







Author: xidianwangtao@gmail.com
Distributed TensorFlow
2016年4月TensorFlow发布了0.8版本宣布支持分布式计算,这个特性,我们称之为Distributed TensorFlow。
这是非常重要的一个特性,因为在AI的世界里,训练数据的size通常会大到让人瞠目结舌。比如Google Brain实验室今年发表的论文OUTRAGEOUSLY LARGE NEURAL NETWORKS: THE SPARSELY-GATED MIXTURE-OF-EXPERTS LAYER中提到,下图中MOE Layer Model可以达到680亿个Parameters的规模,如此复杂的模型,如果只能单机训练,那耗时难于接受。通过Distributed TensorFlow,可以利用众多服务器构建TensorFlow Cluster来提高训练效率。

关于Distributed TensorFlow的更多内容,请参考官方内容www.tensorflow.org/deplopy/distributed,这里给出Distributed TensorFlow结构图:

Why TensorFlow on Kubernetes
Distributed TensorFlow虽然提供了分布式能力,可以利用服务器集群加快训练,但是还有许多缺点,比如资源无法隔离、PS进程遗留问题等等,而这些正是Kubernetes所擅长的地方。下图是总结的你需要将TensorFlow运行在Kubernetes上的理由:

对于我们来说,前期最大的用户痛点就是算法团队使用的HDFS Read性能不及预期,经过网上查找资料及我们自己简单的对比测试,发现GlusterFS可能是最适合我们的分布式存储了。因此在我们的TensorFlow on Kubernetes项目中使用GlusterFS来存放训练数据,worker将从GlusterFS中读取训练数据进行计算。
关于PS进程遗留问题,TensorFlow社区有很多讨论,但至今没有官方的实现方案,在Kubernetes中,这将比较好解决,在后面的Thinking小节中会单独讨论。
Integrated Architecture
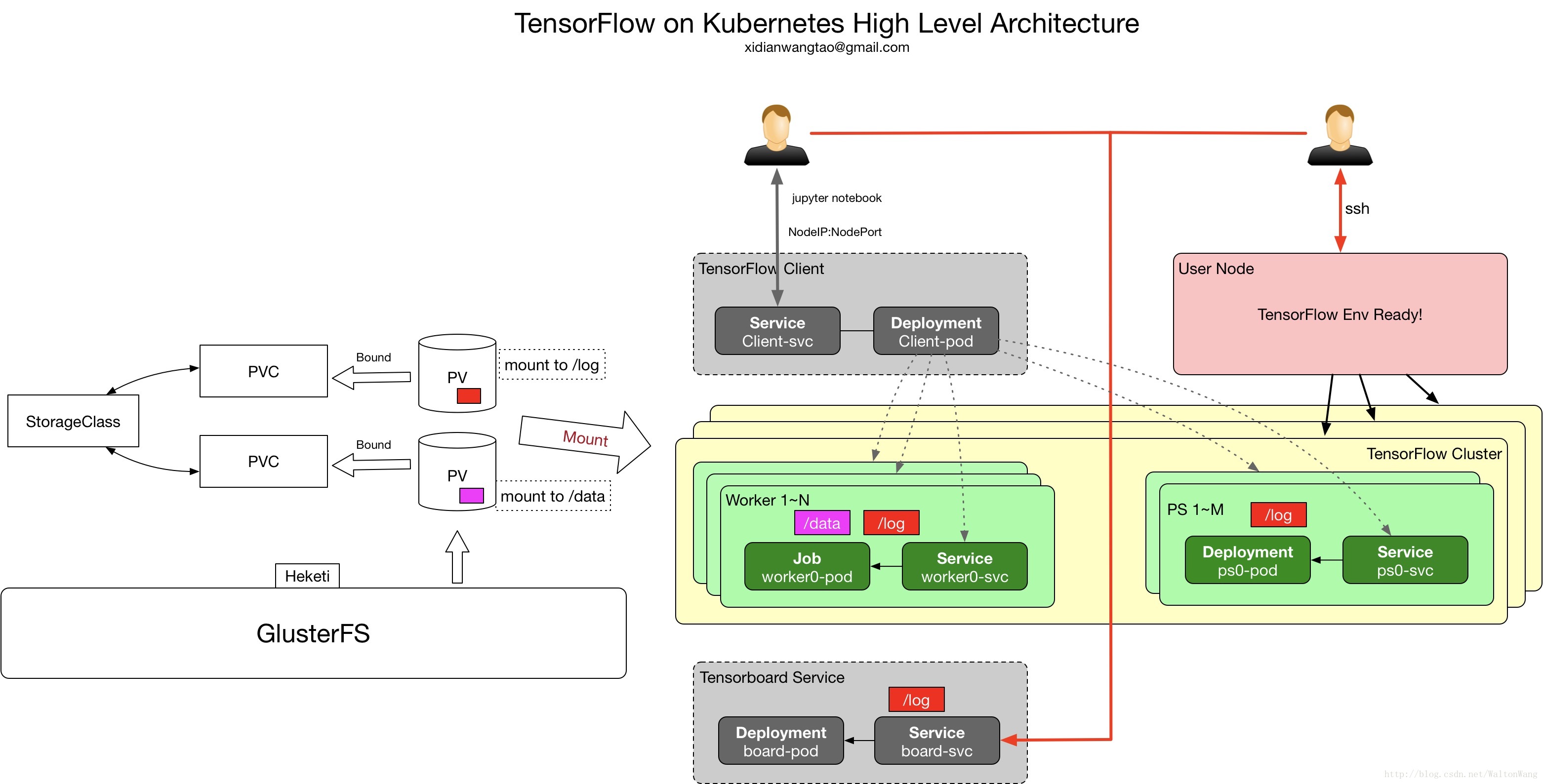
说明:
- 支持Between-Graph和In-Graph两种replication场景;
- PS Task通过Kubernetes Deployment来部署,Worker Task通过Kubernetes Job来部署,由Kubernetes service和KubeDNS来提供服务发现;
- 每个TensorFlow Cluster都会通过StorageClass来Dynamic Provision PV,事先会先创建好通过Heketi对接Gluster集群的StorageClass;
- GlusterFS集群通过Heketi来暴露rest api与Kubernetes进行交互,关于Heketi的部署,请参考官方文档;
- 每个TensorFlow Cluster会最终创建两个PV,一个用来存放训练数据(挂载到容器内/data,对应TensorFlow –data_dir配置),一个用来存储训练日志(挂载到容器内/log,对应TensorFlow –log_path配置);
- 每个用户会对应在Kubernetes中创建一个namespace;
- 会给每个用户部署一个Jupyter Notebook Deployment和Service,Service通过NodePort暴露到集群外;
- 有一个节点比较特殊,我们称之为User Node,这个节点通过Taint方式,保证会运行Pod,但是会通过kube-proxy来暴露集群内的service,比如上面的Jupyter Notebook service将只允许在这个节点暴露出去;
- User Node节点存放着用户写的python算法,并可以通过http查看和下载这些算法文件,Between-Graph场景下,容器启动后将通过curl下载这些算法文件;
- 会给没用用户创建一个Tensorboard Deployment和Service,Serivce通过NodePort暴露到集群外(同样只能在User Node暴露),Tensorboard Pod会挂着log PV,这样就能得到TensorFlow Graph。
Deploy Architecture

整个系统涉及以下核心Components:
- TensorFlow: 1.3.0
- Kubernetes: 1.7.4
- Docker: 1.12.6
- Harbor: 1.1.2
- Contiv netplugin: 0.1-12-23-2016.19-44-42.UTC
- Keepalived: 1.3.5
- Haproxy:1.7.8
- Etcd2: 2.3.7
- Etcd3: 3.2.1
- Glusterfs: 3.10.5
网络方案:contiv netplugin + ovs + vlan.
日志方案:fluentd + Kafka + ES + Kibana.
监控方案:cadvisor + prometheus + Grafana.
CaaS的细节不在这里讨论,其实也是大家非常熟悉的方案了。
Demo
大家可以参考Kyle Bai的https://github.com/kairen/workshop413,他这里时候用NFS作为后端存储,需要改成你们自己的存储,大家自己去尝试吧,我这就不一步一步来了,好无聊。
这个Demo,我改成NodePort方式暴露Jupyter Nodebook,登录时输入正确的token即可:

这是一个In-Graph集群,点击master_client.ipynb,可以看到具体的训练算法内容:

点击执行,可以在下面看到输出:

这只是个简单的Demo,实际使用上,自动化生成各个ps, worker, pvc对应的kubernetes yaml,使用域名进行服务发现,不然如果你使用IP的话,可能就需要利用Pod的ProStart Hook来反馈各个Task的IP了,这将比较麻烦。
Thinking
- Q: PS进程遗留问题,在社区讨论比较多(issue 4173),结合Kubernetes,我们可以比较简单的来做到回收PS进程的目的。
A:在DevOps的TaaS模块中,针对每个TensorFlow Cluster都启动一个协程,检查计数器是否达到worker数量(worker是job运行的,down了以后,watch到job successed,则计数器加1),如果等于worker数,则表明训练结束,等待30s后,调用kubernetes apiserver接口将ps deployment/service删除,达到自动回收ps的效果; - **Q**worker是无状态的,ps是有状态的,而ps是无法进行checkpoint的,如何进行训练save和restore呢?
A:worker虽然是无状态的,但是tf.train.Saver提供能力在worker上进行checkpoint,大概原理就是逐个从PS task中get Parameters,并进行save持久化。 Q怎么让用户指定ps和worker个数等少量参数,自动生成kubernetes yaml?
A: 因为当前我们还没有针对TaaS做前端Portal,所以目前是通过jinja template来自动生成的(可以参考tensorflow/ecosystem/kubernetes),用户只要指定少量参数即可生成ps和worker需要的kubernetes yaml。
比如下面是我的一个jinja template tfcluster_template.yaml.jinja,{%- set name = "imagenet" -%} {%- set worker_replicas = 3 -%} {%- set ps_replicas = 2 -%} {%- set script = "http://xxx.xx.xx.xxx:80/imagenet/imagenet.py" -%} {%- set image = "tensorflow/tensorflow:1.3.0" -%} {%- set data_dir = "/data" -%} {%- set log_dir = "/log" -%} {%- set port = 2222 -%} {%- set replicas = {"worker": worker_replicas, "ps": ps_replicas} -%} {%- macro worker_hosts() -%} {%- for i in range(worker_replicas) -%} {%- if not loop.first -%},{%- endif -%} {{ name }}-worker-{{ i }}:{{ port }} {%- endfor -%} {%- endmacro -%} {%- macro ps_hosts() -%} {%- for i in range(ps_replicas) -%} {%- if not loop.first -%},{%- endif -%} {{ name }}-ps-{{ i }}:{{ port }} {%- endfor -%} {%- endmacro -%} {%- for job in ["worker", "ps"] -%} {%- for i in range(replicas[job]) -%} kind: Service apiVersion: v1 metadata: name: {{ name }}-{{ job }}-{{ i }} spec: selector: name: {{ name }} job: {{ job }} task: "{{ i }}" ports: - port: {{ port }} targetPort: 2222 {% if job == "worker" %} --- kind: Job apiVersion: batch/v1 metadata: name: {{ name }}-{{ job }}-{{ i }} spec: replicas: 1 template: metadata: labels: name: {{ name }} job: {{ job }} task: "{{ i }}" spec: containers: - name: {{ name }}-{{ job }}-{{ i }} image: {{ image }} ports: - containerPort: 2222 command: ["/bin/sh", "-c"] args:[" curl {{ script }} -o /opt/{{ name }}.py; python /opt/{{ name }}.py \ --ps_hosts={{ ps_hosts() }} \ --worker_hosts={{ worker_hosts() }} \ --job_name={{ job }} \ --task_index={{ i }} \ --log_path={{ log_dir }} \ --data_dir={{ data_dir }} ;"] volumeMounts: - name: data mountPath: {{ data_dir }} - name: log mountPath: {{ log_dir }} restartPolicy: Never volumes: - name: data persistentVolumeClaim: claimName: {{ name }}-data-pvc - name: log persistentVolumeClaim: claimName: {{ name }}-log-pvc {% endif %} {% if job == "ps" %} --- kind: Deployment apiVersion: extensions/v1beta1 metadata: name: {{ name }}-{{ job }}-{{ i }} spec: replicas: 1 template: metadata: labels: name: {{ name }} job: {{ job }} task: "{{ i }}" spec: containers: - name: {{ name }}-{{ job }}-{{ i }} image: {{ image }} ports: - containerPort: 2222 command: ["/bin/sh", "-c"] args:[" curl {{ script }} -o /opt/{{ name }}.py; python /opt/{{ name }}.py \ --ps_hosts={{ ps_hosts() }} \ --worker_hosts={{ worker_hosts() }} \ --job_name={{ job }} \ --task_index={{ i }} \ --log_path={{ log_dir }} ;"] volumeMounts: - name: log mountPath: {{ log_dir }} restartPolicy: Never volumes: - name: log persistentVolumeClaim: claimName: {{ name }}-log-pvc {% endif %} --- {% endfor %} {%- endfor -%} apiVersion: v1 kind: PersistentVolumeClaim metadata: name: {{ name }}-log-pvc annotations: volume.beta.kubernetes.io/storage-class: glusterfs spec: accessModes: - ReadWriteMany resources: requests: storage: 10Gi --- apiVersion: v1 kind: PersistentVolumeClaim metadata: name: {{ name }}-data-pvc annotations: volume.beta.kubernetes.io/storage-class: glusterfs spec: accessModes: - ReadWriteMany resources: requests: storage: 10Gi ---然后执行
python render_template.py tfcluster_template.yaml.jinja | kubectl apply -f -完成对应的Between-Graph TensorFlow Cluster的创建和启动。
Summary
TensorFlow和Kubernetes分别作为深度学习和容器编排领域的王者,两者的合理整合可以将释放Distributed TensorFlow的能力,本文只是我对TensorFlow on Kubernetes的浅尝,未来还有很多工作需要做,比如给某些算法定制特殊的调度策略、网络IO性能调优、在DevOps上开发TaaS,提升易用性、TensorFlow Serving的快速部署等等,欢迎对这方面有浓厚兴趣的同学加我微信xidianwangtao交流。














 2010
2010











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









