







基本结构
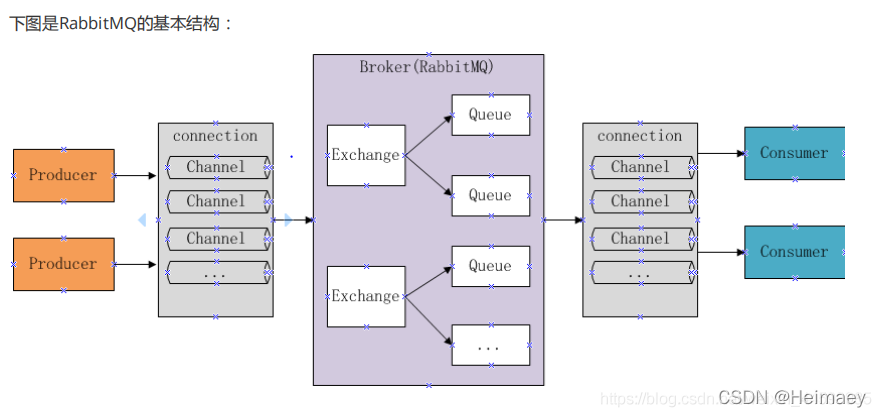
组成部分说明如下:
Broker:消息队列服务进程,此进程包括两个部分:Exchange和Queue。
Exchange:消息队列交换机,按一定的规则将消息路由转发到某个队列,对消息进行过虑。 内部实现为保存 binding 关系的查找表。
Queue:消息队列,存储消息的队列,消息到达队列并转发给指定的消费方。具有自己的 erlang 进程。
Producer:消息生产者,即生产方客户端,生产方客户端将消息发送到MQ。
Consumer:消息消费者,即消费方客户端,接收MQ转发的消息。
Binding: 绑定,它的作用就是把exchange和queue按照路由规则绑定起来
Routing Key: 路由关键字,exchange根据这个关键字进行消息投递
VHost: vhost 可以理解为虚拟 broker ,即 mini-RabbitMQ server。其内部均含有独立的 queue、exchange 和 binding 等,但最最重要的是,其拥有独立的权限系统,可以做到 vhost 范围的用户控制。当然,从 RabbitMQ 的全局角度,vhost 可以作为不同权限隔离的手段(一个典型的例子就是不同的应用可以跑在不同的 vhost 中)。
Channel: 消息通道,在客户端的每个连接里,可建立多个channel,每个channel代表一个会话任务。实际进行路由工作的实体,即负责按照 routing_key 将 message 投递给 queue 。
由 AMQP 协议描述可知,channel 是真实 TCP 连接之上的虚拟连接,所有 AMQP 命令都是通过channel 发送的,且每一个channel有唯一的ID。一个channel只能被单独一个操作系统线程使用,故投递到特定 channel 上的 message是有顺序的。但一个操作系统线程上允许使用多个 channel 。
消息发布接收流程
生产者
(1) 生产者连接到RabbitMQ Broker , 通过TCP长连接,建立一个连接(Connection) ,开启一个信道(Channel)
(2) 生产者声明一个交换器,并设置相关属性,比如交换机类型、是否持久化等
(3) 生产者声明一个队列井设置相关属性,比如是否排他、是否持久化、是否自动删除等
( 4 ) 生产者通过路由键将交换器和队列绑定起来
( 5 ) 生产者发送消息至RabbitMQ Broker,其中包含路由键、交换器等信息
(6) 相应的交换器根据接收到的路由键查找相匹配的队列。
( 7 ) 如果找到,则将从生产者发送过来的消息存入相应的队列中。
(8) 如果没有找到,则根据生产者配置的属性选择丢弃还是回退给生产者
(9) 关闭信道。
(1 0) 关闭连接。
消费者
(1)消费者连接到RabbitMQ Broker ,建立一个连接(Connection ) ,开启一个信道(Channel) 。
(2) 消费者向RabbitMQ Broker 请求消费相应队列中的消息,可能会设置相应的回调函数,
以及做一些准备工作
(3)等待RabbitMQ Broker 回应并投递相应队列中的消息, 消费者接收消息。
(4) 消费者确认( ack) 接收到的消息。
( 5) RabbitMQ 从队列中删除相应己经被确认的消息。
( 6) 关闭信道。
( 7) 关闭连接。
Kafka、ActiveMQ、RabbitMQ、RocketMQ 有什么优缺点?

RabbitMQ的交换机类型
Direct exchange(直连交换机)
完全根据key进行投递
单个绑定:
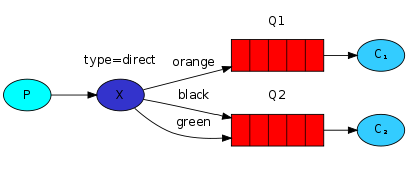
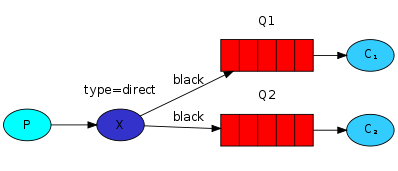
多个绑定: 消息会被同时路由到队列Q1和队列Q2
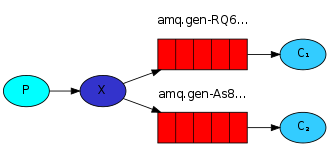
Fanout exchange(扇型交换机)
不需要key,它采取广播模式,一个消息进来时,投递到与该交换机绑定的所有队列
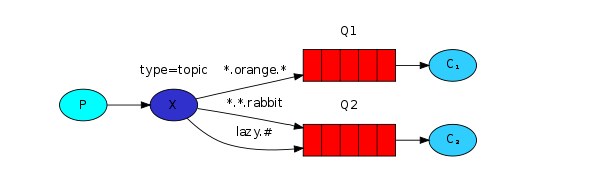
Topic exchange(主题交换机)
对key进行模式匹配后进行投递,符号”#”匹配一个或多个词,符号””匹配正好一个词。例如”abc.#”匹配”abc.def.ghi”,”abc.”只匹配”abc.def”
Dead Letter Exchange(死信交换机)
在默认情况,如果消息在投递到交换机时,交换机发现此消息没有匹配的队列,则这个消息将被悄悄丢弃。为了解决这个问题,RabbitMQ中有一种交换机叫死信交换机。当消费者不能处理接收到的消息时,将这个消息重新发布到另外一个队列中,等待重试或者人工干预。这个过程中的exchange和queue就是所谓的”Dead Letter Exchange 和 Queue”
Alternate Exchange(默认交换机)
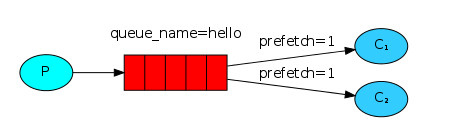
默认交换机(default exchange)实际上是一个由RabbitMQ预先声明好的名字为空字符串的直连交换机(direct exchange)。它有一个特殊的属性使得它对于简单应用特别有用处:那就是每个新建队列(queue)都会自动绑定到默认交换机上,绑定的路由键(routing key)名称与队列名称相同。如:当你声明了一个名为”hello”的队列,RabbitMQ会自动将其绑定到默认交换机上,绑定(binding)的路由键名称也是为”hello”。因此,当携带着名为”hello”的路由键的消息被发送到默认交换机的时候,此消息会被默认交换机路由至名为”hello”的队列中。即默认交换机看起来貌似能够直接将消息投递给队列,如同我们之前文章里看到一例子。
交换机的属性
除交换机类型外,在声明交换机时还可以附带许多其他的属性,其中最重要的几个分别是:
Name:交换机名称
Durability:是否持久化。如果持久性,则RabbitMQ重启后,交换机还存在
Auto-delete:当所有与之绑定的消息队列都完成了对此交换机的使用后,删掉它
Arguments:扩展参数
RabbitMQ的工作模式
simple模式(即最简单的收发模式)
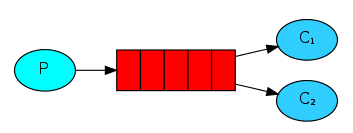
1.消息产生消息,将消息放入队列
2.消息的消费者(consumer) 监听 消息队列,如果队列中有消息,就消费掉,消息被拿走后,自动从队列中删除(隐患 消息可能没有被消费者正确处理,已经从队列中消失了,造成消息的丢失,这里可以设置成手动的ack,但如果设置成手动ack,处理完后要及时发送ack消息给队列,否则会造成内存溢出)。
work工作模式(资源的竞争)
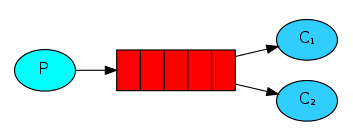
消息产生者将消息放入队列消费者可以有多个,消费者1,消费者2同时监听同一个队列,消息被消费。C1 C2共同争抢当前的消息队列内容,谁先拿到谁负责消费消息(隐患:高并发情况下,默认会产生某一个消息被多个消费者共同使用,可以设置一个开关(syncronize) 保证一条消息只能被一个消费者使用)。
publish/subscribe发布订阅(共享资源)
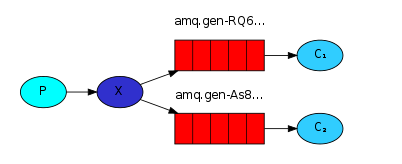
1、每个消费者监听自己的队列;
2、生产者将消息发给broker,由交换机将消息转发到绑定此交换机的每个队列,每个绑定交换机的队列都将接收到消息。
routing路由模式
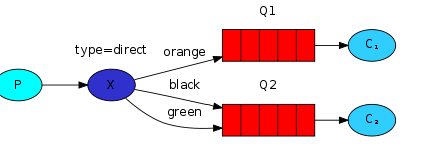
1.消息生产者将消息发送给交换机按照路由判断,路由是字符串(info) 当前产生的消息携带路由字符(对象的方法),交换机根据路由的key,只能匹配上路由key对应的消息队列,对应的消费者才能消费消息;
2.根据业务功能定义路由字符串
3.从系统的代码逻辑中获取对应的功能字符串,将消息任务扔到对应的队列中。
4.业务场景:error 通知;EXCEPTION;错误通知的功能;传统意义的错误通知;客户通知;利用key路由,可以将程序中的错误封装成消息传入到消息队列中,开发者可以自定义消费者,实时接收错误;
topic 主题模式(路由模式的一种)
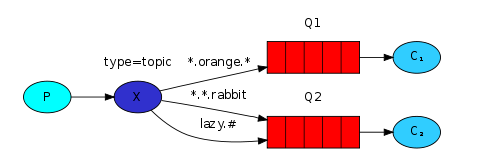
1.星号井号代表通配符
2.星号代表多个单词,井号代表一个单词
3.路由功能添加模糊匹配
4.消息产生者产生消息,把消息交给交换机
5.交换机根据key的规则模糊匹配到对应的队列,由队列的监听消费者接收消息消费
(在我的理解看来就是routing查询的一种模糊匹配,就类似sql的模糊查询方式)
消息如何分发
若该队列至少有一个消费者订阅,消息将以循环(round-robin)的方式发送给消费者。每条消息只会分发给一个订阅的消费者(前提是消费者能够正常处理消息并进行确认)。通过路由可实现多消费的功能
消息怎么路由
消息提供方->路由->一至多个队列消息发布到交换器时,消息将拥有一个路由键(routing key),在消息创建时设定。通过队列路由键,可以把队列绑定到交换器上。消息到达交换器后,RabbitMQ 会将消息的路由键与队列的路由键进行匹配(针对不同的交换器有不同的路由规则);
常用的交换器主要分为一下三种:
fanout:如果交换器收到消息,将会广播到所有绑定的队列上
direct:如果路由键完全匹配,消息就被投递到相应的队列
topic:可以使来自不同源头的消息能够到达同一个队列。 使用 topic 交换器时,可以使用通配符
消息基于什么传输
由于 TCP 连接的创建和销毁开销较大,且并发数受系统资源限制,会造成性能瓶颈。RabbitMQ 使用信道的方式来传输数据。信道是建立在真实的 TCP 连接内的虚拟连接,且每条 TCP 连接上的信道数量没有限制。
如何保证RabbitMQ消息的顺序性

-
拆分多个 queue,每个 queue 一个 consumer,就是多一些 queue 而已,确实是麻烦点;或者就一个 queue 但是对应一个 consumer,然后这个 consumer 内部用内存队列做排队,然后分发给底层不同的 worker 来处理。
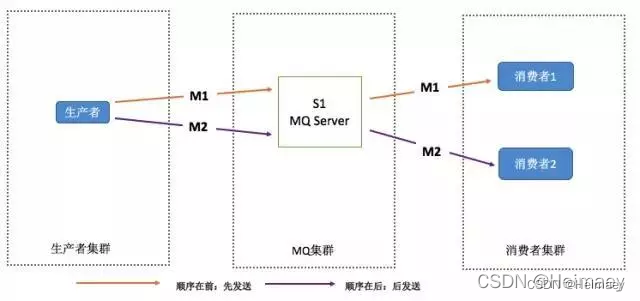
缺陷: -
并行度就会成为消息系统的瓶颈(吞吐量不够)
更多的异常处理,比如:只要消费端出现问题,就会导致整个处理流程阻塞,我们不得不花费更多的精力来解决阻塞的问题。 -
通过合理的设计或者将问题分解来规避。
不关注乱序的应用实际大量存在
队列无序并不意味着消息无序 所以从业务层面来保证消息的顺序而不仅仅是依赖于消息系统,是一种更合理的方式。 -
(推荐)一个topic下有多个queue,为了保证发送有序,rocketmq提供了MessageQueueSelector队列选择机制
可使用hash取模法,让同一个订单发送到同一个queue中,再使用同步发送,只有消息A发送成功,再发送消息B
rocketmq的topic内的队列机制,可以保证存储满足FIFO,剩下的只需要消费者顺序消费即可
rocketmq仅保证顺序发送,顺序消费由消费者业务保证
消息重复消费问题(消息幂等性)
先说为什么会重复消费:正常情况下,消费者在消费消息的时候,消费完毕后,会发送一个确认消息给消息队列,消息队列就知道该消息被消费了,就会将该消息从消息队列中删除。但是因为网络传输等等故障,确认信息没有传送到消息队列,导致消息队列不知道自己已经消费过该消息了,再次将消息分发给其他的消费者。
解决思路是:保证消息的唯一性,就算是多次传输,不要让消息的多次消费带来影响;保证消息等幂性;
在消息生产时,MQ内部针对每条生产者发送的消息生成一个inner-msg-id,作为去重和幂等的依据(消息投递失败并重传),避免重复的消息进入队列。在消息消费时,要求消息体中必须要有一个bizId(对于同一业务全局唯一,如支付ID、订单ID、帖子ID等)作为去重和幂等的依据,避免同一条消息被重复消费。
这个问题针对业务场景来答分以下几点:
- 如果消息是做数据库的insert操作,给这个消息做一个唯一主键,那么就算出现重复消费的情况,就会导致主键冲突,避免数据库出现脏数据。
- 如果消息是做redis的set的操作,不用解决,因为无论set几次结果都是一样的,set操作本来就算幂等操作。
- 如果以上两种情况还不行,可以准备一个第三方介质,来做消费记录。以redis为例,给消息分配一个全局id,只要消费过该消息,将<id,message>以K-V形式写入redis。那消费者开始消费前,先去redis中查询有没消费记录即可。
如何保证RabbitMQ消息的可靠传输
消息不可靠的情况可能是消息丢失,劫持等原因;
丢失又分为:生产者丢失消息、消息列表丢失消息、消费者丢失消息;
生产者丢失消息
从生产者弄丢数据这个角度来看,RabbitMQ提供transaction和confirm模式来确保生产者不丢消息。
transaction机制
RabbitMQ客户端中Channel 接口提供了几个事务机制相关的方法:
channel.txSelectchannel.txCommitchannel.txRollback
发送消息前,开启事务(channel.txSelect()),然后发送消息,如果发送过程中出现什么异常,事务就会回滚(channel.txRollback()),如果发送成功则提交事务(channel.txCommit())。然而,这种方式属于同步操作,一条消息发送后会使发送方处于阻塞状态,等待mq的回应后才会发送下一条消息,性能低。
源码截图如下:com.rabbitmq.client 包中public interface Channel extendsShutdownNotifier {}接口
confirm模式
通过调用channel.confirmSelect();开启confirm模式,一旦channel进入confirm模式,所有在该信道上发布的消息都将会被指派一个唯一的ID(从1开始),一旦消息被投递到所有匹配的队列之后,rabbitMQ就会发送一个确认(Basic.Ack)包含消息的唯一deliveryTag和multiple参数)给生产者,这就使得生产者知道消息已经正确到达目的队列了。如果rabbitMQ没能处理该消息,则会发送一个Nack消息给你,你可以进行重试操作。
异步监听确认及未确认消息:
channel.addConfirmListener(new ConfirmListener() {
//消息正确到达broker
@Override
public void handleAck(long deliveryTag, boolean multiple) throws IOException {
System.out.println("已收到消息");
//做一些其他处理
}
//RabbitMQ因为自身内部错误导致消息丢失,就会发送一条nack消息
@Override
public void handleNack(long deliveryTag, boolean multiple) throws IOException {
System.out.println("未确认消息,标识:" + deliveryTag);
//做一些其他处理,比如消息重发等
}
});
Confirm模式有三种方式实现
串行confirm模式
producer每发送一条消息后,调用waitForConfirms()方法,等待broker端confirm,如果服务器端返回false或者在超时时间内未返回,客户端进行消息重传。
for(int i = 0;i<50;i++){
channel.basicPublish(
exchange, routingKey,
mandatory, immediate,
messageProperties,
message.getContent()
);
if (channel.waitForConfirms()) {
System.out.println("发送成功");
} else {
//发送失败这里可进行消息重新投递的逻辑
System.out.println("发送失败");
}
}
批量confirm模式
producer每发送一批消息后,调用
waitForConfirms()方法,等待broker端confirm。
for(int i = 0;i<50;i++){
channel.basicPublish(
exchange, routingKey,
mandatory, immediate,
messageProperties,
message.getContent()
);
}
if (channel.waitForConfirms()) {
System.out.println("发送成功");
} else {
System.out.println("发送失败");
}
上面代码是简单版本的,生产环境绝对不是循环发送的,而是根据业务情况,
各个客户端程序需要定期(每x秒)或定量(每x条)或者两者结合来publish消息,然后等待服务器端confirm。相比普通confirm模式,批量可以极大提升confirm效率。
但是有没有发现什么问题?
问题1: 批量发送的逻辑复杂化了。
问题2: 一旦出现confirm返回false或者超时的情况时,客户端需要将这一批次的消息全部重发,这会带来明显的重复消息数量,并且当消息经常丢失时,批量confirm性能应该是不升反降的。
异步confirm模式
提供一个回调方法,broker confirm了一条或者多条消息后producer端会回调这个方法。
Channel channel = channelManager.getPublisherChannel(namespaceName);
ProxiedConfirmListener confirmListener = new ProxiedConfirmListener();//监听类
confirmListener.setChannelManager(channelManager);
confirmListener.setChannel(channel);
confirmListener.setNamespace(namespaceName);
confirmListener.addSuccessCallbacks(successCallbacks);
channel.addConfirmListener(confirmListener);
channel.confirmSelect();//开启confirm模式
AMQP.BasicProperties messageProperties = null;
if (message.getProperty() instanceof AMQP.BasicProperties) {
messageProperties = (AMQP.BasicProperties) message.getProperty();
}
confirmListener.toConfirm(channel.getNextPublishSeqNo(), rawMsg);
for(int i = 0;i<50;i++){
channel.basicPublish(
exchange, routingKey,
mandatory, immediate,
messageProperties,
message.getContent()
);
}
异步模式需要自己多写一部分复杂的代码实现,异步监听类,监听server端的通知消息,异步的好处性能会大幅度提升,发送完毕之后,可以继续发送其他消息。
MQServer通知生产端ConfirmListener监听类:用户可以继承接口实现自己的实现类,处理消息确认机制,此处继承类代码省略,就是上面 ProxiedConfirmListener 类:
下面贴下要实现的接口:
package com.rabbitmq.client;
import java.io.IOException;
/**
* Implement this interface in order to be notified of Confirm events.
* Acks represent messages handled successfully; Nacks represent
* messages lost by the broker. Note, the lost messages could still
* have been delivered to consumers, but the broker cannot guarantee
* this.
*/
public interface ConfirmListener {
/**
** handleAck RabbitMQ消息接收成功的方法,成功后业务可以做的事情
** 发送端投递消息前,需要把消息先存起来,比如用KV存储,接收到ack后删除
**/
void handleAck(long deliveryTag, boolean multiple)
throws IOException;
//handleNack RabbitMQ消息接收失败的通知方法,用户可以在这里重新投递消息
void handleNack(long deliveryTag, boolean multiple)
throws IOException;
}
上面的接口很有意思,如果是你的话,怎么实现?
消息投递前如何存储消息,ack 和 nack 如何处理消息?
下面看下异步confirm的消息投递流程:
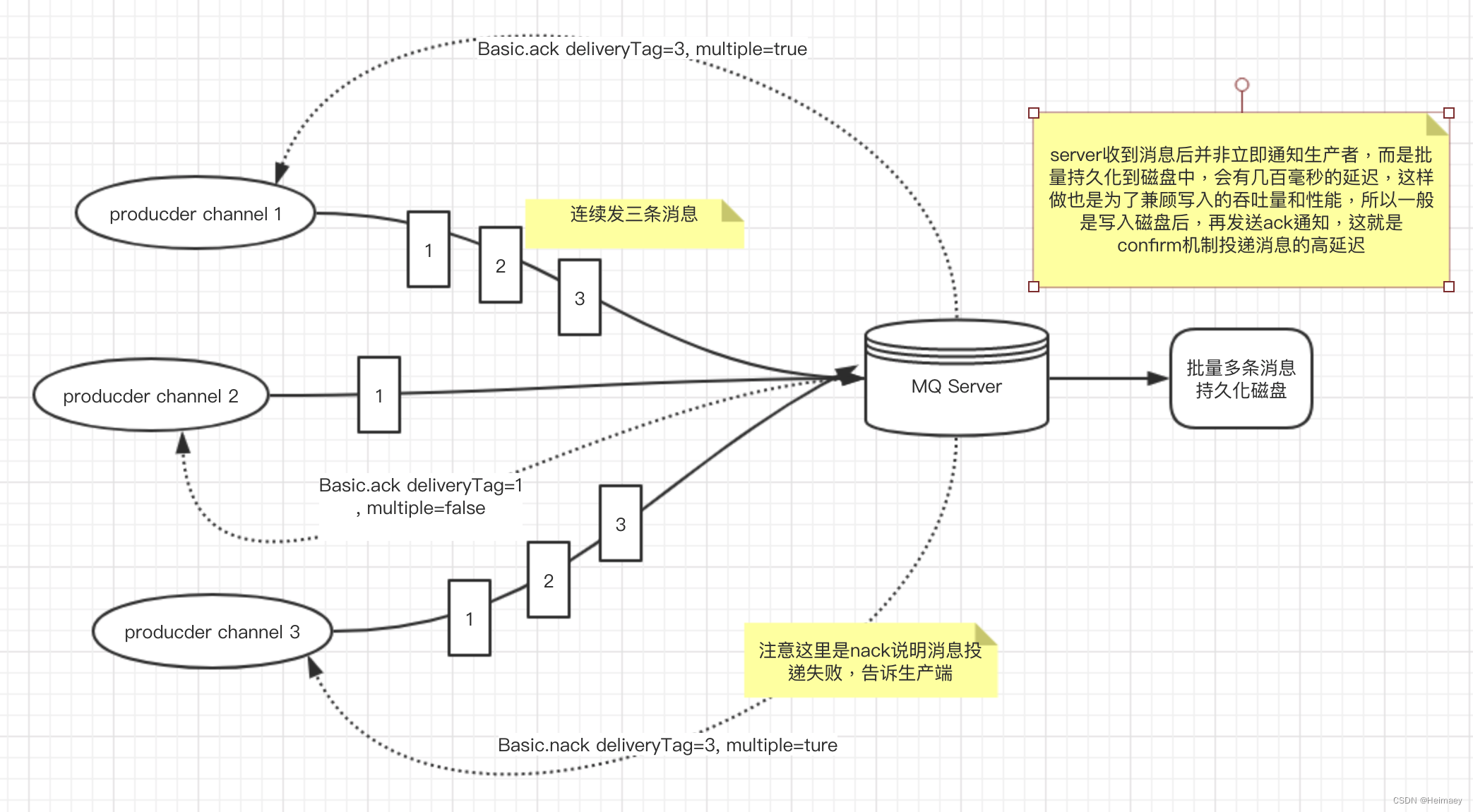
解释下这张图片:
channel1 连续发类1,2,3条消息到RabbitMQ-Server,RabbitMQ-Server通知返回一条通知,里面包含回传给生产者的确认消息中的deliveryTag包含了确认消息的序号,此外还有一个参数multiple=true,表示到这个序号之前的所有消息都已经得到了处理。这样客户端和服务端通知的次数就减少类,提升类性能。
channel3 发送的消息失败了,生产端需要对投递消息重新投递,需要额外处理代码。
那么生产端需要做什么事情呢?因为是异步的,生产端需要存储消息然后根据server通知的消息,确认如何处理,于是我们面临的问题是:
第一:发送消息之前把消息存起来
第二:监听ack 和 nack 并做响应处理
那么怎么存储呢?
我们分析下,可以使用SortedMap 存储,保证有序,但是有个问题高并发情况下,
每秒可能几千甚至上万的消息投递出去,消息的ack要等几百毫秒的话,放内存可能有内存溢出的风险。所以建议采用KV存储,KV存储承载高并发能力高,性能好,但是要保证KV 高可用,单个有个缺点就是又引入了第三方中间件,复杂度升高。
消息队列丢数据
message消息到达RabbitMQ后先是到exchange交换机中,然后路由给queue队列,最后发送给消费端。所以要消息完全持久化:Message(channel.basicPublish(EXCHANGE_NAME, ROUTING_KEY, MessageProperties.PERSISTENT_TEXT_PLAIN, message.getBytes(StandardCharsets.UTF_8));)、Exchange(channel.exchangeDeclare(EXCHANGE_NAME, "direct", true);)、Queue(channel.queueDeclare(QUEUE_NAME, true, false, false, null);)都要开启持久化,有一个没开启,持久化机制也是无效的(queue 和 exchange 具有durable 属性,同时 message 具有 persistent 属性)
处理消息队列丢数据的情况,一般是开启持久化磁盘的配置。
这个持久化配置可以和confirm机制配合使用,你可以在消息持久化磁盘后,再给生产者发送一个Ack信号。
这样,如果消息持久化磁盘之前,rabbitMQ阵亡了,那么生产者收不到Ack信号,生产者会自动重发。
那么如何持久化呢?
这里顺便说一下吧,其实也很容易,就下面两步
1、将queue的持久化标识durable设置为true,则代表是一个持久的队列
2、发送消息的时候将deliveryMode=2
这样设置以后,即使rabbitMQ挂了,重启后也能恢复数据
交换机没有匹配队列发生消息丢失
事务机制和publisher confirm机制确保的是消息能够正确的发送至RabbitMQ,这里的“发送至RabbitMQ”的含义是指消息被正确的发往至RabbitMQ的交换器,如果此交换器没有匹配的队列的话,那么消息也将会丢失,怎么办?
这里有两个解决方案,
- 使用mandatory 设置true
- 利用备份交换机(alternate-exchange):实现没有路由到队列的消息
我们看下RabbitMQ客户端代码方法
Channel 类中 发布消息方法
void basicPublish(String exchange, String routingKey, boolean mandatory, boolean immediate, BasicProperties props, byte[] body)
throws IOException;
解释下:basicPublish 方法中的,mandatory和immediate
/**
* 当mandatory标志位设置为true时,如果exchange根据自身类型和消息routeKey无法找到一个符合条件的queue, 那么会调用basic.return方法将消息返回给生产者<br>
* 当mandatory设置为false时,出现上述情形broker会直接将消息扔掉。
*/
@Setter(AccessLevel.PACKAGE)
private boolean mandatory = false;
/**
* 当immediate标志位设置为true时,如果exchange在将消息路由到queue(s)时发现对于的queue上没有消费者, 那么这条消息不会放入队列中。
当immediate标志位设置为false时,exchange路由的队列没有消费者时,该消息会通过basic.return方法返还给生产者。
* RabbitMQ 3.0版本开始去掉了对于immediate参数的支持,对此RabbitMQ官方解释是:这个关键字违背了生产者和消费者之间解耦的特性,因为生产者不关心消息是否被消费者消费掉
*/
@Setter(AccessLevel.PACKAGE)
private boolean immediate;
所以为了保证消息的可靠性,需要设置发送消息代码逻辑。如果不单独形式设置mandatory=false
使用mandatory 设置true的时候有个关键点要调整,生产者如何获取到没有被正确路由到合适队列的消息呢?通过调用channel.addReturnListener来添加ReturnListener监听器实现,只要发送的消息,没有路由到具体的队列,ReturnListener就会收到监听消息。
channel.addReturnListener(new ReturnListener() {
public void handleReturn(int replyCode, String replyText, String exchange, String routingKey, AMQP
.BasicProperties basicProperties, byte[] body) throws IOException {
String message = new String(body);
//进入该方法表示,没路由到具体的队列
//监听到消息,可以重新投递或者其它方案来提高消息的可靠性。
System.out.println("Basic.Return返回的结果是:" + message);
}
});
此时有人问了,不想复杂化生产者的编程逻辑,又不想消息丢失,那么怎么办?
还好RabbitMQ提供了一个叫做alternate-exchange东西,翻译下就是备份交换器,这个干什么用呢?很简单,它可以将未被路由的消息存储在另一个exchange队列中,再在需要的时候去处理这些消息。
那如何实现呢?
简单一点可以通过webui管理后台设置,当你新建一个exchange业务的时候,可以给它设置Arguments,这个参数就是 alternate-exchange,其实alternate-exchange就是一个普通的exchange,类型最好是fanout 方便管理
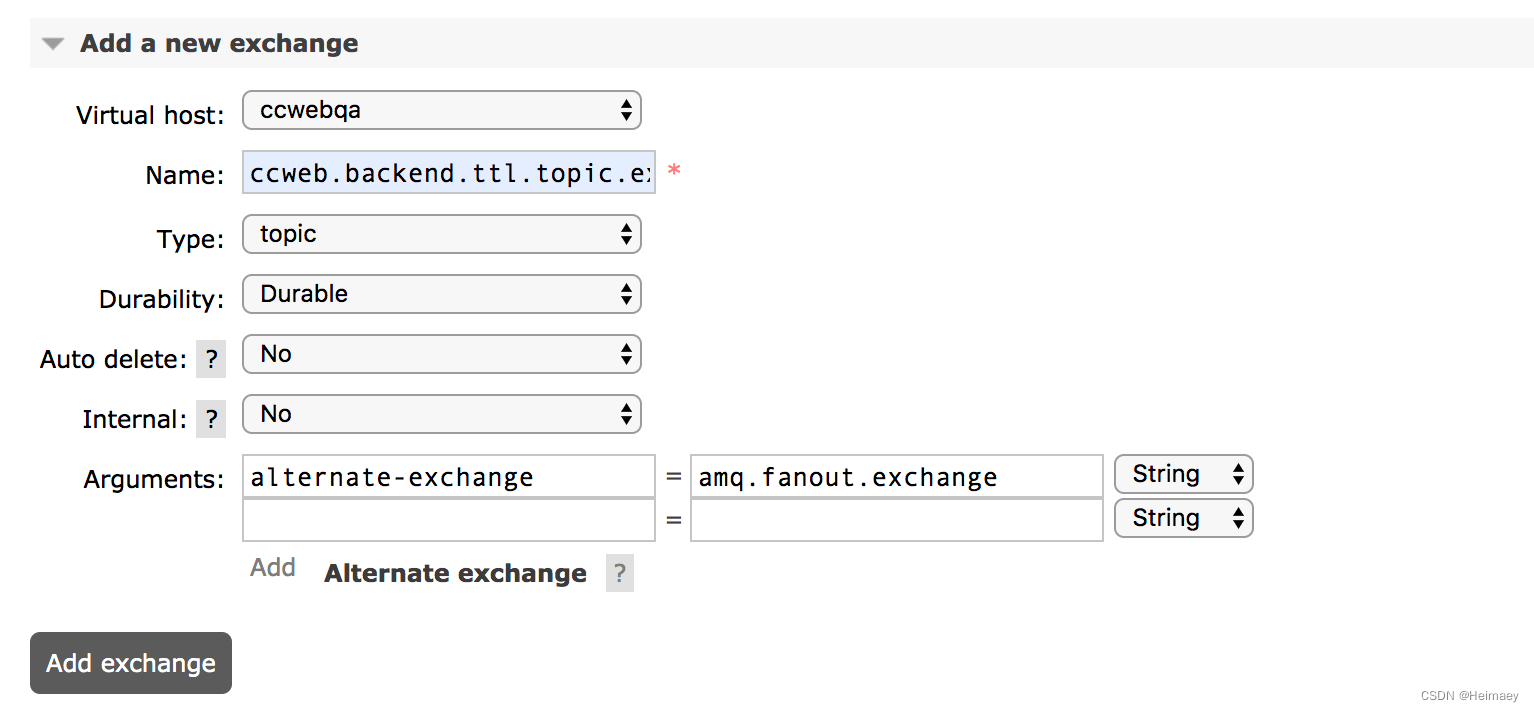
当你发送消息到你自己的exchange时候,对应key没有路由到queue,就会自动转移到alternate-exchange对应的queue,起码消息不会丢失。
下面一张图看下投递过程:
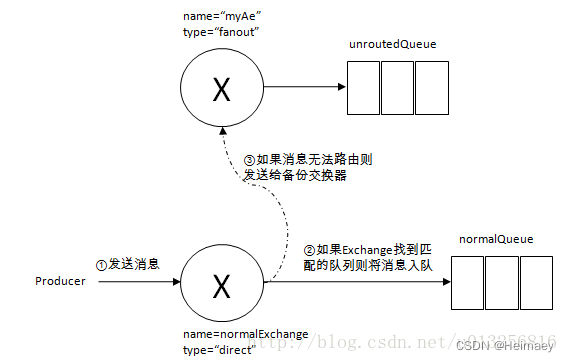
那么有人有个疑问,上面介绍了,两种方式处理,发送的消息无法路由到队列的方案,
如果备份交换器和mandatory参数一起使用,会有什么效果?
答案是:mandatory参数无效
消息补偿机制(MQ外的提供补偿测量)
消息入库
消息入库,顾名思义就是将要发送的消息保存到数据库中。
首先发送消息前先将消息保存到数据库中,有一个状态字段status=0,表示生产端将消息发送给了RabbitMQ但还没收到确认;在生产端收到确认后将status设为1,表示RabbitMQ已收到消息。这里有可能会出现上面说的两种情况,所以生产端这边开一个定时器,定时检索消息表,将status=0并且超过固定时间后(可能消息刚发出去还没来得及确认这边定时器刚好检索到这条status=0的消息,所以给个时间)还没收到确认的消息取出重发(第二种情况下这里会造成消息重复,消费者端要做幂等性),可能重发还会失败,所以可以做一个最大重发次数,超过就做另外的处理。
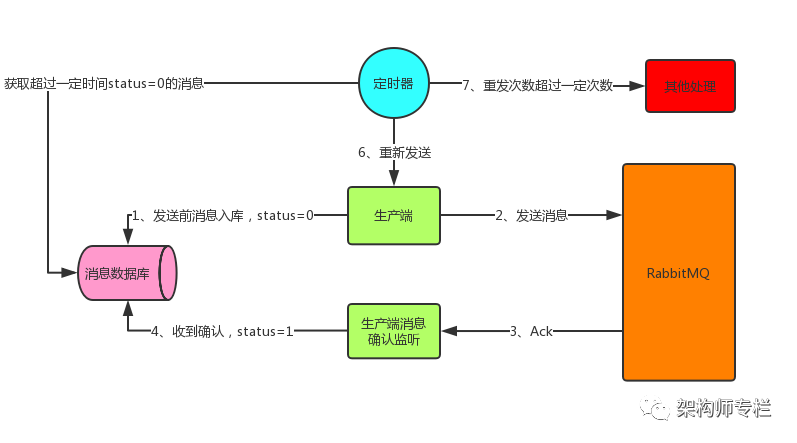
这样消息就可以可靠性投递到RabbitMQ中了,而生产端也可以感知到了。
消费者丢失消息
消费者丢数据一般是因为采用了自动确认消息模式,改为手动确认消息即可!
消费者在收到消息之后,处理消息之前,会自动回复RabbitMQ已收到消息,如果这时处理消息失败,就会丢失该消息。
解决方案:处理消息成功后,手动回复确认消息。
自动确认模式:消费者挂掉,待ack的消息回归到队列中。消费者抛出异常,消息会不断的被重发,直到处理成功。不会丢失消息,即便服务挂掉,没有处理完成的消息会重回队列,但是异常会让消息不断重试。
手动确认模式:如果消费者来不及处理就死掉时,没有响应ack时会重复发送一条信息给其他消费者;如果监听程序处理异常了,且未对异常进行捕获,会一直重复接收消息,然后一直抛异常;如果对异常进行了捕获,但是没有在finally里ack,也会一直重复发送消息(重试机制)。
DeliverCallback deliverCallback = (consumerTag, delivery) -> {
try {
//接收到消息,做处理
//手动确认
channel.basicAck(delivery.getEnvelope().getDeliveryTag(), false);
} catch (Exception e) {
//出错处理,这里可以让消息重回队列重新发送或直接丢弃消息
}
};
//第二个参数autoAck设为false表示关闭自动确认机制,需手动确认
channel.basicConsume(QUEUE_NAME, false, deliverCallback, consumerTag -> {});
不确认模式:
acknowledge=“none” 不使用确认机制,只要消息发送完成会立即在队列移除,无论客户端异常还是断开,只要发送完就移除,不会重发。
如何解决消息队列的延时以及过期失效问题?消息队列满了以后该怎么处理?有几百万消息持续积压几小时,说说怎么解决?
消息积压处理办法:临时紧急扩容:
先修复 consumer 的问题,确保其恢复消费速度,然后将现有 cnosumer 都停掉。
新建一个 topic,partition 是原来的 10 倍,临时建立好原先 10 倍的 queue 数量。
然后写一个临时的分发数据的 consumer 程序,这个程序部署上去消费积压的数据,消费之后不做耗时的处理,直接均匀轮询写入临时建立好的 10 倍数量的 queue。
接着临时征用 10 倍的机器来部署 consumer,每一批 consumer 消费一个临时 queue 的数据。这种做法相当于是临时将 queue 资源和 consumer 资源扩大 10 倍,以正常的 10 倍速度来消费数据。
等快速消费完积压数据之后,得恢复原先部署的架构,重新用原先的 consumer 机器来消费消息。
MQ中消息失效:假设你用的是 RabbitMQ,RabbtiMQ 是可以设置过期时间的,也就是 TTL。如果消息在 queue 中积压超过一定的时间就会被 RabbitMQ 给清理掉,这个数据就没了。那这就是第二个坑了。这就不是说数据会大量积压在 mq 里,而是大量的数据会直接搞丢。我们可以采取一个方案,就是批量重导,这个我们之前线上也有类似的场景干过。就是大量积压的时候,我们当时就直接丢弃数据了,然后等过了高峰期以后,比如大家一起喝咖啡熬夜到晚上12点以后,用户都睡觉了。这个时候我们就开始写程序,将丢失的那批数据,写个临时程序,一点一点的查出来,然后重新灌入 mq 里面去,把白天丢的数据给他补回来。也只能是这样了。假设 1 万个订单积压在 mq 里面,没有处理,其中 1000 个订单都丢了,你只能手动写程序把那 1000 个订单给查出来,手动发到 mq 里去再补一次。
mq消息队列块满了:如果消息积压在 mq 里,你很长时间都没有处理掉,此时导致 mq 都快写满了,咋办?这个还有别的办法吗?没有,谁让你第一个方案执行的太慢了,你临时写程序,接入数据来消费,消费一个丢弃一个,都不要了,快速消费掉所有的消息。然后走第二个方案,到了晚上再补数据吧。
消息积压问题
当生产者发送消息的速度超过了消费者处理消息的速度,就会导致队列中的消息堆积,直到队列存储消息达到上限。之后发送的消息就会成为死信,可能会被丢弃,这就是消息堆积问题。
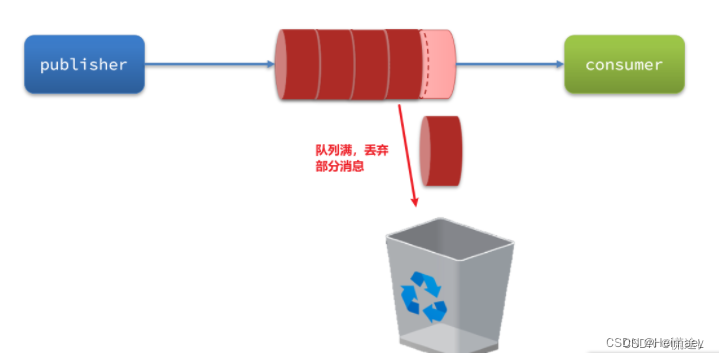
解决消息堆积有两种思路:
- 增加更多消费者,提高消费速度。也就是我们之前说的work queue模式
- 给消费者开启多线程,提高消费速度
- 使用惰性队列,扩大队列容积,提高堆积上限,将消息存入磁盘而不是内存,消息需要消费时才从磁盘中读取并加载到内存中,支持数百万条消息存储。
死信队列和延迟队列的使用
死信队列
消息被拒绝(Basic.Reject或Basic.Nack)并且设置 requeue 参数的值为 false
消息过期了
队列达到最大的长度
过期消息
在rabbitmq 中存在2种方可设置消息的过期时间,第一种通过对队列进行设置,这种设置后,该队列中所有的消息都存在相同的过期时间,第二种通过对消息本身进行设置,那么每条消息的过期时间都不一样。如果同时使用这2种方法,那么以过期时间小的那个数值为准。当消息达到过期时间还没有被消费,那么那个消息就成为了一个死信消息。
队列设置:在队列申明的时候使用 x-message-ttl 参数,单位为 毫秒
单个消息设置:是设置消息属性的 expiration 参数的值,单位为 毫秒
延时队列
在rabbitmq中不存在延时队列,但是我们可以通过设置消息的过期时间和死信队列来模拟出延时队列。消费者监听死信交换器绑定的队列,而不要监听消息发送的队列。
创建延迟队列:
1、延时队列可以由过期消息+死信队列来实现
2、过期消息通过队列中设置 x-message-ttl 参数实现
3、死信队列通过在队列申明时,给队列设置 x-dead-letter-exchange 参数,然后另外申明一个队列绑定x-dead-letter-exchange对应的交换器
为什么不应该对所有的 message 都使用持久化机制?
首先,必然导致性能的下降,因为写磁盘比写 RAM 慢的多,message 的吞吐量可能有 10 倍的差距。
其次,message 的持久化机制用在 RabbitMQ 的内置cluster集群方案时会出现“坑爹”问题。矛盾点在于,若 message 设置了 persistent 持久化属性,但 queue 未设置 durable 持久化属性,那么当该 queue 的 owner node 所有者节点出现异常后,在未重建该 queue 前,发往该 queue 的 message 将被 blackholed ;若 message 设置了 persistent 持久化属性,同时 queue 也设置了 durable 持久化属性,那么当 queue 的 owner node 所有者节点异常且无法重启的情况下,则该 queue 无法在其他 node 上重建,只能等待其 owner node 所有者节点重启后,才能恢复该 queue 的使用,而在这段时间内发送给该 queue 的 message 将被 blackholed 。
所以,是否要对 message 进行持久化,需要综合考虑性能需要,以及可能遇到的问题。若想达到 100,000 条/秒以上的消息吞吐量(单 RabbitMQ 服务器),则要么使用其他的方式来确保 message 的可靠 delivery ,要么使用非常快速的存储系统以支持全持久化(例如使用 SSD)。另外一种处理原则是:仅对关键消息作持久化处理(根据业务重要程度),且应该保证关键消息的量不会导致性能瓶颈。
如何保证高可用的?RabbitMQ 的集群
RabbitMQ 是比较有代表性的,因为是基于主从(非分布式)做高可用性的,我们就以 RabbitMQ 为例子讲解第一种 MQ 的高可用性怎么实现。RabbitMQ 有三种模式:单机模式、普通集群模式、镜像集群模式。
单机模式
就是 Demo 级别的,一般就是你本地启动了玩玩儿的?,没人生产用单机模式
普通集群模式
意思就是在多台机器上启动多个 RabbitMQ 实例,每个机器启动一个。你创建的 queue,只会放在一个 RabbitMQ 实例上,但是每个实例都同步 queue 的元数据(元数据可以认为是 queue 的一些配置信息,通过元数据,可以找到 queue 所在实例)。你消费的时候,实际上如果连接到了另外一个实例,那么那个实例会从 queue 所在实例上拉取数据过来。这方案主要是提高吞吐量的,就是说让集群中多个节点来服务某个 queue 的读写操作。
镜像集群模式
这种模式,才是所谓的 RabbitMQ 的高可用模式。跟普通集群模式不一样的是,在镜像集群模式下,你创建的 queue,无论元数据还是 queue 里的消息都会存在于多个实例上,就是说,每个 RabbitMQ 节点都有这个 queue 的一个完整镜像,包含 queue 的全部数据的意思。然后每次你写消息到 queue 的时候,都会自动把消息同步到多个实例的 queue 上。RabbitMQ 有很好的管理控制台,就是在后台新增一个策略,这个策略是镜像集群模式的策略,指定的时候是可以要求数据同步到所有节点的,也可以要求同步到指定数量的节点,再次创建 queue 的时候,应用这个策略,就会自动将数据同步到其他的节点上去了。这样的话,好处在于,你任何一个机器宕机了,没事儿,其它机器(节点)还包含了这个 queue 的完整数据,别的 consumer 都可以到其它节点上去消费数据。坏处在于,第一,这个性能开销也太大了吧,消息需要同步到所有机器上,导致网络带宽压力和消耗很重!RabbitMQ 一个 queue 的数据都是放在一个节点里的,镜像集群下,也是每个节点都放这个 queue 的完整数据。
什么是元数据?元数据分为哪些类型?包括哪些内容?与 cluster 相关的元数据有哪些?元数据是如何保存的?元数据在 cluster 中是如何分布的?
在非cluster模式下,元数据主要分为
- Queue 元数据(queue 名字和属性等)
- Exchange 元数据(exchange 名字、类型和属性等)
- Binding 元数据(存放路由关系的查找表)
- Vhost 元数据(vhost范围内针对前三者的名字空间约束和安全属性设置)
在 cluster 模式下,
- 还包括 cluster 中 node 位置信息和 node 关系信息。
元数据按照 erlang node 的类型确定是仅保存于 RAM 中,还是同时保存在 RAM 和 disk 上。元数据在 cluster 中是全 node 分布的。
在单node系统和多node构成的cluster 系统中声明queue、exchange,以及进行binding会有什么不同?
当你在单 node 上声明 queue 时,只要该 node 上相关元数据进行了变更,你就会得到 Queue.Declare-ok 回应;
而在 cluster 上声明 queue ,则要求 cluster 上的全部 node 都要进行元数据成功更新,才会得到 Queue.Declare-ok 回应。另外,若 node 类型为 RAM node 则变更的数据仅保存在内存中,若类型为 disk node 则还要变更保存在磁盘上的数据。
死信队列&死信交换器 : DLX 全称(Dead-Letter-Exchange),称之为死信交换器,当消息变成一个死信之后,如果这个消息所在的队列存在x-dead-letter-exchange参数,那么它会被发送到x-dead-letter-exchange对应值的交换器上,这个交换器就称之为死信交换器,与这个死信交换器绑定的队列就是死信队列。
元数据在 cluster 中是如何分布的?
元数据在cluster 中是全 node 分布的。
RAM node 和 disk node 的区别?
RAM node 仅将 fabric(即 queue、exchange 和 binding 等 RabbitMQ 基础构件)相关元数据保存到内存中,但 disk node 会在内存和磁盘中均进行存储。RAM node 上唯一会存储到磁盘上的元数据是 cluster 中使用的 disk node 的地址。要求在 RabbitMQ cluster中至少存在一个 disk node
RabbitMQ 上的一个 queue 中存放的 message 是否有数量限制?
可以认为是无限制,因为限制取决于机器的内存,但是消息过多会导致处理效率的下降。
RabbitMQ 概念里的 channel、exchange 和 queue 是逻辑概念,还是对应着进程实体?分别起什么作用?
queue 具有自己的 erlang 进程;
exchange 内部实现为保存 binding 关系的查找表;
channel 是实际进行路由工作的实体,即负责按照 routing_key 将 message 投递给queue 。
由 AMQP 协议描述可知,channel 是真实 TCP 连接之上的虚拟连接,所有AMQP 命令都是通过 channel 发送的,且每一个 channel 有唯一的 ID。一个 channel 只能被单独一个操作系统线程使用,故投递到特定 channel 上的 message 是有顺序的。但一个操作系统线程上允许使用多个 channel 。channel 号为 0 的 channel 用于处理所有对于当前 connection 全局有效的帧,而 1-65535 号 channel 用于处理和特定 channel 相关的帧。其中每一个 channel 运行在一个独立的线程上,多线程共享同一个 socket。
vhost 是什么?起什么作用?
vhost 可以理解为虚拟 broker ,即 mini-RabbitMQ server。其内部均含有独立的queue、exchange 和 binding 等,但最最重要的是,其拥有独立的权限系统,可以做到vhost 范围的用户控制。当然,从 RabbitMQ 的全局角度,vhost 可以作为不同权限隔离的手段(一个典型的例子就是不同的应用可以跑在不同的 vhost 中)。
若 cluster 中拥有某个 queue 的 owner node 失效了,且该 queue 被声明具有durable 属性,是否能够成功从其他 node 上重新声明该 queue ?
不能,在这种情况下,将得到 404 NOT_FOUND 错误。只能等 queue 所属的 node恢复后才能使用该 queue 。但若该 queue 本身不具有 durable 属性,则可在其他 node上重新声明。
cluster 中 node 的失效会对 consumer 产生什么影响?若是在 cluster 中创建了mirrored queue ,这时 node 失效会对 consumer 产生什么影响?
若是 consumer 所连接的那个 node 失效(无论该 node 是否为 consumer 所订阅queue 的 owner node),则 consumer 会在发现 TCP 连接断开时,按标准行为执行重连逻辑,并根据“Assume Nothing”原则重建相应的 fabric 即可。若是失效的 node 为consumer 订阅 queue 的 owner node,则 consumer 只能通过 Consumer CancellationNotification 机制来检测与该 queue 订阅关系的终止,否则会出现傻等却没有任何消息来到的问题。
能够在地理上分开的不同数据中心使用 RabbitMQ cluster 么
不能。第一,你无法控制所创建的 queue 实际分布在 cluster 里的哪个 node 上(一般使用 HAProxy + cluster 模型时都是这样),这可能会导致各种跨地域访问时的常见问题;
第二,Erlang 的 OTP 通信框架对延迟的容忍度有限,这可能会触发各种超时,导致业务疲于处理;
第三,在广域网上的连接失效问题将导致经典的“脑裂”问题,而RabbitMQ 目前无法处理(该问题主要是说 Mnesia)。
为什么 heavy RPC 的使用场景下不建议采用 disk node
heavy RPC 是指在业务逻辑中高频调用 RabbitMQ 提供的 RPC 机制,导致不断创建、销毁 reply queue ,进而造成 disk node 的性能问题(因为会针对元数据不断写盘)。所以在使用 RPC 机制时需要考虑自身的业务场景。
向不存在的 exchange 发 publish 消息会发生什么?向不存在的 queue 执行consume 动作会发生什么
都会收到 Channel.Close 信令告之不存在(内含原因 404 NOT_FOUND)。
routing_key 和 binding_key 的最大长度是多少
255 字节。
RabbitMQ 允许发送的 message 最大可达多大
根据 AMQP 协议规定,消息体的大小由 64-bit 的值来指定,所以你就可以知道到底能发多大的数据了。
什么情况下 producer 不主动创建 queue 是安全的
- message 是允许丢失的;
- 实现了针对未处理消息的 republish 功能(例如采用Publisher Confirm 机制)
为什么说保证 message 被可靠持久化的条件是 queue 和 exchange 具有durable 属性,同时 message 具有 persistent 属性才行?
binding 关系可以表示为 exchange – binding – queue 。从文档中我们知道,若要求投递的 message 能够不丢失,要求 message 本身设置 persistent 属性,要求 exchange和 queue 都设置 durable 属性。其实这问题可以这么想,若 exchange 或 queue 未设置durable 属性,则在其 crash 之后就会无法恢复,那么即使 message 设置了 persistent 属性,仍然存在 message 虽然能恢复但却无处容身的问题;同理,若 message 本身未设置persistent 属性,则 message 的持久化更无从谈起。
Consumer Cancellation Notification 机制用于什么场景?
用于保证当镜像 queue 中 master 挂掉时,连接到 slave 上的 consumer 可以收到自身 consume 被取消的通知,进而可以重新执行 consume 动作从新选出的 master 出获得消息。若不采用该机制,连接到 slave 上的 consumer 将不会感知 master 挂掉这个事情,导致后续无法再收到新 master 广播出来的 message 。另外,因为在镜像 queue 模式下,存在将 message 进行 requeue 的可能,所以实现 consumer 的逻辑时需要能够正确处理出现重复 message 的情况。
设计MQ思路
比如说这个消息队列系统,我们从以下几个角度来考虑一下:
首先这个 mq 得支持可伸缩性吧,就是需要的时候快速扩容,就可以增加吞吐量和容量,那怎么搞?设计个分布式的系统呗,参照一下 kafka 的设计理念,broker -> topic -> partition,每个 partition 放一个机器,就存一部分数据。如果现在资源不够了,简单啊,给 topic 增加 partition,然后做数据迁移,增加机器,不就可以存放更多数据,提供更高的吞吐量了?
其次你得考虑一下这个 mq 的数据要不要落地磁盘吧?那肯定要了,落磁盘才能保证别进程挂了数据就丢了。那落磁盘的时候怎么落啊?顺序写,这样就没有磁盘随机读写的寻址开销,磁盘顺序读写的性能是很高的,这就是 kafka 的思路。
其次你考虑一下你的 mq 的可用性啊?这个事儿,具体参考之前可用性那个环节讲解的 kafka 的高可用保障机制。多副本 -> leader & follower -> broker 挂了重新选举 leader 即可对外服务。
能不能支持数据 0 丢失啊?可以的,参考我们之前说的那个 kafka 数据零丢失方案。















 4628
4628











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









