score
[127.0.0.1:6379> zrevrange myset 0 -1 withscores
1) "rose"
2) "60"
3) "jack"
4) "58"
5) "lisa"
6) "49"
# 截取查询,查询下标从2开始到最后位置区间的成员
[127.0.0.1:6379> zrange myset 2 -1
1) "rose"3、Zcard 统计集合中成员个数 (统计)
语法:Z
card key
# 集合内全部成员-分数
[127.0.0.1:6379> zrevrange myset 0 -1 withscores
1) "rose"
2) "60"
3) "jack"
4) "58"
5) "lisa"
6) "49"
# 统计myset集合中成员个数
[127.0.0.1:6379> zcard myset
(integer) 34、Zcount 统计指定分数区间的成员个数 (统计个数)
语法:Z
count key [开始下标] [结束下标] [withscores可选,表示也查出分数]
# 集合内全部成员-分数
[127.0.0.1:6379> zrevrange myset 0 -1 withscores
1) "rose"
2) "60"
3) "jack"
4) "58"
5) "lisa"
6) "49"
# 查询分数在58-70之间的成员数量
[127.0.0.1:6379> zcount myset 58 70
(integer) 2
5、Zincrby 对指定成员的分数执行 +增量值 (+增量值)
语法:Z
incrby key [increment] member
# 集合内全部成员-分数
[127.0.0.1:6379> zrevrange myset 0 -1 withscores
1) "rose"
2) "60"
3) "jack"
4) "58"
5) "lisa"
6) "49"
# 给myset集合中,成员Lisa增加10分
[127.0.0.1:6379> zincrby myset 10 lisa
"59"6、Zscore 查询指定成员的分数 (查分数)
语法:Z
score key member
# 集合内全部成员-分数
[127.0.0.1:6379> zrevrange myset 0 -1 withscores
1) "rose"
2) "60"
3) "jack"
4) "58"
5) "lisa"
6) "49"
# 查询rose的分数
[127.0.0.1:6379> zscore myset rose
"60"7、Zrem 删除多个成员 (删除)
语法:Z
rem key member1 member2..
# 集合内全部成员-分数
[127.0.0.1:6379> zrevrange myset 0 -1 withscores
1) "rose"
2) "60"
3) "jack"
4) "58"
5) "lisa"
6) "49"
# 移除多个成员
[127.0.0.1:6379> zrem myset lisa rose
(integer) 2
127.0.0.1:6379> zrange myset 0 -1
1) "jack"8、Zrangebyscore 获取指定分数区间的成员 (查询分数区间成员)
语法:Z
rangebyscore key min max (min和max是分数区间)
# 集合内全部成员-分数
127.0.0.1:6379> zrange myset 0 -1 withscores
1) "jack"
2) "58"
3) "sun"
4) "64"
5) "bob"
6) "79"
# -inf:负无穷 +inf:正无穷 查询全部分数的成员
127.0.0.1:6379> zrangebyscore myset -inf +inf
1) "jack"
2) "sun"
3) "bob"
#注意:zrange是查询下标区间 zrangebyscore是查询分数区间
127.0.0.1:6379> zrange myset 0 60
1) "jack"
2) "sun"
3) "bob"
# 查询myset集合中 0-60分之间的成员
127.0.0.1:6379> zrangebyscore myset 0 60
1) "jack" #jack是58,满足条件
思考:Redis zset为什么用跳表呢?
- 跳表比 B 树/B+树占用的内存更少。
- 跳表以链表的形式进行遍历,和平衡树是一样的。缓存局部性与其他类型的平衡树相当
- 更易于实现,调试。
跳表是一种采用了用空间换时间思想的数据结构。它会随机地将一些节点提升到更高的层次,以创建一种逐层的数据结构,以提高操作的速度。在理论上能够在 O(log(n))时间内完成查找、插入、删除操作。
简言之,跳表和时间复杂度几乎和红黑树一样,而且实现起来简单。
思考:redis的zset为什么不用平衡树作为数据结构呢?
- 跳表的实现更加简单,不用旋转节点,相对效率更高
- 跳表在范围查询的时候的效率是高于红黑树的,因为跳表是从山层往下层查找的,上层的区域范围更广,可以快速定位到查询的范围
- 平衡树的插入和删除操作可能引发子树的调整、逻辑复杂,而跳表的插入和删除只需修改相邻节点的指针,操作简单又快速。
- 查找单个key,跳表和平衡树时间复杂度都是O(logN)
另外,从内存占用上来说:跳表能更少的占用内存;指针会比较少;
skiplist(跳表)比平衡树更灵活一些。一般来说,平衡树每个节点包含2个指针(分别指向左右子树),而跳表每个节点包含的指针数目平均为1/(1-p),具体取决于参数p的大小。如果像Redis里的实现一样,取p=1/4,那么平均每个节点包含1.33个指针,比平衡树更有优势。
思考:HashMap为什么用红黑树而不用跳表?
1、跳表需要维护额外的多层链表,是空间换时间的做法,红黑树不用占用多余的空间
2、同时HashMap的Entry并没有内在的排序关系,所以也无法使用跳表,因为跳表本身要求要存在排序关系
其他说明:hashCode无法排序,所以无法实现跳表结构。Map的种类有很多,有实现了排序关系的Map,比如TreeMap;再比如底层就是跳表的ConcurrentSkipListMap。
基于跳表实现的Map也有,基于红黑树实现的Map也有,看业务场景来选择使用。
如果你只在乎随机查询效率那就是HashMap,如果要求线程安全那就是ConcurrentHashMap;如果要求排序,范围查询那就是ConcurrentSkipListMap
思考:为什么MySQL的索引结构,采用了B+树,没有使用跳跃表呢?
- B+树的一个节点可以存储很多关键字,而且单个节点大小可以与磁盘页对齐(默认16kb),一次IO就能传输一整个节点(跳跃表可能会出现跨页IO),大幅减少磁盘IO次数,所以B+树更适合用于文件系统及关系型数据库。
- 跳跃表的索引层建立具有随机性,磁盘不能对链表进行预读,会产生大量随机IO。(磁盘预读:从本次被读取的位置开始,顺序向后读取一定长度的数据放入内存)
- B+树检索效率比跳表高。
B+树发明于 1972 年,跳表发明于 1989 年















 839
839











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









