






一.类型转换
概念:不一致但相互兼容的数据类型,在同一表达式中将会发生类型转换。
转换模式如下
隐式转换:系统按照隐式规则自动进行的转换
强制转换:用户显式自定义进行的转换
隐式规则:从小类型向大类型转换,目的是保证不丢失表达式中数据的精度
隐式转换代码:
char a = 'a';
int b = 12;
float c = 3.14;
float x = a + b - c; // 在该表达式中将发生隐式转换,所有操作数被提升为float
强制转换:用户强行将某类型的数据转换为另一种类型,此过程可能丢失精度
char a = 'a';
int b = 12;
float c = 3.14;
int d = (int)c;
float x = a + b - (int)c; // 在该表达式中a隐式自动转换为int,c被强制转为int
二,整型数据尺寸
概念:整型数据尺寸是指某种整型数据所占用内存空间的大小 C语言标准并未规定整型数据的具体大小,只规定了相互之间的 “ 相对大小 ” ,比如: short 不可比 int 长 long long 不可比 int 短 long 型数据长度等于系统字长(32位操作系统(2^32)long是占用4字节,64位操作系统(2^64)long 是占用 8字节)
系统字长:CPU 一次处理的数据长度,称为字长。比如32位系统、64位系统。
典型尺寸: char 占用1个字节 short 占用2个字节 int 在16位系统中占用2个字节,在32位和64位系统中一般都占用4个字节 long 的尺寸等于系统字长 long long 在32位系统中一般占用4个字节,在64位系统中一般占用8个字节
存在问题: 同样的代码,放在不同的系统中,可能会由于数据尺寸发生变化而无法正常运行。 因此,系统标准整型数据类型,是不可移植的,这个问题在底层代码中尤为突出。
三,可移植性整型 概念:不管放到什么系统,尺寸保持不变的整型数据,称为可移植性整型
关键:typedef
typedef int int32_t; // 将类型 int 取个别名,称为 int32_t
typedef long int64_t; // 将类型 long 取个别名,称为 int64_t
思路: 1. 为所有的系统提供一组固定的、能反应数据尺寸的、统一的可移植性整型名称
2. 在不同的系统中,为这些可移植性整型提供对应的 typedef 语句 系统预定义的可移植性整型:
int8_t int16_t int32_t int64_t uint8_t uint16_t uint32_t uint64_t
四,运算符
1. 算术运算符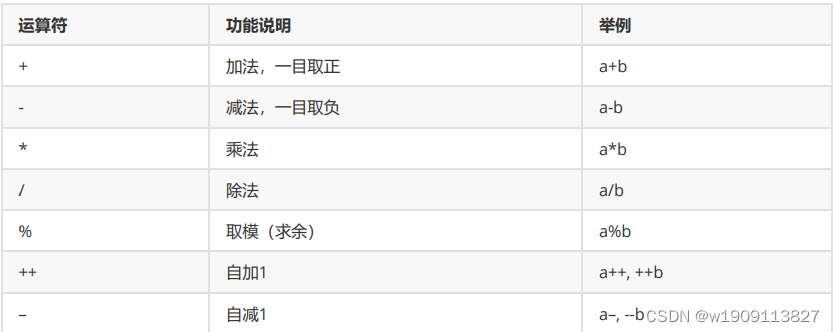
% 是算术运算符的重点,一般将某个数值控制在一定范围内,还有数据解析上
/与%在处理数据的时候可以进行提取低字节或者高字节数据比如0x123%10,或者0x123/10,应用场景比如温湿 度的截取
2,单目运算符 目:目标操作数 ++ -- +(正号) -(负号) 前后缀运算:
(1). 前缀自加自减运算:先进行自加自减,再参与表达式运算(++a)
(2). 后缀自加自减运算:先参与表达式运算,在进行自加自减(a++)
3,双目运算符
+ - * / %
4,关系运算符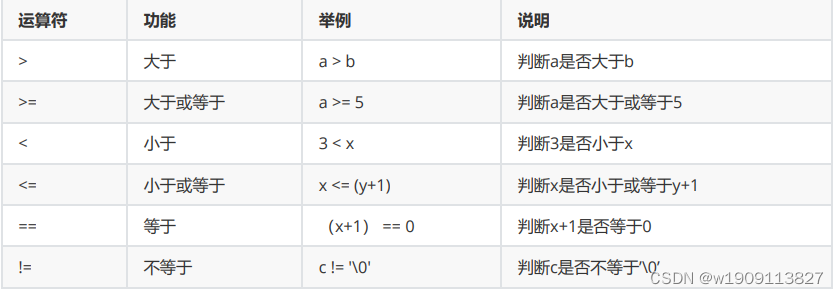
5,逻辑运算符
运算规则:
逻辑反:将逻辑真、假翻转,即真变假,假变真
逻辑与:将两个关系表达式串联起来,当且仅当左右两个表达式都为真时,结果为真。
逻辑或:将两个关系表达式并联起来,当且仅当左右两个表达式都为假时,结果为假。
6. 位运算符(重点,对整个变量的某一位操作)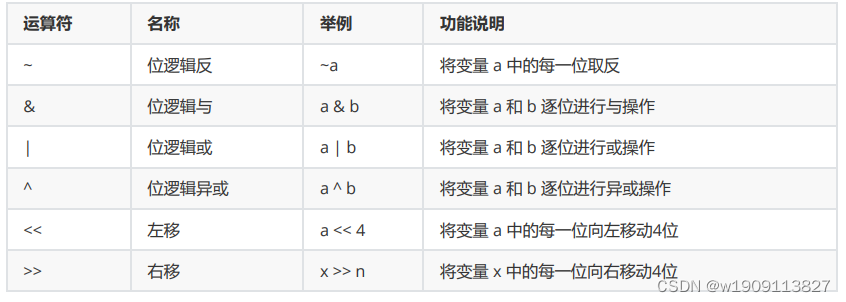
7,条件运算符(三目运算符,重点) 唯一需要三个操作数的运算符
语法:表达式1?表达式2:表达式3
释义:当表达式1为真时,去表达式2,否则取表达式3
例如 int a = 200;
int b = 100;
int m = (a>b) ? a : b; // 如果 a>b 为真,则 m 取 a 的值,否则取 b 的值
8.优先级与结合性
当表达式出现不同的运算符时,根据优先级来决定谁先执行,比如先乘除后加减 当表达式中出现多个相同优先级的运算符时,更具结合性决定谁先运行,比如从左到右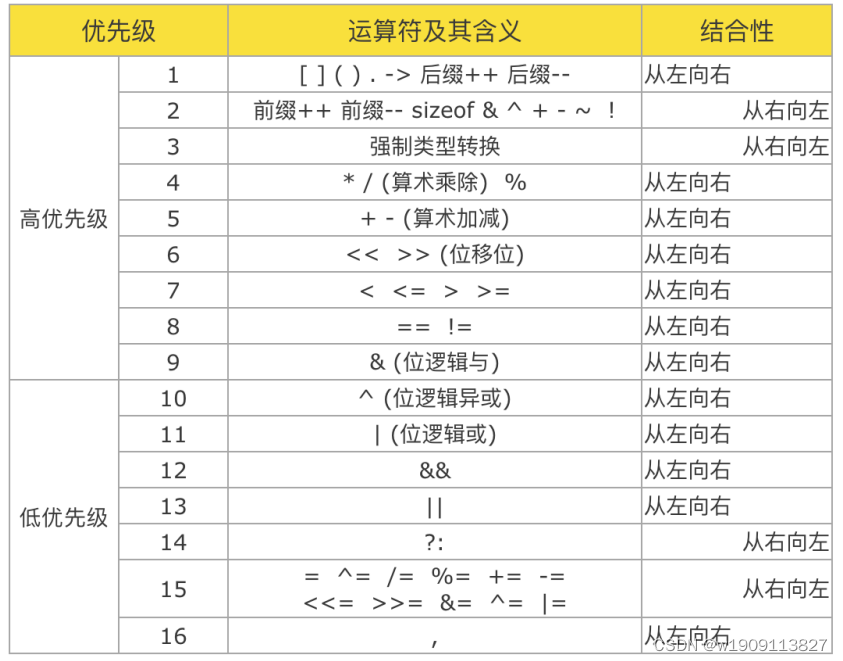
五,控制流
二路分支
-
逻辑:程序中某段代码需要在满足某个条件时才能运行
-
形式:
-
if语句:表达一种 如果-则的条件执行关系
-
if-else语句:表达一种 如果-否则 的互斥分支关系
-
举例:
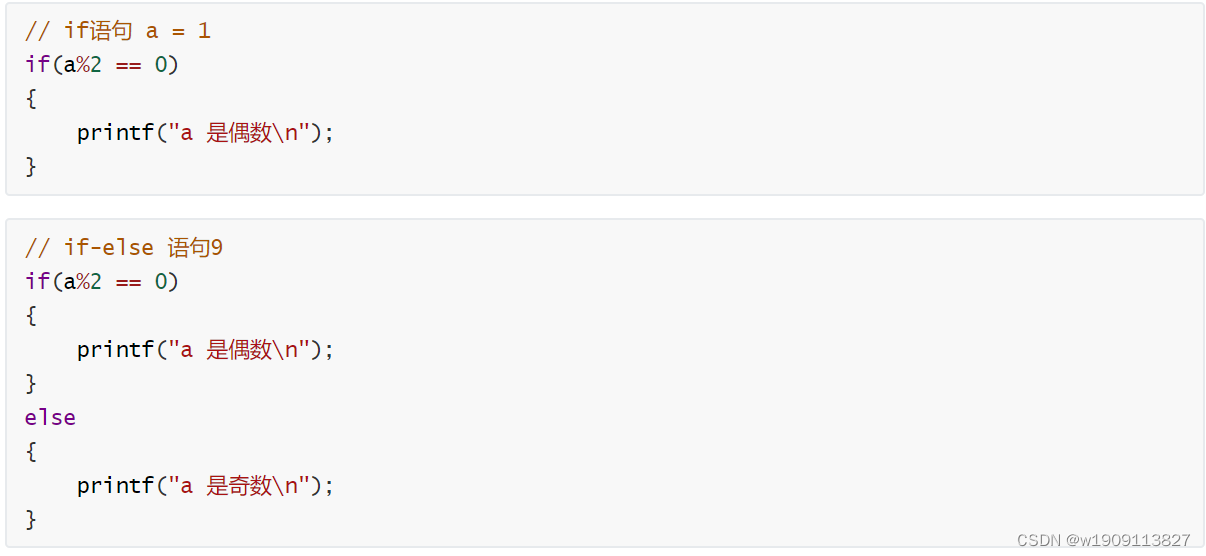


注意:
-
只要表达式的值为真(非0),则执行{}复合语句
-
if语句可以单独使用,else语句不可以,else语句必须根if语句配套使用
-
不管是if语句还是else语句,代码块都必须使用大括号{}括起来,否则只有首句有效
多路分支
-
辑:根据不同的条件执行不同的代码片段
-
语法:
-
switch(n)//条件
{
case 1:
printf("one\n");
break;
case 2:
printf("two\n");
break;
case 3:
printf("three\n");
break;
default:
printf("其他数字\n");
}要点解析
-
switch(n)语句中的n必须是一个整型表达式,即switch判断的数据必须是整型或者字符
-
case语句只能带整型常量,包括普通整型或字符,不包括const型数据
-
break语句的作用是跳出整一个switch结构,没有break程序会略过case往下执行
-
default语句不是必须的,一般放在最后面(因此不需要break)
while与do...while循环
逻辑:使得程序中每一段代码可以重复循环的运行
形式:
-
while循环:先判断,再循环
while(表达式)// 表达式的值为真的时候进入循环体,为假退出
{
}
while(1)// 死循环 等价于 while(1);
{
}
如果循环体内只有一条语句,那么{}可以省略
while(1)
printf("11\n");
do-while循环:先循环,再判断
格式
do
{
循环体;
}while(表达式)
for循环
-
逻辑:与 while 循环类似,但更加紧凑,for 循环将控制循环的变量集中在一行
-
for(初始表达式1;判断表达式2;循环操作表达式3)
{
循环体;
}
// 第一条表达式只执行一遍i = 0只执行一遍
// 然后执行表达式2,判断i 是否小于等于5,如果为真则执行{}里面的内容
// 最后执行表达式3,i++
// 然后一次循环完成再重新执行表达式2,判断i是否小于5,如果为真会执行
// {}里面的内容,最后执行表达式3,i++,依次类推,直到表达式2为假
// 则退出循环体
for(int i = 0; i <= 5; i++)
{
printf("i:%d\n",i);
}
// 死循环
for(;;)
{
}
或者
for(;;);
//多变量
for(int i = 0,j = 0; i < 5; i++,j++)
{
printf("i:%d j:%d\n",i,j);
}
for嵌套
int main(int argc, char const *argv[])
{
for(int i = 0; i < 5; i++)// 外循环
{
for(int j = 0; j < 4; j++)// 内循环
{
printf("i:%d j:%d\n",i,j);
}
}
return 0;
}
break(退出)与continue(继续)
-
运用场景与特点
-
break关键字只能用于循环(while for do...while)和switch语句中,表示结束循环或者跳出switch语句
-
break关键字只能跳出最近一层的循环,也就是说,如果有多重循环,只能跳出最靠近break语句那层循环
-
break关键字 不能 单独用于 if语句中,除非if语句外面包含了循环
-
-
逻辑:
-
continue关键字只能用于循环体中(while do...while for),用于提前结束当前循环体后,又从最近一层循环体开始执行
-
continue关键字不能 单独用于 if语句或者switch 语句中,除非外面包含了循环
-
break:① 跳出 switch 语句; ② 跳出当层循环体
-
continue:结束当次循环,进入下次循环
-
六,数组初阶
基本概念
-
数组的概念
-
由相同类型的多个元素所组成的一种复合数据类型
-
在工程中同时定义多个相同类型的变量时,重复定义,可以使用数组
-
-
逻辑:一次性定义多个相同的变量,并存储到一片连续的内存中
-
格式
-
类型说明符 数组名[整型常量表达式];
-
类型说明符:指定数组元素的数据类型,任意c语言合法类型都可以
-
数组名 : c语言标识符,其值为该数组的首地址(常量)
-
int a[5];//定义一个数组a,该数组一个由五个元素,每个元素都是int类型
int size = 4;
int array[size];//变长数组,如果式局部变量则正确,全局变量编译出错
-
语法释义:
-
a是数组名,即这片连续内存的名称
-
[5]代表这片连续内存总共分成5个相等的格子,每个格子称为数组的元素
-
int代表每个元素的类型,可以是任意基本类型,也可以是组合类型,甚至可以是数组
-
数组中所有元素的类型都是一致
-
数组申请的空间是连续的,从低地址到高地址依次连续存放数组中的每个元素
数组定义
#include <stdio.h>
int main(int argc, char const *argv[])
{
// 申请5块连续的空间,将a称为数组
int a[5];
// 将这5块空间逐一赋值,注意,数组下标从0开始
a[0] = 1;
a[1] = 20;
a[2] = 30;
a[3] = 40;
a[4] = 50;
//a[5] = 60; // 越界,无法使用
printf("%d\n",a[4]);
// 循环给数组a赋值
for(int data = 10,i = 0; i < 5; i++,data+=10)
{
a[i] = data;
}
// 遍历输出
for(int i = 0; i < 5; i++)
{
printf("%d\n",a[i]);
}
return 0;
}
初始化:在定义的时候赋值,称为初始化
// 正常初始化
int a[5] = {100,200,300,400,500};
int a[5] = {100,200,300,400,500,600}; // 错误,越界了
int a[ ] = {100,200,300}; // OK,自动根据初始化列表分配数组元素个数
int a[5] = {100,200,300}; // OK,只初始化数组元素的一部分
// 不能在使用变长数组的情况下初始化数组
int a[size] = {1,2,3};//编译出错
// 变长数组只能先定义再使用
int a[size]; // 正确的
a[0] = 10;
测量数组的总大小:sizeof(array)
测量数组元素个数:sizeof(array)/sizeof(array[0])
数组名[下标]
"下标":C语言的下标是从0开始,下标必须是>=0的整数
a[0]、a[1]、a[n]
引用数组元素a[i]和普通变量一样,既可以作为左值,也可以作为右值
下标最小值为0,最大值为 元素个数 -1
int a[5]; // 有效的下标范围是 0 ~ 4
a[0] = 1;
a[1] = 66;
a[2] = 21;
a[3] = 4;
a[4] = 934;
a[5] = 62; // 错误,越界了
a = 10; // 错误,不可对数组名赋值















 1246
1246











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









