







背景
目前大概的需求如下:
- 一个大内网中,一个服务端,多个客户端(至少有五个)
- 服务端大多是下发一些周期性任务给到客户端(也会有少量临时任务),客户端执行,任务执行结果需要持久化
- 服务端能通过web界面对任务进行管理,包括:任务参数配置/任务下发/任务暂停/任务重启/任务停止/执行是否成功等
- 服务端需要知道客户端是否在线
- 传递的任务消息不需要绝对的可靠性
- S或C端的语言栈可接受python或go
网上找了下解决方案,一般推荐的是使用任务队列来实现,go的任务队列还并不成熟,python用的比较多的就是celery+broker+flower的解决方案了。
网上有很多关于python的celery介绍和使用,但是感觉都讲得很不清楚,要么就是老版本有各种BUG,本文基于python3,讲解celery+broker+flower的解决方案,并提供测试demo。
celery简介
1. celery基本概念:
celery是一个强大的分布式任务处理框架,它可以让任务的执行完全脱离主程序,甚至可以被分配到其他的主机上运行。它是一个专注于实时处理的任务队列,同时也支持任务调度。
2. celery架构:

在上图中,一共可以分为四个部分:
- Producer(任务生产者)
- broker(任务队列)
- worker(任务消费者)
- database(任务结果存储)
简单介绍下这四个部分的作用:
(1)任务生产者
任务生产者负责产生计算任务,甩给任务队列。
(2)任务队列
任务队列负责接受任务生产者发送过来的任务处理消息,存进队列,等待对应的消费者来拉取消费,我们一般会选择rabbitmq和redis 等celery官方支持较好的消息队列。
(3)任务消费者
任务消费者就是具体执行任务的一方,它从任务队列中拉取对应的任务,完成这些任务,并且返回任务处理的结果(如存回进redis或存到数据库进行持久化)。
Celery支持分布式部署和横向扩展,我们可以在多个服务器上起celery的消费者,将一个大型任务切割成多个小任务,交由多个消费者进行处理,提高任务处理速度。
(4)任务结果存储
Celery 支持任务处理完后将状态信息和结果进行保存,以供查询,常见的如甩回给redis或存进数据库进行持久化。
3. celery特性:
- 方便查询任务的进展情况,如执行结果,状态,消耗时间
- 可以搭配flower进行基于web界面的任务和客户端管理
- 支持redis和rabbitmq等多个broker
- 支持将任务结果存入mongodb等数据库进行持久化
- 可以进行并发操作
- 提供异常处理机制
4. celery应用场景:
- web应用:当需要触发事件需要较长时间处理完成,可以交给celery进行异步执行,执行完后返回结果,客户端在这段时间不用等待,提高系统响应时间。
- 特殊任务:如发送邮件等,任务的结果需要等待一段时间才能拿到任务执行结果,不可能让主线程去干这类事。
- 定时任务处理:一些周期性定时任务处理,且这类任务往往执行时间较长。
5. celery具体实现:
比较成熟的celery库是用python实现的:https://github.com/celery/celery ,当然go也有,但是资料和成熟度都没有python的好,推荐使用python的celery库。
简单总结下:celery是个分布式任务处理框架,celery对任务的下发、任务消费和任务结果存储等进行了统一的封装,你只要调celery的函数就行了,不用关心其中具体的实现。
flower简介
一个对 Celery 集群进行实时监控和提供 web 管理界面的工具,当然也是基于python实现的:https://github.com/mher/flower,用flower的前提是flower所在服务器能和任务队列所在服务器连通。
最牛逼的是起了flower后,你可以选择通过API调用方式来对任务和worker进行管理,而不用flower自带的web界面,等于是你可以自己开发个web界面来调flower的接口。

celery实战demo
1. demo架构
我简单用图展示下demo架构,大家看得懂就好:

其中server端和flower在一台windows机器上,作为broker的redis和作为数据库的mongodb在一台centos7上,消费者在server端(省机器所以这么搞)和其它多个linux机上都有。
2. 各组件及版本
本次celery示例的demo基于python3.7.4版本,推荐使用python3版本,因为python2版本有诸多bug。
具体组件及版本:
redis 5.0.7
mongodb 4.2.3
python3.7.4相关库及版本:
pip3 install eventlet==0.25.1
pip3 install celery==4.2.0
pip3 install redis==3.4.1
pip3 install pymongo==3.10.1
pip3 install flower==0.9.2
3. python代码
- 代码目录如下:
celery_test目录:
│ celery_config.py #记录celery配置文件
│ producer.py #任务生产者
│ test.py #test项目文件
- celery_config.py代码:
# coding:utf-8
from datetime import timedelta
from celery.schedules import crontab
C_FORCE_ROOT = True
CELERY_ENABLE_UTC = False
CELERY_TIMEZONE = 'Asia/Shanghai'
# broker
BROKER_URL = 'redis://192.168.6.34:6379/0'
CELERY_TASK_RESULT_EXPIRES = 60 * 60 * 24 # 任务过期时间
CELERY_RESULT_BACKEND = 'mongodb://192.168.6.34:27017/'
CELERY_RESULT_BACKEND_SETTINGS = {
"database":"task",
"taskmeta_collection":"stock_taskmeta_collection",
"max_pool_size":100,
}
CELERY_TASK_ROUTES = {
'test.tasks.add':{'queue':'add'},
}
celery配置的py文件中清楚配置了broker地址、mongodb地址、celery时区、任务过期时间和任务路由等。
- test.py代码:
# coding:utf-8
from celery import Celery,platforms
import time
app = Celery('test') #加载celery项目,test这个名字必须与test.py的test相对应
app.config_from_object('celery_config') #同理,celery_config名字也是与配置py文件名字相对应
platforms.C_FORCE_ROOT = True
@app.task(name='add_sleep_2') #定义个测试函数,睡2秒,然后返回结果
def add_sleep_2(x, y):
time.sleep(2)
return x + y
@app.task(name='add_sleep_60') #定义个测试函数,睡60秒,然后返回结果
def add_sleep_60(x, y):
time.sleep(60)
return x + y
- producer.py代码:
# coding:utf-8
from celery import Celery
import time
from celery.utils.log import get_task_logger
app = Celery('test') #加载celery项目,test这个名字必须与test.py的test相对应
app.config_from_object('celery_config') #同理,celery_config名字也是与配置py文件名字相对应
logger = get_task_logger(__name__)
@app.task(name='add_sleep_2') #这个函数还是要定义遍,而且要一模一样,或者直接从test.py引入也行
def add_sleep_2(x, y):
time.sleep(2)
return x + y
@app.task(name='add_sleep_60') #这个函数还是要定义遍,而且要一模一样,或者直接从test.py引入也行
def add_sleep_60(x, y):
time.sleep(60)
return x + y
def start_add_sleep_2():
print("[*]Start function start_add_sleep_2")
r = add_sleep_2.apply_async((2, 2), queue='add')
# r = add_sleep_2.delay(2, 2)
print(r.ready())
# print(r.result)
print(r.get())
print(r.ready())
# print(r.successful())
print("[*]Done")
def start_add_sleep_60():
print ("[*]Start function start_add_sleep_60")
r = add_sleep_60.delay(3, 3)
# print r.ready()
print (r.result)
print (r.get())
print(r.ready())
print ("[*]Done")
if __name__=="__main__":
start_add_sleep_2()
#start_add_sleep_60()
4. celery各组件运行
demo毕竟是有多台服务器的多个组件构成的,启动总要有个先后顺序吧,启动顺序具体如下:
- broker(redis)和数据库(mongodb)启动
- 多个worker启动
- flower启动,打开web页面
- producer启动,生成任务
(1)redis和mongodb启动
- 先在centos7上启动redis和mongodb,我这边都是用docker起的:

(2)worker启动
- windows worker启动:进入celery_test项目目录,
celery -A test worker -l info -P eventlet -n win -Q add,-A指定项目名,windows机器上必须加上-P eventlet启动,否则会出错,-n指定当前worker名字,-Q指定该worker监听一个或多个任务队列。
根据cmd回显结果,可以看到redis和mongodb都成功连上了,两个函数也成功注册。

- linux worker启动:进入celery_test项目目录,
celery -A test worker -l info -n linux,从回显看也是redis和mongodb都连上了,两个函数也注册成功。

(3)flower启动
- windows机器上,进入celery_test项目目录,
flower -A test --port=5555 --address=0.0.0.0 --persistent=True,-A指定项目名,port指定web端监听端口,address指定地址,persistent为true指定flower在本地保存当前状态。

- windows机器上,访问http://127.0.0.1:5555,结果如下,可以对各个worker和任务进行管理:

查看linux worker的状态:

查看任务状态:

查看任务队列状态:

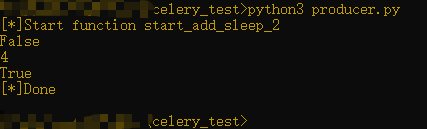
(4)producer产生任务:python3 producer.py,并在终端打印结果。由于我这个demo会将结果存在mongodb中,所以也可以去数据库中查下结果。

supervisor启动celery
线上环境中,为了celery高可用性,肯定需要配置celery自动失败重启和开机自启动等,保证celery服务端和客户端的可用性。
此处以客户端celery为例,在centos7中通过python3的supervisor实现对celery客户端的管理,大致步骤如下:
- 创建
/etc/supervisor/supervisord.conf配置文件,内容如下:
[unix_http_server]
file=/tmp/supervisor.sock ; path to your socket file
port=127.0.0.1:9001
[supervisord]
logfile=/var/log/supervisord/supervisord.log ; supervisord log file
logfile_maxbytes=50MB ; maximum size of logfile before rotation
logfile_backups=10 ; number of backed up logfiles
loglevel=info ; info, debug, warn, trace
pidfile=/var/run/supervisord.pid ; pidfile location
nodaemon=false ; run supervisord as a daemon
minfds=1024 ; number of startup file descriptors
minprocs=200 ; number of process descriptors
user=root ; default user
childlogdir=/var/log/supervisord/ ; where child log files will live
[rpcinterface:supervisor]
supervisor.rpcinterface_factory = supervisor.rpcinterface:make_main_rpcinterface
[supervisorctl]
serverurl=unix:///tmp/supervisor.sock ; use unix:// schem for a unix sockets.
[include]
# Uncomment this line for celeryd for Python
;files=celeryd.confi
files = /etc/supervisor/supervisord.conf.d/*.conf
- 创建
/etc/supervisor/supervisord.conf.d/celeryd_worker.conf文件,内容如下:
[program:celery]
command=celery -A celery_tasks.main worker -l info -P gevent --without-heartbeat
directory=/home/xxx/xxx # 运行命令的目录
numprocs=1
# 设置log的路径
stdout_logfile=/var/log/supervisor/celeryworker.log
stderr_logfile=/var/log/supervisor/celeryworker.log
autostart=true
autorestart=true
startsecs=10
stopwaitsecs = 600
priority=15
- 创建日志文件目录:
mkdir -p /var/log/supervisor和mkdir -p /var/log/supervisord - 创建
/etc/systemd/system/supervisord.service文件,此文件用于在centos中通过服务起supervisord,内容如下:
[Unit]
Description=Process Monitoring and Control Daemon
After=rc-local.service nss-user-lookup.target
[Service]
Type=forking
ExecStart=/usr/local/bin/supervisord -c /etc/supervisor/supervisord.conf
ExecStop=/usr/local/bin/supervisord shutdown
ExecReload=/usr/local/bin/supervisord reload
KillMode=process
Restart=on-failure
RestartSec=42s
[Install]
WantedBy=multi-user.target
- 输入
systemctl start supervisord启动supervisor,之后celery会自动启动:

通过supervisorctl status命令可发现celery成功运行:

celery问题
-
服务和客户端代码同步问题
如果你完整运行过上面的代码,会发现一个问题,也是我目前认为celery最大的一个缺点:
任务的具体逻辑代码在server端和client端都需要有,那么问题来了,一个server和client还好,如果是7,8个甚至十几个client端怎么办?我微调下任务代码,十几台服务器代码都要动?
celery官方也承认了这个问题,最新官方文档中阐述如下,链接https://docs.celeryproject.org/en/stable/userguide/tasks.html#how-it-works:

大致意思是发送任务时,不会把具体的任务逻辑代码发给任务队列,传递的只有任务名,worker在接收到任务后,会去自己的本地代码中找该函数然后执行。这意味着任务生产者和多个消费者必须保证任务代码完全相同。 -
celery序列化传递数据问题
服务端在使用celery向客户端传递数据时,有时可能会出现如下问题:
kombu.exceptions.EncodeError:Object of type is not JSON serializable
原因是celery4版本的 默认使用 JSON 作为 serializer ,而 celery3版本的默认使用 pickle。
所以为了让报错消除,需要添加设置:
from celery import platforms
CELERY_TASK_SERIALIZER = 'pickle'
CELERY_RESULT_SERIALIZER = 'pickle'
CELERY_ACCEPT_CONTENT = ['pickle', 'json']
platforms.C_FORCE_ROOT = True
参考资料
资料最好还是看英文的吧,中文的celery还有很多没翻译完。
- celery github地址:https://github.com/celery/celery
- celery英文手册:https://docs.celeryproject.org/en/stable/index.html
- celery中文手册:https://www.celerycn.io/
- flower github地址:https://github.com/mher/flower
- flower英文手册:https://flower.readthedocs.io/en/latest/
- flower中文手册:https://flower-docs-cn.readthedocs.io/zh/latest/















 837
837











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









