









注:本文由我的「论文解读智能体」、「文章润色智能体」和「我」合作完成
一、引言
2024 年 9 月 18 日早上,在腾讯美国工作的 Wenhao Yu 在社交媒体上发布一个关于 ChatGPT-O1 preview 使用过程中的一个有趣的“新发现”。
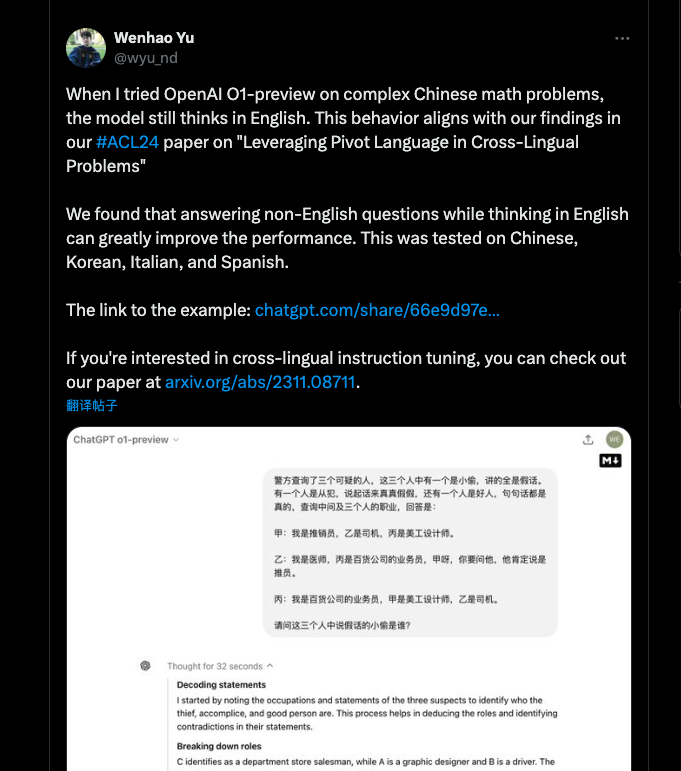
译文如下:
当我在复杂的中文数学问题上尝试使用 OpenAI 的 O1-preview 时,模型仍然以英语进行思考。这种行为与我们在 #ACL24 论文《PLUG: Leveraging Pivot Language in Cross-Lingual Instruction Tuning》中的发现一致。我们发现,用非英语提问题以英语思考可以大大提高性能。这一结果在中文、韩语、意大利语和西班牙语上进行了测试。示例链接:https://chatgpt.com/share/66e9d97e-b0ac-8009-844d-bbdb4848ba70
论文地址:https://arxiv.org/abs/2311.08711
有很多网友表示深受启发,表示自己的喜欢用英语来写系统提示词。

也有网友对作者提出了质疑,认为推理过程虽然用英文展示并不意味着模型一定是用英文来思考问题。
论文中英对照:https://yiyibooks.cn/arxiv/2311.08711v2/index.html

二、论文 AI 解读
1 论文概括
这篇论文探讨了跨语言指令调优中的语言资源不平衡问题。现有的大型语言模型(LLM)在高资源语言(如英语)上的表现优异,但在低资源语言上表现不足,原因在于预训练数据中的语言分布不均。为了解决这一问题,论文提出了一种名为“PLUG”(Pivot Language Guided Generation)的新方法,使用高资源语言(如英语)作为枢轴语言,以提高模型在低资源语言中的指令跟随能力。通过 PLUG,模型在理解指令时先生成枢轴语言的响应,再生成目标语言的最终回应。实验表明,PLUG 方法显著提升了模型在中文、韩语、意大利语和西班牙语等低资源语言中的表现。
2 论文详情
2.1 论文解决什么问题
该论文主要解决了现有大型语言模型在低资源语言中的指令跟随能力较弱的问题,尤其是由于预训练过程中语言资源分布不均导致的能力不平衡。
2.2 论文用了什么方法
论文提出了PLUG(Pivot Language Guided Generation)方法,训练模型首先理解枢轴语言(通常为高资源语言,如英语)中的指令并生成响应,然后再生成目标语言的回应。具体来说,模型经过训练后,在接收到低资源语言的指令时,会首先在高资源语言中生成一个中间响应,并通过该中间响应引导生成最终的目标语言回应。
2.3 论文的主要创新点是什么?
提出了一种新的跨语言指令调优方法,即使用枢轴语言(高资源语言)来辅助模型在低资源语言中的生成任务。
建立了一个名为 X-AlpacaEval 的多语言指令跟随基准测试,包含了中文、韩语、意大利语和西班牙语的高质量指令数据集。
实验表明,相比于直接在目标语言中生成回应,使用枢轴语言能显著提升模型的响应质量,尤其在低资源语言上效果更加显著。
2.4 论文的主要观点或者结论是什么?
PLUG方法的有效性:在实验中,PLUG 方法显著提升了模型在多个目标语言(如中文、韩语、意大利语和西班牙语)中的指令跟随能力。与传统的单语言生成方法相比,PLUG 平均提升了32%的响应质量。
枢轴语言的重要性:PLUG 方法利用了模型在高资源语言中的强大理解和生成能力,进一步提高了低资源语言的生成质量。尤其在资源较少的韩语和意大利语中,PLUG 的改进幅度更大。
对真确性和推理能力的提升:实验还显示,PLUG 不仅提升了生成语言的流畅度,还改善了模型在低资源语言中的事实准确性和逻辑推理能力。
高效的数据使用:即使在小规模训练数据上,PLUG 方法依然展现了卓越的性能,表明该方法在数据效率上也具有优势。
3 论文相关问题
3.1 什么是低资源语言和高资源语言?
高资源语言(High-resource languages)是指那些在预训练过程中拥有丰富数据资源的语言。这些语言通常有大量的文本语料库、标注数据集和丰富的模型支持,使得它们在自然语言处理任务中表现优异。如英语。
低资源语言(Low-resource languages)是指那些在自然语言处理(NLP)任务中缺乏大量数据的语言。这些语言在大规模预训练数据中占有较少比例,缺乏丰富的语言资源,如文本语料库、标注数据集、词典、工具和模型支持。由于数据量和相关资源的稀缺,处理这些语言的模型通常表现较差。如老挝语、高棉语、缅甸语等。
这因具体模型而易,关键要看模型更擅长哪一种语言。
3.2 为什么在用非英语提问时以英语思考可以大大提高性能?
英语资源丰富:大型语言模型通常在预训练阶段接受了大量英语数据,因此在理解和生成英语内容时表现更强。相比之下,低资源语言的数据较少,模型对这些语言的理解和生成能力相对较弱 。
英语的中介作用:论文提出的 PLUG(Pivot Language Guided Generation)方法利用英语作为枢轴语言,模型先以英语生成中间回答,再将其翻译为目标语言的最终答案。这种方法充分利用了模型在英语上的强大能力,从而提升了在低资源语言上的表现 。
遵循人类的思维过程:就像人类在使用不熟悉的语言时,通常先以母语思考再翻译一样,PLUG 方法引导模型通过英语生成逻辑上更完整和准确的中间答案,再将其转换为目标语言的输出。这避免了模型直接在低资源语言中生成错误或不自然的回答 。
提高指令理解和生成质量:通过在英语中思考,模型可以更准确地理解复杂的指令,并生成具有更高逻辑性和一致性的答案,这对提升目标语言的回答质量至关重要 。
3.3 PLUG 方法与传统的单语言训练方法相比有什么优势?
PLUG 方法通过使用高资源语言作为中间语言,能有效提升低资源语言的生成质量。传统的单语言训练方法只依赖目标语言数据,往往由于预训练数据中的语言资源不平衡,导致模型在低资源语言中表现较差。
3.4 论文中的 X-AlpacaEval 基准测试有什么特点?
X-AlpacaEval是一个包含四种语言(中文、韩语、意大利语和西班牙语)的多语言指令跟随基准测试集,所有指令均由专业译者标注,确保了数据的高质量。这为评估跨语言指令调优方法提供了可靠的测试环境。
3.5 PLUG 方法对模型的原始枢轴语言能力有影响吗?
根据实验结果,PLUG方法不会对模型的枢轴语言(如英语)的生成能力造成负面影响,模型在高资源语言中的能力得以保持,同时在低资源语言中的性能显著提升。
3.6 除了英语,其他语言也可以作为枢轴语言吗?
实验表明,除了英语,其他语言也可以有效地作为枢轴语言来辅助低资源语言的生成,尤其在语言基因相似性较高的情况下(如西班牙语和意大利语),使用类似的高资源语言作为枢轴语言也能带来显著改进。
3.7 PLUG 方法能否提升模型的推理能力?
是的,实验显示,使用 PLUG 训练的模型在逻辑推理任务中(如数学问题的解答)也表现出了更高的准确率,表明 PLUG 方法不仅提升了语言生成的流畅性,也增强了推理能力。
三、总结
本论文所提到的思想与我之前讨论的提示词调优策略存在一定相似性。当提示词经过充分优化但模型表现仍不理想时,可以尝试将提示词翻译为英文,这有时会带来意想不到的提升效果。
在使用以英语为主要语言的大语言模型时,除了将提示词翻译成英文外,某些情况下也可以尝试使用中文提问,让模型以英文进行思考和作答,这可能会带来更好的效果。
对此,你有什么看法?欢迎在评论区交流讨论。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











