






因为项目需要,在知乎上爬取一些社会热点话题的一些相关资料,在爬取问题答案的时候
发现所有问题答案都是在同一个页面加载的,而且没有页数提示,每次都需要点击更多,来加载后面的答案,使用开发者工具查看,发现返回的文件中有一个questionAnswerListV2,而我们所要爬取的答案就在这个地址返回的数据里面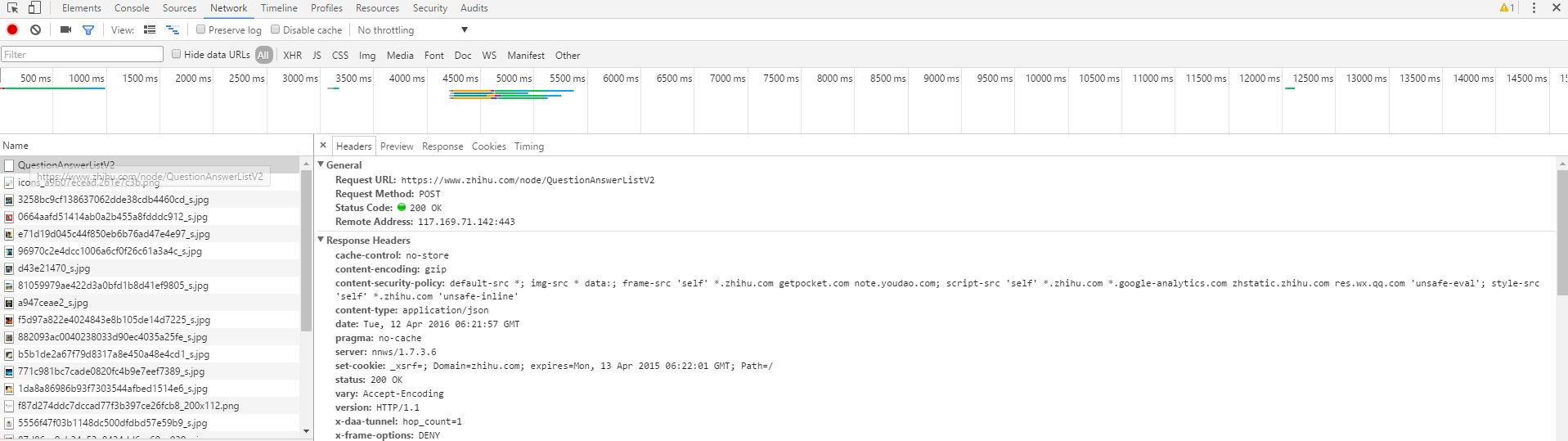
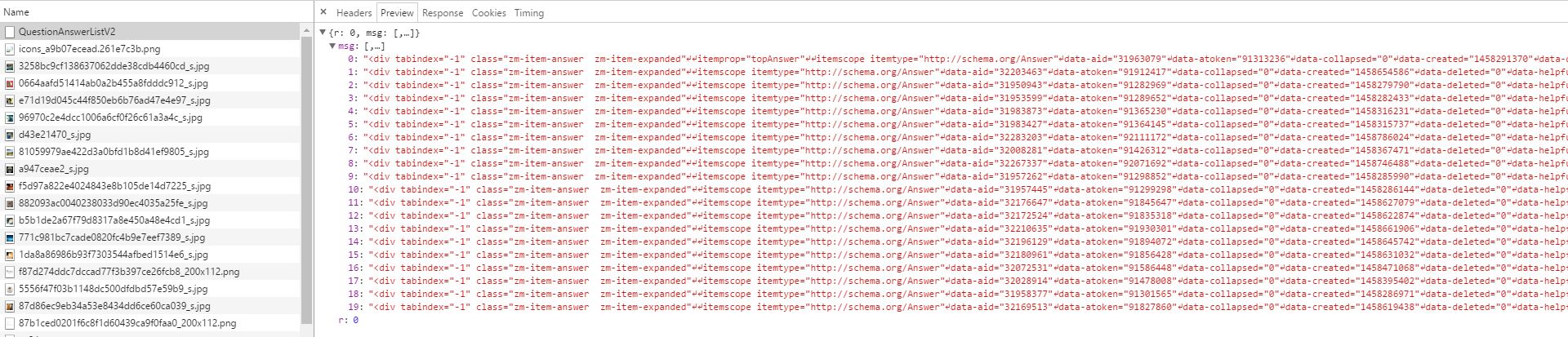
我们可以看到发送请求的url每次都是https://www.zhihu.com/node/QuestionAnswerListV2,直接访问网页将返回404状态码,因为请求网页的方式是post,因此,我们往下拉可以看到我们在点击的时候,发送的数据是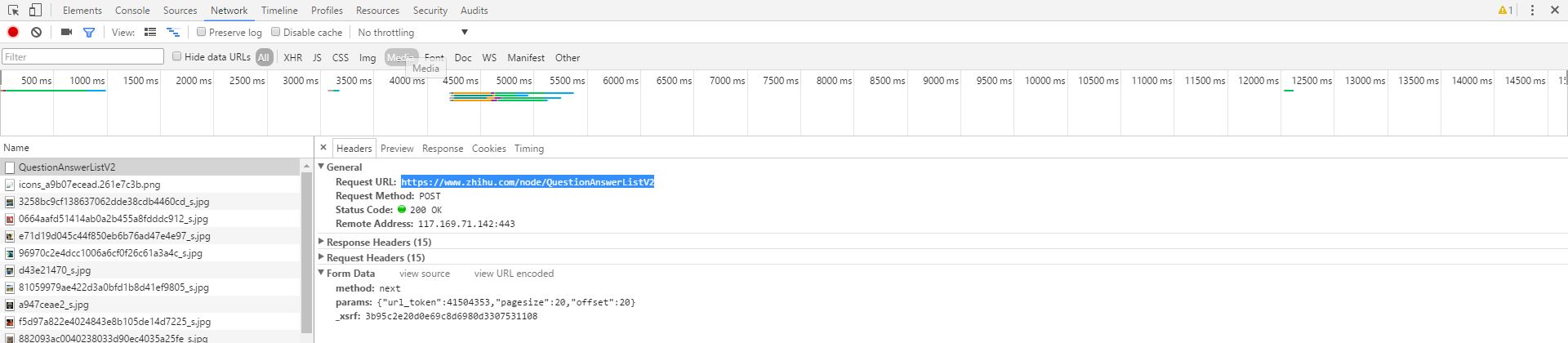
这里面就包含了我们每次点击加载更多的时候所返回的数据,因此,我们只需要在发送post请求的时候将参数带问题的id,每一次加载的数目pagesize和控制页数的offset以及method=next加上去即可获得返回的数据,在这里我用了httpclient4.4来实现这个过程,下面是我的实现代码,代码不难:
public static void main(String[] args) throws ClientProtocolException, IOException
{
RequestConfig requestConfig = RequestConfig.custom().setCookieSpec(CookieSpecs.STANDARD_STRICT).build();
CloseableHttpClient httpClient = HttpClients.custom().setDefaultRequestConfig(requestConfig).build();
HttpPost post = new HttpPost("https://www.zhihu.com/node/QuestionAnswerListV2?method=next¶ms=%7B%22url_token%22%3A41504353%2C%22pagesize%22%3A20%2C%22offset%22%3A"+page*20+"%7D");
HttpResponse httpResponse = httpClient.execute(post);
HttpEntity he = httpResponse.getEntity();
if (he != null) {
String responseString = EntityUtils.toString(he);
// System.out.println("response length:" + responseString.length());
System.out.println(UTF8(responseString));
}
}注意,我们要将引号进行转义,不然我们将无法发送正确的请求,获取不到我们所需要的数据。我们获取到的是unicode格式的字符,还要对它进行转格式。最后就可以获取到所需要的数据啦~















 995
995











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









