







写在前面
本文来看一个语音克隆相关的tts大模型GPT-SoVITS,这是由花儿不哭耗时两个月的作品,并免费开源给我们使用,让我们为花儿不哭大佬鼓掌👏。
1:下载和运行
这里我们选择整合包,从这里下载,如果你有百度网盘会员的话也可以从这里下载,不然我大百度的限速功能会让你的千兆光纤显得那么的力不从心而又渺小,这是我本地下载的:

下载后注意用7z工具解压,因为其他工具可能会导致文件丢失,解压后我们会得到如下的目录结构:
启动也很简单,只需要点击其中的go-webui.bat(注意不要以管理员身份启动),耐心等待一会就会自动在浏览器打开ui了,如下图:
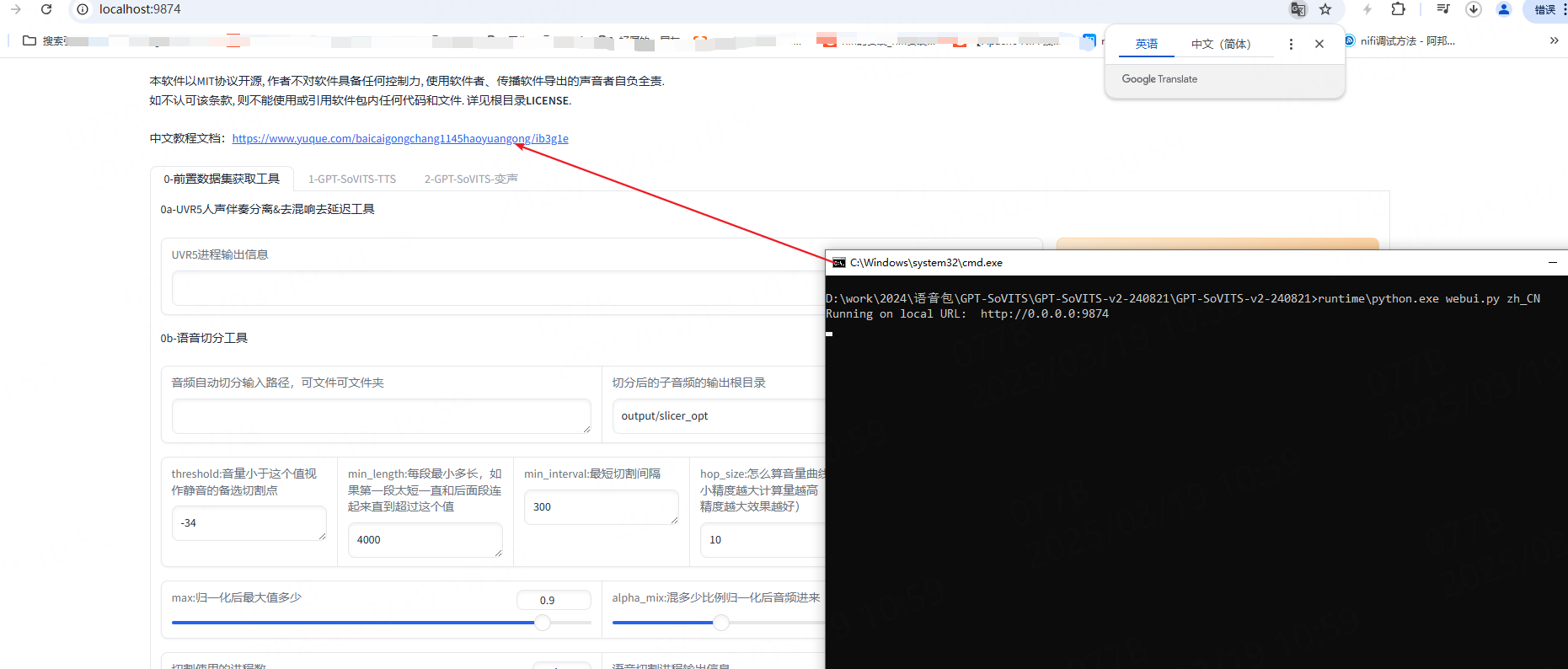
这样我们就运行成功了★,°:.☆( ̄▽ ̄)/$:.°★ 😊😊😊。
2:正戏
2.1:准备素材
因为是要克隆声音,所以你需要先准备你要克隆的声音素材,这里要求是wav格式的文件,你可以自己录制,也可以从这里来生成声音,声音不需要太长,30秒左右就行。当然如果你只是为了了解下这个工具而非真实使用那么你也可以从这里下载现成的素材。注意自己录制的话,一定要找个安静的环境,保证声音尽量的纯净,尽量少的杂音,这样后续的效果才有可能比较好。
电脑端可以使用这个网站,录制后直接导出wav格式。
2.1:切分文件
就是将一个大文件分成多个小文件,如下操作:
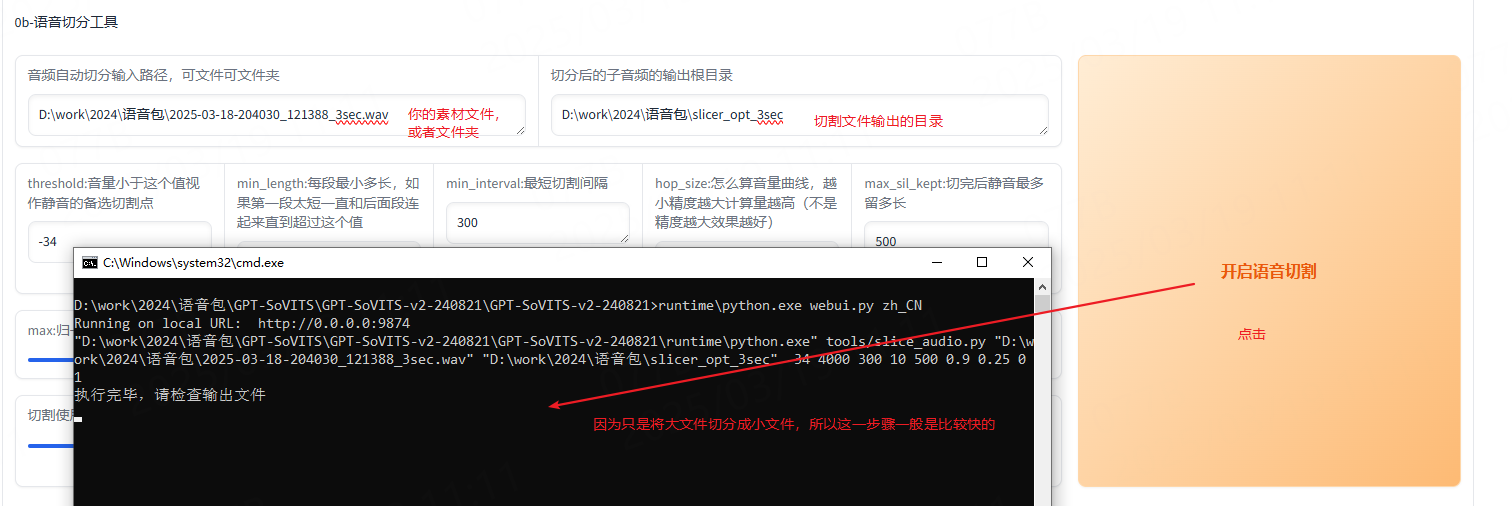
如下是切分文件结果:
因为我的素材文件只有3秒钟,所以只切出来一个文件,如果你的比较大的话,就会切出来多个文件了。
2.2:语音降噪
因为我们的素材很纯,所以这一步就免了。
2.3:打标批量离线asr,校对标注
这一步骤的目的是获取每个分割音频文件对应的文本是什么,这样才能知道每个文件该怎么读:
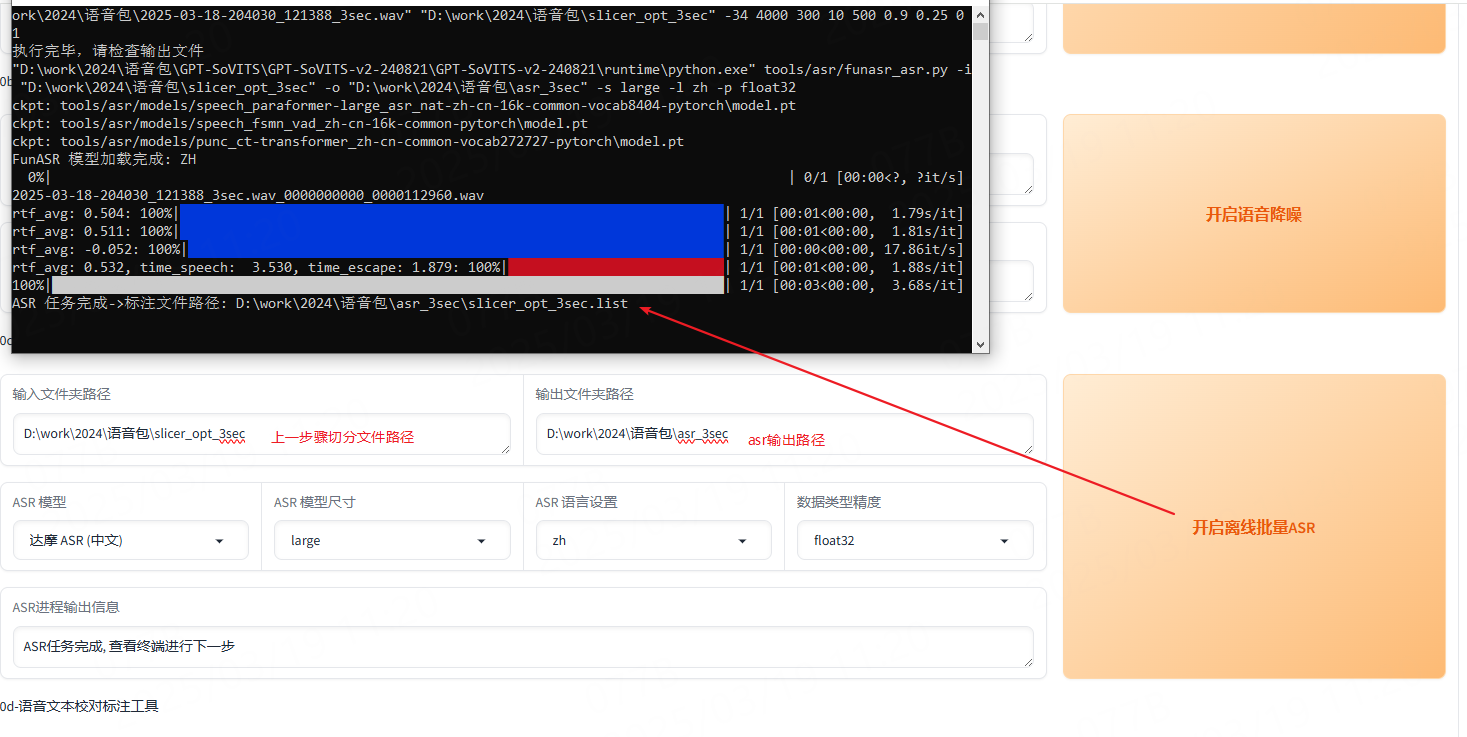
输出文件如下:

打开看到话就是每个文件对应的内容是啥。但是asr识别的可能并不是百分百的准确,比如文字不对,标点符号不符合人类语言的逻辑等,所以就需要校对标注来进行校准,这一步骤需要人工参与,所以可能会比较耗时耗精力(关键时刻还是要靠人真的是):

点击后稍等一会就会弹出打标页面了,让我们校对文本和语音是否对应,是否符合实际情况等:
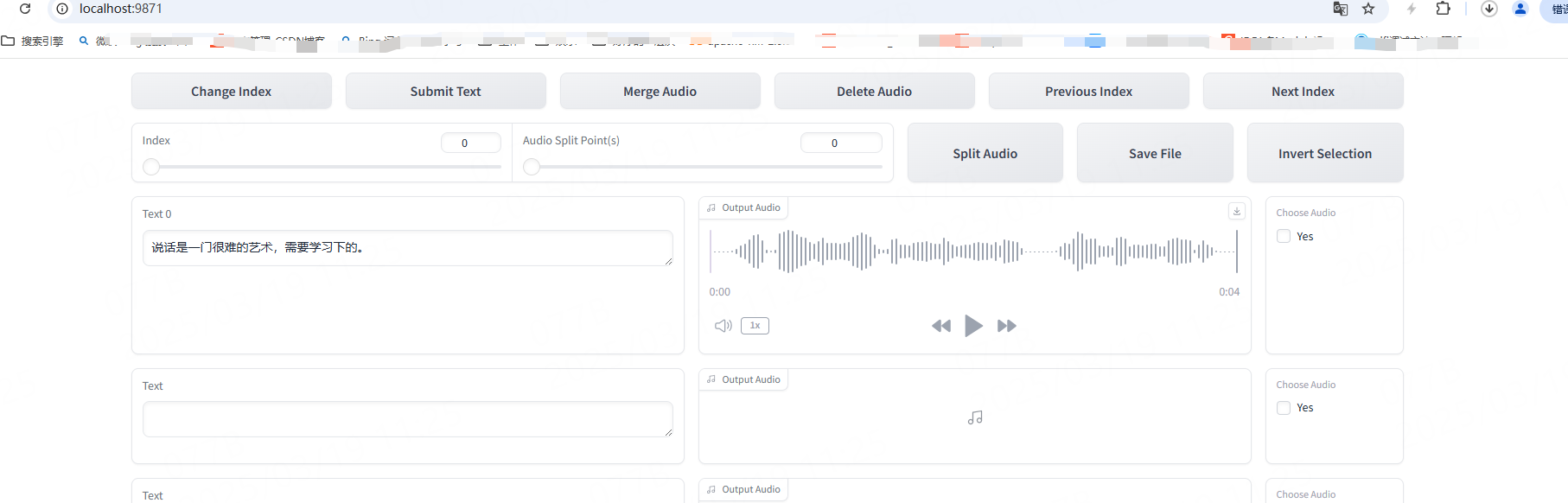
当然我这里只有一个切分文件,所以只有一行了,你可以在左侧来修改文案或者是标点符号,使其更能和右侧的语音对应起来,也可以在右侧进行试听:

修改完成后千万记得点击submit text,要不然你的修改就丢球了😔😔😔。
2.4:开启一键三连
切换到第二个tab签:

并给模型起个名字,这里随意了。
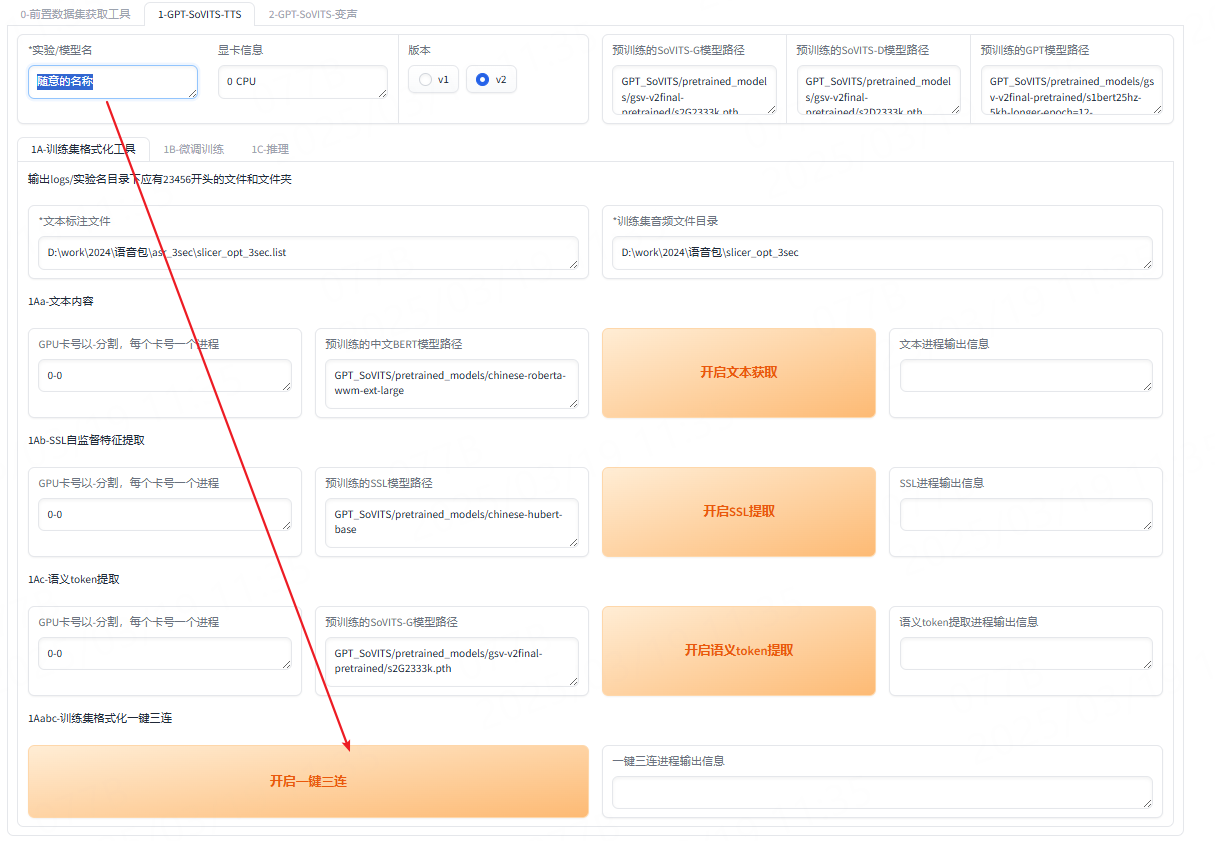
接着点击开启一键三连按钮:
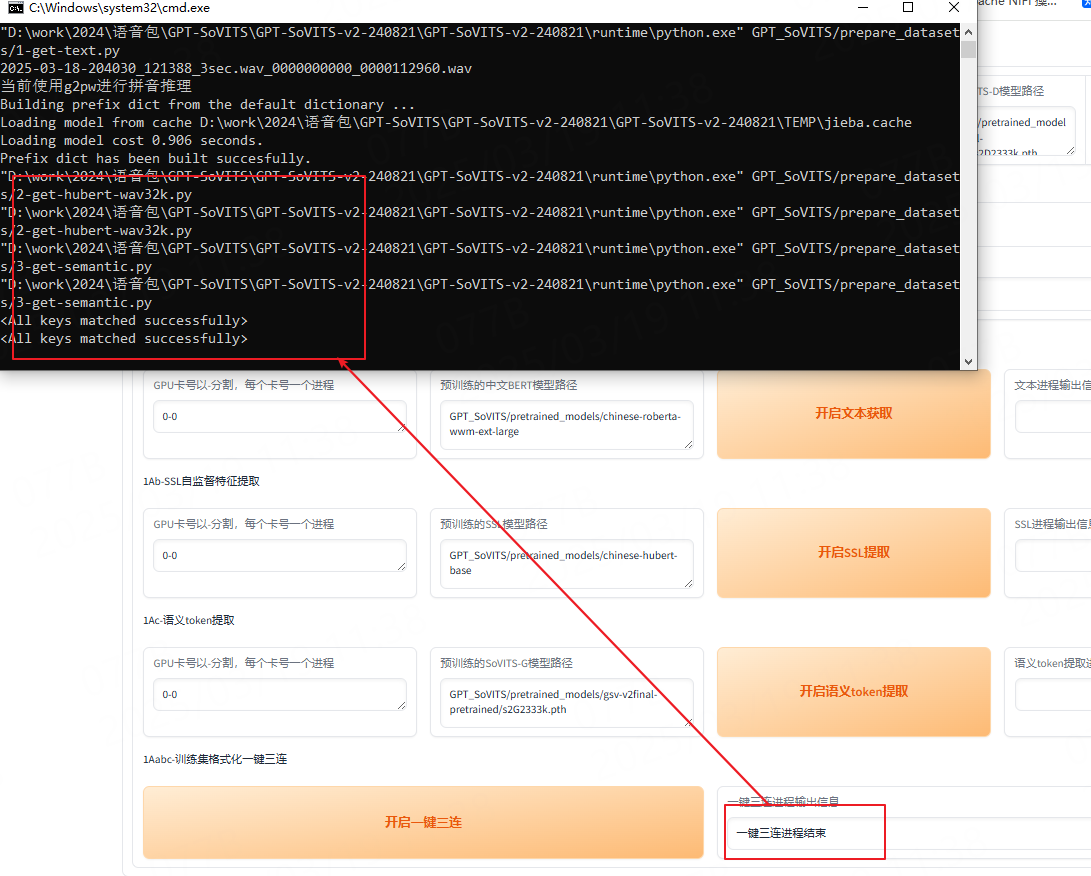
如上图就成功了。
接着就进入最最时间长的阶段,微调训练。
2.5:微调训练
我们切换到微调训练tab签:
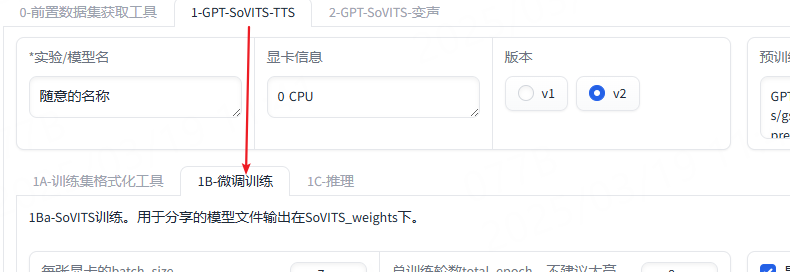
依次点击如下两个按钮,注意前一个成功后再点击后一个:
时间都比较长,耐心等待!
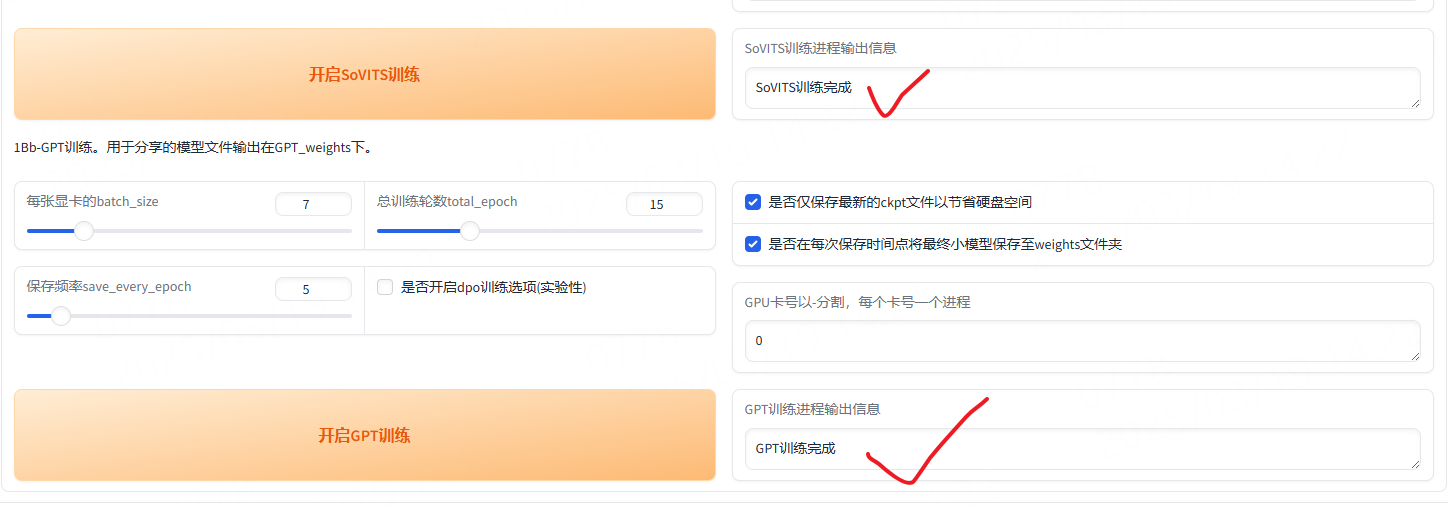
如下SoVITS训练中:
gtp训练中:
二者都训练完成了:
2.6:推理
到这一步就可以来合成自己的语音了。
点击1c-推理,并点击按钮开启TTS推理web UI:
成功后会打开如下的页面:
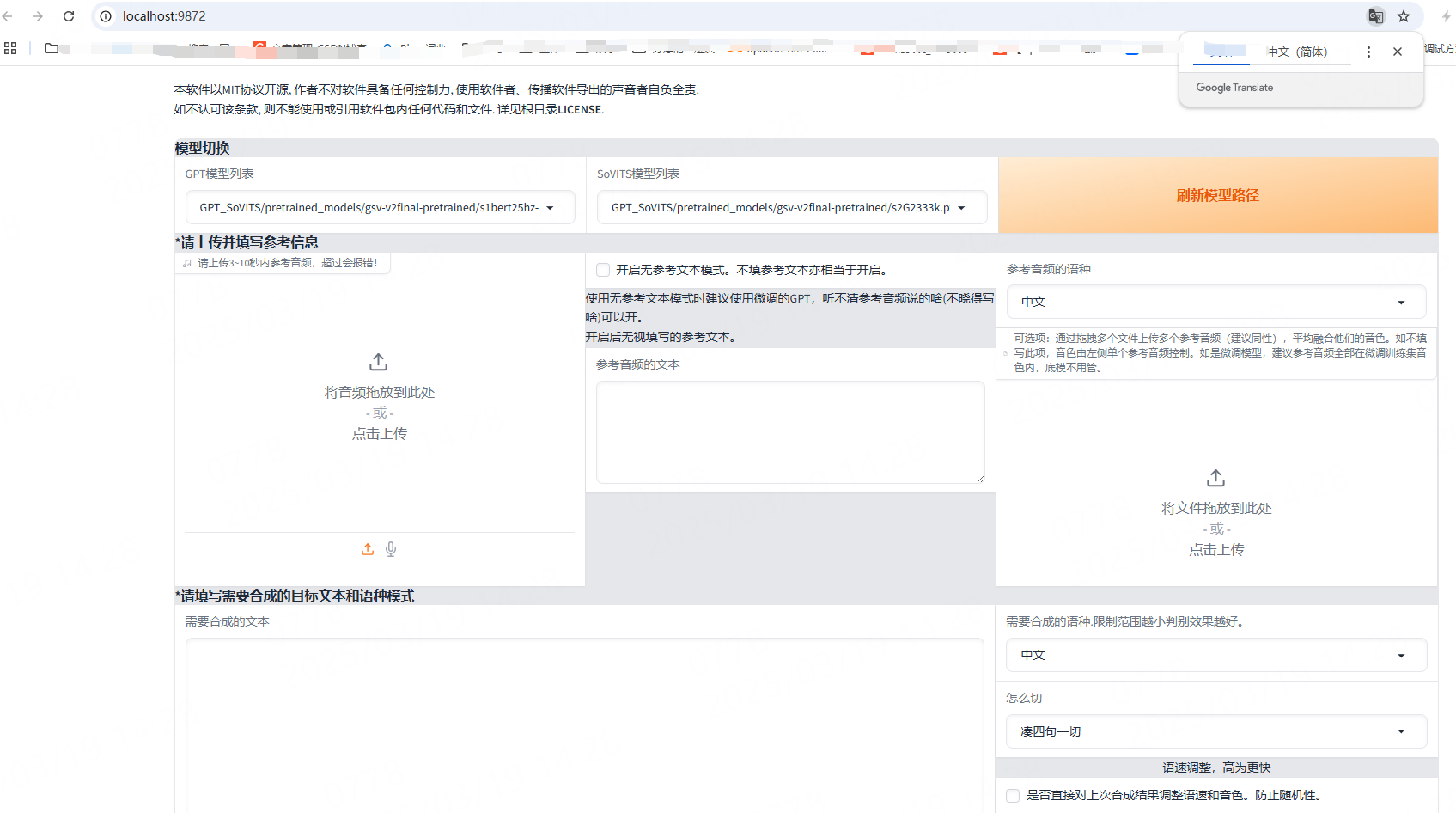
首先进行如下的设置:
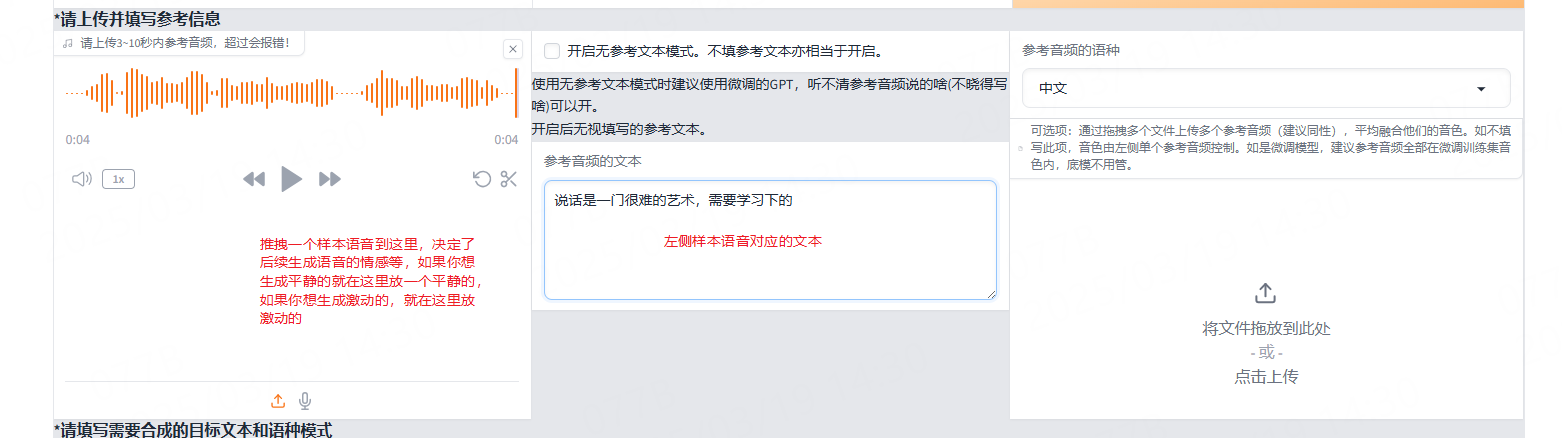
接着就可以进行如下操作来生成语音了:
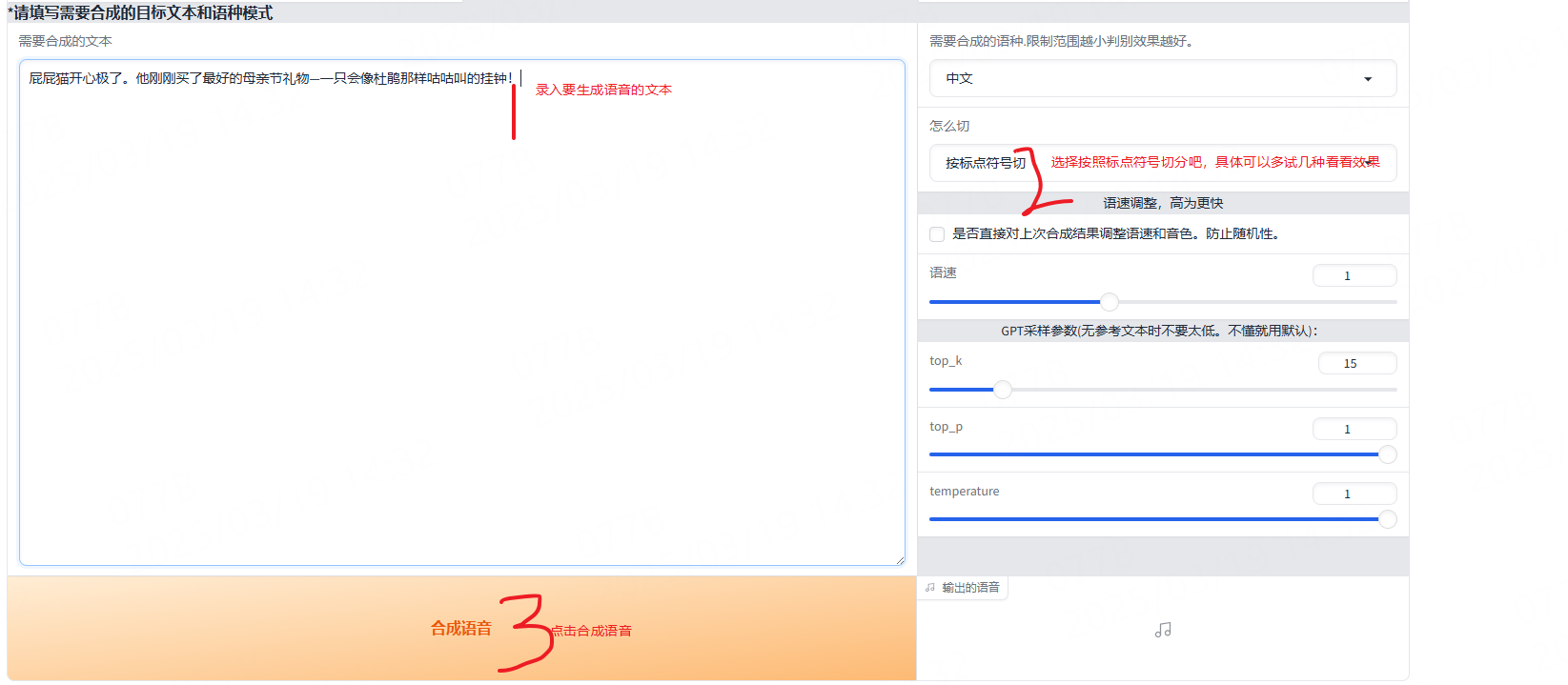
生成成功后如下:
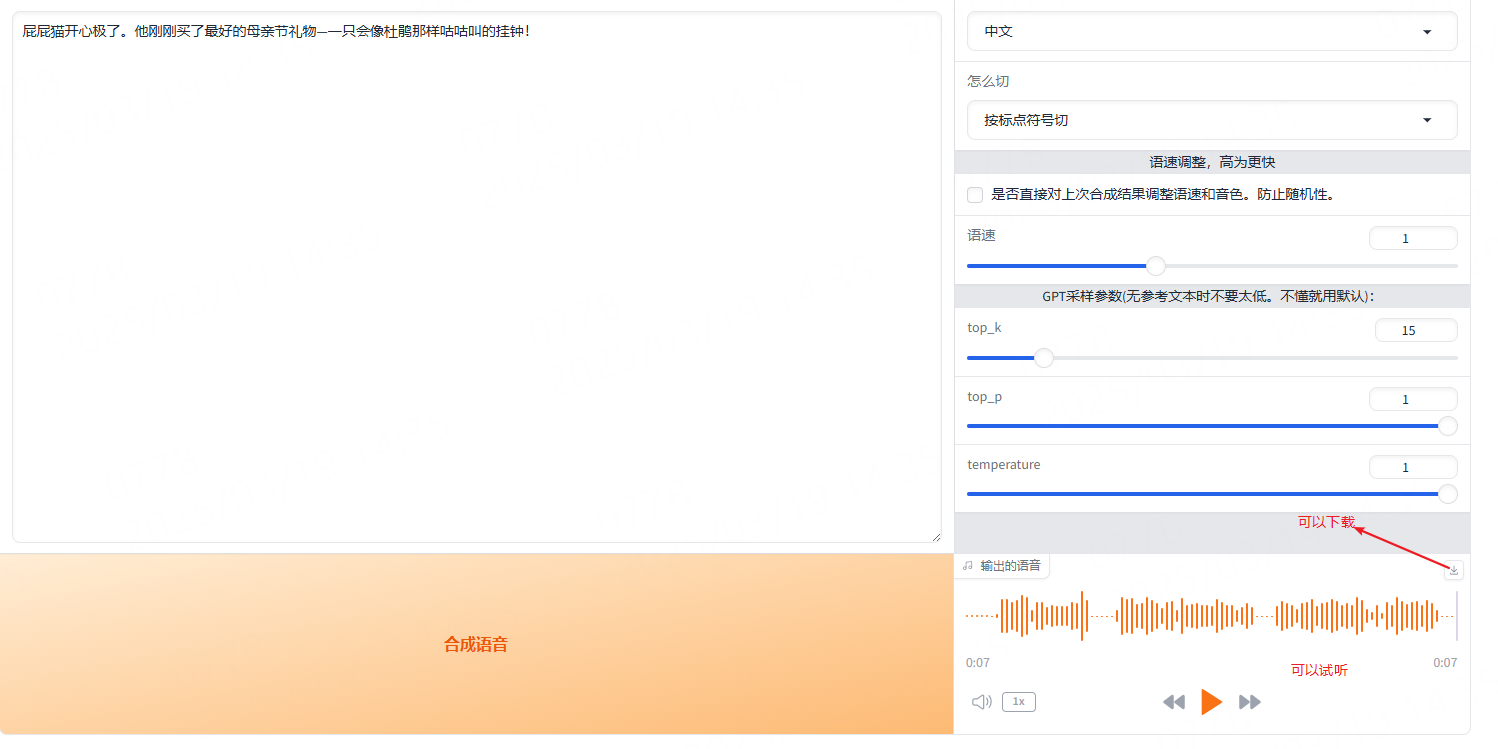
如下文本:
当屁屁猫和矮矮虫回来的时候,保修好先生已把每个零件重新装好了。
“噢,谢谢你,保修好先生!”屁屁猫说。
“很高兴能帮上忙。”保修好先生说。
屁屁猫急不可待地要把礼物送给妈妈。到了家门前,他按响了自行车的铃铛。
“咕咕—咕咕!”车铃铛叫起来。
屁屁猫非常惊讶。然后他把挂钟交给妈妈。
“母亲节快乐!”他说。
生成的语音,大家可以参考。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









