







本文出自:JShaman.com,一个专业的JS代码混淆平台。
防代码格式化,又称防代码美化、selfDefending。
意思是:将一段代码,经混淆加密,输出的代码是被压缩到一行的,这一行代码不可使用格式化手段变为多行,使其容易阅读。如果格式化,代码则不能运行。
如:
var a=1;经反格式化保护后的代码:
var _0x5647a6=function(){var _0xf77285=!![];return function(_0x138773,_0x1b2add){var _0x5d2349=_0xf77285?function(){if(_0x1b2add){var _0x5daeb2=_0x1b2add['apply'](_0x138773,arguments);_0x1b2add=null;return _0x5daeb2;}}:function(){};_0xf77285=![];return _0x5d2349;};}();var _0x16e48a=_0x5647a6(this,function(){return _0x16e48a['toString']()['search']('(((.+)+)+)+$')['toString']()['constructor'](_0x16e48a)['search']('(((.+)+)+)+$');});_0x16e48a();var a=0x1;这段代码,是不能被格式化的,如果格式化,如下:
var _0x5647a6 = function() {
var _0xf77285 = !![];
return function(_0x138773, _0x1b2add) {
var _0x5d2349 = _0xf77285 ?
function() {
if (_0x1b2add) {
var _0x5daeb2 = _0x1b2add['apply'](_0x138773, arguments);
_0x1b2add = null;
return _0x5daeb2;
}
}: function() {};
_0xf77285 = ![];
return _0x5d2349;
};
} ();
var _0x16e48a = _0x5647a6(this,
function() {
return _0x16e48a['toString']()['search']('(((.+)+)+)+$')['toString']()['constructor'](_0x16e48a)['search']('(((.+)+)+)+$');
});
_0x16e48a();
var a = 0x1;然后再执行,则会出错,如在浏览器中报错:Uncaught InternalError: too much recursion

在nodejs中报错:

很奇怪!
同样的代码,加了换行,与不加换行,执行结果竟然不同!
为什么?
找原因:
1、用fc比较两者,看两段代码差异:

失败,因为换行也被识别为差异,这样的方式比较不出结果。
2、比较ast(抽象语法树)
得到两段代码的ast,再进行比较。

fc这两个ast:

是能比较出,但还是因为行号的原因,差异还是非常大。不可用。
3、自写程序,获取ast并比较
未格式化前:
const esprima = require('esprima')
const estraverse = require('estraverse')
var escodegen = require('escodegen');
const { expressionStatement } = require('@babel/types');
//测试用,要处理的js代码
const code = `
var _0x53aa35=function(){var _0x41e828=!![];return function(_0x15be79,_0xbd3dcc){var _0xe1c04d=_0x41e828?function(){if(_0xbd3dcc){var _0x52f8eb=_0xbd3dcc['apply'](_0x15be79,arguments);_0xbd3dcc=null;return _0x52f8eb;}}:function(){};_0x41e828=![];return _0xe1c04d;};}();var _0x2a1040=_0x53aa35(this,function(){return _0x2a1040['toString']()['search']('(((.+)+)+)+$')['toString']()['constructor'](_0x2a1040)['search']('(((.+)+)+)+$');});_0x2a1040();var a=0x1;
`
//生成 AST
const ast = esprima.parseScript(code,{ comment: true })
console.log(JSON.stringify(ast))得到AST:

格式化后的代码:
const esprima = require('esprima')
const estraverse = require('estraverse')
var escodegen = require('escodegen');
const { expressionStatement } = require('@babel/types');
//测试用,要处理的js代码
const code = `
var _0x53aa35 = function() {
var _0x41e828 = !![];
return function(_0x15be79, _0xbd3dcc) {
var _0xe1c04d = _0x41e828 ?
function() {
if (_0xbd3dcc) {
var _0x52f8eb = _0xbd3dcc['apply'](_0x15be79, arguments);
_0xbd3dcc = null;
return _0x52f8eb;
}
}: function() {};
_0x41e828 = ![];
return _0xe1c04d;
};
} ();
var _0x2a1040 = _0x53aa35(this,
function() {
return _0x2a1040['toString']()['search']('(((.+)+)+)+$')['toString']()['constructor'](_0x2a1040)['search']('(((.+)+)+)+$');
});
_0x2a1040();
var a = 0x1;
`
//生成 AST
const ast = esprima.parseScript(code,{ comment: true })
console.log(JSON.stringify(ast))
require("fs").writeFileSync(__dirname + "/" + "1ast.txt",JSON.stringify(ast))比较前后ast的差异:

无差异!
4、分析无果,只好借助搜索引擎。
某度是无效的,上bing:

找出一些相关内容:
Javascript是如何进行自我保护的?它是如何在美化后进入无限循环的?:

该stackoverflow上的问题代码与本文上述类似:
var _0x2a3a06=function(){var _0x409993=!![];return function(_0xe0f537,_0x527a96){var _0x430fdb=_0x409993?function(){if(_0x527a96){var _0x154d06=_0x527a96['apply'](_0xe0f537,arguments);_0x527a96=null;return _0x154d06;}}:function(){};_0x409993=![];return _0x430fdb;};}();var _0x165132=_0x2a3a06(this,function(){var _0x46b23c=function(){var _0x4c0e23=_0x46b23c['constructor']('return\x20/\x22\x20+\x20this\x20+\x20\x22/')()['constructor']('^([^\x20]+(\x20+[^\x20]+)+)+[^\x20]}');return!_0x4c0e23['test'](_0x165132);};return _0x46b23c();});_0x165132();console['log']();该问题的回复是这样:
对代码进行格式化,并替换变量(修改乱码变量为容易理解的变量,得到如下代码):
var makeRun = function() {
var firstMakeRun = true;
return function(global, callback) {
var run = firstMakeRun ? function() {
if (callback) {
var result = callback['apply'](global, arguments);
callback = null;
return result;
}
} : function() {};
firstMakeRun = false;
return run;
};
}();
var run = makeRun(this, function() {
var fluff = function() {
var regex = fluff['constructor']('return /" + this + "/')()['constructor']('^([^ ]+( +[^ ]+)+)+[^ ]}');
return !regex['test'](run);
};
return fluff();
});
run();
console['log']()重要的部分是它针对run函数本身测试regex/^([^]+(+[^]+)+)+[^]}/并执行隐式run.toString()。现在无限循环在哪里?没有,但应用于包含大量空格的字符串的正则表达式确实表现出灾难性的回溯。试着用制表符而不是空格来运行缩进的代码,结果会很好——只要run函数不包含多个空格,并且结尾}前面没有空格,regex就会匹配,就不会无限循环了。
回到本文的程序,则可知,重点在:
function() {
return _0x16e48a['toString']()['search']('(((.+)+)+)+$')['toString']()['constructor'](_0x16e48a)['search']('(((.+)+)+)+$');
});其实,别的代码不重要,只要构建这一行代码,即可以实现同样的效果:
console.log("start");
function t(){
return t.toString().search('(((.+)+)+)+$').toString();
}
a=t();
console.log("end");运行这段代码,会发现,程序执行不到log("end"),

但如果去掉t函数中的回车换行:
console.log("start");
function t(){ return t.toString().search('(((.+)+)+)+$').toString();}
a=t();
console.log("end");则运行正常:

那么,重点中的重点找到了,就是serach语句。
serach与indexof相似,不同的是 search 是强制正则表达式的,而 indexOf 只是按字符串匹配的。serach将(((.+)+)+)+$视为正则表达式进行匹配。
到此,大体明白了它的原理了,其实也就是递归,让程序执行不下去。
再来看正则表达式:(((.+)+)+)+$
“.”:匹配除 "\n" 之外的任何单个字符。
“+”:匹配前面的子表达式一次或多次。
(pattern): 匹配 pattern 并获取这一匹配。所获取的匹配可以从产生的 Matches 集合得到,在VBScript 中使用 SubMatches 集合,在JScript 中则使用 $0…$9 属性。
“$”: 与字符串结束的地方匹配,不匹配任何字符
测试正则表达式:
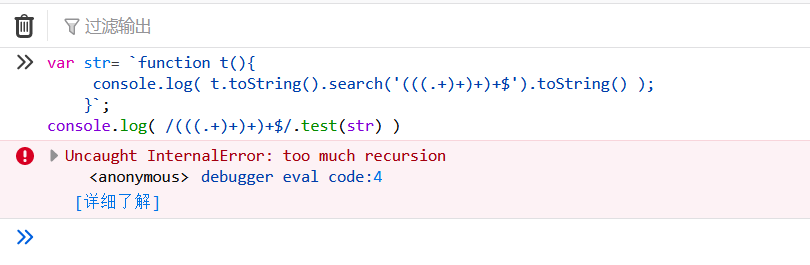
var str= `function t(){ console.log( t.toString().search('(((.+)+)+)+$').toString() );}`;
console.log( /(((.+)+)+)+$/.test(str) )
console.log("start");执行:

但如果改为带换行的语句:
var str= `function t(){
console.log( t.toString().search('(((.+)+)+)+$').toString() );
}`;
console.log( /(((.+)+)+)+$/.test(str) )
console.log("start");执行会被卡死:

但为什么这样的一句正则会被卡死?
一般的解释:

但显然不适用于我们这种情况。
再三查找原因,从ob的源码中,看到selddefineding相关功能看到原始模版:

const {selfDefendingFunctionName} = {callControllerFunctionName}(this, function () {
const test = function () {
const regExp = test
.constructor('return /" + this + "/')()
.constructor('^([^ ]+( +[^ ]+)+)+[^ ]}');
return !regExp.test({selfDefendingFunctionName});
};
return test();
});
{selfDefendingFunctionName}();确实是用正则表达式所构建,实现了一个特殊的正则查询 。















 1052
1052











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









