







PS:小知识点, yarn 应该写为: YARN,通常使用大写的 “YARN” 来指代 “Yet Another Resource Negotiator”
章节内容
上一节完成:
- Hadoop分发
- 单节点启动 NameNode初始化 DataNode启动
- YRAN启动 ResourceManager NodeManager
- 集群启动 HDFS启动 YRAN集群启动
- 各种启停相关的内容
本节内容较为简单,但是需要基于前面的内容!!!
背景介绍
这里是三台公网云服务器,每台 2C4G,搭建一个Hadoop的学习环境,供我学习。
之前已经在 VM 虚拟机上搭建过一次,但是没留下笔记,这次趁着前几天薅羊毛的3台机器,赶紧尝试在公网上搭建体验一下。
注意,如果你和我一样,打算用公网部署,那一定要做好防火墙策略,避免不必要的麻烦!!!
请大家都以学习为目的,也请不要对我的服务进行嗅探或者攻击!!!
但是有一台公网服务器我还运行着别的服务,比如前几天发的:autodl-keeper 自己写的小工具,防止AutoDL机器过期的。还跑着别的Web服务,所以只能挤出一台 2C2G 的机器。那我的配置如下了:
- 2C4G 编号 h121
- 2C4G 编号 h122
- 2C2G 编号 h123

请确保上一节内容全部完毕和跑通!!!
HDFS
创建文件夹
在h121节点上进行操作:
hdfs dfs -mkdir -p /test/input
上传文件
hdfs dfs -put /opt/wzk/test.txt /test/input
下载文件
hdfs dfs -get /test/input/test.txt

WordCount
创建文件夹
hdfs dfs -mkdir /wcinput
创建文件
在本地创建一个文件
vim /opt/wzk/wordcount.txt
写入如下的内容(当然你也可以是自己的内容)
Hadoop is an open-source framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models.
It is designed to scale up from single servers to thousands of machines, each offering local computation and storage.
The Hadoop framework application works in an environment that provides distributed storage and computation across many computers.
Hadoop is designed to scale up from single servers to thousands of machines, each offering local computation and storage.
The Hadoop Distributed File System (HDFS) is the primary storage system used by Hadoop applications.
HDFS stores large files (typically in the range of gigabytes to terabytes) across multiple machines.
Hadoop’s HDFS is designed to store very large files, and it has many features that are designed to support the storage of larg
e files.
For example, HDFS splits files into large blocks and distributes them across machines in a cluster.
The Hadoop framework transparently provides both reliability and data motion to applications.
Hadoop implements a computational paradigm named MapReduce, where the application is divided into many small fragments of work, each of which may be executed or re-executed on any node in the cluster.
上传文件
hdfs dfs -put /opt/wzk/wordcount.txt /wcinput
观察文件情况

可以看到文件已经上传了
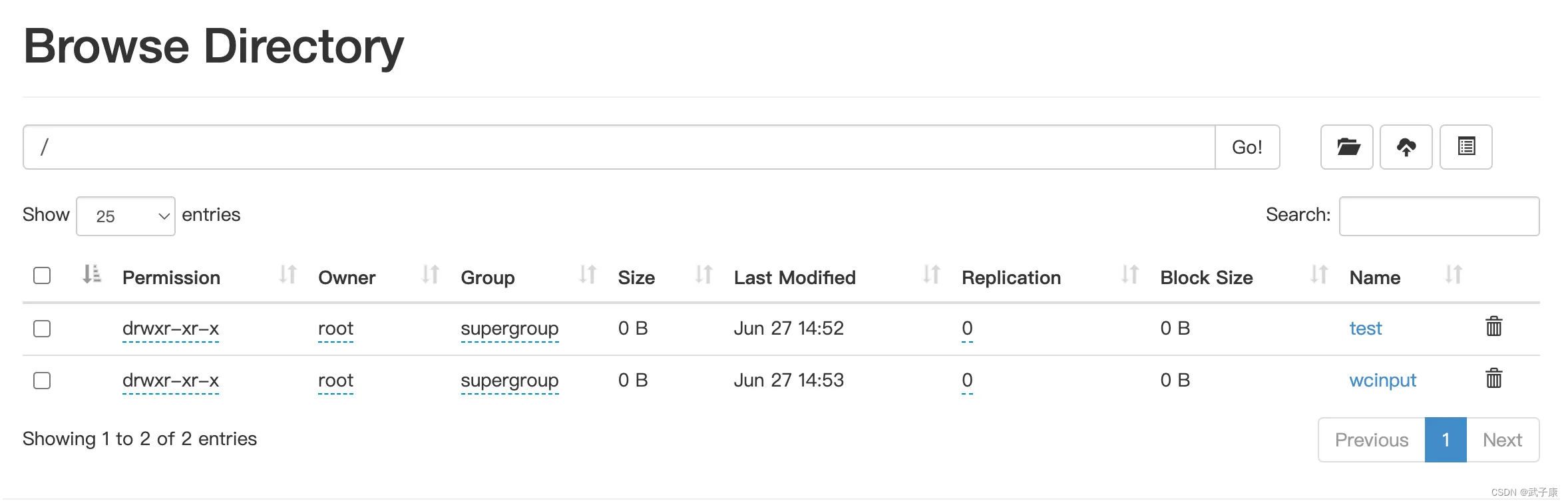
运行实例
cd /opt/servers/hadoop-2.9.2
注意下面的指令,不要写错了:
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.2.jar wordcount /wcinput /wcoutput
此时运行之后,任务会被提交到给集群运行,需要耐心的等待一会儿。
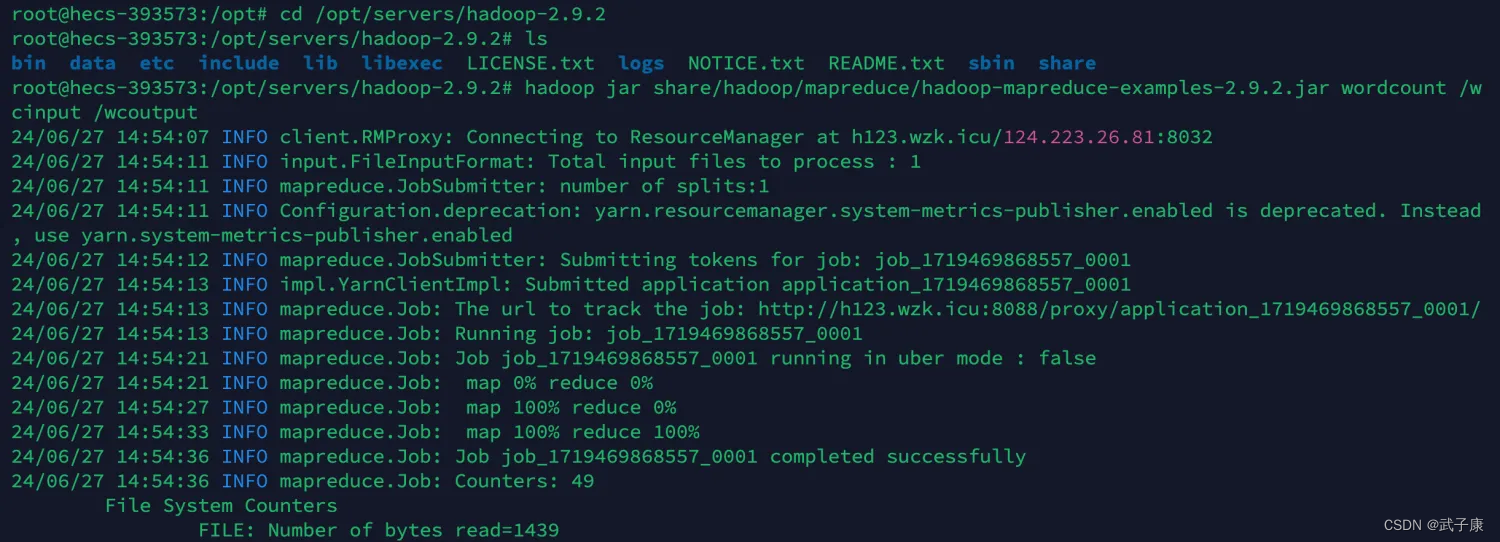
查看结果
这里可以查看到此时的HDFS的结果:
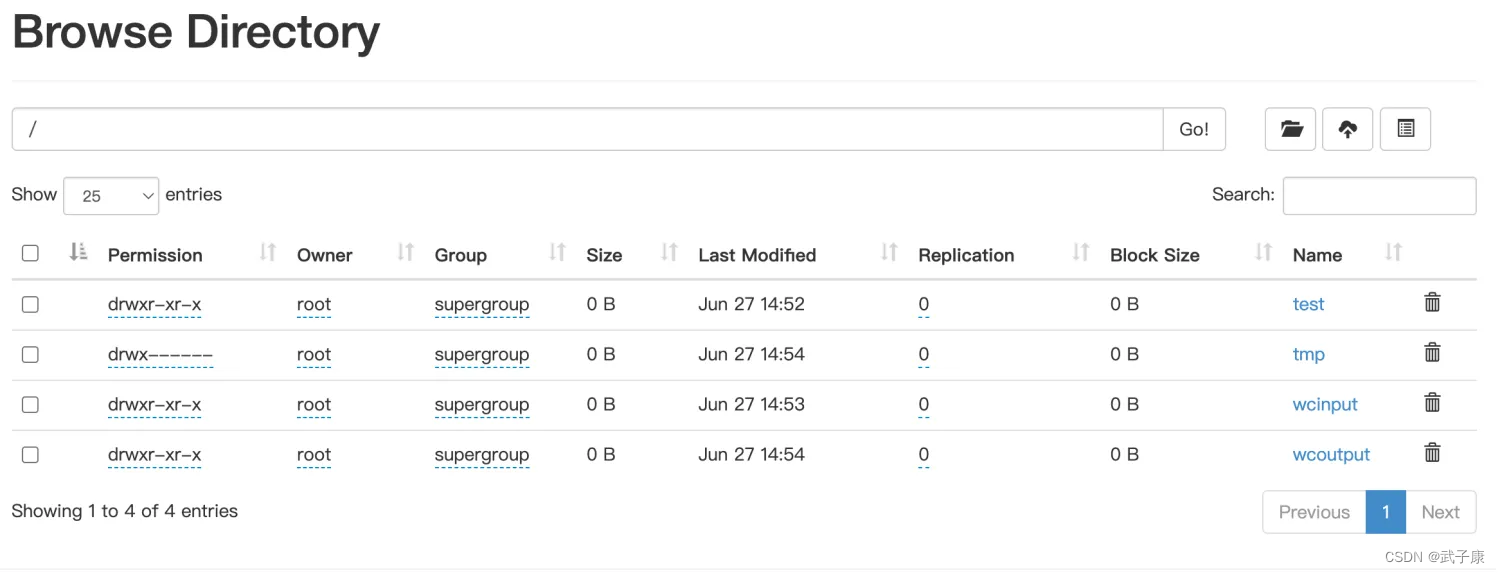
我们点击查看 wcoutput文件夹的内容:
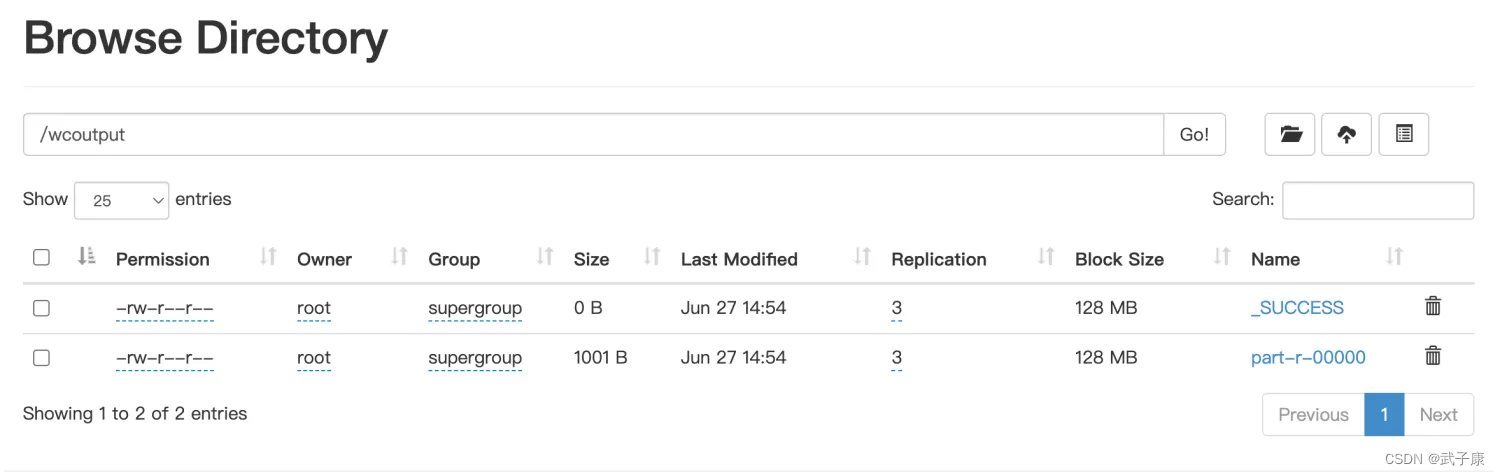
命令查看
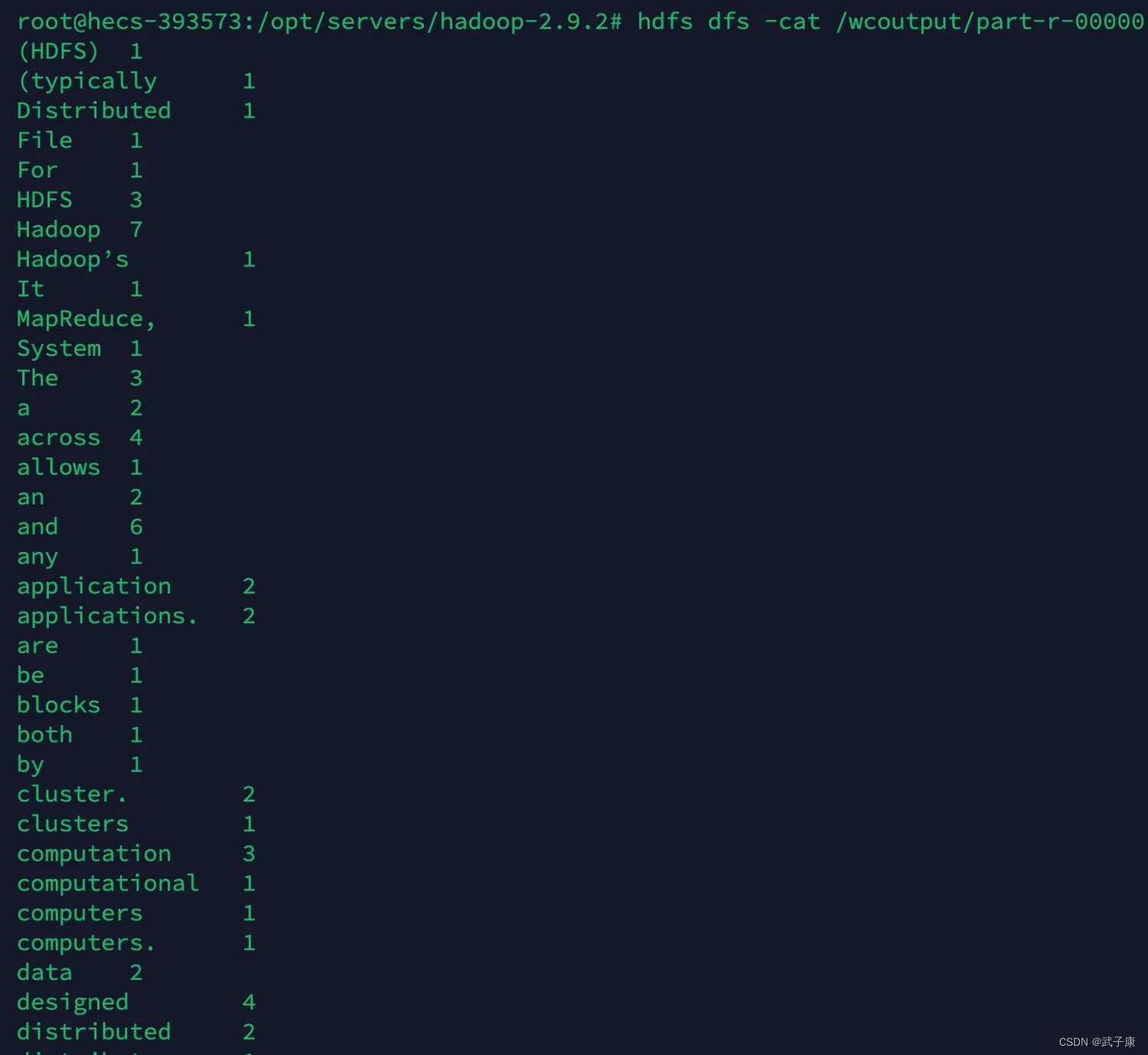
hdfs dfs -cat /wcoutput/part-r-00000
我们可以看到最终的计算结果,符合我们的预期:
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









