







Introduction
本文研究的课题为 tracking by natural language (NL) 。人类的学习过程是视觉和语言共同作用的,而在基于外观的跟踪过程中引入语言描述同样可以使得跟踪器更加精确、灵活和鲁棒(如图 1 的例子)。因此,本文将孪生跟踪器与语言描述结合,将语言描述编码成一个卷积核嵌入到孪生框架中(SNL-RPN),并将视觉和语言的预测进行动态聚合(Dynamic Aggregation),为 tracking by NL 任务提供了一个新的 baseline。具体贡献总结如下:
- 提出一种新的 tracking by NL 的 baseline,Siamese Natural Language Region Proposal Network (SNL-RPN);
- 提出了一种基于视觉和语言预测的动态聚合(Dynamic Aggregation),将 SNL-RPN 转换为 Siamese Natural Language Tracker (SNLT);
- 在 NL 标注的数据集上将孪生跟踪器的性能提升了 3-7 个百分点,并且性能超过其他 NL tracker,速度为 50FPS。
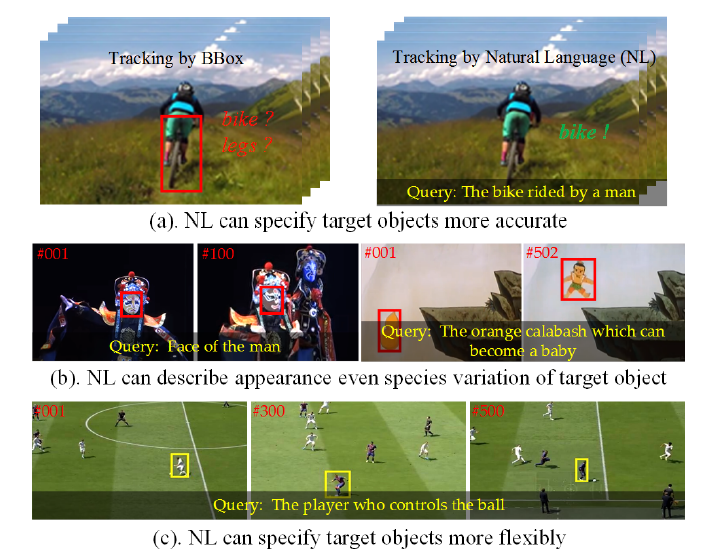
图 1 (摘自 CVPR2021 TNL2K) (a) 只利用 box 时跟踪器可能会混淆跟踪目标是自行车还是人的腿,加入语言描述使得跟踪对象更加清晰;(b) 当目标发生剧烈形变时加入语言描述可以减少漂移;(c) 语言描述可以更灵活地指定目标,如这里需要跟踪持球的运动员,使用传统跟踪器达到这一效果需要反复重新初始化跟踪器。
Method
Overview
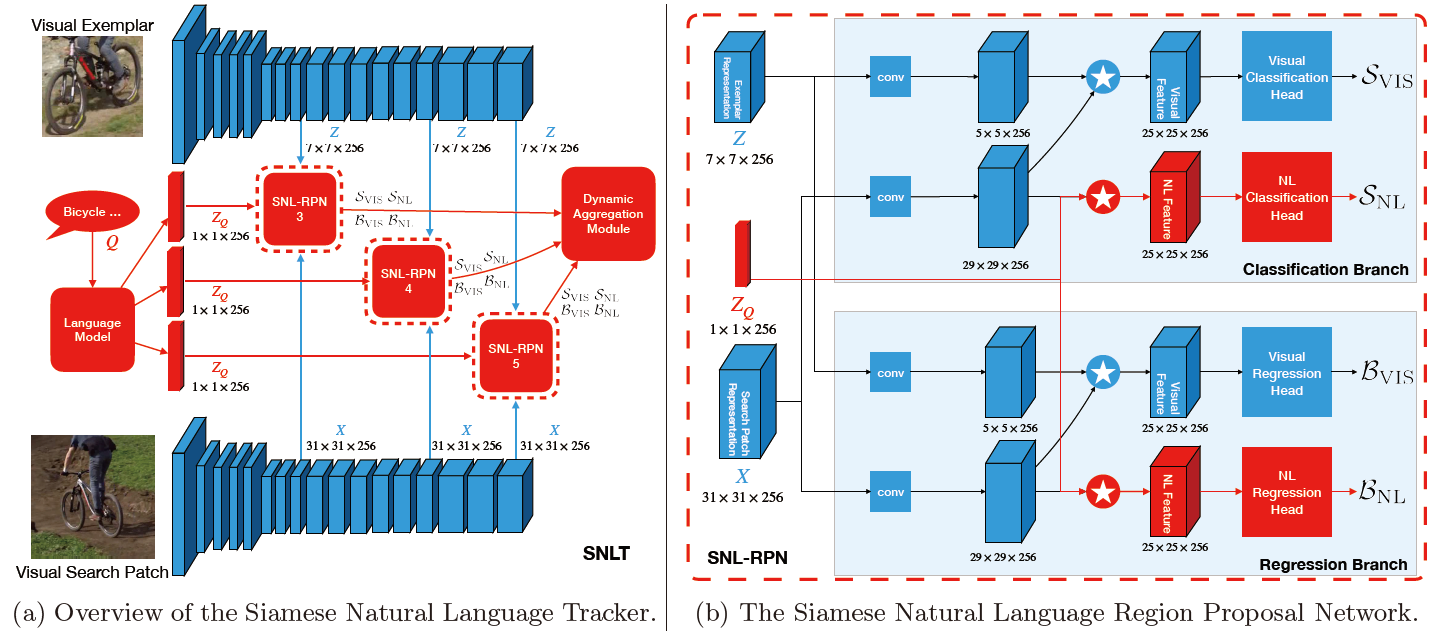
上图展示了 SNLT 整体框架,将语言描述嵌入到 SiamRPN++ 中。输入包含三部分:模板、搜索区域和查询语言 Q。模板和搜索区域经过卷积提取特征和
,查询语言经过语言模型(BERT, GloVe, HGLMM)提取句子嵌入编码
。三元组
送入 SNL-RPN,分别预测视觉和语言的分类和回归响应。最后二者通过 Dynamic Aggregation Module 进行融合。
Architecture of the SNL-RPN
SNL-RPN 如上图 b 所示,包括蓝色部分的 visual head 和红色部分的 NL head,都是通过 DW-XCorr 生成相应的的分类和回归响应。类似 SiamRPN++,同样在 ResNet 的三个 stage 上进行预测,并将结果融合,融合权重通过离线训练得到。visual head 和 NL head 各包含两个分支,总共有四组融合参数:
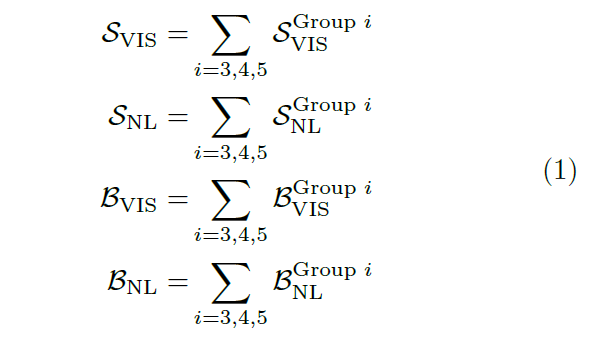
表示分类分支的视觉和语言预测,
表示回归分支的两种预测。
Aggregation of the SNL-RPN Predictions
上一节对不同 stage 的预测融合,本节作者对视觉和语言的结果再次进行融合:
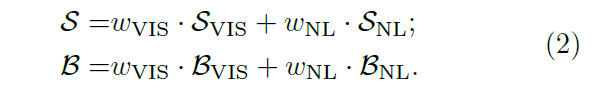
可以简单像上面一样离线训练得到,但是融合对象来自两个不同的输入,用固定的权重融合并不是最优的。因此,作者提出一个基于预测响应图熵的动态融合方式:
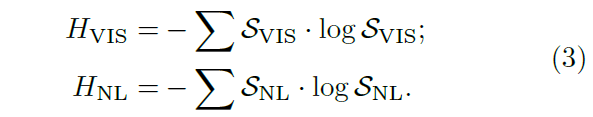
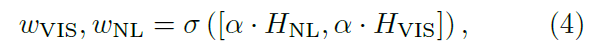
其中表示 softmax 函数,
表示缩放因子。公式 4 的含义是熵越大的项赋予更小的权重。熵越大表示预测图分布越混乱,越不准确,所以权重更小。
Training the SNL-RPN and Loss Functions
训练设置和 siamese 框架一样,额外增加了一个语言模型。损失函数分别计算视觉和语言对应的分类回归损失。
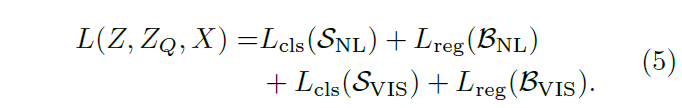
Experiments
训练数据集使用的是 MSCOCO, YouTube-BB, VisualGenome, LaSOT, OTB-99-LANG,其中后三个都是有语言标注的,前两个只有类别标注。
测试数据集使用有语言标注的 OTB-99-LANG 和 LaSOT。
Comparison with Visual and NL Trackers
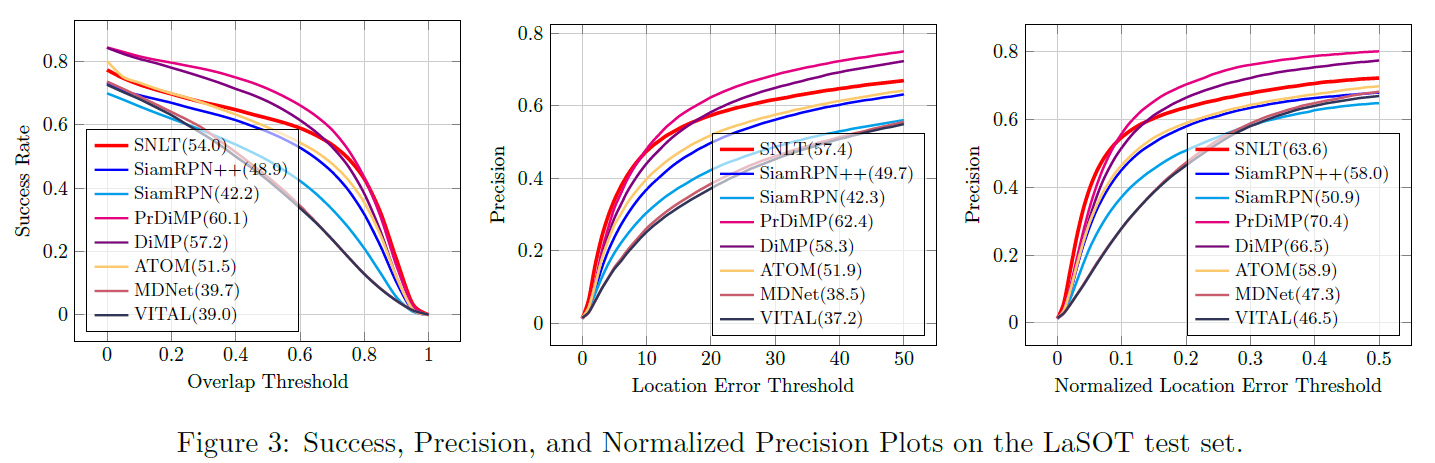
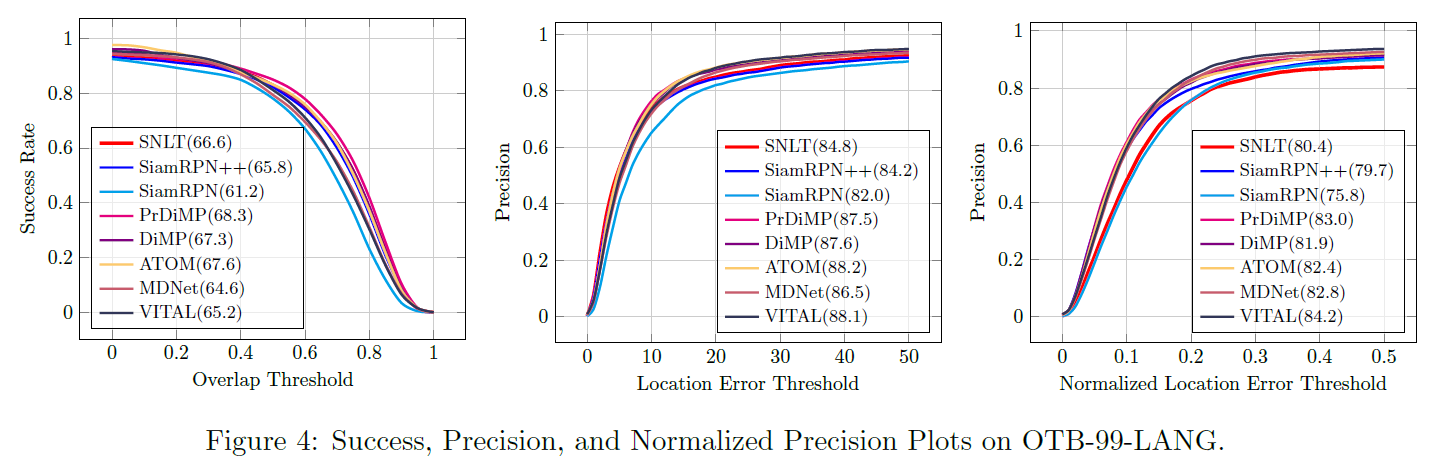


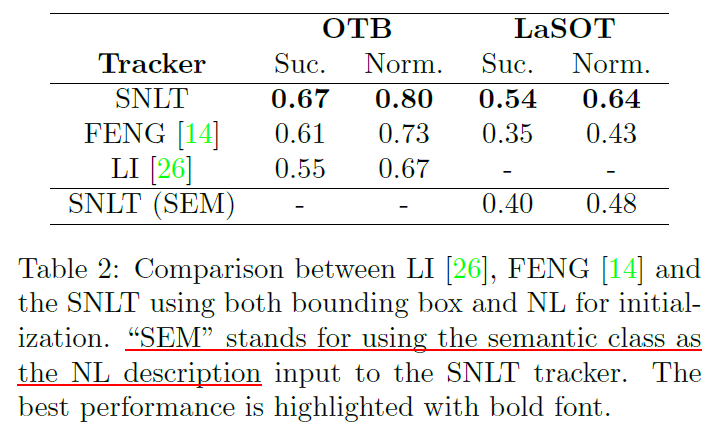
表 2 最后一行表示只使用语义类别作为语言输入测试 LaSOT(原始的 LaSOT 里语言描述是一句话),这样效果会下降,证明 SNLT 可以学到比语义类别更多的东西。
Ablation Studies
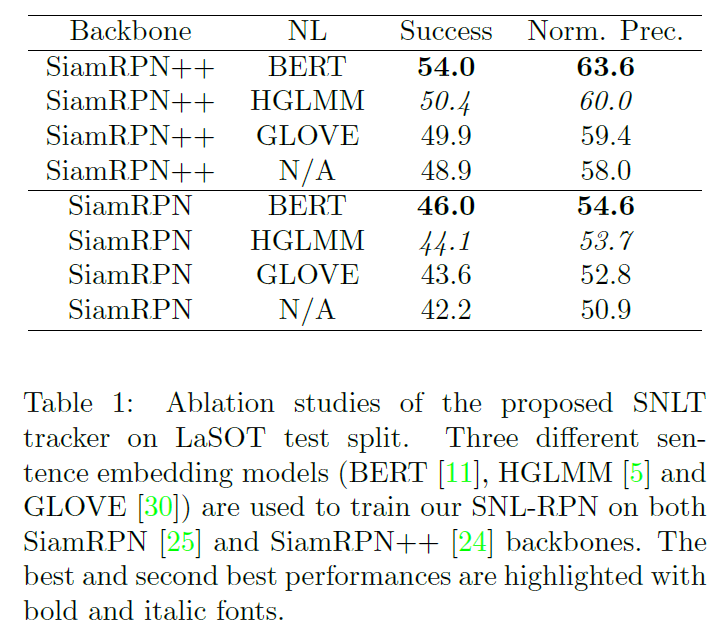
表 1 对比了不同语言模型的效果
图 6 的两个例子,第一个展示了语言描述可以辅助跟踪器避免模型漂移,而第二个例子语言描述不能唯一地描述目标,导致跟踪器漂移。

图 8 展示了视觉和语言的分类响应图,NL head 的响应更加准确,可能是由于遮挡阻碍了视觉模型。通过计算响应图的熵,赋予熵更小的 NL 响应图更大的权重。















 1360
1360











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









