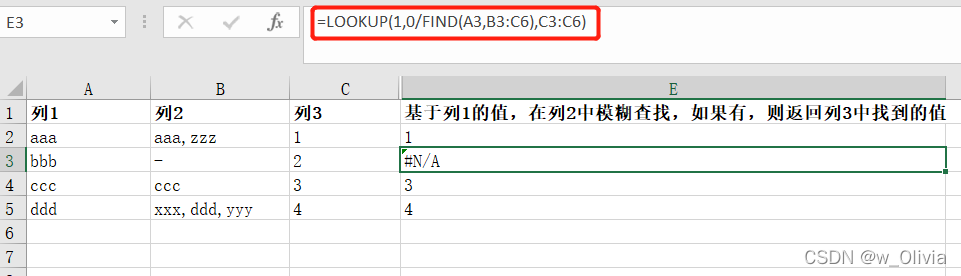
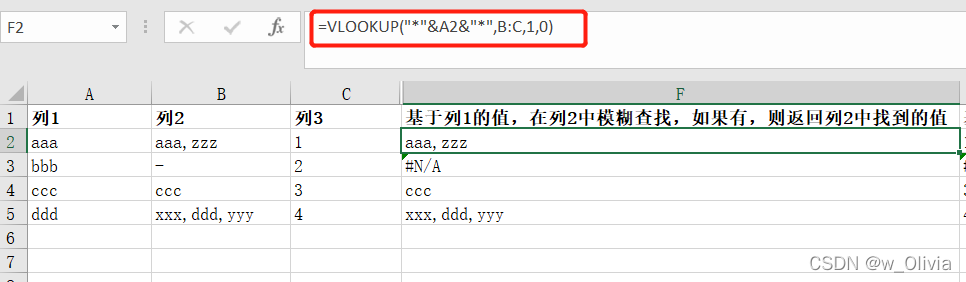
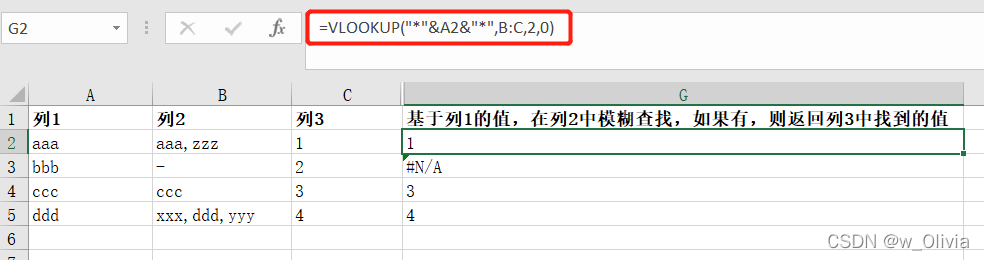
方法一: =LOOKUP(1,0/FIND(A1,B2:C5),B2:C5) —A1,要查找的字符串 ; B2:C5可以是一个单元格 情形一:基于列1的值,在列2中模糊查找,如果有,则返回列2中找到的值 情形二:基于列1的值,在列2中模糊查找,如果有,则返回列3中找到的值 方法二: =VLOOKUP(""&A2&"",B:C,1,0) 情形一:基于列1的值,在列2中模糊查找,如果有,则返回列2中找到的值 情形二:基于列1的值,在列2中模糊查找,如果有,则返回列3中找到的值


























 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


 被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言






