







首先应该明确两个概念: 目标识别 和 目标检测
目标识别是指识别图片中物体的类别.
目标检测是指不仅要识别图片中物体的类别, 而且还要使用 Bounding Box 标出物体的位置.
目标检测 = 目标识别 + 定位
经典目标检测方法
基于回归的思想
将 Bounding Box 的四个参数(x.y,width,height)作为网络的预测结果, 和真实的参数做损失. 网络使用L2损失函数.基于滑动窗口的思想
基于输入图像, 取不同的滑动窗口, 之后利用 CNN 获得不同窗口图片的评分, 以此找出评分最高的目标窗口. 简单粗暴.
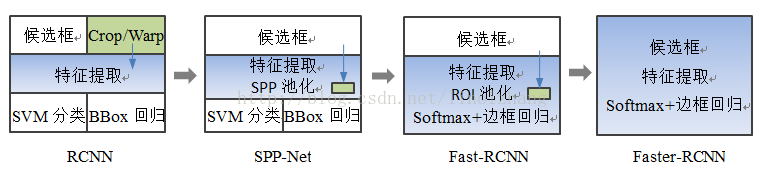
R-CNN
- 根据
selective search算法生成可能包含目标的候选区域, 也就是region proposal. 生成的候选区域大小可能是不同的. resize不同大小的候选区至相同尺寸,分别将生成的region proposal放入 CNN 获取对应候选区的特征, 并缓存起来.- 训练一个
svm二分类器, 用来判断缓存起来的特征是否是相应的目标类别. 每个类别对应一个svm. - 最后用一个
regression修正器修正框的位置. (bbox regression)
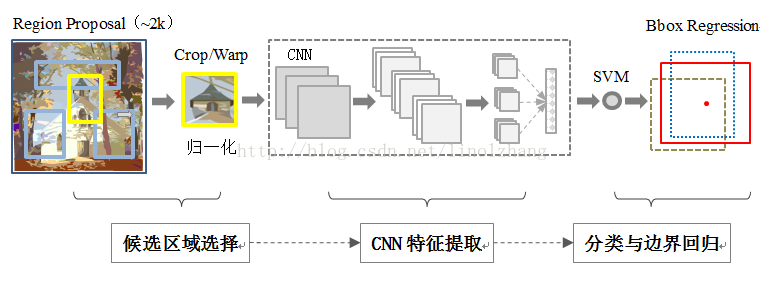
缺点: 尽管使用选择性搜索算法, 但是候选区大小不一, 需要调整到统一大小, 这样会导致信息丢失; 此外, 由于候选区重叠,多个候选区都会重复计算卷积特征, 计算性能和效率下降很多. 最后, 各个过程是分开的.
SPP-Net
卷积/池化/激活等操作是不需要固定输入图像的 size 的, 所以可以共享前面的操作.
- 共享卷积计算。
- 采用空间金字塔池化(
Spatial Pyramid Pooling)替换了全连接层之前的最后一个池化层 - 最关键的是
spp的位置,它放在所有的卷积层之后,有效解决了卷积层的重复计算问题(测试速度提高了24~102倍)
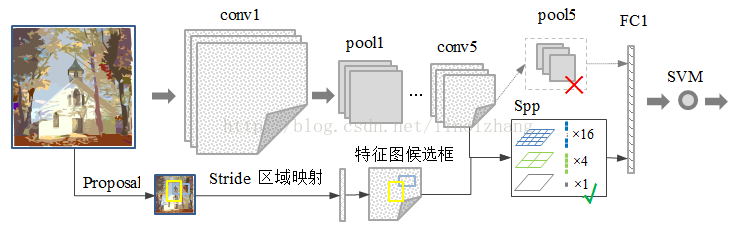
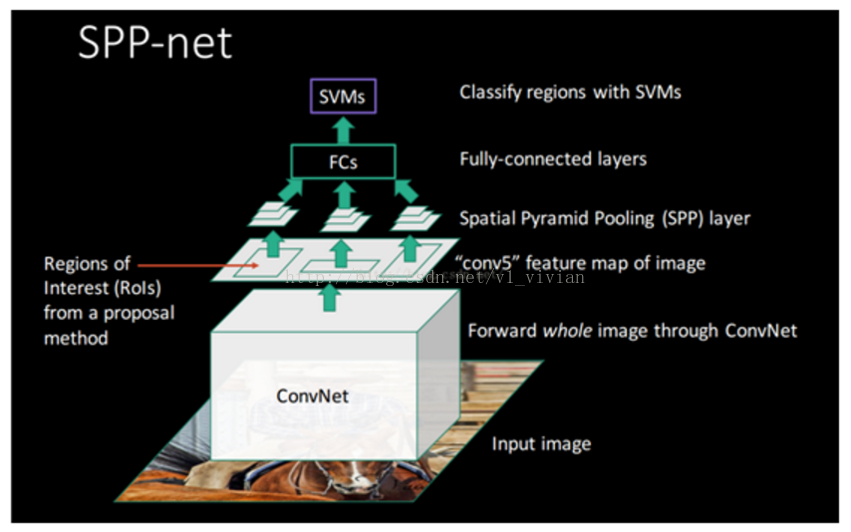
缺点: 和RCNN一样,训练过程仍然是独立的。分类和回归仍然是分开的,中间结果(卷积特征)依旧需要大量转存,太麻烦。SPP-Net在无法同时调整在SPP-Layer两边的卷积层和全连接层,很大程度上限制了深度CNN 的效果;
Fast R-CNN
- 使用金字塔池化思想实现多尺度输入, 只使用一层金字塔池化, 最后生成的时固定大小的特征图.
- 只对原图提取一次卷积特征, 共享卷积操作.
- 目标分类和 bbox regression 都放到网络中, 构成 multi-task 模型.
Softmax Loss代替svm,SmoothL1Loss取代Bouding box回归- 全连接层通过
SVD(奇异值分解)加速
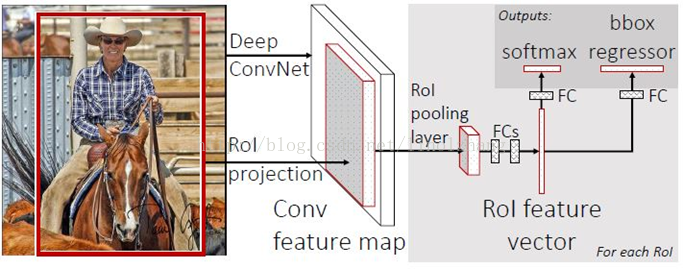

缺点 就是候选区域的生成是基于选择性搜索算法的, 这个过程又也是非常耗时的.
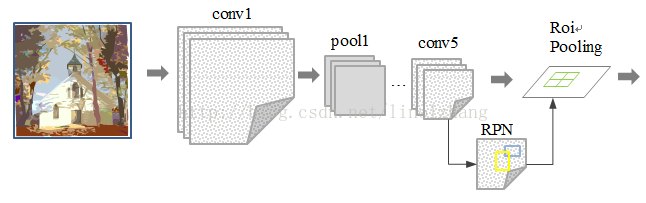
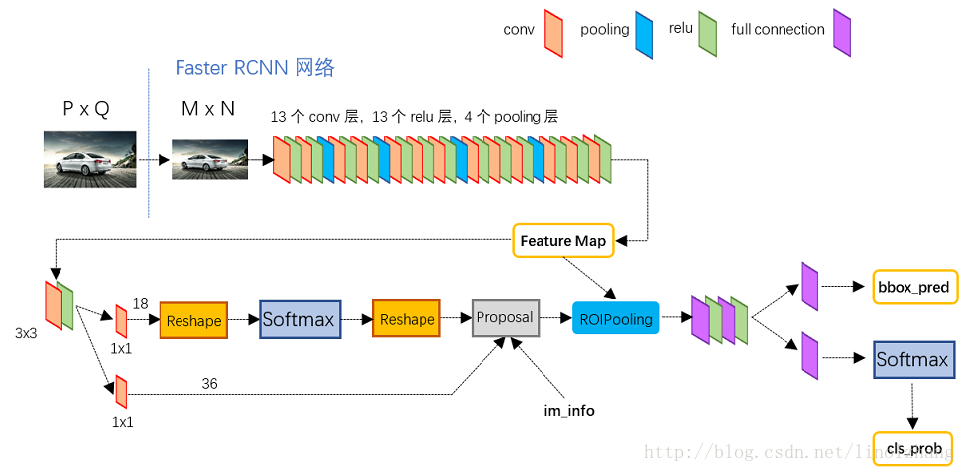
Faster R-CNN
- 加入一个提取边缘的神经网络,也就说找到候选框的工作也交给神经网络来做了. 做这样的任务的神经网络叫做
Region Proposal Network(RPN)


YOLO
SSD
总结
整理自:
https://www.cnblogs.com/skyfsm/p/6806246.html
http://blog.csdn.net/linolzhang/article/details/54344350
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









