






我们通过SQL语句查询表中的数据看似很快,但如果表中的数据达到百万级甚至是千万级的话,那一切都变了,针对不同的条件筛选数据时会变得很慢。如电信运营商对庞大的数据库做的优化:最简单的说,电信运营商有三个“R技能”:
1) 分布式集群:在全国各地部署大量的电信数据库,每个数据库默认只记录当前地区的实时通话记录,每隔一段时间,这些数据库的数据会同步一次。
2) 拆分表:将通话记录按照不同年份和月份的方式存在不同的表中
3) 索引:对单张表进行一些特殊的优化,提升查询效率。其中,一个重要的技术就是索引。
分布式数据库的设计及同步算法等知识点属于比较难一点的知识点了。这里,我们先对索引进行分析。
一、什么是索引:
1.正如电子书和字典的目录的作用是为了方便检索内容。在数据库中,也有相同的设计,索引就类似于这些电子书或字典的目录。另外,索引分为聚集索引和非聚集索引两种。就像新华字典,拼音目录就相当于聚集索引,而偏旁部首目录则类似于非聚集索引,为什么有这样的区别,这是因为字典中真正的内容就是按照拼音的方式存放起来的,所以拼音是聚集索引。
2.索引是如何来实现快速检索功能的呢?举例如下:
我们给一张学生信息表的学号列创建一个索引表,应该这样:
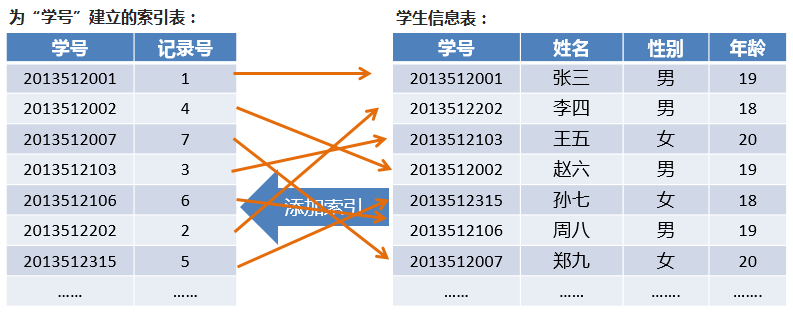
也就是说,一旦我们为学号创建一个索引,那么在数据库中,就会创建一张索引表,表中存储学号和记录号(学号在主表的位置列。其中,学号列中的数据就会进行物理排序。
我们可以通过二分查找法等算法在索引表中快速定位某个学号的位置,然后通过该学号对应的记录号获取该学号对应的学生信息在“学生信息表”中的行号。
我们来比较一下建立索引和不建立索引的平均查找时间:
1)如果我们没有建立索引表的话,则平均查找时间为n/2。

2)但如果我们建立了索引表的话,则平均查找时间为log(n)

当 n 很小的时候差别并不大;但 n 越来愈大的时候,log(n)的值远小于n/2。也就是说此时索引带来的查询效率大大提升了。总结一下,索引是对数据库表中一列或多列的值进行排序的一种结构,使用索引可快速访问数据库表中的特定信息。
二、索引的适用场景:
上面说到,使用索引可快速访问数据库表中的特定信息。但实际工作中,索引并不是越多越好。1) 索引的创建会占用物理空间,属于典型的“空间换时间”策略;2) 索引的创建和维护会耗费时间,属于典型的“双刃剑”系列。索引的优缺点非常明显,一方面,它大大加快了数据的检索速度。而另一方面,它又拖慢了数据的插入、更新和删除速度,并且还占据了一定的物理空间。所以,索引只有在特定的场景下才能起到积极的作用:
1)经常查询的字段可以考虑加索引
2)在存在大量重复值的字段,增加索引没什么太大意义
3)字段里的数据量太大,最好也不要加索引
三、索引的创建:
理论上一张表可以创建250个索引,但聚集索引实际上就是数据的物理存储排序,所以一张表只能有一个聚集索引。剩下都只能创建非聚集索引。但建立索引时讲究要适度,用量需谨慎,索引只创建在查询较多的列上。如员工表中经常通过name字段进行数据检索的话,那么就可以在此列上创建索引:

















 534
534

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











