







机器学习小白必看!从零到一构建模型全流程
在机器学习的世界里,构建一个模型就像搭建一座桥梁,连接着数据和预测结果。对于初入此领域的小伙伴,可能会觉得无从下手,别担心,今天就带你梳理一下从获取数据到模型评估的完整流程,让你轻松上手!
一、工作流程
机器学习项目的推进有章可循,主要涵盖以下几个关键步骤:
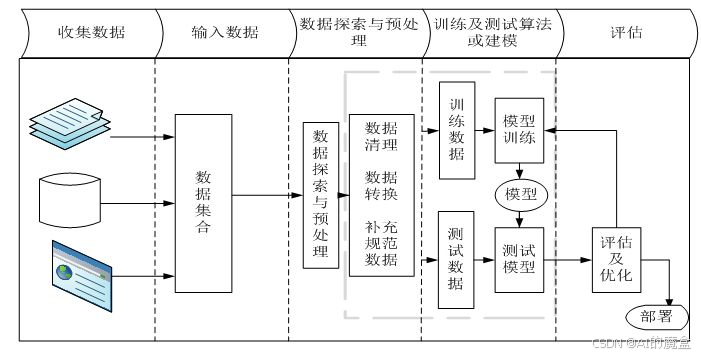
1.1 获取数据
这是整个项目的基础,如同盖房子得先有砖石。数据来源多样,可能是业务系统导出的表格、公开的数据集网站下载,又或是通过爬虫技术合规抓取。拿到数据后,要初步了解它的规模、类型等信息。
1.2 数据基本处理
原始数据往往 “脏乱差”,缺失值、异常值频现。缺失值可能是因为采集失误,比如一份用户信息表里,部分用户的年龄一栏空缺;异常值则像是传感器偶尔出错,记录下远超正常范围的数据。这时候,我们要么删除问题数据,要么用合理方式填补,让数据变得干净整洁。
1.3 特征工程
这一步堪称魔法时刻,把原始数据变换成机器学习算法更易理解的形式。毕竟,算法不是万能的,数据得 “投其所好”,好的特征能让模型事半功倍。
1.4 模型训练
拿着处理好的数据,喂给选定的算法,就像老师教学生,通过大量 “案例” 让模型学习数据里的规律。这个过程要不断调整模型参数,找到最优解。
1.5 模型评估
训练好的模型不能 “王婆卖瓜”,得用测试数据检验它的真本事。通过一系列指标,判断模型是学得刚好,还是过拟合(记住训练数据太死板,遇新情况就懵)、欠拟合(没掌握核心规律)。
二、获取数据集介绍
数据集是机器学习的 “粮食”,了解它的构成至关重要。
2.1 专有名称
- 样本 :想象一张张病历,每张病历就是一个样本,也就是数据表里的一行,记录着某个个体或事件的完整信息;对于图片数据,一张图片就是一个样本。
- 特征 :在病历里,患者的年龄、体温、症状等就是特征,对应数据表的一列,或是图片里的纹理、形状等细节。
- 目标值(标签值) :这是我们想预测的结果,比如根据病历特征判断患者是否患有某种疾病,患病与否就是目标值。
- 特征值 :就是特征对应的数值,比如年龄是 30 岁,体温是 37.5 度。
2.2 数据类型构成
- 类型一 :包含特征值和目标值。特征值又分连续的,像身高、体重这类可无限取值;离散的,如班级人数、房间数这类有固定间隔和数量。
- 类型二 :只有特征值,没有目标值。这类数据常用于无监督学习,算法自己去挖掘数据里的潜在结构,比如给定一群顾客的消费习惯数据,找出不同消费群体。
2.3 数据分割
数据集不能一股脑全用来训练,得合理分配:
- 训练数据 :占比 7 - 8 成,是模型的 “课堂”,让模型在上面学习规律,不断优化自己。
- 测试数据 :剩下 2 - 3 成,相当于 “期末考试”,模型训练完,用它来验证学得怎么样,评估模型对未知数据的处理能力。
三、数据基本处理
前面提到数据常有缺失值、异常值,具体处理手段如下:
- 缺失值处理 :要是缺失比例很小,直接删除相关样本;要是特征重要,可以用均值、中位数、众数填补,比如年龄特征缺失,用平均年龄补上。
- 异常值处理 :统计学里,可以用箱线图判断异常值,超出上下界的就是;处理时,要么把异常值修正到合理范围,要么直接剔除,避免干扰模型训练。
四、特征工程
这是机器学习的 “点金术”,让数据发光发热。
4.1 定义
把原始、杂乱的数据,转换成能凸显信息、方便算法处理的形式。就好比把一堆乱石雕刻成精美的雕塑,让算法一眼就能看懂数据价值。
4.2 目标
数据和特征决定了机器学习模型的上限,模型和算法只是尽力去逼近这个上限。换句话说,特征不好,再厉害的算法也巧妇难为无米之炊。
4.3 包含内容
- 特征提取 :从原始数据里挑出有用的特征。比如在文本数据里,提取关键词;图像数据里,提取边缘、轮廓等。
- 特征预处理 :把特征数值范围映射到合适区间。像像素值原本 0 - 255,可能归一化到 0 - 1,让模型训练更稳定、收敛更快。
- 特征降维 :当特征太多,模型容易过拟合,计算量也大。通过主成分分析(PCA)等方法,减少特征数量,保留主要信息。
五、机器学习
到了这一步,就是挑选合适的 “武器” ——算法,开启训练之旅。算法众多,监督学习里有线性回归、决策树、支持向量机;无监督学习有 K - 均值聚类、关联规则挖掘等。要根据数据类型、目标值情况、问题复杂度来选,比如预测房价(连续值),线性回归可能合适;分类垃圾邮件(离散类别),决策树表现不错。
六、模型评估
训练好的模型,得拉出来遛遛,看看成色。
常见的评估指标有:
- 分类问题 :准确率(预测正确的比例)、召回率(实际正例中预测为正例的比例)、F1 - score(准确率和召回率的调和平均)。
- 回归问题 :均方误差(MSE,预测值和真实值差的平方均值)、平均绝对误差(MAE,预测值和真实值差的绝对值均值)。
根据这些指标,判断模型是否靠谱,若不理想,还得回头调整特征工程、算法参数等,反复迭代优化。
接下来上我的代码
# coding:utf-8
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split,GridSearchCV
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
# 1、获取数据集
iris = load_iris()
# 2、数据基本处理
# 2.1 数据分割
# x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=22, test_size=0.2)
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2)
# 3、特征工程
# 3.1实例化一个转化器
transfer = StandardScaler()
# 3.2 调用fit_transform方法进行标准化
x_train = transfer.fit_transform(x_train)
x_test = transfer.fit_transform(x_test)
print("测试集个数\n",x_test.shape[0])
# 4、模型训练
# 4.1 实例化一个估计器
estimator = KNeighborsClassifier(n_neighbors=5,algorithm='auto')
param_grid={'n_neighbors':[1,3,5,7,9,11]}
# 网格搜索器,为了解决寻找最合适的n_neighbors值
estimator = GridSearchCV(estimator,param_grid,cv=10,n_jobs=-1)
# 4.2 模型训练
estimator.fit(x_train, y_train)
# 5、模型评估
# 5.1 输出预测值
y_pre = estimator.predict(x_test)
print("预测值是:\n", y_pre)
print("预测值和真实值对比:\n", y_pre == y_test)
# 5.2 输出准确率
ret = estimator.score(x_test, y_test)
print("准确率是:\n", ret)
# 5.2其他的评估方法
print("最好的模型:\n", estimator.best_estimator_)
print("最好的结果:\n", estimator.best_score_)
print("整体模型结果:\n", estimator.cv_results_)
怎么样,看完是不是对机器学习从零搭建模型有了清晰的认识?赶紧动手实践,开启你的机器学习探索之旅吧!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









