







在上一篇文章中,我们介绍了Wgpu中的渲染管线与着色器的概念以及基本用法。相信读者还记得,我们在渲染一个三角形的时候,使用了三角形的三个顶点的索引作为了顶点着色器的输入,并根据索引值计算了三个几何顶点在视口中的位置,并通过片元着色器的代码逻辑,控制了每一个像素都用红色色值,最终渲染了一个红色三角形:

当然,我们不可能一直使用wgpu来渲染这样的简单固定的图形。面对实际的场景,我们有时候需要根据一些上下文来动态的修改渲染图形的大小形状。在本文中,我们将开始介绍顶点缓冲区的概念,来为后续实际的场景做一些铺垫。
认识缓冲区
缓冲区(Buffer)一个可用于 GPU 操作的内存块(又叫“显存”)。在wgpu(或其他例如OpenGL等库)中的缓冲区概念通常指的是 GPU 能读写的内存区域,与之对应的就是我们常见的CPU内存。回想一下常规的软件运行的过程:程序在启动后,会在“内存”中申请一块能够存放数据的区域。在运行的过程中,我们的代码指令按照既定的逻辑做着计算,并不断的读、写内存区域里面的数据,以达到期望的程序运行的结果。不严谨地讲,GPU 与 CPU 是一样的,它同样能够执行计算逻辑,同样会有数据存储的区域,这个区域就是 GPU 的缓冲区。
一般来说,我们都在 CPU 直接阶段,在内存中将一些初始的数据准备好,通过一定的方式发送给 GPU,并存储在GPU上的缓冲区中。在执行的过程中,我们可以通过着色器代码来读取缓冲区中的数据:
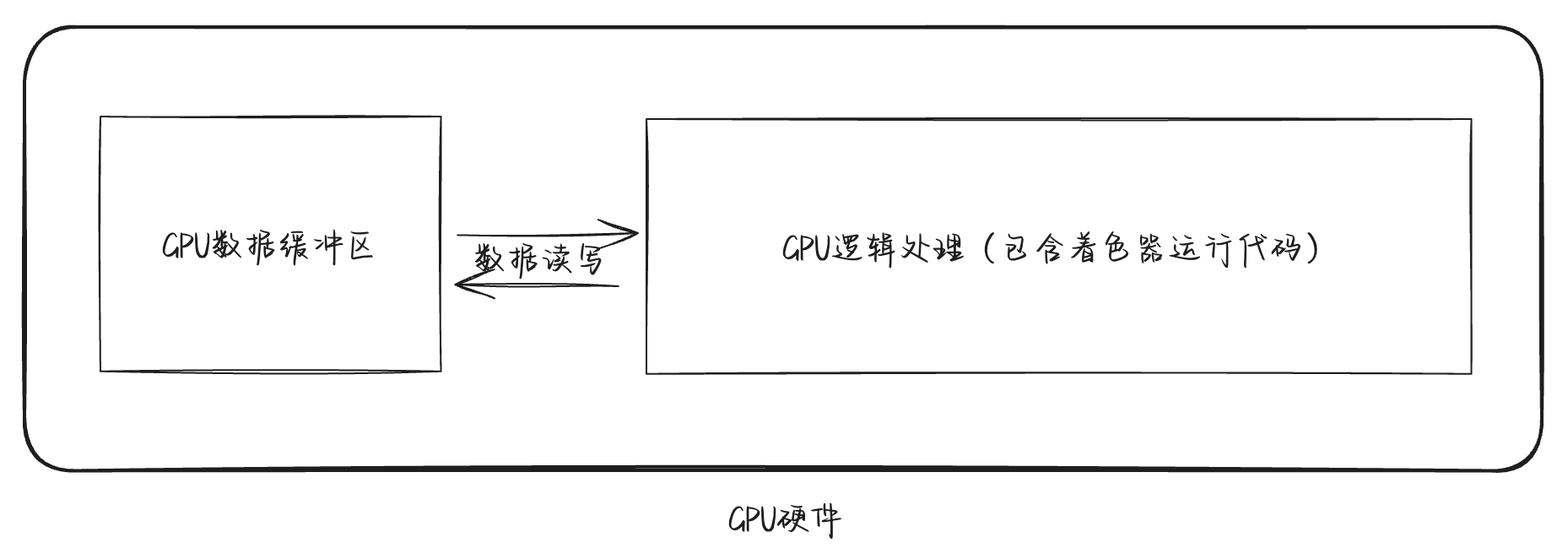
创建顶点缓冲区
为了更好的管理不同类型的数据(比如常见的有顶点数据、顶点索引数据),我们会按照其不同类型来设定不同的缓冲区。在本文中,我们先介绍如何创建并使用顶点缓冲区,对于其他缓冲区我们会在后续的文章中说明。
顶点缓冲区,顾名思义,就是包含了在渲染过程中会使用到的顶点数据的 GPU 显存区域。需要注意的是,图形学中的顶点并不是我们常规意义上的几何顶点,而是包含了位置坐标、颜色信息、纹理坐标以及法线向量等的顶点数据,常规意义上的几何顶点仅仅是顶点数据中的一部分。
在上一篇文章中,尽管在最后我们成功终绘制了一个三角形,但实际上它的三个顶点位置是通过三个顶点索引(0、1、2)计算而来的。假设我期望绘制一个比较另类的三角形或其他图形,纯粹靠顶点索引是不够的。这种场景我们一般会按照如下的方式进行:
- 准备一些包含自定义位置信息的顶点数据;
- 将顶点数据放置到顶点缓冲区中,并进行一定的配置;
- 最后,在着色器代码中通过一定的方式读取这些顶点数据,并交给顶点着色器来使用。
接下来让我们开始实践如何通过编程方式创建顶点缓冲区。
假设最终我们期望渲染一个由(0, 1)、(-0.5, -0.5)、(0.5, 0)三个2维顶点构成的三角形:
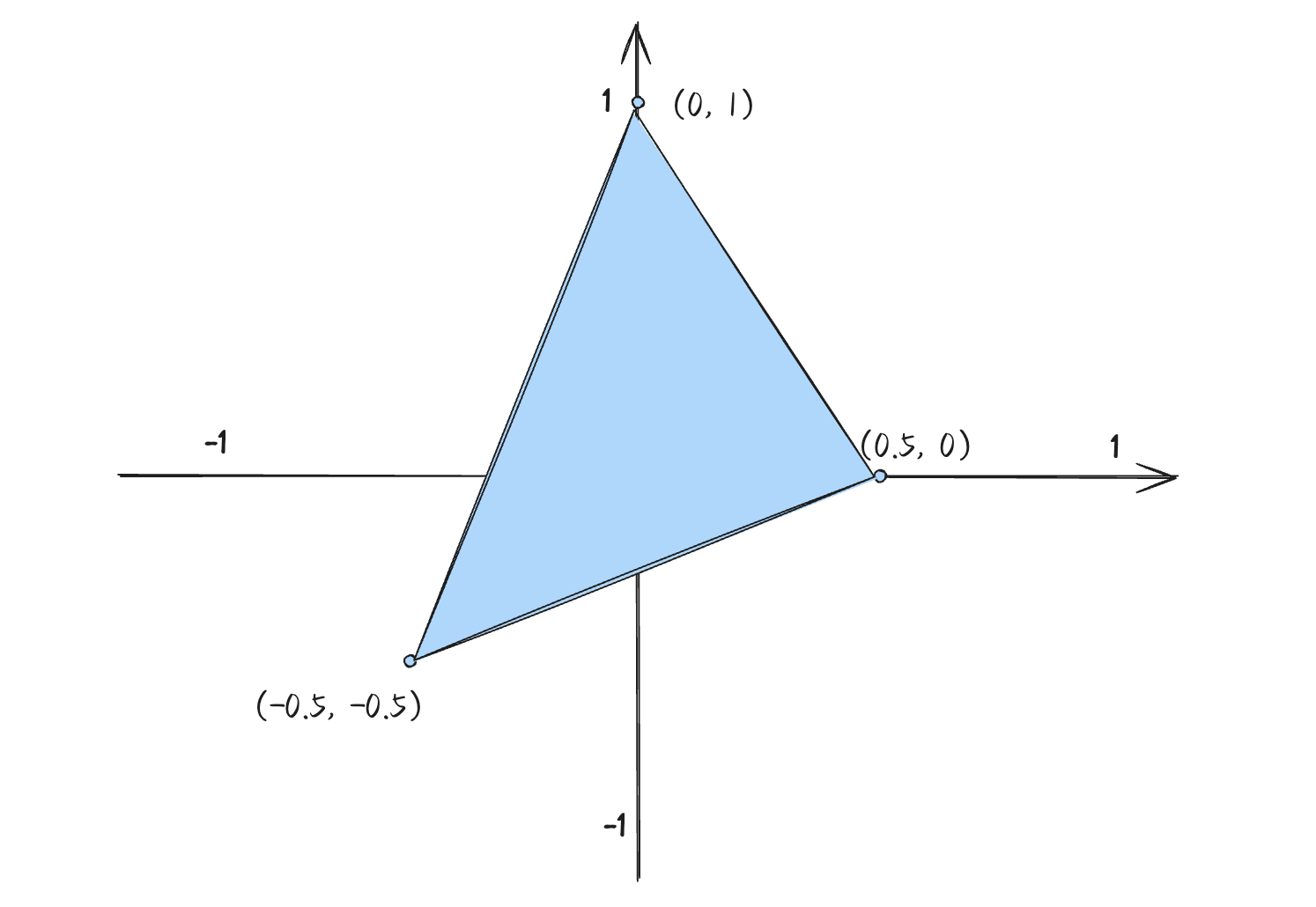
首先,让我们在基础项目中增加一个结构体Vertex,用来表达我们的顶点:
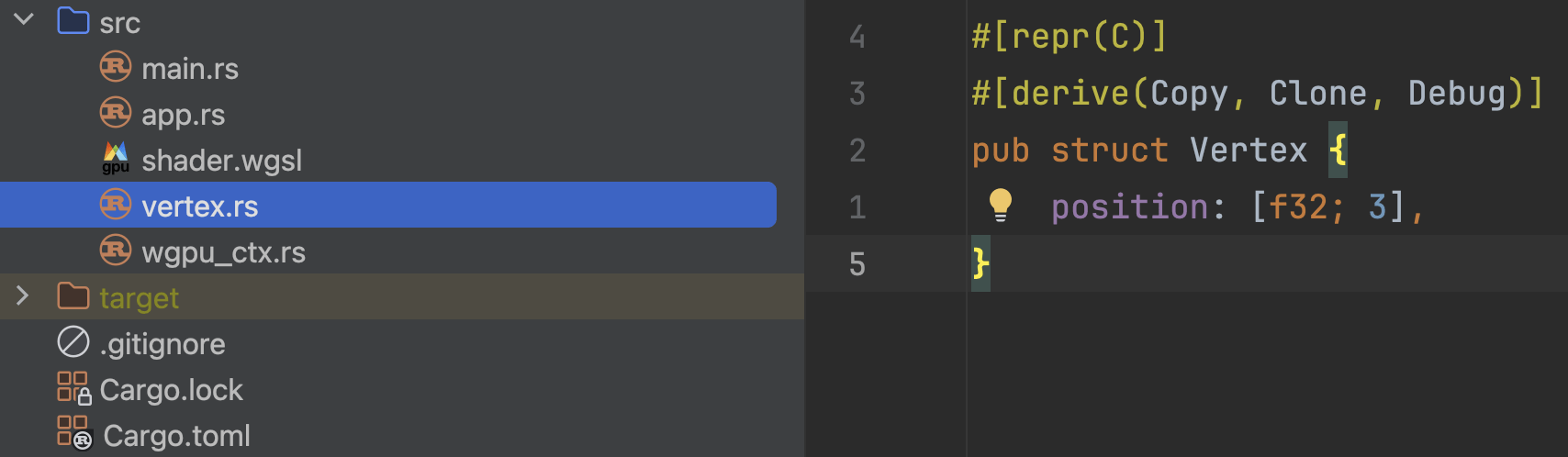
这个结构体我们现在仅有一个类型为[f32; 3]类型的字段position,用来表示一个位置坐标。
⚠️这里务必添加Copy派生
引申:关于内存布局
该结构体上的属性,除了我们常见用来派生Copy、Clone等trait的derive属性外,还有一个特殊的属性:#[repr(C)],在配置该属性后,Rust 编译器会强制按照 C 编译器的编译方式来安排结构体字段的顺序和对齐方式。假设有如下结构体,在#[repr(C)]的加持下,其内存布局会保持4字节对齐:

上面的结构体中,age字段的类型是u8,但因为强制使用了#[repr(C)],让其保持了4字节的内存布局。我们可以用如下的代码来验证:
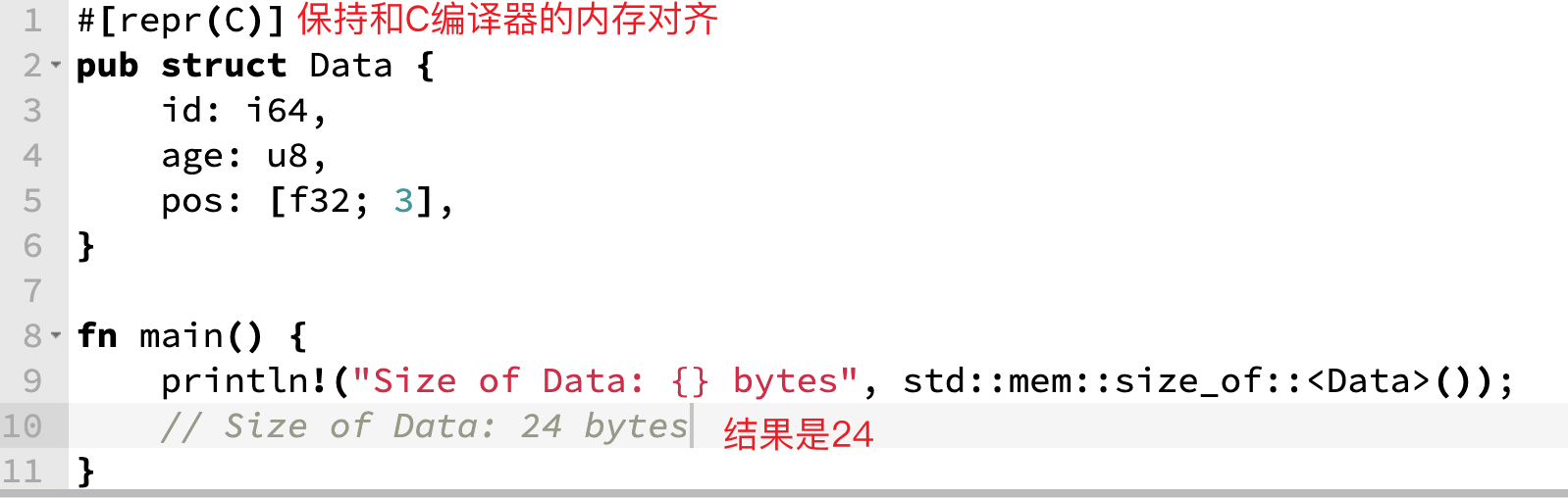
当然,有的小伙伴会发现即使不添加#[repr(C)],结果也是24bytes,是因为Rust编译器在某些场景下会进行对齐,不过这样无法保证是按照和C编译器一样的4字节对齐;此外,Rust编译器在有时为了内存的高效利用,可能会进行布局压缩。当然,你还可以使用#[repr(packed)]来禁用内存对齐填充:

好了,让我们回归正文。此时我们已经编写了一个Vertex结构体,也理解了#[repr(C)]的意义。接下来,我们创建一个数组切片来存放三个顶点的数据:
// 表示三角形三个顶点的顶点列表
pub const VERTEX_LIST: &[Vertex] = &[
Vertex {
position: [0.0, 1.0, 0.0] },
Vertex {
position: [ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5403
5403

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









