






一、大数据分析流程前言
在当今数据驱动的时代,大数据分析已经成为企业决策、科研探索和政策制定中不可或缺的一部分。它涉及从大量复杂数据中提取有价值的信息,以支持更明智的决策。
大数据分析是一个复杂而系统的过程,它涉及数据的采集、处理、分析、可视化和应用等多个环节。这些环节相互关联、相互依存,共同构成了大数据分析的完整流程。大数据分析流程的目的是从海量、复杂的数据中提取有价值的信息,为决策提供科学依据。以下是大数据分析的基本流程及相关的常用技术:
二、大数据分析流程概述
- 数据采集:
- 数据采集是大数据分析的第一步,也是后续步骤的基础。
- 数据来源广泛,包括数据库、日志文件、传感器数据、第三方数据等。
- 采集方式多样,如实时采集、批量采集等。
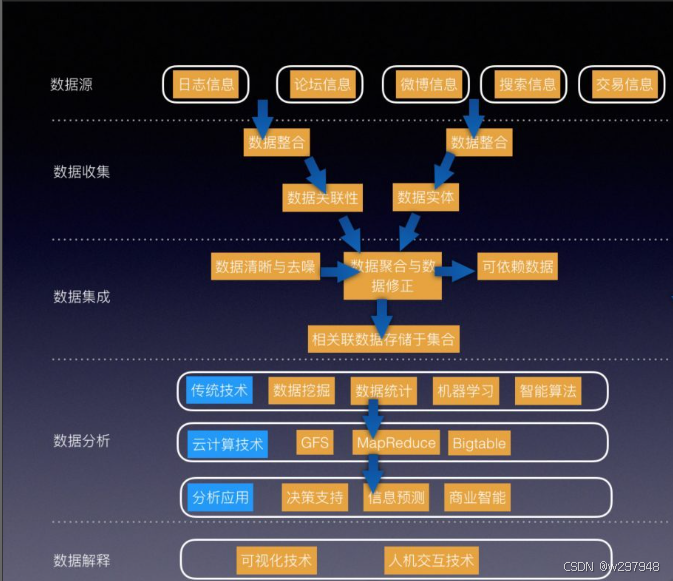
- 数据预处理:
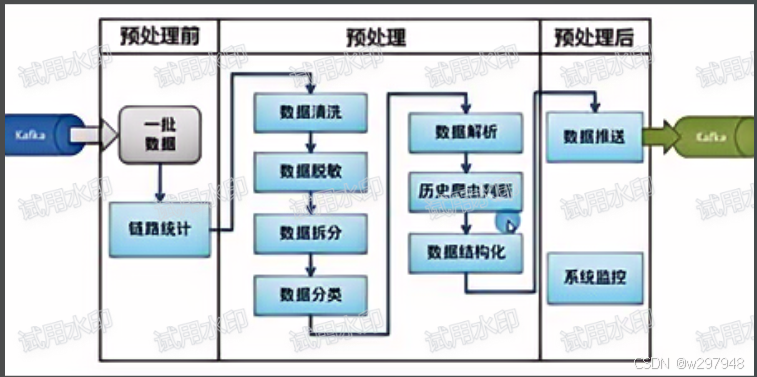
- 数据预处理是数据清洗、转换和合并的过程。
- 该步骤旨在去除无效或错误数据,提高数据质量。
- 常用的预处理技术包括填补缺失值、处理异常值、数据归一化等。
- 数据存储:
- 数据存储是将清洗后的数据存储在高效、分布式的存储系统中。
- 常用的存储技术包括Hadoop Distributed File System(HDFS)、HBase等。
- 这些技术能够确保数据的可靠性、可扩展性和高效性。

- 数据分析:
- 数据分析是大数据分析的核心环节,旨在从数据中提取有价值的信息。
- 常用的分析技术包括关联分析、聚类分析、朴素贝叶斯、随机森林等。
- 这些技术能够揭示数据之间的关联、发现数据中的模式和趋势。

- 数据可视化:
- 数据可视化是将分析结果转化为直观的图表、仪表盘等展示方式。
- 可视化有助于人们更直观地理解数据和分析结果。
- 常用的可视化工具包括Matplotlib、Tableau等。
三、大数据分析常用技术概述
- 数据采集技术:
- Apache Flume:用于日志数据的实时采集和传输。
- Apache Kafka:分布式消息队列,能够处理高吞吐量的实时数据流。
- Web爬虫:通过编写爬虫程序抓取网页数据。
import requests
from bs4 import BeautifulSoup
# 目标URL
url = 'https://example.com'
# 发送HTTP请求
response = requests.get(url)
# 检查请求是否成功
if response.status_code == 200:
# 解析HTML内容
soup = BeautifulSoup(response.content, 'html.parser')
# 查找并提取所需的数据
# 例如,提取所有的标题(假设标题在<h1>标签中)
titles = soup.find_all('h1')
for title in titles:
print(title.get_text())
else:
print(f"Failed to retrieve the webpage. Status code: {response.status_code}")
- 数据预处理技术:
- Pandas:用于小规模数据的清洗和处理,特别适合CSV、Excel等格式的数据。
- Apache Spark:支持大规模分布式数据的处理,适用于大规模数据清洗和转换。
1. 导入 Pandas 库
import pandas as pd
2. 创建 DataFrame
# 从字典创建 DataFrame
data = {
'Name': ['Alice', 'Bob', 'Charlie'],
'Age': [25, 30, 35],
'City': ['New York', 'Los Angeles', 'Chicago']
}
df = pd.DataFrame(data)
print(df)
3. 读取和写入文件
# 读取 CSV 文件
df = pd.read_csv('data.csv')
# 写入 CSV 文件
df.to_csv('output.csv', index=False)
4. 查看数据
# 查看前几行数据
print(df.head())
# 查看数据的基本信息
print(df.info())
# 描述性统计
print(df.describe())
5. 数据选择与过滤
# 选择单列
ages = df['Age']
# 选择多列
subset = df[['Name', 'City']]
# 根据条件过滤数据
filtered_df = df[df['Age'] > 30]
6. 数据清洗
# 处理缺失值
df.dropna() # 删除包含缺失值的行
df.fillna(value=0) # 用指定值填充缺失值
# 重命名列
df.rename(columns={'Name': 'Full Name'}, inplace=True)
7. 数据排序
# 按单列排序
sorted_df = df.sort_values(by='Age')
# 按多列排序
sorted_df = df.sort_values(by=['Age', 'Name'], ascending=[True, False])
8. 数据分组与聚合
# 按单列分组并计算均值
grouped = df.groupby('City').mean()
# 按多列分组并计算多个聚合函数
grouped = df.groupby(['City']).agg({'Age': ['mean', 'max'], 'Name': 'count'})
9. 合并与连接
# 合并两个 DataFrame
df1 = pd.DataFrame({'key': ['A', 'B', 'C'], 'value1': [1, 2, 3]})
df2 = pd.DataFrame({'key': ['A', 'B', 'D'], 'value2': [4, 5, 6]})
merged_df = pd.merge(df1, df2, on='key', how='inner')
# 连接两个 DataFrame(按索引)
concatenated_df = pd.concat([df1, df2], axis=1)
10. 应用自定义函数
# 定义一个自定义函数
def add_ten(x):
return x + 10
# 应用自定义函数到某一列
df['Age'] = df['Age'].apply(add_ten)
- 数据分析技术:
- 关联分析:用于描述多个变量之间的关联。
- 聚类分析:将数据集划分为多个簇,揭示数据的内在结构。
- 朴素贝叶斯:基于贝叶斯定理的分类算法,适用于文本分类等领域。
- 随机森林:集成学习方法,通过构建多个决策树来提高分类和回归的准确性。
- 数据可视化技术:
- Matplotlib:Python中的绘图库,支持多种图表类型。
- Tableau:商业智能和数据可视化工具,提供丰富的可视化组件和交互功能。
import matplotlib.pyplot as plt
# 数据
x = [1, 2, 3, 4, 5]
y = [2, 3, 5, 7, 11]
# 创建图形对象
plt.figure()
# 绘制折线图
plt.plot(x, y, marker='o', linestyle='-', color='b', label='Prime Numbers')
# 添加标题和标签
plt.title('Simple Line Plot')
plt.xlabel('X-axis')
plt.ylabel('Y-axis')
# 显示图例
plt.legend()
# 显示网格
plt.grid(True)
# 显示图形
plt.show()
四、大数据分析与常用总结
随着大数据技术的不断发展,越来越多的先进技术被应用于大数据分析中。这些技术不仅提高了数据分析的效率和准确性,还拓展了数据分析的应用领域。数据统计分析理论是现代科学研究和技术应用的基石之一。掌握这些基本概念和方法不仅有助于我们理解数据背后的规律,还能提高我们的决策能力和创新水平。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









