







知乎首发链接:https://zhuanlan.zhihu.com/p/2201031718
最近看了一些关于agent debate相关的内容,觉得挺有意思的(跟我以前做的对比学习很像,可以认为是大模型推理阶段的生成式对比学习),所以就把我的理解分享出来,也欢迎大家的匹配指正。现有的debate(一种Agentic Workflow)策略分为3步,第一步就是对给定的问题生成解决方案,第二步就是多轮相互discussion(辩论的回合数越多,消耗的token越多,越费时间和money),第三步在discussion的基础上进行投票表决。本质上,agent debate能力涉及到了LLM本身的角色扮演(角色扮演能够提升debate的效果),多轮对话,长序列指令遵循等能力,如果模型把这些能力训练好,debate能力就具备了前置条件了(至少两个智能体的多轮对话debate能够做了)。现有的debate研究都是一些策略,除了能够消除推理的幻觉(hallucinations),做事实性校验(fact checking)外,还能构建多个LLM的agent通过debate 策略提升数据生成的质量,优化SFT(例如Debatetune,DebateGPT),另外,有人研究了debate策略的拓扑结构,通过简单的debate拓扑结构能够减少token消耗,提升模型的精度(Group Debate),还有人研究了debate后达成一致的投票过程加了置信度(weighted),使用不同的LLM(ChatGPT, Bard, Claude2等)作为agents,典型的有RECONCILE,DebUnc;还有人研究了在discussion出现平局的情况下引入了一个秘书(secretary)来做最终的结论,典型的是(CMD);此外,有研究在disscussion阶段注入RAG知识来打破认知孤岛(cognitive islands,挺有意思的概念),典型的就是MADKE,最后,有人就是直接在训练里面加入debate策略(Acc-Debate),都是一些不错的探索。其实,有人在看debate初始化的时候,需要使用LLM做多次reasoning,感觉就是self-consistency+投票表决,其实只是初始化差不多,MAD还有多轮的迭代对话等等,但是两个策略关系很密切。

与单智能体相比,MAD在推理上有下面这几个优势:
1.多样化的视角:多智能体辩论允许模型通过与提供意见的其他智能体互动来考虑不同的观点;
2.增强推理:通过辩论的互动,模型有机会挑战假设,建立更强有力的论据来提升推理过程;
3.错误更正:可以通过辩论框架内的相互讨论来识别和纠正各个智能体之间的不一致的结论和错误;
4.性能提升:与单智能体方法相比,MAD利用的是群体智慧,通常会提升模型的整体性能。
也有人会问,single agent会很差吗?这个不一定,single agent有strong prompt的时候能够达到和multi agent相同的效果(CMD论文的观点),在没有few shot情况下,multi agent的效果是比single agent好很多的。由于文章篇幅的限制,DebateGPT相关的内容,就不做重复介绍了,有兴趣可以参考我以前写的agent tuning相关的文章,欢迎大家批评指正:
2024年大模型Agent tuning关键技术Fireact, Agent-FLAN, AgentOhana, Agent LUMOS, STE, ETO,MoE, DebateGPT等
Should we be going MAD? A Look at Multi-Agent Debate Strategies for LLMs
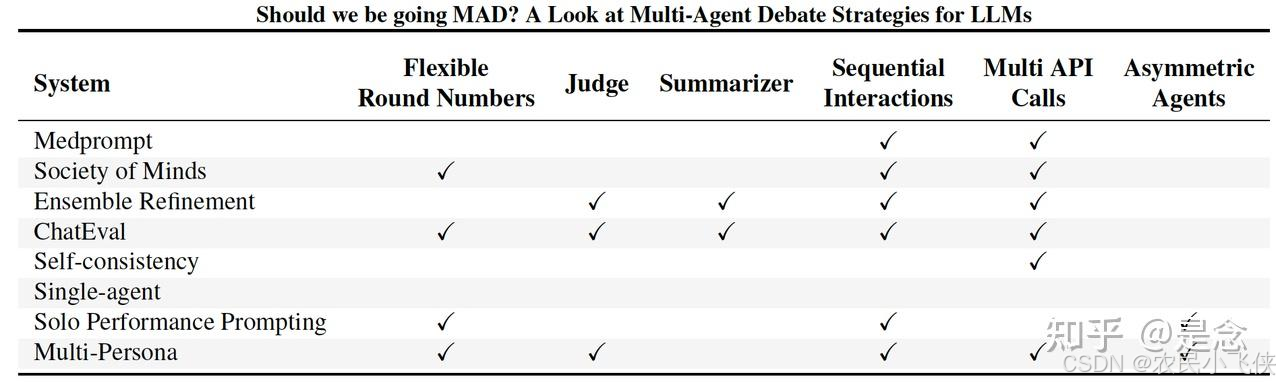
这篇轮文最大的特点就是比较了现有主流的一些agent debate策略的效果,方便读者了解这个领域的进展。大型语言模型 (LLM) 的最新进展凸显了它们在各个领域响应查询的潜力。然而,确保生成agents提供准确可靠的答案仍然是一个持续的挑战。在这种背景下,多agents辩论 (MAD) 已成为一种有前途的策略,可提高 LLM 的真实性。论文还对一系列辩论和提示策略进行了基准测试,以探索成本、时间和准确性之间的权衡。重要的是,目前形式的多agent辩论系统并不能可靠地胜过其他提议的提示策略,例如自洽和使用多种推理路径的集成。然而,在执行超参数调整时,多个 MAD 系统(例如 Multi-Persona)表现更好。这表明 MAD 协议可能本质上并不比其他方法差,但它们对不同的超参数设置更敏感并且难以优化。基于这些结果,提供改进辩论策略的见解,例如调整agent协议水平,这可以显著提高性能,甚至超越其他非辩论协议。
论文链接:
Should we be going MAD? A Look at Multi-Agent Debate Strategies for LLMs
代码链接:
DebateLLM
Can LLMs Speak For Diverse People? Tuning LLMs via Debate to Generate Controllable Controversial Statements
让 LLM 代表不同群体(尤其是少数群体)发声,并生成支持他们多样化甚至有争议的观点的陈述,对于营造包容性环境至关重要。然而,现有的 LLM 对其生成内容的立场缺乏足够的可控性,往往包含不一致、中立或有偏见的陈述。本文提高了 LLM 在生成支持用户在提示中定义的论点的陈述方面的可控性。两个立场相反的 LLM 之间的多轮辩论会为每个辩论生成更高质量、更突出的陈述,这些陈述是提高 LLM 可控性的重要训练数据。受此启发,论文提出了一种新颖的辩论与调整(DEBATUNE)pipeline,对 LLM 进行微调以生成通过辩论获得的陈述。为了研究 DEBATUNE,论文整理了迄今为止最大的辩论主题数据集,该数据集涵盖了 710 个有争议的主题以及每个主题对应的论点。 GPT-4 judge使用新颖的争议可控性指标进行的评估表明,DEBATUNE 显著提高了 LLM 生成多样化观点的能力。此外,这种可控性可以推广到未见过的主题,从而生成支持争议性论点的高质量陈述。
DEBATUNE 有两个主要阶段,即辩论和训练。在辩论阶段,DEBATUNE旨在通过多轮辩论,针对每个争议话题的每个立场,实现高质量、突出且多样化的陈述(由不同的论点引发)。在训练阶段,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











