






目录
1.Linux 中在不知道指令需要什么参数时
可以通过 man --help info -h 百度、搜索 这些方法进行查看喝了解指令
2.Linux中将普通文件添加可执行权限
可以使用 chmod a+x 文件名 这条命令添加权限
3.python 的 魔法方法
__new__ :类的构造器,创建初始化后的基本实例对象 == 类的框架
__init__ :类的数据初始化方法,给实例化对象添加属性
__del__ 类的析构器,用来在实例销毁前使用,释放资源
__call__ :将实例对象声明为一个方法调用,保护内部实现
__getattr__ :获取某个属性时使用
__setattr__ :设置某个属性时使用
4:列表和元组的区别
1.可变性(Mutability):列表是可变的(mutable),意味着可以修改、添加或删除其中的元素。而元组是不可变的(immutable),一旦创建后,就不能修改其中的元素。
2.语法表示:列表使用方括号([])来表示,元素之间用逗号分隔。例如:[1, 2, 3]。而元组使用圆括号(())来表示,元素之间也用逗号分隔。例如:(1, 2, 3)。
3.使用场景:由于元组是不可变的,所以在需要保持数据的不可变性和安全性的场景中更适用,例如用于存储常量或函数参数。列表则更适用于需要频繁修改或扩展元素的场景,例如存储动态数据。
4.性能:元组的访问和迭代比列表更快,这是因为元组的不可变性使得Python可以对其进行一些优化。
5、python的三大器
装饰器、迭代器、生成器
6、生成器中yield解释
如果不太好理解yield,可以先把yield当作return的同胞兄弟来看,他们都在函数中使用,并履行着返回某种结果的职责。
return结束函数返回,yield是暂停函数并返回,当下次执行会从上次暂停的地方继续执行
7、简述python元类
元类(metaclass)是 Python 中的一个特殊概念,用于创建类的类。元类可以控制类的创建、行为和属性。
在 Python 中,一切皆对象,包括类。在定义类时,Python 首先会查找类的元类,然后使用元类来创建这个类。元类可以被看作是类的模板,它定义了类应该具有的属性、方法和行为。
下面是关于元类的一些详解:
类是对象:在 Python 中,类也是对象,因此它们都是通过元类创建的实例。
type 是默认的元类:如果在创建类时没有指定元类,Python 默认使用 type 作为元类。type 是 Python 中所有类的元类,它负责创建类对象。
自定义元类:我们可以通过定义自己的元类来控制类的创建过程。自定义元类需要继承于 type 类,并重写一些特殊方法,如 new 和 init 等。通过重写这些方法,我们可以在类创建的过程中动态地修改类的属性、方法等。
元类的作用:使用元类可以实现一些高级的功能,例如对类的注解、属性、方法进行验证、修改或增强。元类还可以用于自动注册类、实现ORM(对象关系映射)等。
metaclass 属性:在定义类时,可以通过 metaclass 属性来指定元类。例如:class MyClass(metaclass=MyMeta)。
元类的继承:元类也可以继承自其他元类,形成元类的层次结构。当创建类时,Python 会按照继承关系依次调用所有相关的元类。
8.封装
封装(Encapsulation)是面向对象编程中的一种重要概念,它指的是将数据和操作数据的方法捆绑在一起,形成一个独立的实体。封装通过隐藏对象的内部细节,只暴露必要的接口给外部使用者,提供了更好的安全性、可维护性和灵活性。
9.多态
多态(Polymorphism)是面向对象编程中的一个重要概念,它指的是同一种操作可以在不同的对象上产生不同的行为。多态允许我们使用统一的接口来处理各种不同类型的对象,提高了代码的灵活性和可扩展性。
10.继承
继承(Inheritance)是面向对象编程中的一个重要概念,它允许一个类继承另一个类的属性和方法。被继承的类称为父类(或基类、超类),继承这些属性和方法的类称为子类(或派生类、衍生类)。
11.猴子补丁
猴子补丁(Monkey Patching)是一种在运行时修改或扩展现有代码的技术。在编程中,猴子补丁通常用于动态地修改已存在的类、函数、方法或模块,以添加、修改或删除其行为
12. 迭代器详解
python一切皆对象,迭代器(iterator)也可以说是迭代器对象。具有__iter__方法的对象调用__iter__会返回一个迭代器对象。从语法上说就是那些同时具有__next__和__iter__方法的对象。
迭代器调用__next__方法会调用迭代器中的下一个值;
迭代器调用__iter__方法返回迭代器本身;
13.生成器中yield解释
如果不太好理解yield,可以先把yield当作return的同胞兄弟来看,他们都在函数中使用,并履行着返回某种结果的职责。
return结束函数返回,yield是暂停函数并返回,当下次执行会从上次暂停的地方继续执行
14.python 列表推导式
Python 中的列表推导式(List Comprehension)允许我们使用简洁的语法快速生成列表。它提供了一种在一行代码中创建列表的方法,非常常用和方便。
一般形式为:
[expression for item in iterable if condition]
其中,expression 是对 item 进行操作得到的值,item 是可迭代对象中的每个元素,iterable 是原始的可迭代对象,if condition 是可选的条件表达式。
15.python 字典推导式
Python 中的字典推导式(Dictionary Comprehension)可以通过一行代码快速创建字典。它提供了一种简洁的语法来生成字典,非常方便和实用。
一般形式为:
{key_expression: value_expression for item in iterable if condition}
其中,key_expression 是对 item 进行操作得到的键值的表达式,value_expression 是对 item 进行操作得到的值的表达式,item 是可迭代对象中的元素,iterable 是原始的可迭代对象,if condition 是可选的条件表达式。
16.钩子函数有那些?
钩子函数(Hook Function)是一种在特定事件发生时被调用的函数,用于允许开发者插入自己的代码以改变或增强程序的行为。钩子函数通常作为回调函数的一种形式存在,并被用于各种编程和开发场景。以下是一些常见的钩子函数的示例:
消息钩子(Message Hook):在操作系统消息处理过程中被触发的钩子函数。可以用于拦截和处理窗口消息,如键盘输入、鼠标点击、窗口状态变化等。
鼠标钩子(Mouse Hook):在鼠标事件发生时被触发的钩子函数。可以用于监控和响应鼠标的移动、点击和滚动等操作。
键盘钩子(Keyboard Hook):在键盘事件发生时被触发的钩子函数。可以用于捕捉用户的按键操作,如监听特定的快捷键、拦截输入等。
网络钩子(Network Hook):在网络数据传输过程中被触发的钩子函数。可以用于拦截和分析网络通信数据,实现网络安全检测、流量控制等功能。
文件钩子(File Hook):在文件系统操作发生时被触发的钩子函数。可以用于监测文件的访问、读写等操作,进行文件的拦截或修改。
系统钩子(System Hook):在操作系统级别拦截和处理系统事件的钩子函数。可以用于监控系统的状态变化,如系统启动、关机、进程创建等。
数据库钩子(Database Hook):在数据库操作发生时被触发的钩子函数。可以用于对数据库操作进行拦截、验证或记录。
17.Shell是什么?
Shell(壳)是计算机操作系统中提供给用户与操作系统内核进行交互的界面。它可以是一个命令行解释器,也可以是一个图形用户界面(GUI)。
18.启动Redis
redis-server [--port 6379]
如果命令参数过多,建议通过配置文件来启动Redis。
redis-server [xx/xx/redis.conf]
6379是Redis默认端口号。
19.连接Redis
./redis-cli [-h 127.0.0.1 -p 6379]
20.停止Redis
redis-cli shutdown
kill redis-pid
以上两条停止Redis命令效果一样。
21.Linux 中 操作 Redis
查看版本使用:redis-server --version 
22.查看是否开启
使用该命令查看: ps -ef|grep redis
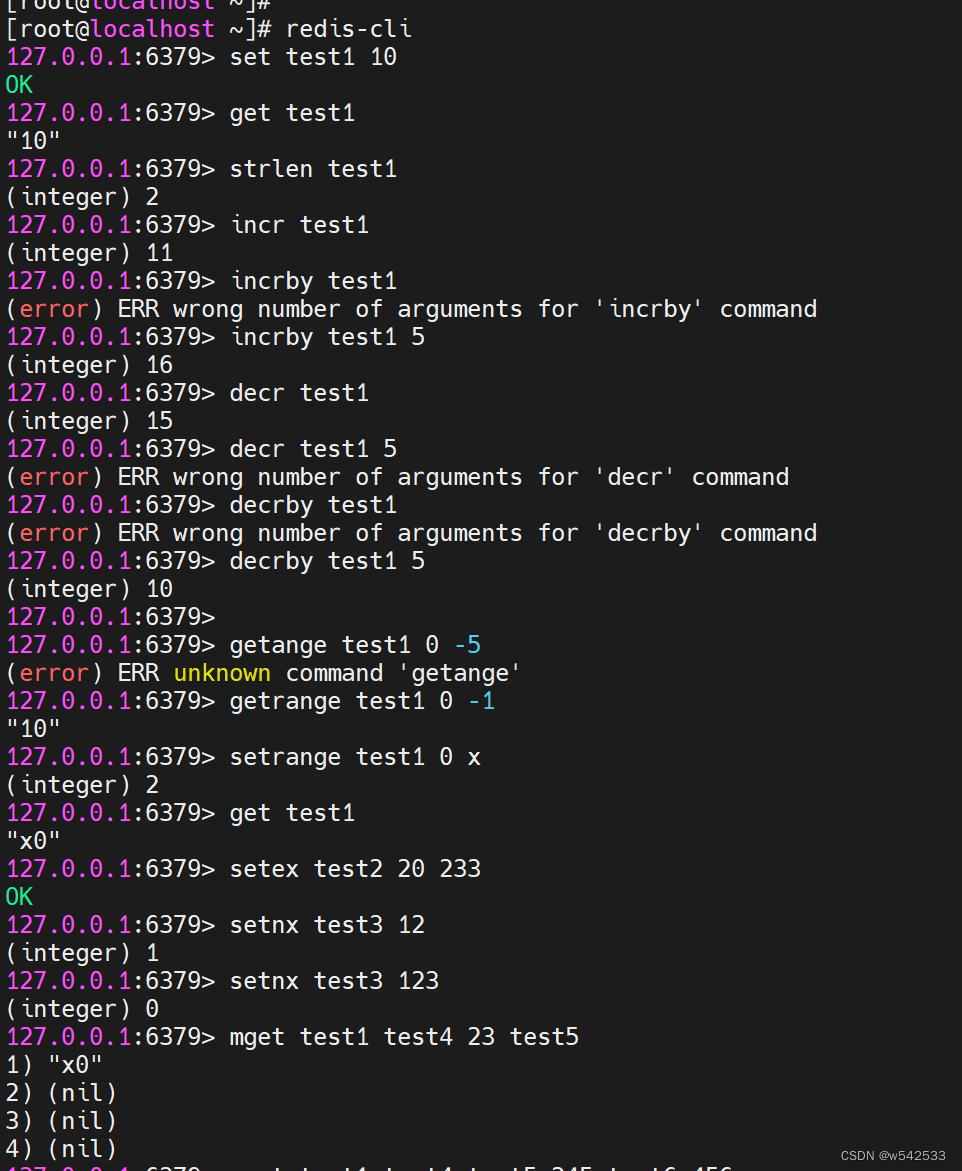
23.常用操作string
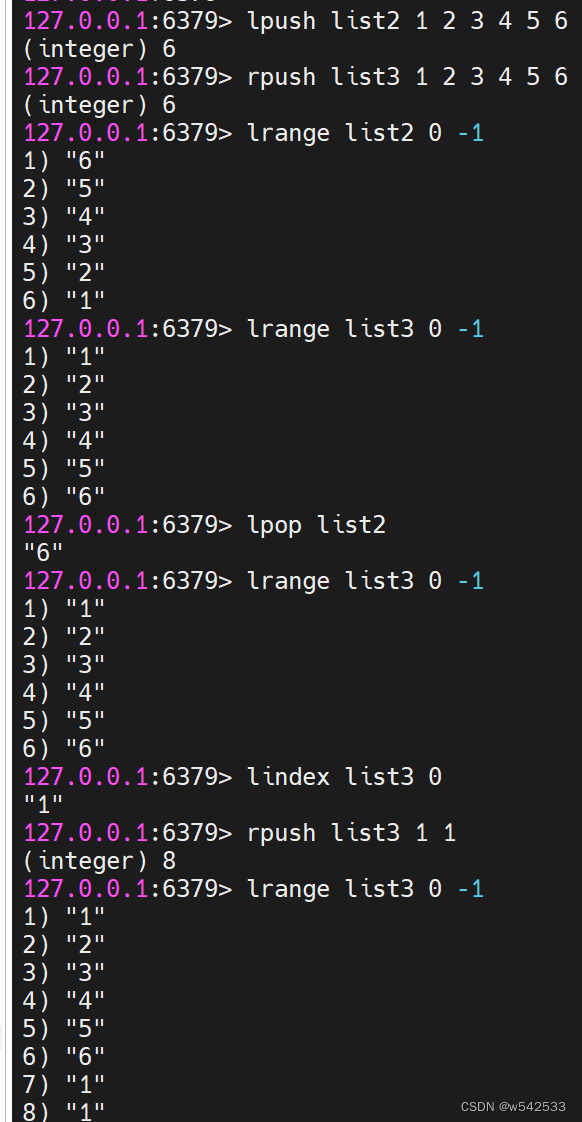
24.常用操作list
25.linux安装Redis
1.安装Redis
# 在基于Red Hat的发行版上
sudo yum install redis
# 在基于Debian的发行版上
sudo apt install redis-server
2.启动Redis服务
sudo systemctl start redis
3.确保Redis服务在系统启动时自动启动
sudo systemctl enable redis
4.检查Redis服务是否正在运行
sudo systemctl status redis
5.启动Redis客户端
redis-cli
26.Redis数据库基本
redis 默认情况下有 16 个数据库序号为(0——15) 默认情况下是使用的序号为 0 的数据库。
Redis 默认有16个数据库,即16个database
Select 【数字】 转到第几个数据库
Dbsize 查看当前数据库有多少个key
Keys * 当前库的key查询出来
Flushdb 清除当前库
Flushall 清除所有库
Auth 【密码】 认证密码
Exists【key的名字】 判断某个key是否存在
Move key 【db序号】 将当前库的key剪切到指定db序号
Expire key【时间秒】 为给定的key设置过期时间,过期后会移除系统
Ttl key 查看还有多少秒过期,-1表示永远不过期,-2表示已过期
Type key 查看你的key是什么类型
Del key 删除key
27.Redis持久化
-
Redis持久化数据扩容:可以通过增加硬盘容量或者使用分布式存储系统来扩容。如果使用AOF持久化方式,可以将AOF文件分割成多个小文件,以便于管理和备份。
-
Redis缓存扩容:可以通过增加Redis节点或者使用Redis集群来扩容。增加节点可以提高Redis的读写能力,而使用集群可以将数据分散到多个节点上,提高整个系统的可用性和性能。
需要注意的是,在扩容过程中要注意数据的一致性和可用性,可以采用数据迁移、数据备份等方式来保证数据的完整性和安全性。
28.在web服务器中的http请求响应的实现原理
在Web服务器中,HTTP请求和响应的实现原理涉及到客户端和服务器之间的通信过程。下面是HTTP请求和响应的一般实现原理:
29. HTTP请求:
- 客户端发起HTTP请求:当用户在Web浏览器中输入网址或点击链接时,浏览器会向服务器发送HTTP请求。这个请求通常由HTTP方法(例如GET、POST、PUT等)和请求头组成。
- 服务器接收请求:Web服务器接收到客户端发送的HTTP请求后,开始处理请求。它会解析请求头中的信息,包括目标URL、请求方法、请求参数等。
- 处理请求:服务器根据请求的URL和方法来确定应该执行哪些操作。这可能涉及到查询数据库、读取文件、执行业务逻辑等。
- 构建响应:服务器处理完请求后,会构建HTTP响应。响应通常包括一个响应头和一个响应体。响应头包含了响应的状态码(例如200表示成功,404表示未找到等)和其他元数据信息。
- 发送响应:一旦构建完整的HTTP响应,服务器会将响应发送回客户端。这通过将响应数据分成小块(称为数据包)并通过网络传输到客户端实现。
30.HTTP响应:
- 客户端接收响应:客户端(通常是Web浏览器)接收到来自服务器的HTTP响应后,开始处理响应。
- 解析响应:客户端解析响应头,以获取响应的状态码和其他元数据信息。
- 处理响应:根据响应的状态码,客户端决定如何处理响应。例如,对于成功的响应(状态码为200系列),客户端可能会解析响应体中的数据并将其呈现给用户。
- 渲染响应:如果响应包含HTML、CSS、JavaScript等内容,客户端会解析和渲染这些内容,以在浏览器中呈现网页。
- 完成响应:一旦客户端完成处理和渲染响应,用户可以看到相应的网页内容或执行其他操作。














 166
166











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









