







算法背景
决策树算法采用自上至下递归建树的技术,J.R.Quinlan在上世纪80年代提出了ID3算法(Iterative Dichotomiser 3) ,该算法奠定了日后决策树算法发展的基础。这种算法的提出得益于香农(Shannon C E.)在信息论中提出的信息熵的概念,其表示离散随机事件出现的概率。
ID3算法最核心的思想,就是以信息增益作为分裂属性选取的依据,信息增益表示某个属性能够为分类系统带来多少“信息”,信息越多,则通过该属性对数据集的分类更为准确。ID3算法适用于大多数据集的分类问题,分类速度和测试速度都比较快。但该算法未考虑到如何处理连续属性、属性缺失以及噪声等问题。
算法的目的
若给定一训练集D如下
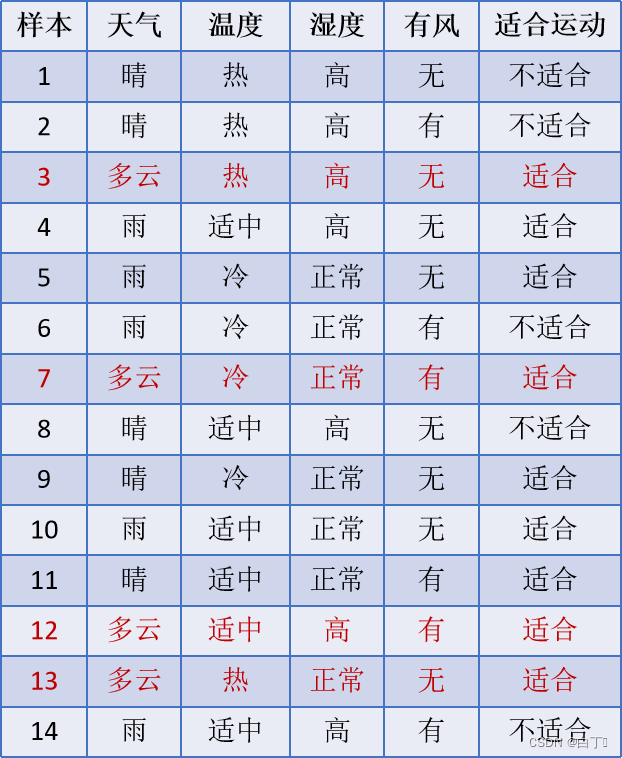
那么算法的目的就是通过训练集中的样例生成如下决策树
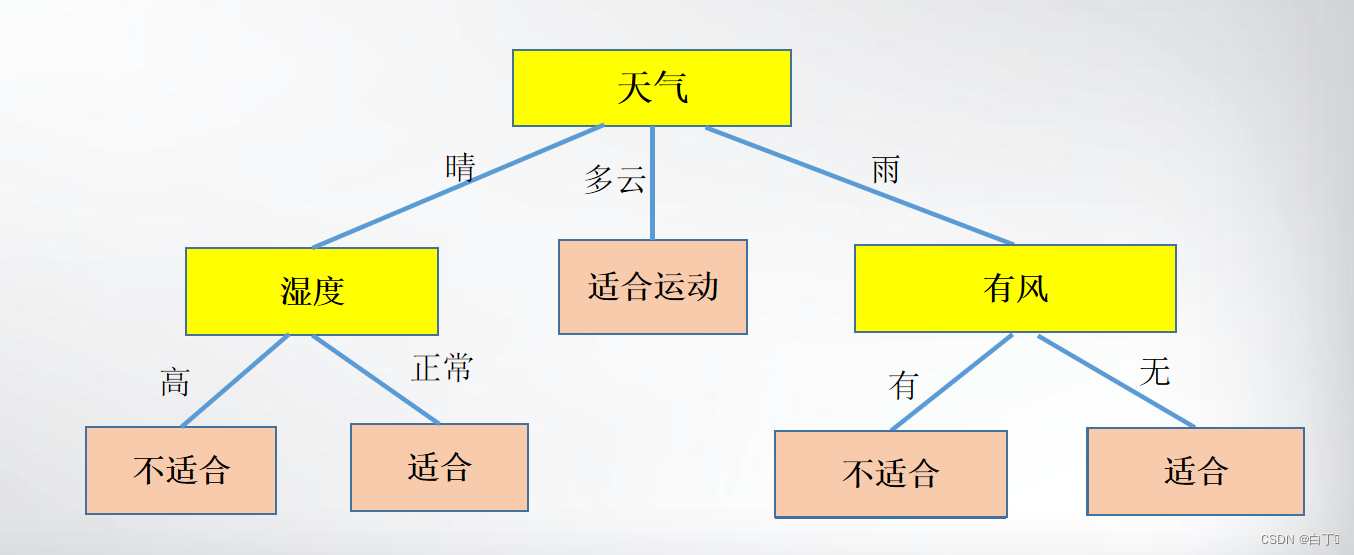
通过该决策树,我们可以从根开始逐步判断天气、湿度、温度、是否有风这四种属性来判断今天是否适合运动。这就是算法的实际意义。
相关名词
想要明白如何实现该算法,首先我们需要理解如下几个专业名词的意义。
1.信息熵
信息熵(information entropy)是度量样本集合纯度的指标。
假定当前样本集合D中第k类样本所占的比例为pk ,(k=1,2,… , n )
则D的信息熵定义为

如上例: 样本集合D有14个样本,分为适合运动和不适合运动两类,n=2
设k=1,表示适合运动,p1=9/14 ;设k=2,表示不适合运动,p2=5/14
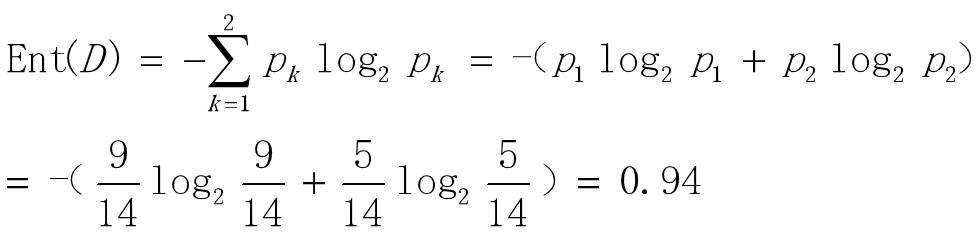
通过上面的例子,我们明白了什么叫度量样本集合纯度的指标。信息熵越大说明样本越不纯,越小说明样本越纯,当信息熵为0时,此样本的所有样本点的该属性均相同。
当随机变量只有两个取值的时候,例如0,1,那么X的分布为:
P
(
X
=
1
)
=
p
,
P
(
X
=
0
)
=
1
−
p
,
0
⩽
p
⩽
1
P(X=1)=p,P(X=0)=1-p,0\leqslant p\leqslant 1
P(X=1)=p,P(X=0)=1−p,0⩽p⩽1
那么X的熵为:
H
(
p
)
=
−
p
l
o
g
2
p
−
(
1
−
p
)
l
o
g
2
1
−
p
H(p)=-plog_{2}^{p}-(1-p)log_{2}^{1-p}
H(p)=−plog2p−(1−p)log21−p
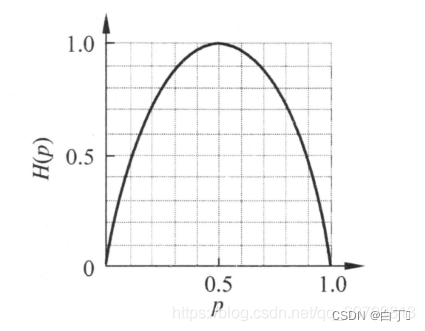
H( p)的变化曲线如下(下图来源)
2.信息增益
信息增益是表示数据集中某个特征a的信息使类D的信息的不确定性减少的程度,即特征D让类a不确定度降低。

实例: 计算天气属性的信息增益

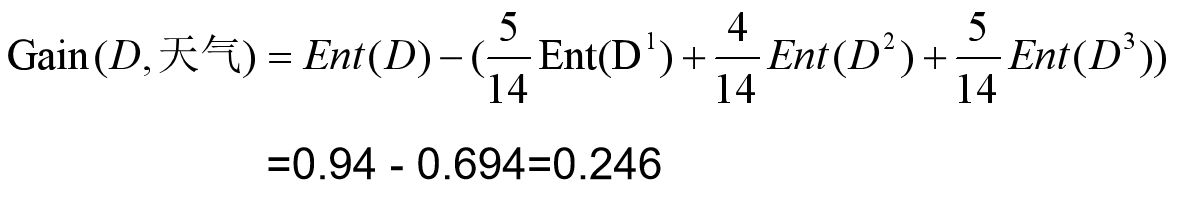
样本的天气属性有三个取值分别为:晴、多云、雨,那么可以将该样本集根据这三种取值分成D1,D2,D3,分别计算信息熵Ent(D1),Ent(D2),Ent(D3),那么数据集中天气属性的信息使类D的信息的不确定性减少的程度为
G
a
i
n
(
D
,
天气
)
=
E
n
t
(
D
)
−
(
D
1
D
E
n
t
(
D
1
)
+
D
2
D
E
n
t
(
D
2
)
+
D
3
D
E
n
t
(
D
3
)
)
Gain(D,天气)=Ent(D)-(\frac{D1}{D}Ent(D1)+\frac{D2}{D}Ent(D2)+\frac{D3}{D}Ent(D3))
Gain(D,天气)=Ent(D)−(DD1Ent(D1)+DD2Ent(D2)+DD3Ent(D3))
通过信息增益我可以知道通过样本的某个属性的判断,能够使得最终判断今天是否适合运动的结果的明确程度。Gain(D,a)越大,那么最终结果判断越明确,越小反之。
算法的思路
该算法是通过递归来创建决策树的。首先我们需要该层结点的属性集A={a1, a2, …,am}和训练集D。然后从属性集A中算出信息增益最大的属性a_max(因为我们应该使得决策树的高度尽可能的小,而每次选择信息增益最大的那个属性来作为划分属性可以使得我们接下来的判断结果更加明确),然后依据该属性的n个取值,将训练集D分为{D1,D2,D3…Dn};那么下一层递归所需要的属性集B=A-{a_max},然后分别递归D1,D2,D3…Dn.这就是递归的过程。那么递归的结束条件是什么呢。情况1:训练集D的所有样本点都属于同一类。情况2:该层递归的属性集A为空集或者训练集在属性集上的取值都是一样的。遇到上述两种情况时,我们需要将该结点置为叶子结点。以下是该算法的伪代码
输入:属性集A={a1, a2, …,am}, 训练集D
输出: 一棵决策树
1. 生成结点node
2. if D 中样本全属于同一个类别C then
3. 将node标记为C类叶结点; return; // 情形(1)
4. if A是空集 || D中所有样本在A上的取值都相同 then
5. 将node标记为C类叶结点; return; // 情形(2)
6. 从A中选择最优划分属性 ax // 通过计算信息增益选择最优属性
7. for 对训练集中的每个数据点 D do
8. 为其根据属性ax的取值分割成训练子集Di//Di被存入Ddiv
9. for 对每一个训练子集Di Ddiv do
10. 为node生成一个分支结点
11. ID3(Di,A-ax) // 递归
10. 输出以node 为根结点的决策树
算法的具体代码实现
#include <bits/stdc++.h>
using namespace std;
#define endl '\n'
vector<string> dictionary;//存储每种属性
unordered_map<string,int> swt;//属性to下标
unordered_map<string,unordered_set<string> > range_set;//每一种属性取值范围
struct Data{//数据点
int id;//样本点编号
vector<string> qualities;//存储每个属性值
};
struct TreeNode{//树节点
string name;//该层结点的划分属性
vector<TreeNode*> children;//树的子节点
vector<string> classify;//每个分支对应的属性值
};
vector<Data> training_set;//训练集
TreeNode *root;//决策树的根节点
void input(){//输入训练集信息
//freopen("data.txt","r",stdin);如果你想要直接用文本文件输入的话加入这行代码就行了,如果输出出现乱码则有可能是你文本编码格式不对,应该改为gbk2412格式
int n,m,k,id;
string a,s;
cin>>n;//n个属性
for(int i=0;i<n;i++){
cin>>a>>m;//该属性名和属性取值范围大小
dictionary.push_back(a);
swt[a]=i;
for(int j=0;j<m;j++){
cin>>s;//各属性值
range_set[a].insert(s);
}
}
vector<string> cur(dictionary.size());
cin>>k;//k个样本点
for(int i=0;i<k;i++){
cin>>id;//此样本点编号
for(int j=0;j<cur.size();j++){
cin>>cur[j];//样本各属性值
}
training_set.push_back({id,cur});//压入训练集
}
}
void output(){//输出训练集信息
queue<TreeNode*> que;
vector<TreeNode*> vec;
que.push(root);
while(!que.empty()){
int size=que.size();
vec.clear();
for(int i=0;i<size;i++){
TreeNode* cur=que.front();
que.pop();
vec.push_back(cur);
if(cur->children.size()==0)cout<<"O:";//如果为叶子节点则在前方加上"O:"以区分
cout<<cur->name<<" ";
}
cout<<endl;
for(int i=0;i<size;i++){
int cnt=0;
for(int j=0;j<vec[i]->children.size();j++){
cnt++;
cout<<"branch"<<cnt<<":"<<vec[i]->classify[j]<<" ";//如果输出分支则在前方加上"branch X:"以区分
que.push(vec[i]->children[j]);
}
}
cout<<endl;
}
}
double Ent(const vector<Data> &D){//计算该训练子集的信息熵
unordered_map<string,int> mp;
int n=D.size();
double result=0,p;
for(int i=0;i<n;i++){//将样本分类计数
mp[D[i].qualities.back()]++;
}
for(auto it=mp.begin();it!=mp.end();it++){
p=it->second*1.0/n;
result+=p*(log(p)/log(2));
}
return -1*result;
}
double Gain(const vector<Data> &D,const string &qua){//计算训练子集信息增益
double result=Ent(D);
int k=swt[qua];
unordered_map<string,int> mpa;//该属性的各属性值数据点计数
unordered_map<string,vector<Data> > mpb;//该属性的各属性值所分割的训练子集
int n=D.size();
for(int i=0;i<n;i++){
mpa[D[i].qualities[k]]++;
mpb[D[i].qualities[k]].push_back(D[i]);//分类数据集
}
for(auto it=mpb.begin();it!=mpb.end();it++){
double p=mpa[it->first]*1.0/n;
result-=p*Ent(it->second);
}
return result;
}
bool case1(const vector<Data> &D){//遇到情况1
bool flag=true;
for(int i=1;i<D.size();i++){
if(D[i].qualities.back()!=D[i-1].qualities.back()){
flag=false;
break;
}
}
return flag;
}
bool case2(const vector<Data> &D,const vector<string> &A){//遇到情况2
if(A.size()==0)return true;
bool flag=true;
for(int i=1;i<D.size();i++){
for(int j=0;j<A.size();j++){
if(D[i].qualities[swt[A[j]]]!=D[i-1].qualities[swt[A[j]]]){
flag=false;
break;
}
}
if(!flag)break;
}
return flag;
}
TreeNode* ID3(const vector<Data> &D,vector<string> A){//递归创建决策树
TreeNode* node=new TreeNode();
//情形1||情形2
if(case1(D)||case2(D,A)){
node->name=D[0].qualities.back();
return node;
}
int k=0;
double maxx=0,t;
for(int i=0;i<A.size();i++){//找到最优划分属性
t=Gain(D,A[i]);
if(maxx<t){
maxx=t;
k=i;
}
}
node->name=A[k];
unordered_map<string,vector<Data> > mp;//依据该属性分割训练集
for(int i=0;i<D.size();i++){
mp[D[i].qualities[swt[A[k]]]].push_back(D[i]);
}
A.erase(A.begin()+k,A.begin()+k+1);//移除该属性
for(auto it=mp.begin();it!=mp.end();it++){
node->classify.push_back(it->first);//记录分支属性值
node->children.push_back(ID3(it->second,A));//递归该训练子集返回子结点
}
return node;//返回该层结点
}
int main() {
input();
vector<string> A=dictionary;
A.pop_back();
root=ID3(training_set,A);
output();
return 0;
}
输入输出结果
输入格式
n——有n个属性
a1 m1 s1 s2…sm1——s属性名,范围大小为m,各个取值
a2 m2 s1 s2…sm2
…
an mn s1 s2…smn
k——样本点个数
id1 a11 a12 a13 … a1n——样本编号,样本各属性
iid2 a21 a22 a23 … a2n
…
idk ak1 ak2 ak3 … akn
输入样例
5
天气 3 晴天 多云 雨
温度 3 热 适中 冷
湿度 2 高 正常
风 2 有 无
适合运动 2 适合 不适合
14
1 晴 热 高 无 不适合
2 晴 热 高 有 不适合
3 多云 热 高 无 适合
4 雨 适中 高 无 适合
5 雨 冷 正常 无 适合
6 雨 冷 正常 有 不适合
7 多云 冷 正常 有 适合
8 晴 适中 高 无 不适合
9 晴 冷 正常 无 适合
10 雨 适中 正常 无 适合
11 晴 适中 正常 有 适合
12 多云 适中 高 有 适合
13 多云 热 正常 无 适合
14 雨 适中 高 有 不适合
输出样例
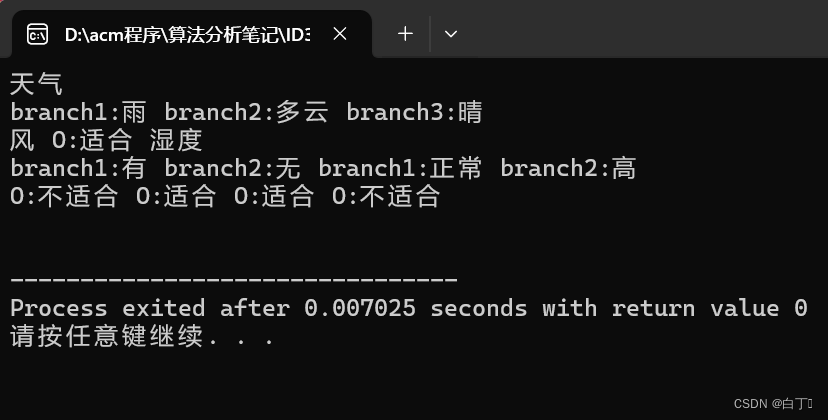
很好!输出的结果和文章开头给出的决策树图差不多!!!















 1208
1208











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









