







一句话需求:从ETL的log中提取出来一个ETL脚本落地了哪些临时表,日常数据库运维需要这些数据。
经过python程序处理后,提取到了如下的信息,这些在脚本中DELETE的都是临时表。
DELETE FROM DTEMP.L_SELL_PROXY_MARKETER_02 ALL;可能大家疑惑这个很简单啊,不用正则,python完全可以处理。暂且不去讨论”前人”为何选择正则去处理。
先上”前人”的正则表达式:
.+\.(.+)\sALL;分析该正则:
.+ .匹配换行以外的任意字符,而后面的+代表匹配优先量词,因此.+匹配了正行数据
\. 匹配一个.符号,由于要匹配这个字符,前面.+不得不将他匹配到的吐出来,直到.的位置,这就产生了几十个回溯
(.+) 同理依旧会吐下.以后所有的字符
\sALL; 又强迫(.+)吐出来很多字符,这又产生了回溯这个正则总共回溯近40次 完成了匹配,虽然对我们的程序没有产生太大的效率问题,还是决定优化下这个正则。
该正则问题在于滥用. 和+
优化思考:
1:既然我只要表名(L_SELL_PROXY_MARKETER_02)那么我是否能将匹配的锚点定到.这个位置
2:分组中的.何不换成\w
最后的正则:
(?=\.)\.(\w+).?优化后的执行:
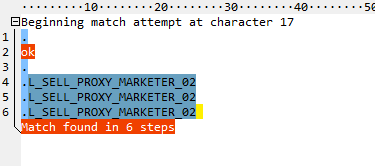
测试通过:
import re
print re.search(r"(?=\.)\.(\w+).?","DELETE FROM DTEMP.L_SELL_PROXY_MARKETER_02 ALL;").group(1)














 945
945

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









