






本文由趣头条实时平台负责人席建刚分享趣头条实时平台的建设,整理者叶里君。文章将从平台的架构、Flink现状,Flink应用以及未来计划四部分分享。
一.平台架构
 首先是平台的架构,2018年3月之前基本都是基于Storm和Spark Streaming来做的。
目前,基本已经把Spark Streaming和Storm淘汰了,主要都是Flink SQL来做的。
起初还比较传统,一般是接需求然后开发类似于Flink SQL的任务,基本是手工作坊操作模式。
首先是平台的架构,2018年3月之前基本都是基于Storm和Spark Streaming来做的。
目前,基本已经把Spark Streaming和Storm淘汰了,主要都是Flink SQL来做的。
起初还比较传统,一般是接需求然后开发类似于Flink SQL的任务,基本是手工作坊操作模式。
2、集群及任务量
 这个是目前集群的规模,CPC集群差不多是30个节点,采用了Flink on Yarn的这种模式,这个是独立的计费集群,会有一些广告商的点击计费统计。
当时这个定的时候,会是由两个集群去跑两个任务,类似于HA,它可以在应用层面去做降级。
比如说集群挂了,它还可以在另外公共集群也会有任务。
这样的话就是说如果出问题,至少不会两个集群同时出问题,这种概率应该是比较小。
这个是目前集群的规模,CPC集群差不多是30个节点,采用了Flink on Yarn的这种模式,这个是独立的计费集群,会有一些广告商的点击计费统计。
当时这个定的时候,会是由两个集群去跑两个任务,类似于HA,它可以在应用层面去做降级。
比如说集群挂了,它还可以在另外公共集群也会有任务。
这样的话就是说如果出问题,至少不会两个集群同时出问题,这种概率应该是比较小。
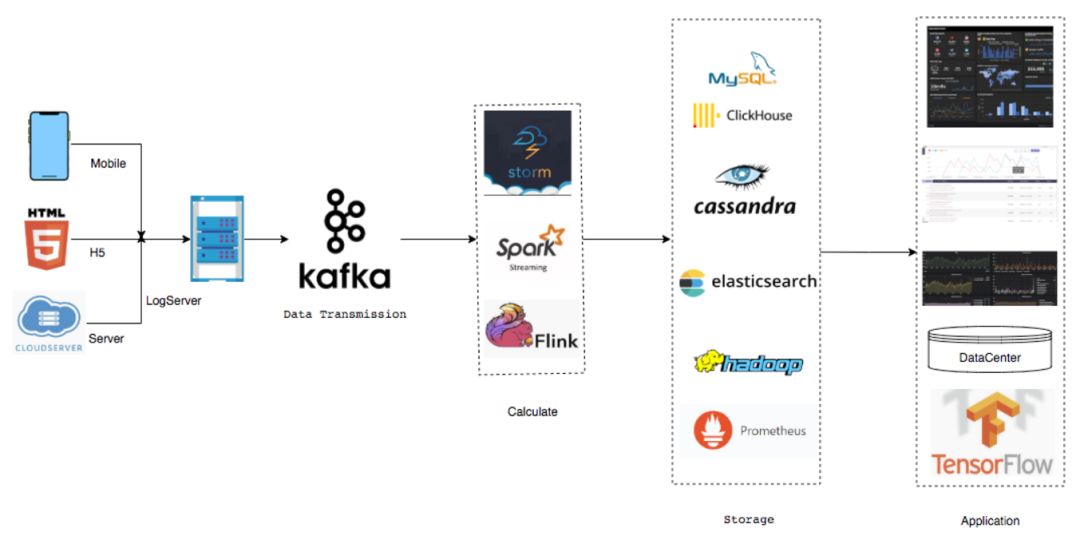 接下来就是Sink出来以后的数据,目前用的种类还是挺多的,包括MySQL, Clickhouse,Cassandra, Elasticsearch包括也会落部分Hadoop到HDFS还有Prometheus。
再往后主要是基于后续落的数据做了一些类似于企业级的应用,最上面Dashboard是大屏,一般是用来显示数据流的大屏。
第二个是基础部门的性能指标。
接下来就是Sink出来以后的数据,目前用的种类还是挺多的,包括MySQL, Clickhouse,Cassandra, Elasticsearch包括也会落部分Hadoop到HDFS还有Prometheus。
再往后主要是基于后续落的数据做了一些类似于企业级的应用,最上面Dashboard是大屏,一般是用来显示数据流的大屏。
第二个是基础部门的性能指标。
4、平台架构
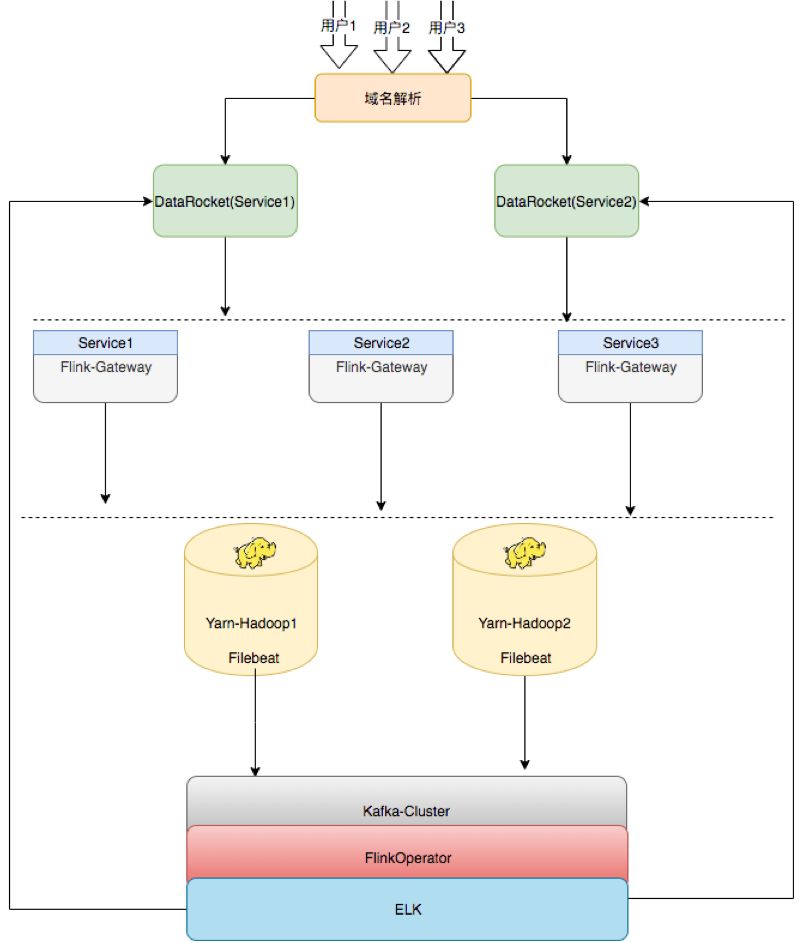
以上为趣头条的平台架构,之前也是单节点,只能做集群的任务发布,目前改造成提供给用户的HA架构,中间开发一层类似于发布机器的概念,上面部了Flink Gateway即每集群在同样的Gateway上是可以随意切换的,比如说Server 1,Server 2,Server 3,三个环境是一样的,后续如果需要扩容,也只需要去扩Flink Gateway,同样的再去部署一套就行了。
再下面Flink Gateway可以往Hadoop集群上发,比如目前用的是Hadoop Yarn,是两个集群,即Gateway可以任意切换到这两个集群发布任务。后续就是通过Filebeat将任务所有运行的记录及日志收集上来。收集完成之后也有基于Flink开发的通用日志统计和分析的工具,将数据落到ELK(Elasticsearch + Logstash + Kibana,以下简称ELK)里,然后提供给用户。比如,用户任务上线之后可能会出现一些异常,包括统计等都会接到ELK里面,由ELK提供可视化的界面,这个就是平台的架构。
 第二部分就是Flink目前在基分的应用,除了趣头条,米读、米读极速版跟萌推目前这些产品包括数据流的统计,数据中间处理环节,基本已经换到Flink来了,支撑整个集团的产品。
业务场景大概主要是计费、监控、仓库,画像包括算法、内容线六部分。
第二部分就是Flink目前在基分的应用,除了趣头条,米读、米读极速版跟萌推目前这些产品包括数据流的统计,数据中间处理环节,基本已经换到Flink来了,支撑整个集团的产品。
业务场景大概主要是计费、监控、仓库,画像包括算法、内容线六部分。
计费主要是算广告商接入的计费成本,跟他们进行结算。每次广告点击完成后,每个月可能会有类似于离线报表,目前如果需要切换成实时,基本只需要点击,就会产生扣费环节,这个算是非常核心的任务。
监控有各种,比如说机器层面的,应用层面的。
仓库目前基本是批量落数据,比如说五分钟、十分钟,类似于窗口的间隔时间去落数据
画像即将用户画像的一些数据通过Flink清洗,完成之后会落到HDFS上,用来做训练。
算法目前除了用户画像,还有推荐,目前的APP打开之后会给不同用户推荐不同的内容。
内容线目前做的是风控,可能有一些用户知道APP会去刷金币,比如说打开某个内容之后,不看内容而可能是在后台跑一百多个程序刷金币,目前通过Flink可以做到实时风控,能实时识别出某台设备究竟是不是真正的用户,如果不是,就会将其屏蔽掉。
2、用户声音
Flink能用Python/Golang开发吗?
Flink好学吗?
我就会SQL可以用吗?
有没有更简单的方式?
以上四个问题是目前接触到的公司内部用户在Flink应用时经常会提到的,包括最初去推实时平台时,可能很多人都会问Flink怎么用、能否用Python或者Golang进行开发,或者仅会SQL不会写代码也想用等。
Flink究竟好不好用?给业务线培养Flink的开发人员所面临情况在于部分业务线确实知道Flink,但是没有Java的背景,语言上主要写Golang,或者每个月需要对产品进行一些策略的调整,但如果没有数据去看,基本就是摸黑的,无法评估策略调完之后可能会给产品带来什么样的影响。
针对以上问题,我们也拿出了解决方案。在第一版的时候,用户只需要写SQL,即会有类似于内存里的宽表,Flink把从Kafka消费过来的数据抽象成内存的一张表,用户只需要打开如下界面根据自己的逻辑去写自定义SQL,就可以提供给产品和分析师,包括其他想用平台的用户。有了这个解决方案之后,其他用户就可以通过简单的方式来体验到Flink带来便捷。
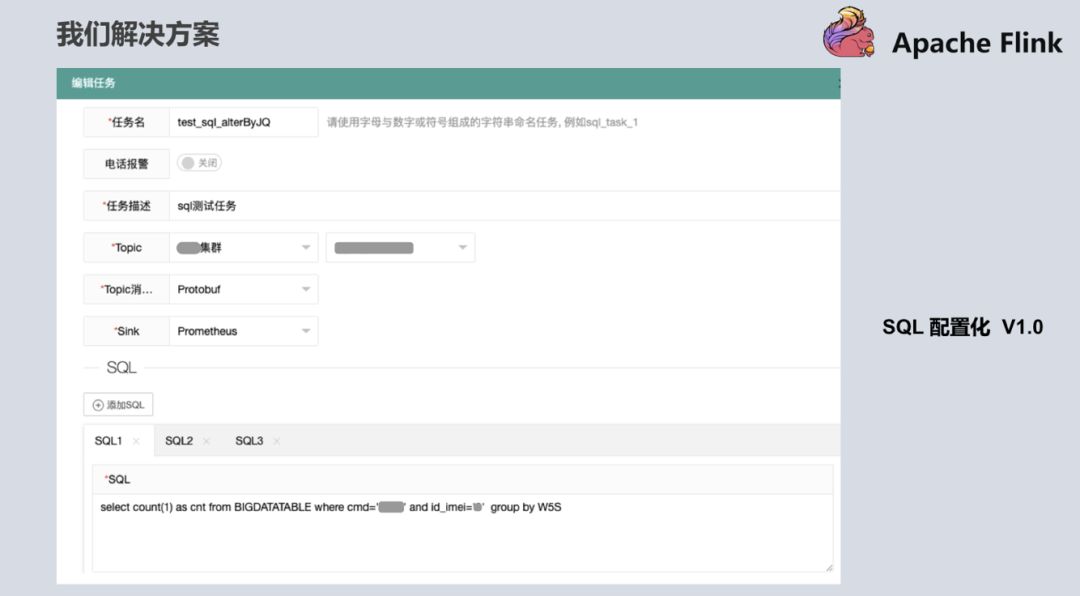
SQL 配置化 1.0 版本中 SQL是有限制的,测试显示如果提供给用户写的SQL越来越多,Checkpoint的压力,与distinct的这种计算结果会带来数据倾斜的这种压力,导致任务可能会失败,所以在设计SQL代码量时有一定的限制,不会让用户无休止的加SQL,基本目前限制是10个。在1.0版本上线之后,刚好Blink开源出来了,我们知道1.0方案还是不够优雅(从工程化看),又参考Flink和开源出来的Blink方案,升级到了第二版,可以更大化的提供用户自定义的方式,也可以把数据源抽象出来,数据源就不仅仅是Kafka了,很大程度上改善了原来1.0的版本。当所有的数据来了之后先到Kafka,目前数据源可以支持HDFS、MySQL、MQ等,只需要创建Source源的概念。下面是平台较详细的截图,基本是输入,输出以及统计逻辑。 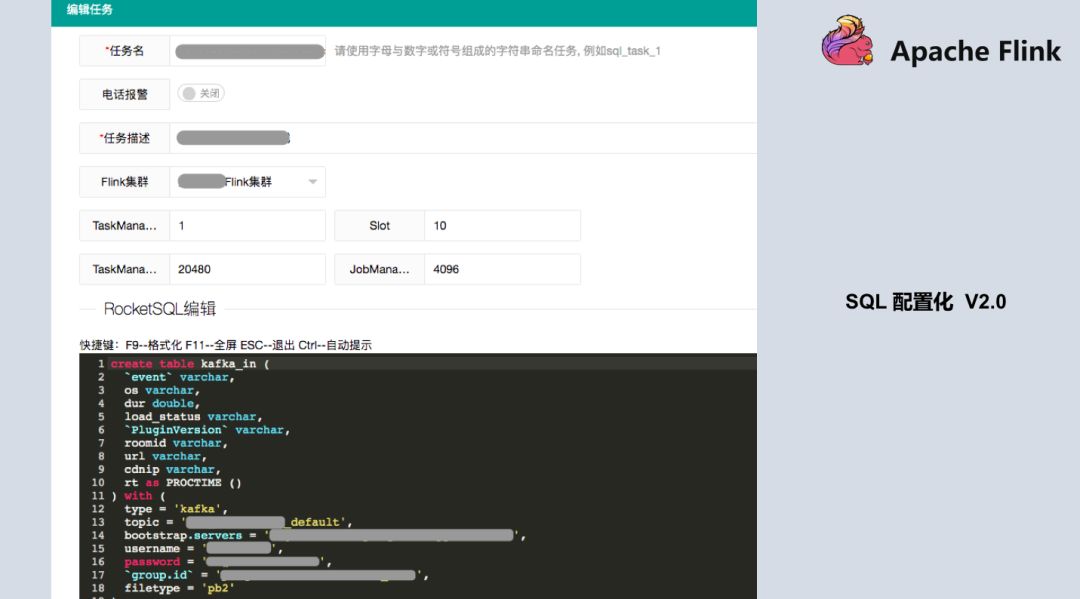 目前跟Blink基本如出一辙,也是参考了Blink的一些设计思路和方法。这个功能已经上线,基本有五、六十个任务已经在用了,用户对当前的平台还是比较满意的。不过更期望写SQL基本就能完成统计指标,这也是实时平台后续想要去做的(尽可能的再去屏蔽一些资源设置比如:tm/slot一般用户不太懂)。
目前跟Blink基本如出一辙,也是参考了Blink的一些设计思路和方法。这个功能已经上线,基本有五、六十个任务已经在用了,用户对当前的平台还是比较满意的。不过更期望写SQL基本就能完成统计指标,这也是实时平台后续想要去做的(尽可能的再去屏蔽一些资源设置比如:tm/slot一般用户不太懂)。  三.现状
三.现状 
第三部分是想分享一下趣头条实时平台的现状,目前Flink 1.9版本已经出来了,我们在测Flink 1.9的新特性,Flink对Python的支持是非常惊喜的,内部很多用户还是比较喜欢脚本式语言的,而Python的开发是写脚本式语言,就能提交Flink任务,这是我们当前测试内容的一部分。另一部分是Flink模板简化,上面提到的2.0模板,让用户写一大堆的SQL,还是比较麻烦的,用户还是更倾向于统计逻辑的简单SQL。我们最终的目标还是想把Flink推广到整个集团公司,让更多的受众参与进来享受Flink带来的好处。
最后一块是Flink SQL的HDFS落库,目前这个功能开发完了,目标是将Kafka出来的数据做类似的实时仓库,即数据可以实时落到HDFS上,而上一个版本是通过Flink开发,基本是按时间窗口去落的还不是实时的。
四.未来计划
 首先是版本升级,趣头条的实时平台目前用的是Flink 1.7,后续是想往1.9版本去切,Flink 1.9版本提供的Task Fault Tolerance的容错、Checkpoint的容错等很好的修复了1.7版本中存在的问题。
首先是版本升级,趣头条的实时平台目前用的是Flink 1.7,后续是想往1.9版本去切,Flink 1.9版本提供的Task Fault Tolerance的容错、Checkpoint的容错等很好的修复了1.7版本中存在的问题。
点击下面[阅读原文]进一步了解大会详细日程。















 472
472











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









